Das Interesse an Bildanalysen zur Generierung von Empfehlungen wächst täglich. Wir haben uns entschlossen herauszufinden, wie real dieses Trendthema ist. Wir sprechen über das Testen des Einsatzes von Deep Learning (Deep Learning), um die Empfehlungen verwandter Produkte zu verbessern.

In diesem Artikel beschreiben wir die Erfahrungen mit der Anwendung der Bildanalysetechnologie zur Verbesserung des Algorithmus verwandter Produkte. Sie können es auf zwei Arten lesen: Wer sich nicht für die technischen Details der Verwendung neuronaler Netze interessiert, kann die Kapitel über das Erstellen eines Datensatzes und das Implementieren von Lösungen überspringen und direkt zu AB-Tests und deren Ergebnissen gehen. Und diejenigen, die ein grundlegendes Verständnis für Konzepte wie Einbettungen, eine Schicht eines neuronalen Netzwerks usw. haben, werden sich für das gesamte Material interessieren.
Deep Learning im Kontext der Bildanalyse
In unserem Technologie-Stack wird Deep Learning sehr erfolgreich eingesetzt, um einige Probleme zu lösen. Seit einiger Zeit haben wir es nicht gewagt, es im Rahmen der Bildanalyse anzuwenden, aber kürzlich sind eine Reihe von Prämissen aufgetaucht, die unsere Meinung geändert haben:
- erhöhtes Interesse der Community an Bildanalysen mit Deep-Learning-Methoden;
- Es wurde ein Kreis von „ausgereiften“ Frameworks und vorab trainierten neuronalen Netzen definiert, von denen aus man recht schnell und einfach beginnen konnte.
- Die Bildanalyse in Empfehlungssystemen wurde häufig als Marketingmerkmal verwendet, das "beispiellose" Verbesserungen garantiert.
- Nahrungsmittelbedürfnisse tauchten in dieser Art von Forschung auf.
Im Zusammenhang mit der Überschneidung von Empfehlungssystemen und der Bildanalyse kann es viele Anwendungen des Tiefenlernens geben. In der ersten Phase haben wir jedoch drei Hauptmethoden für die Entwicklung dieses Bereichs identifiziert:
- Eine allgemeine Verbesserung der Qualität von Empfehlungen, beispielsweise verwandter Produkte für ein Kleid, ist in Farbe und Stil qualitativ besser geeignet.
- Das Suchen von Waren in der Produktbasis eines Geschäfts mithilfe eines Fotos (In Shop Retrieval) ist ein Mechanismus, mit dem Sie mithilfe eines geladenen Fotos Produkte in der Datenbank eines Geschäfts finden können.
- Bestimmung der Eigenschaften / Attribute des Produkts anhand des Fotos (Attributkennzeichnung), wenn anhand des Fotos signifikante Attribute ermittelt werden, z. B. die Art des Produkts - ein T-Shirt, eine Jacke, eine Hose usw.
Die vorrangigste und vielversprechendste Richtung für uns ist die erste Option, und wir haben beschlossen, sie zu erkunden.
Warum haben Sie einen Algorithmus für verwandte Produkte gewählt?
Jedes Empfehlungssystem verfügt über zwei grundlegende statische Warenalgorithmen: Alternativen und verwandte Produkte. Und wenn bei den Alternativen alles klar ist - dies sind Produkte, die dem Originalmodell ähnlich sind (z. B. verschiedene Arten von Hemden), dann ist bei verwandten Produkten alles viel komplizierter. Es ist hier wichtig, keinen Fehler bei der Entsprechung zwischen der Basis- und der empfohlenen Ware zu machen. Beispielsweise sollte das Ladegerät zum Telefon passen, die Farbe des Kleides zu den Schuhen usw.; Sie müssen Rückmeldungen berücksichtigen. Empfehlen Sie dem Ladegerät beispielsweise kein Telefon, obwohl diese zusammen gekauft wurden. und denken Sie über eine Reihe anderer Nuancen nach, die in der Praxis auftreten. Vor allem aufgrund des Vorhandenseins verschiedener Nuancen fiel unsere Wahl auf verwandte Produkte. Darüber hinaus ist es nur bei verwandten Produkten möglich, einen vollwertigen Look zu kreieren, wenn wir über das Modesegment sprechen.
Wir formulierten unser Hauptforschungsziel wie folgt: „Verstehen, ob der aktuelle Algorithmus für verwandte Produkte mithilfe von Deep-Learning-Methoden für die Bildanalyse erheblich verbessert werden kann“.
