Fast alle Empfehlungssysteme haben Schwierigkeiten mit neuen oder seltenen Inhalten - da nur ein kleiner Teil der Benutzer damit interagierte. In seinem Bericht im
Yandex Inside teilte Daniil Burlakov eine Reihe von Tricks mit, die in den Empfehlungen der Musik verwendet werden, und erläuterte das beliebte Modell Singular Value Decomposition (SVD).
Außerdem haben wir solche Künstler, die Komponisten genannt werden und normalerweise von Copyright-Inhabern wie ein Fan niedergeschrieben werden. Nur Mozart hatte mehr als eine Million Kompositionen „aufgenommen“.
- Hallo allerseits! Mein Name ist Daniil Burlakov, ich leite ein Team von Empfehlungen in Media Services. Heute möchte ich über einige der Probleme sprechen, die wir lösen, wenn wir uns mit Empfehlungen in der Musik befassen.
Wir haben ein wunderbares Team, das Empfehlungen nicht nur für Yandex.Music, sondern auch für alle Mediendienste abgibt: Dies ist Kinopoisk, Poster. Wir lösen viel mehr technische Probleme als Empfehlungen.

Heute möchte ich über das zentrale Produkt Yandex.Music sprechen. Unser wichtigstes und beliebtestes Produkt sind intelligente Wiedergabelisten, die wahrscheinlich viele von Ihnen kennen und hören.

Ich werde kurz darauf eingehen, um welche Art von Wiedergabelisten es sich handelt und mit welchen Inhalten wir sie füllen.
Die Wiedergabeliste des Tages wurde als eine Reihe von Titeln konzipiert, die jeden Tag für Sie erstellt werden, damit Sie sie herunterladen und anhören können, auch wenn kein Internet vorhanden ist. Aber es wird großartig für Sie sein, es wird bei Ihnen sein, und es sollte jeden Tag aktualisiert werden und etwas Neues enthalten. Was passt zu dir?
Deja Vu ist eine interessantere Wiedergabeliste. Es wird einmal pro Woche aktualisiert, und es gibt Titel, die Sie nie gehört haben, und Künstler, die Sie praktisch nicht oder gar nicht kennen. Premiere - eine Auswahl neuer Produkte Ihrer Künstler, die Ihnen gefallen könnten.

Das zweite Produkt ist Yandex.Radio. Im Jahr 2015 wurde es gestartet, wir entwickeln es weiter.
Die Idee ist, dem Benutzer zu ermöglichen, einen personalisierten Strom von Audiomusik zu erhalten, ohne etwas zu tun. Tatsächlich habe ich einen Knopf gedrückt und einen wunderbaren Stream erhalten, der niemals enden wird und Sie viele Stunden lang erfreuen wird. Im Gegensatz zu Wiedergabelisten kann es bereits markiert werden. Sie können beispielsweise das Radio nach Genre - Rock oder Hintergrundmusik - einschalten, wenn Sie während der Arbeit nicht abgelenkt werden möchten. Oder ein vollständig personalisierter Audiostream - das nennen wir das Radio „On Your Wave“.

Welche Probleme haben wir, wenn wir diese Empfehlungen aussprechen? Wir stehen vor zwei Hauptproblemen, die für die meisten Empfehlungssysteme typisch sind. Dies sind kalte Benutzer, die gerade zu unserem Service gekommen sind und über die wir noch nichts wissen, und coole Inhalte. Es enthält nicht nur Titel, die kürzlich erschienen sind, sondern auch eine große Anzahl seltener Titel. Der Yandex.Music-Katalog enthält mehr als 50 Millionen Titel, von denen viele noch von keinem Benutzer angehört wurden. Daher tritt ein Problem auf: Selbst wenn der Track lange genug herauskam, wissen wir leider nichts über diesen Track und haben keine Statistiken.
Beide Probleme verschärften sich besonders und wurden für uns besonders wichtig, da Yandex.Music zu einem internationalen Dienst wurde und in viele Länder ging. Bei der Einreise in jedes Land wird vor allem der lokale Inhalt dieses Landes sehr wichtig. Es ist klar, dass es bei der Einreise in ein neues Land eher unangenehm ist, lokale Musik zu ignorieren. Es ist notwendig, es zu empfehlen, angemessen zu empfehlen und die Struktur dieser internen Musik zu verstehen. Tatsächlich hört in Russland niemand israelische Musik, und es gibt nur sehr wenige Statistiken darüber, selbst wenn wir diesen Inhalt haben.
Lassen Sie uns diese Themen durchgehen. Beginnen wir mit dem Problem der kalten Benutzer. Wie kann es gelöst werden?

