Haben Sie sich jemals gefragt, wie die Daten, mit denen Sie arbeiten, im Darm von Python aussehen? Wie werden Variablen erstellt und im Speicher gespeichert? Wie und wann werden sie entfernt? Das Material, dessen Übersetzung wir veröffentlichen, widmet sich der Erforschung der Tiefen von Python. Während dieser Zeit werden wir versuchen, die Merkmale der Speicherverwaltung in dieser Sprache herauszufinden. Nachdem Sie diesen Artikel gelesen haben, werden Sie verstehen, wie die Mechanismen von Computern auf niedriger Ebene funktionieren, insbesondere diejenigen, die sich auf den Speicher beziehen. Sie werden verstehen, wie Python Operationen auf niedriger Ebene abstrahiert und wie es den Speicher verwaltet.

Wenn Sie wissen, was in Python passiert, können Sie das Verhalten dieser Sprache besser verstehen. Ich hoffe, dies gibt Ihnen die Gelegenheit, die enorme Arbeit zu schätzen, die bei der Implementierung der von Ihnen verwendeten Sprache geleistet wird, damit Ihre Programme genau so funktionieren, wie Sie es benötigen.
Die Erinnerung ist ein leeres Buch
Der Computerspeicher kann zu Beginn seiner Arbeit in Form eines leeren Buches für Kurzgeschichten dargestellt werden. Es gibt zwar nichts auf seinen Seiten, aber bald werden Autoren von Geschichten erscheinen, von denen jeder seine eigene Geschichte in dieses Buch schreiben möchte.
Da eine Geschichte nicht übereinander geschrieben werden kann, müssen die Autoren darauf achten, auf welchen Seiten des Buches sie schreiben. Bevor sie etwas schreiben, konsultieren sie den Chefredakteur. Er entscheidet, wo genau die Autoren Geschichten aufnehmen können.
Da es das Buch, über das wir sprechen, schon seit einiger Zeit gibt, sind viele der darin enthaltenen Geschichten bereits veraltet. Wenn niemand eine Geschichte liest oder in seinen Werken erwähnt, wird diese Geschichte aus dem Buch entfernt, um Platz für neue Geschichten zu schaffen.
Im Allgemeinen können wir sagen, dass der Computerspeicher einem solchen Buch sehr ähnlich ist. In der Tat werden fortlaufende Speicherblöcke mit fester Länge sogar als Seiten bezeichnet. Daher glauben wir, dass der Vergleich des Speichers mit einem Buch sehr erfolgreich ist.
Autoren, die ihre Geschichten in ein Buch schreiben, sind verschiedene Anwendungen oder Prozesse, die Daten im Speicher speichern müssen. Der Chefredakteur, der entscheidet, auf welchen Seiten des Buches die Autoren schreiben können, ist der Mechanismus, der sich mit der Speicherverwaltung befasst. Und derjenige, der alte Geschichten aus dem Buch entfernt und Platz für neue schafft, kann mit dem Müllsammelmechanismus verglichen werden.
Speicherverwaltung: Der Weg vom Eisen zum Programm
Die Speicherverwaltung ist ein Prozess, bei dessen Implementierung Programme Daten in den Speicher schreiben und daraus lesen. Ein Speichermanager ist eine Entität, die bestimmt, wo genau eine Anwendung ihre Daten im Speicher ablegen kann. Da die Anzahl der Speicherfragmente, die Anwendungen zugewiesen werden können, nicht unendlich ist, muss der Speichermanager, der Anwendungen bedient, freie Speicherfragmente finden und für Anwendungen bereitstellen, ebenso wie die Anzahl der Seiten in einem Buch nicht unendlich ist. Dieser Vorgang, bei dem der Speicher Anwendungen zugewiesen wird, wird als Speicherzuweisung bezeichnet.
Wenn andererseits einige Daten nicht mehr benötigt werden, können sie gelöscht werden oder mit anderen Worten den Speicher freigeben, den sie belegen. Aber was genau „isolieren“ und „befreien“ sie, wenn sie von Erinnerung sprechen?
Irgendwo auf Ihrem Computer befindet sich ein physisches Gerät, auf dem Daten gespeichert werden, die von Python-Programmen während der Arbeit verwendet werden. Bevor ein Python-Objekt im physischen Speicher angezeigt wird, muss der Code viele Abstraktionsebenen durchlaufen.
Eine der wichtigsten dieser Schichten, die sich auf der Hardware befindet (z. B. RAM oder Festplatte), ist das Betriebssystem. Es führt Anforderungen zum Lesen von Daten aus dem Speicher und zum Schreiben von Daten in den Speicher aus (oder weigert sich, diese zu erfüllen).