Ich stelle fest, dass wir zuvor bei der Berechnung der Produktempfehlungen überhaupt keine Bildinformationen verwendet haben, und hier ist der Grund dafür:
- Während der Existenz der Retail Rocket-Plattform haben wir großes Fachwissen auf dem Gebiet der Produktempfehlungen erworben. Die wichtigste Schlussfolgerung, die wir in dieser Zeit erhalten haben, ist, dass die korrekte Verwendung des Benutzerverhaltens fast 90% des Ergebnisses liefert. Ja, es gibt das Problem eines Kaltstarts, wenn es inhaltliche Dinge wie Informationen über das Bild sind, die Empfehlungen klarstellen oder verbessern können, aber in der Praxis ist dieser Effekt viel geringer als theoretisch. Daher legen wir nicht viel Wert auf inhaltliche Informationsquellen.
- Um Produktempfehlungen in Form von Inhaltsinformationen zu erstellen, verwenden wir Elemente wie Preis, Kategorie, Beschreibung und andere Eigenschaften, die das Geschäft an uns weitergibt. Diese Eigenschaften sind unabhängig von der Sphäre und werden bei der Integration unseres Service qualitativ validiert. Der Wert des Bildes hingegen entsteht eigentlich nur im Segment der Modeartikel.
- Die Aufrechterhaltung des Dienstes an der Arbeit mit Bildern, die Überprüfung ihrer Qualität und Konformität mit Waren ist ein ziemlich komplizierter Prozess und eine ernsthafte technische Pflicht, die ich nicht ohne Bestätigung der Notwendigkeit übernehmen wollte.
Trotzdem haben wir uns entschlossen, den Bildern eine Chance zu geben und zu sehen, wie sie sich auf die Wirksamkeit von Bauempfehlungen auswirken. Unser Ansatz ist nicht ideal, sicher würde jemand das Problem anders lösen. Das Ziel dieses Artikels ist es, unseren Ansatz mit einer Beschreibung der Argumente bei jedem Schritt zu präsentieren und die Ergebnisse dem Leser zu präsentieren.
Konzeptbildung
Wir haben zunächst die drei Komponenten eines Produkts gekreuzt: erschwingliche Technologie, verfügbare Ressourcen und Kundenbedürfnisse. Das Konzept der „Verbesserung von Empfehlungen durch Informationen zum Image verwandter Produkte“ hat sich von selbst entwickelt. Die „ideale“ Implementierung dieses Produkts wurde als ein Thema gebildet, das im Bild eines ausgewählten Looks zusammengestellt wurde. Darüber hinaus sollten solche Empfehlungen nicht nur gut aussehen, sondern auch unter dem Gesichtspunkt der grundlegenden E-Commerce-Metriken (Conversion, RPV, AOV) funktionieren, die nicht schlechter sind als unser grundlegender Algorithmus.
Look ist ein von Stylisten ausgewähltes Bild, das eine Reihe verschiedener Dinge enthält, die sich untereinander kombinieren, z. B. ein Kleid, eine Jacke, eine Tasche, einen Gürtel usw. Auf der Seite unserer Kunden werden solche Arbeiten normalerweise von speziell dafür vorgesehenen Personen ausgeführt, deren Arbeit schlecht automatisiert ist. Schließlich kann nicht jedes neuronale Netzwerk einen Geschmackssinn haben.
 Ein Beispielbild (Look).
Ein Beispielbild (Look).Sofort gab es Einschränkungen bei der Verwendung von Bildinformationen - tatsächlich wurde die Anwendung nur im Modesegment gefunden.
Infrastruktur und Datensatz
Zunächst haben wir einen Prüfstand für Experimente und Prototypen erstellt. Hier ist alles ziemlich Standard-GPU + Python + Keras, daher werden wir nicht auf Details eingehen. Wir haben einen hochwertigen Datensatz gefunden, der mehrere Probleme gleichzeitig lösen soll, von der Vorhersage von Attributen aus dem Bild bis zur Erzeugung neuer Kleidungstexturen. Was für uns besonders wichtig war, waren Fotos, die praktisch einen einzigen Look ausmachten. Der Datensatz enthielt auch Fotos von Kleidungsmodellen aus verschiedenen Blickwinkeln, die wir in der ersten Phase zu verwenden versuchten.