Die erste einfachste Lösung besteht darin, kalten Benutzern nichts zu empfehlen. In der Tat ist die Lösung sehr einfach, Sie können nur nach expliziten Einstellungen fragen. Dies sind zahlreiche Assistenten, die dem Benutzer zur Verfügung gestellt werden können.
Bevor der Benutzer seine erste Wiedergabeliste des Tages erhält, bitten wir ihn, einen solchen Assistenten durchzugehen und seine Vorlieben, eine Reihe von Genres und Künstlern anzugeben, die er möchte.
Infolgedessen wird die erste Wiedergabeliste des Benutzers sehr aussagekräftig, für den Benutzer geeignet, und höchstwahrscheinlich wird sich der Benutzer von der ersten Wiedergabeliste an in ihn verlieben.
Leider kann dieser Ansatz nicht immer durchgeführt werden.

Unser zweites Produkt, Yandex.Radio, wurde als ein Produkt konzipiert, das keine Anstrengung des Benutzers erfordert. Er will nur kommen und die Musik einschalten, ohne etwas zu tun. Darüber hinaus ist Yandex.Radio in viele andere Systeme wie Yandex.Drive eingebettet, in denen es ziemlich seltsam und unpraktisch ist, den Benutzer einfach zu zwingen, im Auto zu sitzen. Klicken Sie auf einen Assistenten, wenn er dort ankommt.
Deshalb sind wir den anderen Weg gegangen. Wir beginnen mit Empfehlungen, sagen wir, für den durchschnittlichen Benutzer, damit die meisten Benutzer aus den ersten Tracks maximale Freude haben und die Musik mögen. Und wir bieten eine sehr schnelle Personalisierung. Im Gegensatz zu der Wiedergabeliste, die Sie erhalten haben und die er den ganzen Tag bei Ihnen hat, sind alle Ihre 60 Titel. Und wenn wir zum Beispiel nicht mit der Tatsache geraten haben, dass Ihr Lieblingsgenre populäre Musik ist (was für den Anfang eine gute Vermutung sein wird), dann werden alle 60 Tracks nicht über Sie handeln, und es wird traurig sein, und höchstwahrscheinlich werden Sie es morgen nicht tun komm zurück
Wenn wir jedoch den ersten Titel populärer Musik ins Radio stellen und Sie sagen, dass Sie ihn nicht hören möchten, werden wir den nächsten Titel sofort für Sie personalisieren und etwas anderes anbieten, zum Beispiel Rock oder ein anderes Genre.
Tatsächlich schließen diese beiden Lösungen das Problem der kalten Benutzer auf die eine oder andere Weise.
Wie könnte das Inhaltsproblem analog gelöst werden? Lösung Nummer eins sowie über Benutzer ist, coole Inhalte nicht zu empfehlen. Aber hier wird im Gegensatz zu Benutzern der Inhalt selbst nicht aufgenommen und nicht erwärmt. Das Problem ist also, dass, wenn wir selbst keine Statistiken über ihn sammeln, das neue Produkt des Künstlers, das gerade veröffentlicht wurde, nicht geliefert wird und Benutzer, die die Nachrichten ihres Künstlers nicht gesehen haben, höchstwahrscheinlich verärgert sind.