Über dem Betriebssystem befindet sich eine Anwendung, in unserem Fall eine der Python-Implementierungen (es kann sich um ein Softwarepaket handeln, das Teil Ihres Betriebssystems ist oder von
python.org heruntergeladen wurde). Es ist dieses Softwarepaket, das sich mit der Speicherverwaltung befasst und den Betrieb Ihres Python-Codes sicherstellt. Der Schwerpunkt dieses Artikels liegt auf den Algorithmen und Datenstrukturen, mit denen Python den Speicher verwaltet.
Python-Referenzimplementierung
Die Referenz-Python-Implementierung heißt CPython. Es ist in C geschrieben. Als ich zum ersten Mal davon hörte, hat es mich buchstäblich verunsichert. Eine Programmiersprache, die in einer anderen Sprache geschrieben ist? Nun, eigentlich ist das nicht ganz richtig.
Die Python-Spezifikation wird in
diesem Dokument in einfachem Englisch beschrieben. Diese Spezifikation allein, in Python geschriebener Code, kann natürlich nicht ausgeführt werden. Dazu benötigen Sie etwas, das gemäß den Regeln dieser Spezifikation in Python geschriebenen Code interpretieren kann.
Außerdem benötigen Sie etwas, das den interpretierten Code auf dem Computer ausführen kann. Die Referenz-Python-Implementierung löst diese beiden Aufgaben. Es konvertiert den Code in Anweisungen, die dann auf der virtuellen Maschine ausgeführt werden.
Virtuelle Maschinen ähneln gewöhnlichen Computern aus Silizium, Metall und anderen Materialien, sind jedoch in Software implementiert. Sie sind normalerweise damit beschäftigt, grundlegende Anweisungen zu verarbeiten, ähnlich den in
Assembler geschriebenen Anweisungen.
Python ist eine interpretierte Sprache. Der in Python geschriebene Code wird in einer Reihe von Anweisungen kompiliert, die für den Computer bequem zu verwenden sind, und zwar im sogenannten
Bytecode . Diese Anweisungen werden von der virtuellen Maschine interpretiert, wenn Sie Ihr Programm ausführen.
Haben Sie jemals Dateien mit der Erweiterung
.pyc oder dem Ordner
__pycache__ ? Sie enthalten denselben Bytecode, der von der virtuellen Maschine interpretiert wird.
Es ist wichtig zu beachten, dass es neben CPython noch andere Python-Implementierungen gibt. Wenn Sie beispielsweise
IronPython verwenden, wird Python-Code in eine Microsoft CLR-Anweisung kompiliert. In
Jython wird Code in Java-Bytecode kompiliert und in einer virtuellen Java-Maschine ausgeführt. In der Python-Welt gibt es so etwas wie
PyPy , aber es verdient einen separaten Artikel, deshalb erwähnen wir es hier nur.
In diesem Artikel werde ich mich darauf konzentrieren, wie Speicherverwaltungsmechanismen in der Python-Referenzimplementierung CPython funktionieren.
Es sollte beachtet werden, dass, obwohl das meiste, worüber wir hier sprechen werden, für neue Versionen von Python zutreffen wird, sich die Dinge in Zukunft ändern können. Beachten Sie daher, dass ich mich in diesem Artikel auf die neueste Version von Python zum Zeitpunkt des Schreibens konzentriere -
Python 3.7 .
Das CPython-Softwarepaket ist also in C geschrieben und interpretiert Python-Bytecode. Was hat das mit Speicherverwaltung zu tun? Tatsache ist, dass die für die Speicherverwaltung verwendeten Algorithmen und Datenstrukturen im CPython-Code vorhanden sind, der, wie bereits erwähnt, in C geschrieben wurde. Um zu verstehen, wie die Speicherverwaltung in Python funktioniert, müssen Sie zunächst ein wenig über CPython verstehen.
Die C-Sprache, in der CPython geschrieben ist, unterstützt keine objektorientierte Programmierung. Aus diesem Grund werden im CPython-Code viele interessante Architekturlösungen verwendet.
Sie haben vielleicht gehört, dass alles in Python ein Objekt ist, auch primitive Datentypen wie
int und
str . Dies ist in der Tat auf der Ebene der Sprachimplementierung in CPython der Fall. Es gibt eine Struktur namens
PyObject , die von in CPython erstellten Objekten verwendet wird.