 Beispielblick aus einem Datensatz.
Beispielblick aus einem Datensatz. Beispiele für Bilder desselben Kleidungsmodells aus verschiedenen Blickwinkeln.
Beispiele für Bilder desselben Kleidungsmodells aus verschiedenen Blickwinkeln.Erste Schritte
Die erste Idee, das Endprodukt mithilfe des Datensatzes zu implementieren, war recht einfach: „Reduzieren wir das Problem auf die Aufgabe, Kleidung anhand des Bildes zu erkennen. Wenn wir Empfehlungen formulieren, werden wir daher diejenigen Empfehlungen „aufheben“, die dem Basisprodukt ähnlich sind. “ Dementsprechend sollte es die Funktion der „Nähe“ von Waren finden und dabei das Problem der Entfernung von Alternativen in dem Problem lösen.
Ich muss sofort sagen, dass diese Art von Problem mit einem herkömmlichen vorab trainierten neuronalen Netzwerk wie ResNet-50 gelöst werden könnte. In der Tat: Wir entfernen die letzte Schicht, wir erhalten Einbettungen und dann den Kosinus als Maß für die „Nähe“. Nachdem wir jedoch ein wenig mit diesem Ansatz experimentiert hatten, beschlossen wir, ihn hauptsächlich aus drei Gründen zu belassen.
- Es ist nicht sehr klar, wie die resultierende Nähe richtig interpretiert werden soll. Was ist Cosinus = 0,7 im Bereich der T-Shirts, wo in der Regel alles sehr ähnlich ist und was ist Cosinus = 0,5 im Bereich der Jacken, wo die Unterschiede signifikanter sind. Wir brauchten diese Art der Interpretation, um gleichzeitig sehr nahe Produkte zu entfernen - Alternativen.
- Dieser Ansatz hat uns aus Sicht der Weiterbildung für unsere spezifischen Aufgaben etwas eingeschränkt. Beispielsweise sind die wichtigen Merkmale, die ein ganzheitliches Bild bilden, von Domäne zu Domäne nicht immer gleich. Irgendwo sind Farbe und Form wichtiger, aber irgendwo das Material und seine Textur. Darüber hinaus wollten wir das Netzwerk trainieren, um weniger geschlechtsspezifische Fehler zu machen, wenn Frauen für Männerkleidung empfohlen werden. Ein solcher Fehler ist sofort offensichtlich und sollte so selten wie möglich auftreten. Mit der einfachen Verwendung von vorab trainierten neuronalen Netzen schien es uns ein wenig eingeschränkt zu sein, dass wir keine Beispiele liefern konnten, die in Bezug auf das Bild „ähnlich“ sind.
- Die Verwendung von siamesischen Netzwerken, die für diese Aufgaben besser geeignet sind, schien eine natürlichere und besser untersuchte Option zu sein.
Ein bisschen über das siamesische neuronale Netz
Siamesische neuronale Netze werden häufig zur Lösung von Aufgaben im Zusammenhang mit der Gesichtserkennung verwendet. Bei der Eingabe wird ein Bild der Person geliefert, bei der Ausgabe der Name der Person aus der Datenbank, zu der sie gehört. Ein solches Problem kann direkt gelöst werden, wenn Sie Softmax verwenden und die Anzahl der Klassen der Anzahl der erkennbaren Personen auf der letzten Schicht des neuronalen Netzwerks entspricht. Dieser Ansatz weist jedoch mehrere Einschränkungen auf:
- Sie müssen für jede Klasse eine ausreichend große Anzahl von Bildern haben, was praktisch unmöglich ist.
- Ein solches neuronales Netzwerk muss jedes Mal umgeschult werden, wenn eine neue Person zur Datenbank hinzugefügt wird, was sehr unpraktisch ist.
Eine logische Lösung in einer solchen Situation wäre, die "Ähnlichkeits" -Funktion der beiden Fotos zu erhalten, um jederzeit zu beantworten, ob die beiden Fotos - die dem Eingang des neuronalen Netzwerks und der Referenz aus der Datenbank zugeführt werden - derselben Person gehören und dementsprechend das Problem der Gesichtserkennung lösen. Dies entspricht eher dem Verhalten einer Person. Ein Wachmann schaut beispielsweise auf das Gesicht einer Person und ein Foto auf einem Abzeichen und beantwortet die Frage, ob diese Person eine Person ist oder nicht. Das siamesische neuronale Netz implementiert ein ähnliches Konzept.