Eine ähnliche Situation mit internationalen Inhalten. Wir sind in ein neues Land gegangen und haben es nicht empfohlen. Das Ignorieren dieses Inhalts passt natürlich nicht zu uns.
Die zweite Lösung, wenn wir völlig analog handeln, empfehlen sie im Durchschnitt irgendwie. Die einfachste Analogie besteht darin, diesen Inhalt jedem in einer Reihe zu überlassen oder ihn als populäre Musik zu empfehlen. Mit der Option, im Durchschnitt zu empfehlen, ist im Allgemeinen nicht sehr klar, was durchschnittliche Musik ist. Dies kann mit Gewalt als populäre Musik bezeichnet werden, aber es kann kaum gesagt werden, dass alle Musik einander so ähnlich ist, dass sie wie populäre Musik aussieht. Wenn Sie also eine Beethoven-Komposition zwischen populärer Musik finden, ist es unwahrscheinlich, dass sich die meisten Menschen darüber freuen. Daher passt diese Lösung auch nicht zu uns.

Was gibt es sonst noch an den Tracks? Zusammen mit dem Titel selbst kommen viele Metadaten vom Inhaber des Urheberrechts zu uns, wie z. B. das Genre des Titels, des Künstlers, des Albums und des Erscheinungsjahres. Lass uns rüber gehen. Wie könnten sie verwendet werden? Zum Beispiel ein Genre. Ein Genre ist eine gute Information, die es uns ermöglicht, mehr oder weniger zu raten. Zum Beispiel löst es das Problem mit Beethoven oder einem Chanson, das möglicherweise versehentlich bei jemandem im Radio aufgetreten ist: Wir kennen das Genre des Tracks und es ist unwahrscheinlich, dass wir es auf diejenigen übertragen, zu denen es nicht passt.
Leider erlaubt er nicht, eine gute Empfehlung zu erstellen, da das Konzept des Genres selbst ziemlich subjektiv ist und es nicht erlaubt, darauf basierend gute Empfehlungen zu erstellen. Natürlich gibt es viele Subgenres innerhalb der Genres, und genau das senden uns Urheberrechtsinhaber.

Das zweite Problem ist, dass ein gewöhnlicher Mensch normalerweise ein Dutzend Genres benennen kann, während Urheberrechtsinhaber uns viele tausend Genres schicken, und dies ist ein Problem, das groß genug ist, um sie irgendwie zu gruppieren, ähnliche zwischen ihnen zu finden und so weiter. Leider ist dieses Problem nicht immer gelöst.
Dann gibt es natürlich Probleme mit der Tatsache, dass Urheberrechtsinhaber leider oft verwirrt sind und Fehler machen. Und wir haben regelmäßig Probleme und Berichte, dass wir Tracks sammeln, die im Radio-Rock beliebt sind, und der Inhaber des Urheberrechts hat das Rock-Genre darauf gesetzt. Analog sammeln wir Jazz und andere Radiosender. Und wir haben regelmäßig Benutzerberichte, die um Korrektur bitten, weil ein fehlerhafter Titel zu diesen Radiosendern geflogen ist.
Ich möchte Ihnen anbieten, das Genre des Tracks zu erraten.
Hören Sie sich den Titel an Dies ist kein Soundtrack. Das ist Metall. Und wir haben ein großes Problem, wenn sie uns solche Markups schicken.
Ich schlage vor, zum nächsten Teil zu gehen und über die Darsteller des Tracks zu sprechen. Ich habe bereits gesagt, dass es ein Problem gibt, dass ein neuer Künstler, ein neuer Titel oder ein neues Album herauskommt, und es sollte empfohlen werden. Insbesondere Informationen über den Künstler werden uns immer retten. Wir wissen, dass der Benutzer diesem Künstler zugehört hat, und wir können ihn ihm entsprechend empfehlen. Also machen wir es. Es gibt jedoch auch Schwierigkeiten. Wenn wir zum Beispiel nichts über den Künstler selbst wussten oder der Benutzer ihm nicht zuhörte, sagen uns die Informationen, die dieser Titel enthält, nichts. Ähnliches gilt für seltene Tracks. Es gab einen seltenen Track von einem seltenen Künstler, wir haben erfahren, dass dieser seltene Track ihm jetzt gehört. Leider gibt es wieder nicht viele Informationen, die es ihm ermöglichen, anderen Personen empfohlen zu werden, die mit seiner Arbeit nicht vertraut sind.