Eine Struktur ist ein zusammengesetzter Datentyp, der Daten verschiedener Typen gruppieren kann. Wenn Sie dies mit objektorientierter Programmierung vergleichen, ähnelt die Struktur einer Klasse, die Attribute, aber keine Methoden aufweist.
PyObject ist der Vorfahr aller Python-Objekte. Diese Struktur enthält nur zwei Felder:
ob_refcnt - Referenzzähler.ob_type - Zeiger auf einen anderen Typ.
Der Referenzzähler wird verwendet, um den Speicherbereinigungsmechanismus zu implementieren. Ein weiteres
PyObject Feld ist ein Zeiger auf einen bestimmten Objekttyp. Dieser Typ wird durch eine andere Struktur dargestellt, die das Python-Objekt beschreibt (z. B. kann es sich um einen
dict oder einen
int ).
Jedes Objekt verfügt über einen eigenen, für ein solches Objekt eindeutigen Speicherzuweisungsmechanismus, der weiß, wie der zum Speichern dieses Objekts erforderliche Speicher abgerufen wird. Darüber hinaus verfügt jedes Objekt über einen eigenen Mechanismus zum Freigeben von Speicher, der den Speicher "freigibt", nachdem er nicht mehr benötigt wird.
Es ist jedoch zu beachten, dass bei all diesen Gesprächen über die Zuweisung und Freigabe von Speicher ein wichtiger Faktor vorhanden ist. Tatsache ist, dass der Computerspeicher eine gemeinsam genutzte Ressource ist. Wenn gleichzeitig zwei verschiedene Prozesse versuchen, etwas in denselben Speicherbereich zu schreiben, kann etwas Schlimmes passieren.
Interpreter Global Lock
Global Interpreter Lock (GIL) ist eine Lösung für ein häufiges Problem, das beim Arbeiten mit gemeinsam genutzten Computerressourcen wie Speicher auftritt. Wenn zwei Threads gleichzeitig versuchen, dieselbe Ressource zu ändern, können sie miteinander "kollidieren". Das Ergebnis wird ein Chaos sein und keiner der Streams wird das erreichen, wonach er strebte.
Kehren wir noch einmal zur Buchanalogie zurück. Stellen Sie sich vor, zwei Autoren hätten willkürlich entschieden, dass sie nun an der Reihe sind, sich Notizen zu machen. Sie beschlossen aber auch, gleichzeitig Notizen auf derselben Seite zu machen.
Jeder von ihnen achtet nicht darauf, dass der andere versucht, seine Geschichte zu schreiben. Zusammen beginnen sie, Text auf die Seite zu schreiben. Infolgedessen werden dort zwei Geschichten übereinander aufgezeichnet, wodurch die Seite vollständig unlesbar wird.
Eine der Lösungen für dieses Problem ist ein einzelner globaler Interpreter-Mechanismus, der gemeinsam genutzte Ressourcen blockiert, mit denen ein bestimmter Thread arbeitet. In unserem Beispiel ist dies ein „Mechanismus“, der die Seite eines Buches „blockiert“. Ein solcher Mechanismus beseitigt die oben beschriebene Situation, in der zwei Autoren gleichzeitig Text auf dieselbe Seite schreiben.
Der GIL-Mechanismus in Python erreicht dies, indem er den gesamten Interpreter blockiert. Infolgedessen kann nichts den Betrieb des aktuellen Threads stören. Wenn CPython mit Speicher arbeitet, verwendet es die GIL, um sicherzustellen, dass diese Arbeit sicher und effizient ausgeführt wird.
Dieser Ansatz hat Stärken und Schwächen, und die GIL ist Gegenstand heftiger Debatten in der Python-Community. Um mehr über GIL zu erfahren, können Sie sich
dieses Material ansehen.
Müllabfuhr
Kehren wir zur Buchanalogie zurück und stellen uns vor, dass einige der in diesem Buch aufgezeichneten Geschichten hoffnungslos veraltet sind. Niemand liest sie, niemand erwähnt sie irgendwo. Und wenn niemand Material in seinen Werken liest oder darauf verweist, kann dieses Material entsorgt werden, um Platz für neue Texte zu schaffen.
Diese alten, vergessenen Geschichten können mit Python-Objekten verglichen werden, deren Referenzanzahl Null ist. Dies sind die gleichen Zähler, über die wir bei der Erörterung der
PyObject Struktur gesprochen haben.
