In den letzten 7 Jahren habe ich zusammen mit dem Team den Kern des Miro-Produkts (ex-RealtimeBoard) unterstützt und weiterentwickelt: Client-Server- und Cluster-Interaktion mit der Datenbank.
Wir haben Java mit verschiedenen Bibliotheken an Bord. Alles wird außerhalb des Containers über das Maven-Plugin gestartet. Es basiert auf der Plattform unserer Partner, die es uns ermöglicht, mit der Datenbank und den Flows zu arbeiten, die Client-Server-Interaktion zu verwalten usw. DB - Redis und PostgreSQL (mein Kollege
hat darüber geschrieben, wie wir von einer Datenbank in eine andere wechseln ).
In Bezug auf die Geschäftslogik enthält die Anwendung:
- mit benutzerdefinierten Boards und deren Inhalten arbeiten;
- Funktionen zur Benutzerregistrierung, Erstellung und Verwaltung von Boards;
- Benutzerdefinierter Ressourcengenerator. Beispielsweise werden große Bilder optimiert, die in die Anwendung hochgeladen werden, damit sie für unsere Kunden nicht langsamer werden.
- viele Integrationen mit Diensten von Drittanbietern.
Im Jahr 2011, als wir gerade anfingen, befand sich der gesamte Miro auf demselben Server. Alles war drauf: Nginx, auf dem PHP für eine Site gedreht wurde, eine Java-Anwendung und Datenbanken.
Das entwickelte Produkt, die Anzahl der Benutzer und der Inhalt, den sie den Boards hinzufügten, nahmen zu, sodass auch die Belastung des Servers zunahm. Aufgrund der großen Anzahl von Anwendungen auf unserem Server konnten wir zu diesem Zeitpunkt nicht verstehen, was genau die Last ergibt, und konnten sie dementsprechend nicht optimieren. Um dies zu beheben, haben wir alles in verschiedene Server aufgeteilt und einen Webserver, einen Server, erhalten mit unserem Anwendungs- und Datenbankserver.
Leider traten nach einiger Zeit wieder Probleme auf, da die Belastung der Anwendung weiter zunahm. Dann haben wir darüber nachgedacht, wie die Infrastruktur skaliert werden kann.

Als Nächstes werde ich auf die Schwierigkeiten eingehen, die bei der Entwicklung von Clustern und der Skalierung von Java-Anwendungen und -Infrastruktur aufgetreten sind.
Infrastruktur horizontal skalieren
Wir haben zunächst Metriken gesammelt: die Verwendung von Speicher und CPU, die Zeit, die zum Ausführen von Benutzerabfragen benötigt wird, die Verwendung von Systemressourcen und die Arbeit mit der Datenbank. Aus den Metriken ging hervor, dass die Generierung von Benutzerressourcen ein unvorhersehbarer Prozess war. Wir können den Prozessor zu 100% laden und einige zehn Sekunden warten, bis alles erledigt ist. Benutzeranfragen für Boards führten manchmal auch zu einer unerwarteten Belastung. Zum Beispiel, wenn ein Benutzer tausend Widgets auswählt und sie spontan verschiebt.
Wir begannen darüber nachzudenken, wie diese Teile des Systems skaliert werden können, und kamen zu offensichtlichen Lösungen.
Skalieren Sie die Arbeit mit Boards und Inhalten . Der Benutzer öffnet die Karte folgendermaßen: Der Benutzer öffnet den Client → gibt an, welche Karte er öffnen möchte → stellt eine Verbindung zum Server her → ein Stream wird auf dem Server erstellt → alle Benutzer dieser Karte stellen eine Verbindung zu einem Stream her → jede Änderung oder Erstellung des Widgets erfolgt innerhalb dieses Streams. Es stellt sich heraus, dass alle Arbeiten mit der Karte streng durch den Fluss begrenzt sind, was bedeutet, dass wir diese Flüsse auf die Server verteilen können.
Skalieren Sie die Generierung von Benutzerressourcen . Wir können den Server herausnehmen, um Ressourcen separat zu generieren, und er empfängt Nachrichten zur Generierung und antwortet dann, dass alles generiert wird.