Das zweite Problem sind Cover und Remixe. Auch hier greifen abscheuliche Urheberrechtsinhaber ein und machen oft Fehler. Insbesondere wenn wir einen Original-Track und sein Cover haben, machen sich die Inhaber des Urheberrechts oft nicht die Mühe, diese Tracks auf unterschiedliche Weise zu benennen, zu unterschreiben, dass einer von ihnen ein Remix ist, oder einfach andere Künstler für sie aufzuschreiben, wenn dies der Fall ist.
Ich möchte Ihnen zwei Spuren anbieten, um zu verstehen, wie unterschiedlich der Klang für Spuren ist, die genau gleich heißen. Somit erhalten wir zwei Spuren, die als ähnlich bezeichnet werden können, sie haben einen relativ ähnlichen Rhythmus, einen relativ ähnlichen Text, aber sie sind unterschiedlich. Und für uns ist es ein und derselbe Track, weil Name, Künstler und alles andere genau gleich sind.
Außerdem haben wir so abscheuliche Künstler, die Komponisten genannt werden und normalerweise von Copyright-Inhabern wie ein Fan niedergeschlagen werden. Nur Mozart hatte mehr als eine Million Kompositionen „aufgenommen“. Es ist klar, dass dies für Liebhaber klassischer Musik nicht möglich sein wird. Wenn der Benutzer sagt, dass er Mozart mag, dann haben wir Millionen von Tracks, verschiedene Wiederholungen von klassischen Standardmelodien. Infolgedessen können wir kaum etwas dagegen tun.

Ich möchte Ihnen weiter erläutern, wie dieses Problem gelöst werden könnte, aber lassen Sie uns zunächst unsere Anforderungen lockern. Wir wollten Titel empfehlen, die niemand gehört hat, und jetzt überlegen wir, wie wir nur Titel empfehlen können, die selten sind. Hier hilft uns die kollaborative Filterung. Wie funktioniert es und was bekommen wir am Ende?
Um zu beginnen, müssen wir eine Matrix von Benutzerbewertungen erstellen, in der Benutzer in den Zeilen, Spuren in den Spalten, am Schnittpunkt der Spalte und in der Zeile, in der sich die Bewertung befindet, vorhanden sind. Es ist klar, dass Benutzer für den größten Teil der Matrix, die wir nicht kennen, nicht in der Lage sind, unseren gesamten Katalog zu hören.
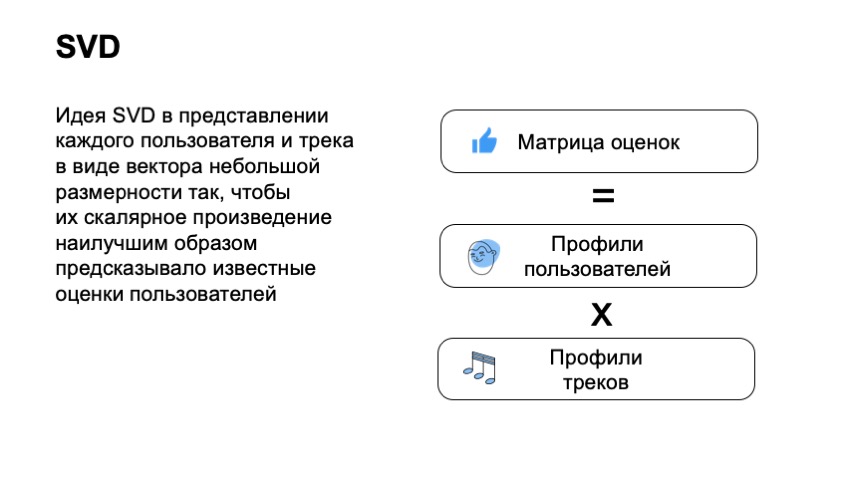
Mit dieser Matrix möchten wir, dass der Benutzer und die Spur kleine Vektoren zuordnen, die kurz genug sind, damit das Skalarprodukt des Benutzervektors und des Elementvektors die Bewertung des Benutzers gut vorhersagen kann. Wir erhalten also, dass wir für jeden Artikel und für jeden Benutzer zwei Vektoren finden müssen, damit das Endprodukt unsere Schätzung am besten vorhersagen kann. Wenn wir in diesem Fall beispielsweise sagen würden, dass der Benutzer die Spur mochte - es ist 1, wenn es ihm nicht gefallen hat - 0. In diesem Fall können wir tatsächlich die Standardtechnik, die SVD-Zerlegung, anwenden und optimale Vektoren für Benutzer und für Spuren erhalten.