Die Hauptkomponente des siamesischen neuronalen Netzwerks ist das neuronale Backbone-Netzwerk, das eine Bildeinbettung ausgibt. Diese Einbettung kann verwendet werden, um den Ähnlichkeitsgrad zwischen den beiden Bildern zu bestimmen. In der Architektur des siamesischen neuronalen Netzwerks wird die Backbone-Komponente jedes Mal zweimal verwendet, um die Einbettung des Bildes zu empfangen. Der Forscher muss die Ausgabewerte 0 oder 1 anzeigen, je nachdem, ob eine oder mehrere Personen die Fotos besitzen, und das neuronale Backbone-Netzwerk anpassen.
 Ein Beispiel für ein siamesisches neuronales Netzwerk. Die Einbettungen der oberen und unteren Bilder werden vom Rückgrat des neuronalen Netzwerks erhalten. Bild aus Andrey Ngs Kurs „Convolutional Neural Networks“.
Ein Beispiel für ein siamesisches neuronales Netzwerk. Die Einbettungen der oberen und unteren Bilder werden vom Rückgrat des neuronalen Netzwerks erhalten. Bild aus Andrey Ngs Kurs „Convolutional Neural Networks“.Grundlösung
Nach einigen Experimenten war die erste Version des Algorithmus also wie folgt:
- Wir nehmen jedes vorab trainierte neuronale Netzwerk als Rückgrat. Wir haben mit ResNet-50 und InceptionV3 experimentiert. Ausgewählt auf der Grundlage des Gleichgewichts zwischen Netzwerkgröße und Genauigkeit der Vorhersagen. Wir haben uns auf die Daten konzentriert, die in der offiziellen Dokumentation zu Keras im Abschnitt „Dokumentation für einzelne Modelle“ enthalten sind.
- Wir bauen auf dieser Basis ein siamesisches Netzwerk auf und verwenden Triplet Loss für Schulungen.
- Als positive Beispiele dienen wir demselben Bild, jedoch aus einem anderen Blickwinkel. Als negatives Beispiel servieren wir ein anderes Produkt.
- Mit einem geschulten Modell erhalten wir die Proximity-Metrik für jedes Produktpaar auf die gleiche Weise, wie Triplet Loss berücksichtigt wird.
Berechnungscode für den Triplettverlust.Der Deal mit Triplet Loss über ein reales Projekt war das erste Mal, was eine Reihe von Schwierigkeiten verursachte. Zunächst hatten sie lange Zeit mit der Tatsache zu kämpfen, dass die erhaltenen Einbettungen alle auf einen Punkt hinausliefen. Es gab eine Reihe von Gründen: Wir haben die Einbettungen vor der Berechnung des Verlusts nicht normalisiert. Rand der Alpha-Parameter war zu klein und die Beispiele zu schwierig. Hinzugefügte Normalisierung und Einbettungen begannen zu variieren. Das zweite Problem wurde unerwartet Gradient Exploding. Glücklicherweise hat Keras es möglich gemacht, dieses Problem ganz einfach zu lösen - wir haben dem Optimierer clipnorm = 1.0 hinzugefügt, wodurch die Farbverläufe während des Trainings nicht wachsen konnten.
Die Arbeit war iterativ: Wir haben das Modell trainiert, den Verlust gesenkt, das Endergebnis betrachtet und fachmännisch entschieden, in welche Richtung wir gehen. Irgendwann wurde klar, dass wir sofort ziemlich komplexe Beispiele aufstellten und die Komplexität sich im Lernprozess nicht ändert, was sich negativ auf das Endergebnis auswirkt. Glücklicherweise hatte der Datensatz, mit dem wir gearbeitet haben, eine gute Baumstruktur, die das Produkt selbst widerspiegelte, zum Beispiel Männer -> Hosen, Männer -> Pullover usw. Dies ermöglichte es uns, den Generator neu zu gestalten, und wir begannen, „einfache“ Beispiele für die ersten paar Epochen zu geben, dann für komplexere und so weiter. Die schwierigsten Beispiele sind Produkte derselben Produktkategorie, zum Beispiel Hosen, als negativ.