Der Verbindungszähler wird aus mehreren Gründen erhöht. Beispielsweise wird der Zähler inkrementiert, wenn das in einer Variablen gespeicherte Objekt in eine andere Variable geschrieben wird:
numbers = [1, 2, 3]
Sie erhöht sich, wenn das Objekt als Argument an eine Funktion übergeben wird:
total = sum(numbers)
Und hier ist ein weiteres Beispiel für eine Situation, in der die Zahl im Referenzzähler zunimmt. Dies geschieht, wenn das Objekt in der Liste enthalten ist:
matrix = [numbers, numbers, numbers]
Mit Python kann der Programmierer mithilfe des
sys Moduls den aktuellen Wert des Referenzzählers eines bestimmten Objekts ermitteln. Hierzu wird folgende Konstruktion verwendet:
sys.getrefcount(numbers)
getfefcount() es verwenden, müssen Sie
getfefcount() dass das Übergeben eines Objekts an die Methode
getfefcount() den
getfefcount() um 1 erhöht.
In jedem Fall ist der Referenzzähler größer als 0, wenn das Objekt noch irgendwo im Code verwendet wird. Wenn der Zählerwert auf 0 fällt, kommt eine spezielle Funktion ins Spiel, die den vom Objekt belegten Speicher "freigibt". Dieser Speicher kann dann von anderen Objekten verwendet werden.
Wir stellen uns nun Fragen darüber, was „Speicher freigeben“ ist und wie andere Objekte diesen Speicher nutzen können. Um diese Fragen zu beantworten, sprechen wir über Speicherverwaltungsmechanismen in CPython.
Speicherverwaltungsmechanismen in CPython
Jetzt werden wir darüber sprechen, wie CPython eine Speicherarchitektur hat und wie die Speicherverwaltung dort erfolgt.
Wie bereits erwähnt, gibt es mehrere Abstraktionsebenen zwischen CPython und physischem Speicher. Das Betriebssystem abstrahiert den physischen Speicher und erstellt eine virtuelle Speicherschicht, mit der Anwendungen arbeiten können (dies gilt auch für Python).
Der virtuelle Speichermanager eines bestimmten Betriebssystems weist dem Python-Prozess einen Speicherplatz zu. Die dunkelgrauen Bereiche im folgenden Bild sind die Speicherelemente, die zum Python-Prozess gehören.
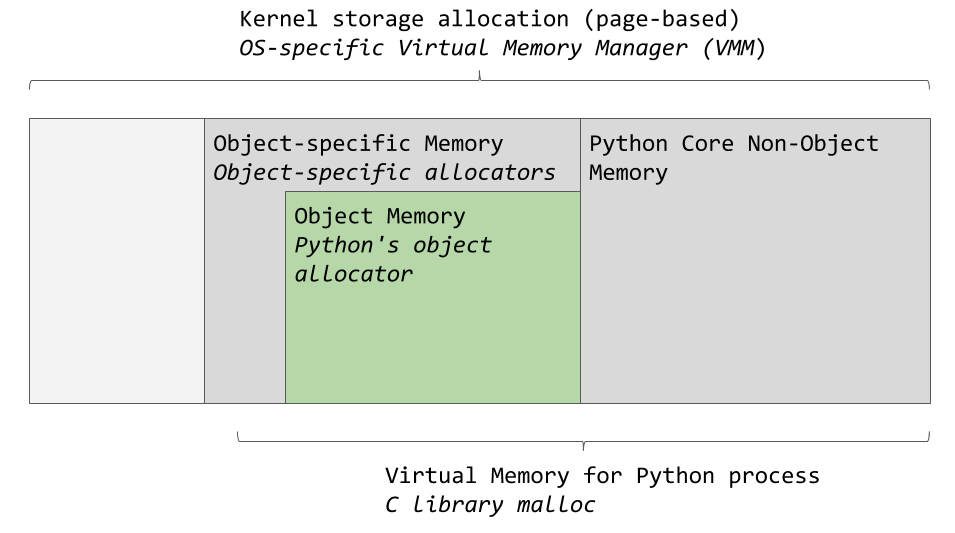 Von CPython verwendete Speicherbereiche
Von CPython verwendete SpeicherbereichePython verwendet eine bestimmte Menge an Speicher für den internen Gebrauch und für Anforderungen, die nicht mit der Zuweisung von Speicher für Objekte zusammenhängen. Ein weiterer Speicher wird zum Speichern von Objekten verwendet (dies sind Werte vom Typ
int ,
dict und ähnliche). Bitte beachten Sie, dass dies ein vereinfachtes Diagramm ist. Wenn Sie das vollständige Bild sehen möchten, schauen Sie sich den Quellcode von
CPython an , in dem alles passiert, worüber wir sprechen.