Alles scheint einfach zu sein. Sobald wir uns jedoch eingehender mit diesem Thema befassten, stellte sich heraus, dass wir zusätzlich einige indirekte Probleme lösen mussten. Wenn beispielsweise ein kostenpflichtiges Abonnement für Benutzer abläuft, müssen wir sie darüber informieren, unabhängig davon, auf welchem Board sie sich befinden. Wenn der Benutzer die Version der Ressource aktualisiert hat, müssen Sie sicherstellen, dass der Cache auf allen Servern korrekt geleert ist und wir die richtige Version angeben.
Wir haben Systemanforderungen identifiziert. Der nächste Schritt besteht darin, zu verstehen, wie dies in die Praxis umgesetzt werden kann. Tatsächlich brauchten wir ein System, mit dem die Server im Cluster miteinander kommunizieren können und auf dessen Grundlage wir alle unsere Ideen verwirklichen können.
Der erste sofort einsatzbereite Cluster
Wir haben die erste Version des Systems nicht ausgewählt, da sie bereits teilweise in der von uns verwendeten Partnerplattform implementiert war. Darin waren alle Server über TCP miteinander verbunden, und über diese Verbindung konnten wir RPC-Nachrichten gleichzeitig an einen oder alle Server senden.
Zum Beispiel haben wir drei Server, die über TCP miteinander verbunden sind, und in Redis haben wir eine Liste dieser Server. Wir starten einen neuen Server im Cluster → er fügt sich der Liste in Redis hinzu → liest die Liste, um Informationen zu allen Servern im Cluster zu erhalten → stellt eine Verbindung zu allen her.
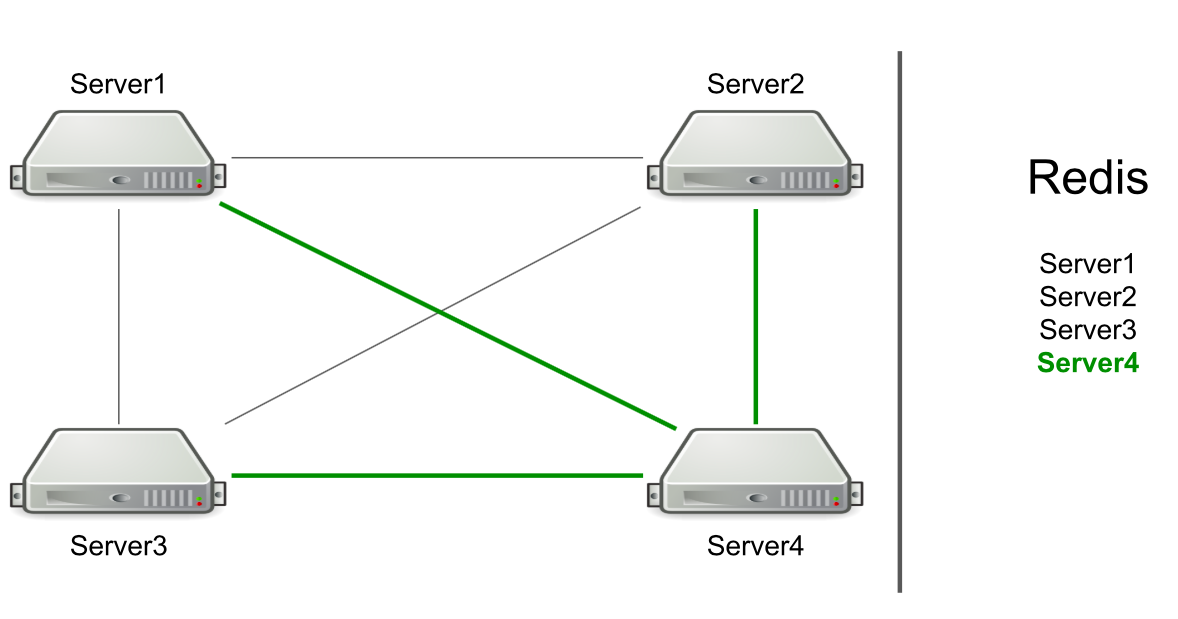
Basierend auf RPC wurde bereits die Unterstützung für das Leeren des Caches und das Umleiten von Benutzern auf den gewünschten Server implementiert. Wir mussten eine Generation von Benutzerressourcen erstellen und Benutzer darüber informieren, dass etwas passiert war (z. B. war ein Konto abgelaufen). Um Ressourcen zu generieren, haben wir einen beliebigen Server ausgewählt und ihm eine Anfrage zur Generierung gesendet. Für Benachrichtigungen über den Ablauf eines Abonnements haben wir einen Befehl an alle Server gesendet, in der Hoffnung, dass die Nachricht das Ziel erreicht.