Als Ergebnis haben wir ein Modell erhalten, das sich in seiner Ausgabe von der „naiven“ Methode zur Verwendung von ResNet-50 unterscheidet. Die Qualität der endgültigen Empfehlungen passte jedoch nicht ganz zu uns. Erstens gab es ein Problem mit geschlechtsspezifischen Fehlern, aber es gab ein Verständnis dafür, wie es gelöst werden könnte. Da der Datensatz die Kleidung in Männer und Frauen aufteilte, war es einfach, negative Beispiele für das Training zu sammeln. Zweitens haben wir beim Training des Datensatzes das Endergebnis visuell auf unsere Kunden überprüft - es wurde sofort klar, dass es notwendig war, ihre Beispiele neu zu trainieren, da für einige der Algorithmus sehr schlecht funktionierte, wenn sich die Waren nicht gut mit dem überlappten, was während des Trainings gezeigt wurde . Schließlich war die Qualität oft schlecht, weil das Trainingsbild oft laut war und zum Beispiel nicht nur Jeans, sondern auch ein T-Shirt enthielt.
 Das Bild von Jeans, auf denen tatsächlich auch ein T-Shirt und Stiefel zu sehen sind.
Das Bild von Jeans, auf denen tatsächlich auch ein T-Shirt und Stiefel zu sehen sind.Die erste Erfahrung diente als Grundlage für die nachfolgende Lösung, obwohl wir nicht sofort mit der Implementierung eines verbesserten Modells begonnen haben.
 Ein Beispiel für Empfehlungen basierend auf einer Basislösung. Es gibt geschlechtsspezifische Fehler, es gibt auch Alternativen.
Ein Beispiel für Empfehlungen basierend auf einer Basislösung. Es gibt geschlechtsspezifische Fehler, es gibt auch Alternativen.Verbessertes Modell
Wir haben zunächst ResNet-50 anhand der Daten aus unserem Datensatz trainiert. Der Datensatz enthält Informationen darüber, was auf dem Bild angezeigt wird. Es wird aus der Struktur des Datensatzes Männer -> Hosen, Frauen -> Strickjacken und mehr extrahiert. Dieses Verfahren wurde aus zwei Gründen durchgeführt: Erstens wollten sie das Rückgrat „lenken“ - ein neuronales Netzwerk zur Bekleidungsdomäne; zweitens hofften sie, das Problem der geschlechtsspezifischen Fehler, die in der ersten Version aufgetreten waren, zu beseitigen, da die Kleidung auch nach Geschlecht unterteilt ist.
In der zweiten Phase haben wir versucht, gleichzeitig das Rauschen aus den Eingabebildern zu entfernen und positive Paare verwandter Produkte für das weitere Training zu erhalten. Der von uns verwendete Datensatz soll auch das Problem der Erkennung von Objekten im Bild lösen. Mit anderen Worten, für jedes Bild gibt es: die Koordinaten des Rechtecks, das das Objekt und seine Klasse beschreibt. Um diese Art von Problem zu lösen, haben wir ein
vorgefertigtes Projekt verwendet . Dieses Projekt verwendet die neuronale Netzarchitektur von RetinaNet mit einem speziellen Fokusverlust. Der Kern dieses Verlusts besteht darin, sich nicht mehr auf den Hintergrund des Bildes zu konzentrieren, der in fast jedem Bild zu sehen ist, sondern auf das Objekt, das erkannt werden muss. Als Rückgrat eines neuronalen Netzwerks für das Training haben wir unser vorab trainiertes Netzwerk ResNet-50 verwendet.
Infolgedessen werden auf jedem Bild aus dem Datensatz drei Objektklassen erkannt: "oben", "unten" und "allgemeine Ansicht". Nachdem wir die Klassen „oben“ und „unten“ definiert haben, schneiden wir das Bild einfach in zwei separate Bilder, die später als Paar positiver Beispiele für die Berechnung des Triplettverlusts verwendet werden. Die Qualität der Erkennung von Objekten erwies sich als recht hoch. Die einzige Beschwerde war, dass es nicht immer möglich war, eine Klasse im Bild zu finden. Dies war für uns kein Problem, da wir die Anzahl der Bilder für Vorhersagen leicht erhöhen konnten.
 Ein Beispiel für das Erkennen der Klassen "oben" und "unten" und das Ausschneiden des Bildes.