CPython verfügt über eine Funktion zum Zuweisen von Speicher für Objekte, die für das Zuweisen von Speicher in dem Bereich verantwortlich ist, in dem Objekte gespeichert werden sollen. Das Interessanteste passiert, wenn dieser Mechanismus funktioniert. Es wird aufgerufen, wenn das Objekt Speicher benötigt oder wenn Speicher freigegeben werden muss.
Das Hinzufügen oder Löschen von Daten zu Python-Objekten wie
list und
int normalerweise nicht die gleichzeitige Verarbeitung sehr großer Informationsmengen. Daher ist die Architektur des Speicherzuweisungswerkzeugs mit Blick auf die Verarbeitung kleiner Datenmengen aufgebaut. Darüber hinaus versucht dieses Tool, keinen Speicher zuzuweisen, bis klar wird, dass dies unbedingt erforderlich ist.
Die Kommentare im
Quellcode beschreiben das Speicherzuweisungstool als "schnelles, spezialisiertes Speicherzuweisungstool für kleine Blöcke, das für die Verwendung auf dem universellen Malloc entwickelt wurde". In diesem Fall ist
malloc eine C-Bibliotheksfunktion zum Zuweisen von Speicher.
Lassen Sie uns die von CPython verwendete Speicherzuweisungsstrategie diskutieren. Zunächst werden wir über drei Entitäten sprechen - die sogenannten Blöcke (Blöcke), Pools (Pools) und Arenen (Arena) und wie sie miteinander in Beziehung stehen.
Arenen sind die größten Erinnerungsfragmente. Sie sind an den Rändern der Speicherseiten ausgerichtet. An der Seitengrenze endet der fortlaufende Block des Speichers mit fester Länge, der vom Betriebssystem verwendet wird. Python geht bei der Arbeit mit dem Speicher davon aus, dass die Größe der Systemspeicherseite 256 KB beträgt.
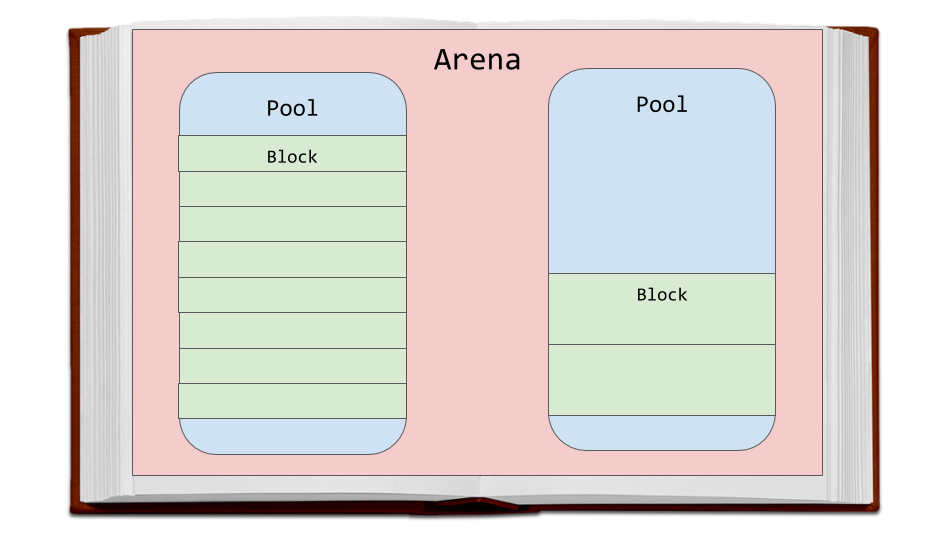 Arenen, Pools und Blöcke
Arenen, Pools und BlöckePools befinden sich in den Arenen, bei denen es sich um 4 KB virtuelle Speicherseiten handelt. Sie ähneln den Seiten des Buches aus unserem Beispiel. Pools sind in kleine Speicherblöcke unterteilt.
Alle Blöcke im selben Pool gehören zur gleichen Größenklasse. Die Größenklasse, zu der der Block gehört, bestimmt die Größe dieses Blocks, der unter Berücksichtigung der angeforderten Speichergröße ausgewählt wird. Hier ist eine Tabelle aus dem Quellcode, die die Datenmenge zeigt, die das System zum Speichern im Speicher anfordert, die Größe der zugewiesenen Blöcke und die Bezeichner der Größenklassen.