Was gibt uns das? Dies gibt uns das nächste große Plus. Für die meisten Ansätze können wir nicht sagen, dass die beiden Tracks ähnlich sind, wenn niemand zusammen zuhört. Normalerweise basiert ein wesentlicher Teil der Ansätze auf der Tatsache, dass wir einige Benutzer haben, die mit Punkt A und B interagiert haben, und wir sehen, dass sie infolgedessen ähnlich sind. Durch kollaboratives Filtern in Form von SVD können wir dies auch dann tun, wenn kein Benutzer zwei Titel zusammen gehört hat. Sie erlauben es uns, es ziemlich gut zu bewerten. Dies ist das erste Plus.
Was gibt uns das? Mit einem Spurvektor können wir ihn einem viel größeren Personenkreis empfehlen und viel weniger beliebte Spuren empfehlen. Und das Hauptplus ist, dass wir immer noch eine Vektordarstellung der Spuren erhalten, mit der Sie sehr bequem arbeiten können, mit der Sie schnell nach ähnlichen Spuren suchen können.
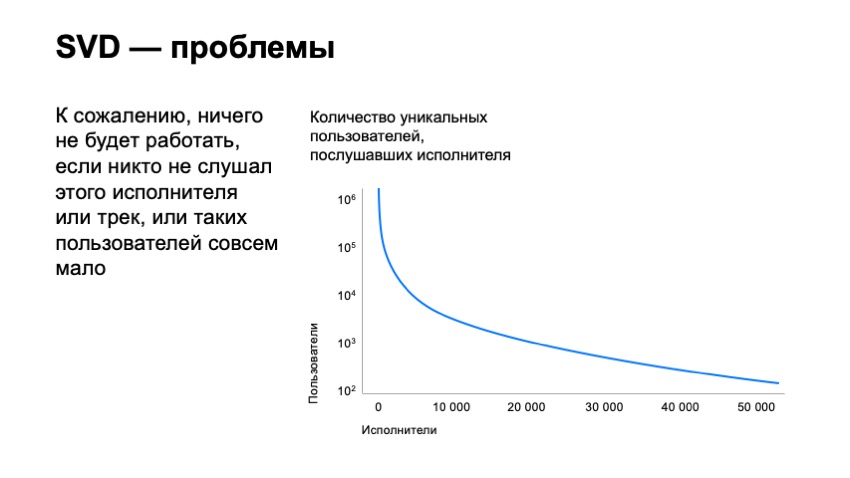
Dies löst jedoch nicht alle unsere Probleme. Wir haben die Leiste für die Anzahl der Tracks, die wir empfehlen können, nur geringfügig verschoben. Wenn wir ein Diagramm der Anzahl der Benutzer erstellen, die den Darstellern zugehört haben, und die Darsteller tatsächlich nach ihrer Beliebtheit sortieren, werden wir feststellen, dass Millionen von Benutzern den Top-Darstellern unseres Dienstes zuhören. Wenn wir uns bereits die zehntausendste Position dieser Künstler ansehen, wird es nur tausend Benutzer geben. Wenn wir uns sogar den 50.000sten Künstler ansehen, wird es nur hundert Benutzer geben. Es ist klar, dass seine Tracks nur Dutzende von Benutzern haben werden, die ihm zugehört haben, was es tatsächlich unmöglich macht, sie zu empfehlen, da der SVD-Vektor für solche Tracks extrem instabil ist und nicht funktioniert.
Wie können wir versuchen, dies zu lösen? Was wollen wir
Wir möchten einen seltenen, neuen Track nehmen, von dem wir nichts wissen, zum Beispiel einen seltenen Track aus Israel, und wir möchten eine Art Vektordarstellung dafür erhalten, die unserem SVD-Vektor sehr ähnlich wäre, mit dem wir sehr bequem arbeiten können und Empfehlungen abgeben.