Ein Beispiel für das Erkennen der Klassen "oben" und "unten" und das Ausschneiden des Bildes.Mit dieser Art von Bildteiler hatten wir die Möglichkeit, einen Blick aus dem Internet zu werfen und ihn in Komponenten für die Verwendung in Schulungen zu unterteilen. Um die Anzahl der Schulungen zu erhöhen und das Problem mit einer unzureichenden Abdeckung von Beispielen zu lösen, die während der Entwicklung der Basislösung entstanden sind, haben wir den Datensatz aufgrund der „geschnittenen“ Bilder eines unserer Kunden erweitert. Das einzige Problem war, dass wir Objekte wie „Accessoire“, „Kopfschmuck“, „Schuhe“ usw. nicht unterschieden haben. Dies führte zu einigen Einschränkungen, war jedoch zum Testen des Konzepts durchaus geeignet. Nachdem wir positive Ergebnisse erhalten hatten, planten wir, das Modell auf die oben beschriebenen Klassen zu erweitern.
Nachdem wir einen erweiterten Datensatz erhalten hatten, verwendeten wir die bereits bewährte Methode zum Aufbau des siamesischen Netzwerks aus der Basislösung, obwohl es mehrere Unterschiede gab. Zunächst verwendeten wir als Rückgrat des neuronalen Netzwerks das oben beschriebene jetzt trainierte ResNet-50-Netzwerk. Zweitens haben wir jetzt als positive Beispiele Top-to-Bottom-Paare und umgekehrt eingereicht, damit wir aus dem neuronalen Netzwerk genau die „Entsprechung“ des Bildes lernen können. Nun, tatsächlich ein Dutzend Epochen später erschien ein Mechanismus, der uns die Möglichkeit gab, die „Konformität“ von Waren mit einem einzigen Bild zu bewerten.
 Ein Beispiel für Empfehlungen, die auf der Verwendung eines neuronalen Netzwerks basieren. Für das Basisprodukt werden Shorts empfohlen, T-Shirts werden empfohlen.
Ein Beispiel für Empfehlungen, die auf der Verwendung eines neuronalen Netzwerks basieren. Für das Basisprodukt werden Shorts empfohlen, T-Shirts werden empfohlen.Das Endergebnis hat uns gefallen: Die Empfehlungen erwiesen sich als visuell von guter Qualität, und was besonders gut ist, ihre Konstruktion erforderte keine Benutzerinteraktionen in der Vergangenheit. Es blieben jedoch Probleme, das Hauptproblem war die Verfügbarkeit von Alternativen bei der Auslieferung. So kam es zu Auslieferungen, bei denen der „Boden“ dem „Boden“ empfohlen wurde, dasselbe geschah mit der Kategorie „oben“. Dies brachte uns zum Nachdenken und zur Verfeinerung der Lösung, um Alternativen zu entfernen.
Alternativen entfernen
Um das Problem der Verfügbarkeit von Alternativen zu lösen, erfolgte die Ausgabe recht schnell. Erste Experimente mit dem „Vanille“ ResNet-50 haben geholfen. Ein solches neuronales Netzwerk gab als „ähnliche“ Güter diejenigen aus, die im Bild am meisten übereinstimmten - tatsächlich Alternativen. Das heißt, es könnte verwendet werden, um Alternativen zu identifizieren.
 Ein Beispiel für Empfehlungen basierend auf dem „Vanille“ ResNet-50. Waren sind Alternativen.
Ein Beispiel für Empfehlungen basierend auf dem „Vanille“ ResNet-50. Waren sind Alternativen.Mit dieser nützlichen Eigenschaft von ResNet-50 haben wir begonnen, möglichst nahe Produkte aus der Emission herauszufiltern und damit die Alternativen zu entfernen. Es gab auch Nachteile dieses Ansatzes - dieselbe unverständliche Situation, mit der der Schwellenwert für die Filterung gewählt werden sollte. Manchmal wurden ziemlich viele Produkte gefiltert, obwohl sie äußerlich keine Alternativen waren. Wir haben uns jedoch nicht auf dieses Problem konzentriert und weiter gearbeitet.
Vorbereitung von AB-Tests
Für die endgültige Überprüfung praktisch jeder Änderung der Algorithmen verwenden wir häufig das AB-Testtool. Darüber hinaus haben wir nur eine Regel: „Egal wie gering der Verlust ist, egal wie komplex und vielschichtig das neuronale Netzwerk ist, wie schön die Empfehlungen sein mögen - all dies wird nicht berücksichtigt, wenn der AB-Test kein Ergebnis liefert.“ Die Logik ist recht einfach: Ein AB-Test ist für alle Beteiligten (insbesondere für Kunden und Unternehmen) am ehrlichsten, verständlichsten und eine genaue Methode zur Messung des Ergebnisses. Retail Rocket - ( «
A/- 99% - ? »). - .