Die Datenmenge in Bytes
| Blockgröße
| IDX-Klassengröße
|
1-8
| 8
| 0
|
9-16
| 16
| 1
|
17-24
| 24
| 2
|
25-32
| 32
| 3
|
33-40
| 40
| 4
|
41-48
| 48
| 5
|
49-56
| 56
| 6
|
57-64
| 64
| 7
|
65-72
| 72
| 8
|
...
| ...
| ...
|
497-504
| 504
| 62
|
505-512
| 512
| 63
|
Wenn beispielsweise 42 Bytes zum Speichern angefordert werden, werden Daten in einen 48-Byte-Block gestellt.
Pools
Pools bestehen aus Blöcken derselben Größenklasse. Jeder Pool wird mithilfe des doppelt verknüpften Listenmechanismus anderen Pools zugeordnet, die Blöcke derselben Größenklasse enthalten. Mit diesem Ansatz kann der Speicherzuweisungsalgorithmus leicht freien Speicherplatz für einen Block einer bestimmten Größe finden, selbst wenn es darum geht, freien Speicherplatz in verschiedenen Pools zu finden.
Mit der Liste der verwendeten Pools können Sie alle Pools verfolgen, in denen Platz für Daten einer bestimmten Größenklasse ist. Wenn ein Block einer bestimmten Größe gespeichert werden soll, überprüft der Algorithmus diese Liste auf eine Liste von Pools, in denen Blöcke der erforderlichen Größe gespeichert sind.
Die Pools selbst müssen sich in einem von drei Zuständen befinden. Sie können nämlich verwendet werden (Status
used ), sie können gefüllt (
full ) oder leer (
empty ) sein. Der verwendete Pool verfügt über freie Blöcke, in denen Daten einer geeigneten Größe gespeichert werden können. Alle Blöcke des gefüllten Pools werden für Daten zugeordnet. Ein leerer Pool enthält keine Daten und kann bei Bedarf zum Speichern von Blöcken einer beliebigen Größenklasse zugewiesen werden.
In der Liste der
freepools Pools werden Informationen zu allen Pools
freepools , die sich im
empty Zustand befinden. Wenn beispielsweise in der Liste der verwendeten Pools keine Einträge zu Pools vorhanden sind, in
usedpools 8-Byte-Blöcke gespeichert sind (Klasse mit IDX 0), wird ein neuer Pool initialisiert, der sich im
empty Zustand befindet und zum Speichern solcher Blöcke ausgelegt ist. Dieser neue Pool wird zur Liste der verwendeten Pools hinzugefügt. Er kann verwendet werden, um Anforderungen zum Speichern von Daten zu erfüllen, die nach seiner Erstellung empfangen wurden.
Angenommen, in einem Pool, der sich im
full Zustand befindet, werden einige Blöcke freigegeben. Dies liegt daran, dass die darin gespeicherten Daten nicht mehr benötigt werden. Dieser Pool befindet sich wieder in der Liste der verwendeten
usedpools und kann für Daten der entsprechenden Größenklasse verwendet werden.
Die Kenntnis dieses Algorithmus ermöglicht es uns zu verstehen, wie sich der Status von Pools während des Betriebs ändert (und wie sich Größenklassen ändern, zu denen Blöcke gehören, die in ihnen gespeichert werden können).
Blöcke
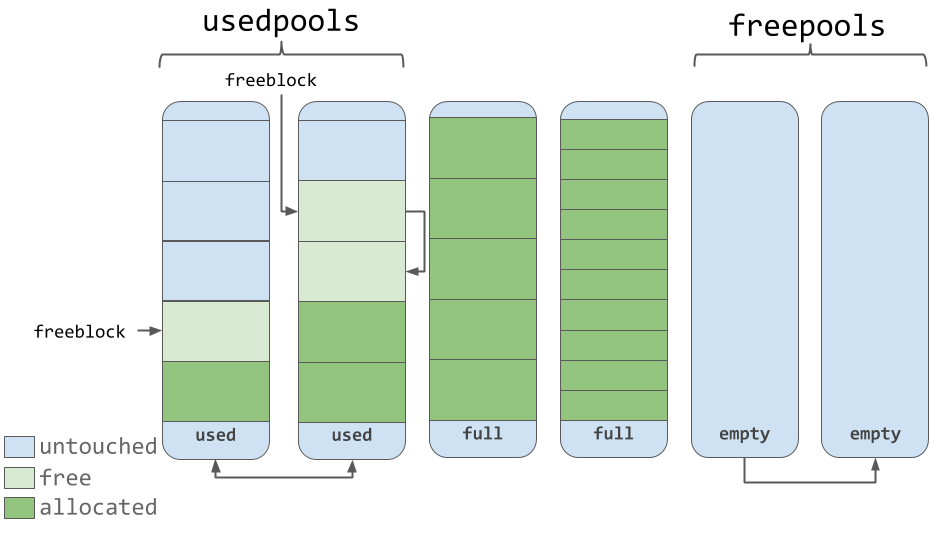 Gebrauchte, volle und leere Pools
Gebrauchte, volle und leere PoolsWie Sie der vorherigen Abbildung entnehmen können, enthalten Pools Zeiger auf die darin enthaltenen "freien" Speicherblöcke. In Bezug auf die Arbeit mit Blöcken sollte ein kleines Merkmal beachtet werden, das im Quellcode angegeben ist. Das in CPython verwendete Speicherverwaltungssystem auf allen Ebenen (Arenen, Pools, Blöcke) ist bestrebt, Speicher nur dann zuzuweisen, wenn dies unbedingt erforderlich ist.