Das einzige, was wir nicht berücksichtigt haben, ist das Audio dieses Tracks selbst. Dank des Audios können wir die Tracks empfehlen. Wie würden wir mit einer Audiospur einen SVD-Vektor erhalten? Das erste, was wir tun wollen, ist eine kleine Konvertierung.
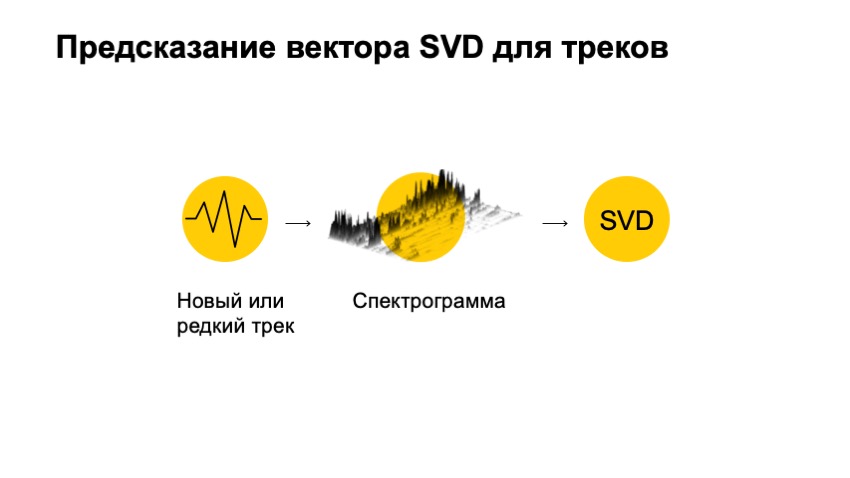
Was ist im Wesentlichen Audio? Sie können sich einen Spannungsgraphen vorstellen. In jedem Fall handelt es sich um eine eindimensionale Menge von Zahlen, deren Arbeit ziemlich unpraktisch ist. Sie ist sehr groß und lang und macht an sich wenig Sinn. Aber wir können sein Spektrum überprüfen und ganz kurz Fourier-Transformationen an ihm vornehmen, um zu sehen, wie sehr er wie eine bestimmte Art von Sinus aussieht. Wie sehr sieht er aus wie eine Art Sinus. Sehen Sie, wie viele Sinuskurven sich in diesem Diagramm befinden, und machen Sie dasselbe für jede der Frequenzen.
Wenn wir dies für den gesamten Track als Ganzes tun, erhalten wir natürlich einige Informationen, aber sehr wenig, es wird sehr wenig aussagen, weil zum Beispiel Übergänge zwischen Teilen des Tracks für die Musik sehr wichtig sind, während wir dies im Spektrum tun werden in indirekter Form eine Änderung sehr großer Frequenzen zu haben, die sich auf Sekunden, Minuten beziehen sollten, und dies ist ziemlich unpraktisch und in Form eines Spektrums schlecht dargestellt.
Deshalb gehen wir weiter und schneiden die Spur in kleine Stücke. In jedem Stück machen wir eine solche Transformation. Als Ergebnis erhalten wir ein solches Bild. Ich habe es in dreidimensionaler Form gezeichnet, damit besser sichtbar ist, dass wir Frequenzen auf einer Ebene in der Zeit und in der Höhe entfaltet haben - der Energie, die zu diesem Zeitpunkt vorhanden war. Und sie haben das sogenannte Spektrogramm bekommen.
Wie würden wir mit diesem Spektrogramm den SVD-Vektor erhalten? Die Antwort in unserer Zeit ist ziemlich banal: Nehmen wir ein neuronales Netzwerk und trainieren es, um den SVD-Vektor vorherzusagen.
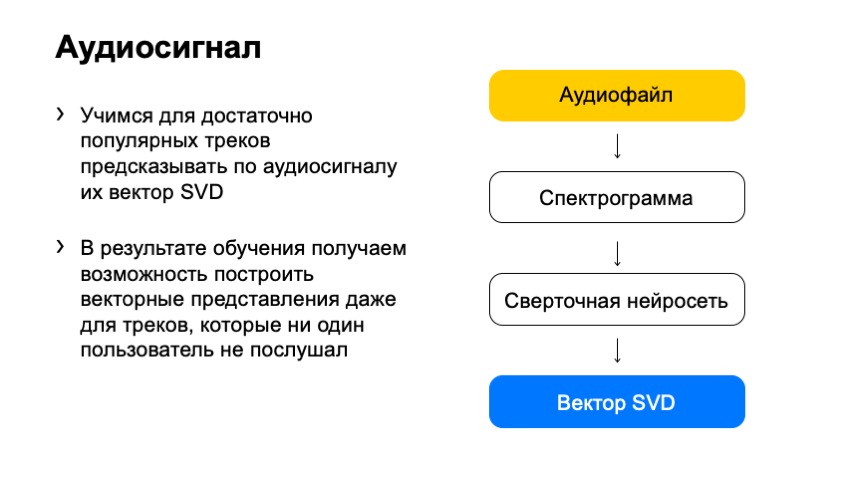
Also haben wir es getan. Was haben wir als Training gewählt? Diese SVD-Spuren, deren Vektor wir sicher kennen. Wir haben speziell beliebte Tracks ausgewählt, deren Feedback groß genug war, damit der SVD-Vektor bereits völlig leise war, und wir konnten ihn klar berechnen. Und - sie trainierten das neuronale Netzwerk, um diese Vektoren vorherzusagen.