-. ,
RecSys 2016 . . , , , , . , - , .
, . , . , . - . , , , , - . : .
- , . -, , , , . -, — , , , , . , . , , , “», .
:
- “” “”, , , , . , , , .
- , . proof-of-concept , .
, , . , , .
AB-
, , - . — fashion. . , , . , , .
. 3 . , 95%.
 . Related-9 — “” , Related — .
. Related-9 — “” , Related — .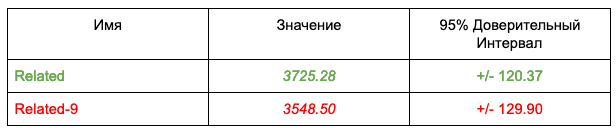 . Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.
. Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.: . , , , “” CTR. , , CTR , . - , - - , -. , .
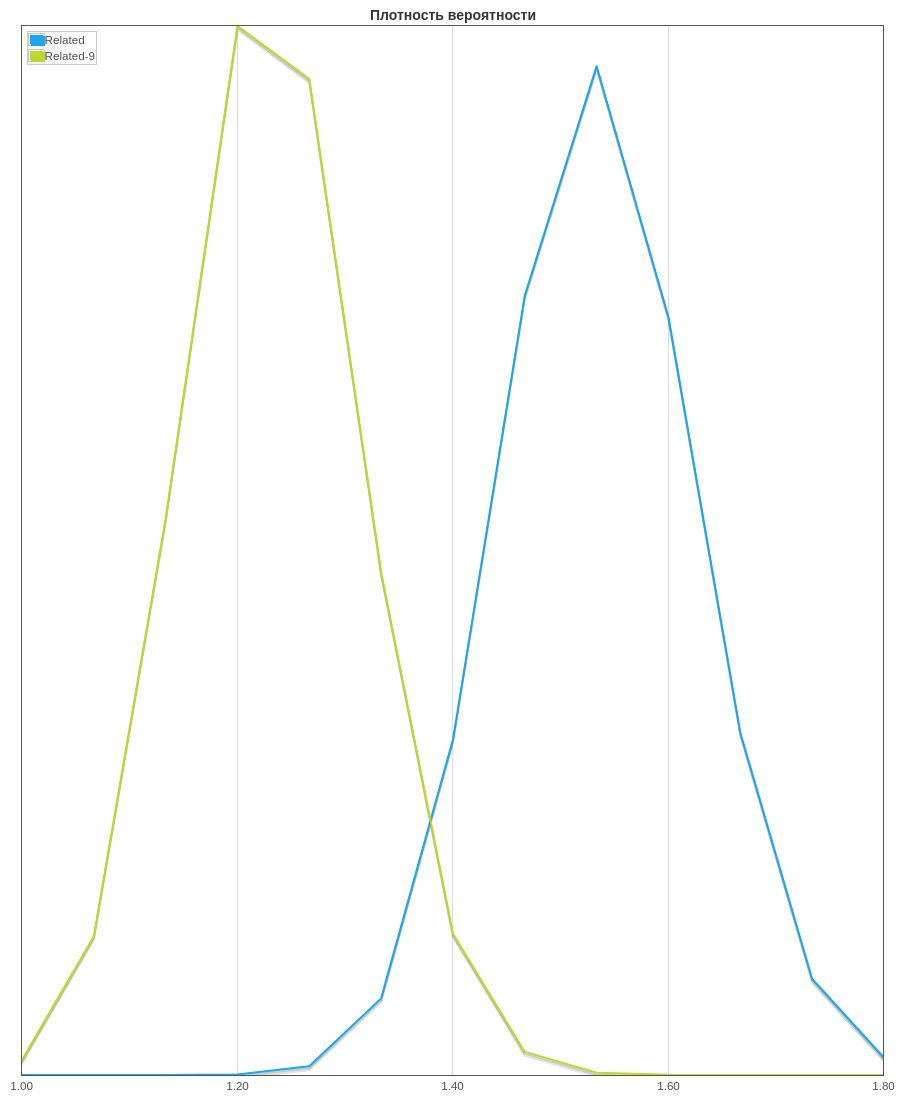 CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%.
CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%., , , , . , , . , , . .
Schlussfolgerungen
, , . , , . - . , — — , . , . , , , Retail Rocket.
, , , , « ». , . , .
, Retail Rocket