Dies bedeutet, dass Pools Blöcke enthalten können, die sich in einem von drei Zuständen befinden:
untouched ist der Teil des Speichers, der noch nicht zugewiesen wurde.free - der Teil des Speichers, der bereits zugewiesen wurde, aber später von CPython "frei" gemacht wurde und keine wertvollen Daten mehr enthält.allocated ist der Teil des Speichers, der wertvolle Daten enthält.
Der
freeblock Zeiger zeigt auf eine einfach verknüpfte Liste von Free-Memory-Blöcken. Mit anderen Worten, dies ist eine Liste von Orten, an denen Sie Daten ablegen können. Wenn mehr als ein freier Block zum Platzieren von Daten benötigt wird, nimmt das Speicherzuweisungstool mehrere Blöcke aus dem Pool, die sich im
untouched Zustand befinden.
Wenn das Speicherverwaltungstool die Blöcke "frei" macht, gelangen sie, wenn sie den
free Zustand erhalten, an die Spitze der Liste der
free freeblock . Die in dieser Liste enthaltenen Blöcke stellen nicht notwendigerweise einen zusammenhängenden Speicherbereich dar, der dem in der vorherigen Abbildung gezeigten ähnlich ist. Sie können tatsächlich wie die folgende aussehen.
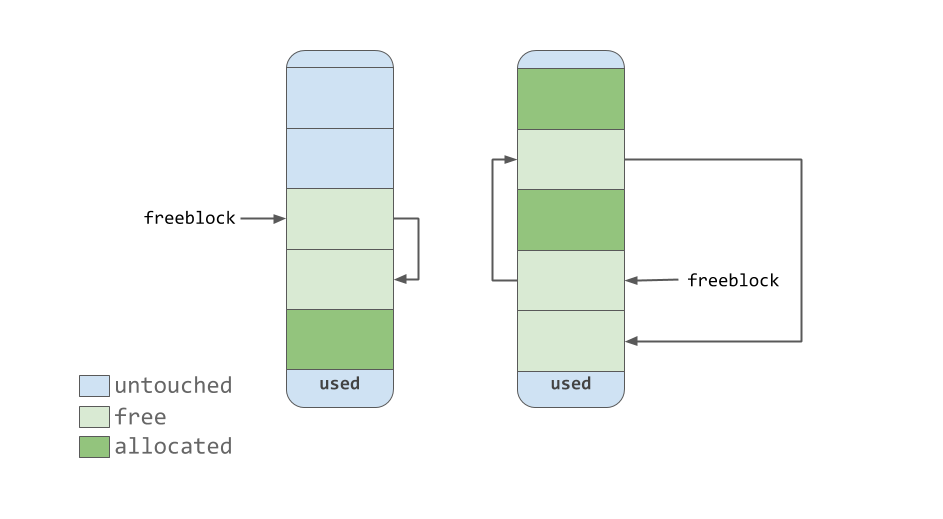 Einzelne verknüpfte Freeblock-Liste
Einzelne verknüpfte Freeblock-ListeArenen
Arenen enthalten Pools. Diese Pools können sich, wie bereits erwähnt, im
used ,
full oder
empty Zustand befinden. Es sollte beachtet werden, dass Arenen keine ähnlichen Zustände haben wie Pools.
Arenen sind in einer doppelt verknüpften Liste mit dem Namen
usable_arenas . Diese Liste ist nach der Anzahl der verfügbaren freien Pools sortiert. Je weniger freie Pools in der Arena vorhanden sind, desto näher steht die Arena an der Spitze der Liste.