Was haben wir am Ende bekommen? Ein Netzwerk, das jede Spur aufnehmen und seinen SVD-Vektor vorhersagen kann. Wir haben eine sehr einfache Lösung, die sehr gut funktioniert.
Ich möchte ein Beispiel für ein Paar Tracks zeigen, die wir herausgezogen haben. Eine dieser Spuren ist sehr beliebt, und ihr SVD-Vektor konnte ziemlich genau erkannt werden, und die zweite ist sehr unbeliebt. Ich möchte vorschlagen, zu erraten, welcher dieser Titel weniger beliebt und welcher beliebter ist.
Erster Track:
Zweiter Track:
Die Antwort
Der erste Titel ist beliebter. Wenn Sie sich die Anzahl der Hörer ansehen, die über diesen Titel Bescheid wussten und ihn ohne die Hilfe von Empfehlungen selbst finden konnten, dann konnte der erste Titel von mehr als 1000 Benutzern gefunden werden und der zweite - nur 10. Und wie wir unsere Technologie angewendet haben, konnten wir nicht Versuchen Sie sogar, diesen Track zu empfehlen, da es nichts gab, an dem Sie sich für Empfehlungen festhalten konnten. Wir konnten es nur diesen 10 Benutzern anbieten.
Als wir dies in der Produktion angewendet haben, haben wir viele großartige Rückmeldungen erhalten. Eine der Wiedergabelisten, "Deja Vu", in die Titel eingebettet werden müssen, die der Benutzer nicht gehört hat, um die Erkennung für den Benutzer zu organisieren, hat sich erheblich verbessert, nachdem wir diese Technologie anwenden konnten.
Natürlich haben wir dies bei der Einreise in neue Länder angewendet und auch viele positive Bewertungen erhalten. Sie stellten fest, dass Wiedergabelisten wissen, wie man gut personalisiert. Darüber hinaus waren die Redakteure in Israel ziemlich überrascht, dass der russische Dienst in Israel keine russischen Künstler in großen Mengen empfiehlt, sondern lokale Musik und internationale Musik.

Über die Zahlen, die wir erreicht haben. Vor allem wollten wir die Anzahl der neuen Produkte für Benutzer im Audiostream erreichen, damit dieser vielfältiger wird. , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . Vielen Dank für Ihre Aufmerksamkeit.