Der Server selbst bestimmt, an wen die Nachricht gesendet werden soll.
Es klingt wie eine Funktion, kein Problem. Der Server konzentriert sich jedoch nur auf die Verbindung zu einem anderen Server. Wenn es Verbindungen gibt, gibt es einen Kandidaten zum Senden einer Nachricht.
Das Problem ist, dass Server Nummer 1 nicht weiß, dass Server Nummer 4 derzeit unter hoher Last steht und nicht schnell genug antworten kann. Infolgedessen werden Server-1-Anforderungen langsamer verarbeitet als sie könnten.
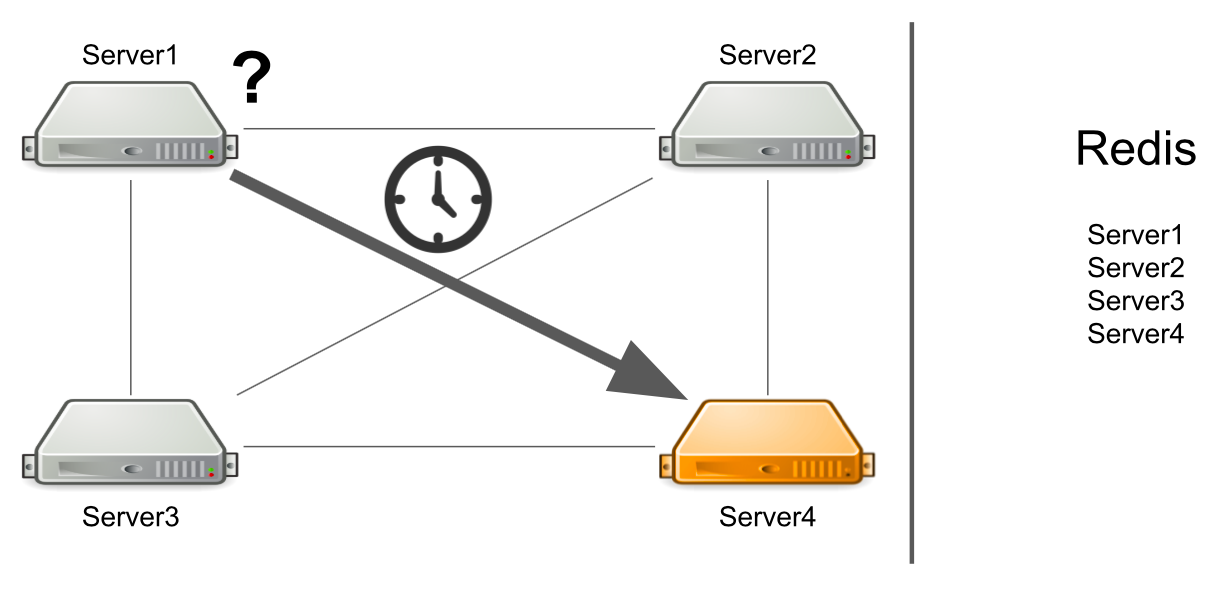
Der Server weiß nicht, dass der zweite Server eingefroren ist
Was aber, wenn der Server nicht nur stark ausgelastet ist, sondern im Allgemeinen einfriert? Außerdem hängt es so, dass es nicht mehr zum Leben erweckt wird. Zum Beispiel habe ich den gesamten verfügbaren Speicher erschöpft.
In diesem Fall weiß Server 1 nicht, wo das Problem liegt, und wartet weiterhin auf eine Antwort. Die verbleibenden Server im Cluster wissen auch nichts über die Situation mit Server Nr. 4, daher senden sie viele Nachrichten an Server Nr. 4 und warten auf eine Antwort. So wird es sein, bis Server Nummer 4 stirbt.