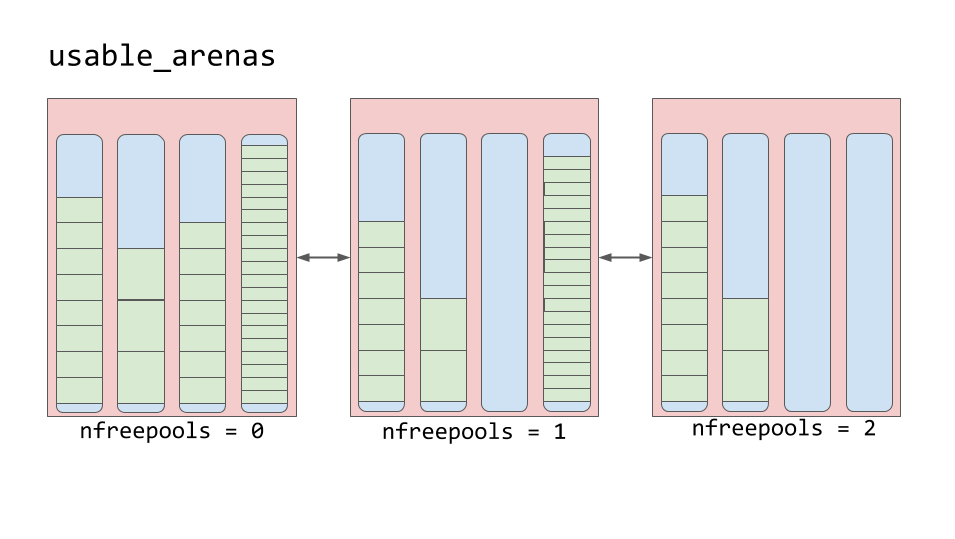 Usable_arenas Liste
Usable_arenas ListeDies bedeutet, dass die Arena, die stärker ist als andere, die mit Daten gefüllt sind, ausgewählt wird, um neue Daten darin zu platzieren. Und warum nicht umgekehrt? Warum nicht neue Daten in der Arena mit dem meisten freien Speicherplatz veröffentlichen?
Tatsächlich führt uns diese Funktion zu der Idee, Speicher wirklich freizugeben. Möglicherweise haben Sie bemerkt, dass wir hier häufig das Konzept der „Speicherfreigabe“ verwendet haben, das in Anführungszeichen gesetzt ist. Der Grund, warum dies getan wurde, ist, dass, obwohl der Block als "frei" betrachtet werden kann, der Speicher, den er darstellt, nicht tatsächlich an das Betriebssystem zurückgegeben wird. Der Python-Prozess enthält diesen Speicher und verwendet ihn später zum Speichern neuer Daten. Die wahre Freigabe des Speichers ist die Rückgabe des Betriebssystems, das davon profitieren kann.
Arenen sind die einzige Einheit in dem hier betrachteten Schema, deren Gedächtnis wirklich freigesetzt werden kann. Der gesunde Menschenverstand schreibt vor, dass das oben beschriebene Schema der Arbeit mit Arenen darauf abzielt, dass die fast leeren Arenen vollständig leer werden. Mit diesem Ansatz kann der Speicherplatz, der durch eine vollständig leere Arena dargestellt wird, wirklich freigegeben werden, wodurch der von Python verbrauchte Speicherplatz reduziert wird.
Zusammenfassung
Folgendes haben Sie beim Lesen dieses Materials gelernt:
- Was ist Speicherverwaltung und warum ist sie wichtig?
- Wie die in der Programmiersprache C geschriebene Referenzimplementierung von Python, Cpython, angeordnet ist.
- Welche Datenstrukturen und Algorithmen werden in CPython für die Speicherverwaltung verwendet?
Die Speicherverwaltung ist ein wesentlicher Bestandteil der Arbeit von Computerprogrammen. Python löst fast alle Speicherverwaltungsaufgaben, die vom Programmierer nicht bemerkt werden. Mit Python kann jeder, der in dieser Sprache schreibt, die vielen kleinen Details im Zusammenhang mit der Arbeit mit Computern ignorieren. Dies gibt dem Programmierer die Möglichkeit, auf einer höheren Ebene zu arbeiten und seinen eigenen Code zu erstellen, ohne sich Gedanken darüber zu machen, wo seine Daten gespeichert sind.
Liebe Leser! Wenn Sie Erfahrung mit der Python-Entwicklung haben, teilen Sie uns bitte mit, wie Sie die Speichernutzung in Ihren Programmen angehen. Versuchen Sie zum Beispiel, es zu speichern?