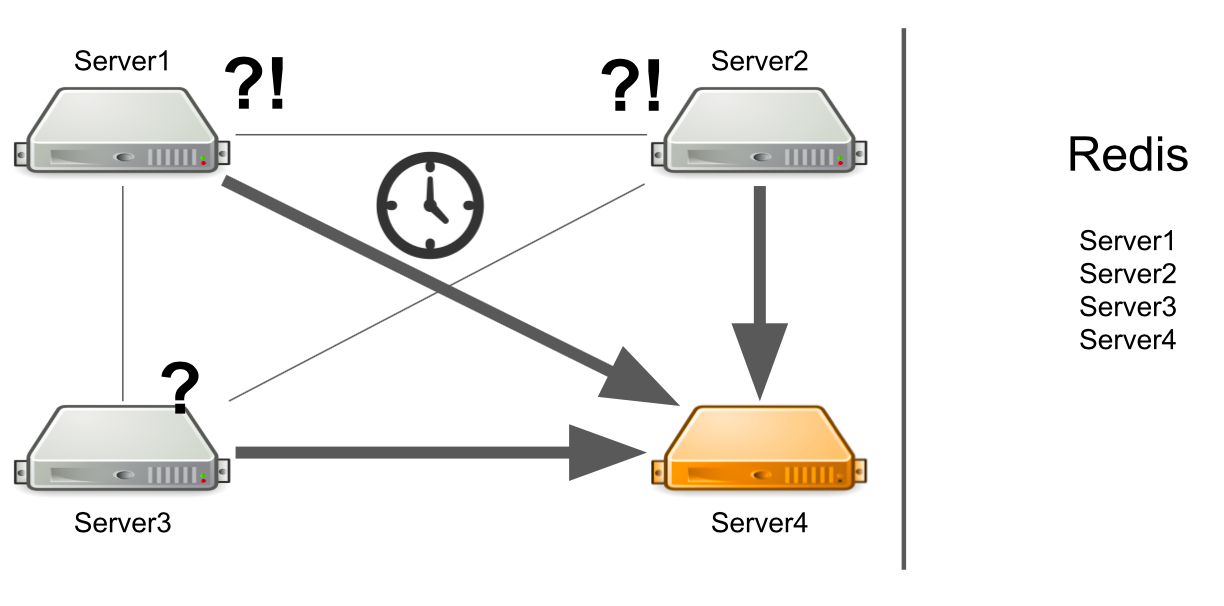
Was zu tun ist? Wir können dem System unabhängig eine Serverstatusprüfung hinzufügen. Oder wir können Nachrichten von "kranken" Servern auf "gesunde" umleiten. All dies wird den Entwicklern zu viel Zeit kosten. Im Jahr 2012 hatten wir wenig Erfahrung in diesem Bereich und suchten nach vorgefertigten Lösungen für alle unsere Probleme gleichzeitig.
Nachrichtenbroker. Activemq
Wir haben uns entschlossen, in Richtung Message Broker zu gehen, um die Kommunikation zwischen Servern korrekt zu konfigurieren. Sie entschieden sich für ActiveMQ, da der Empfang von Nachrichten auf dem Consumer zu einem bestimmten Zeitpunkt konfiguriert werden kann. Wir haben diese Gelegenheit zwar nie genutzt, also könnten wir uns zum Beispiel für RabbitMQ entscheiden.
Infolgedessen haben wir unser gesamtes Clustersystem auf ActiveMQ übertragen. Was gab es:
- Der Server bestimmt nicht mehr selbst, an wen die Nachricht gesendet wird, da alle Nachrichten die Warteschlange durchlaufen.
- Konfigurierte Fehlertoleranz. Um die Warteschlange zu lesen, können Sie nicht einen, sondern mehrere Server ausführen. Selbst wenn einer von ihnen fällt, funktioniert das System weiter.
- Auf den Servern wurden Rollen angezeigt, mit denen der Server nach Lasttyp aufgeteilt werden konnte. Beispielsweise kann ein Ressourcengenerator nur eine Verbindung zu einer Warteschlange zum Lesen von Nachrichten herstellen, um Ressourcen zu generieren, und ein Server mit Karten kann eine Verbindung zu einer Warteschlange zum Öffnen von Karten herstellen.
- Hat RPC-Kommunikation, d.h. Jeder Server verfügt über eine eigene private Warteschlange, an die andere Server Ereignisse senden.
- Sie können Nachrichten über Topic an alle Server senden, mit denen wir Abonnements zurücksetzen.
Das Schema sieht einfach aus: Alle Server sind mit dem Broker verbunden und verwalten die Kommunikation zwischen ihnen. Alles funktioniert, Nachrichten werden gesendet und empfangen, Ressourcen werden erstellt. Aber es gibt neue Probleme.
Was tun, wenn alle erforderlichen Server lügen?
Angenommen, Server 3 möchte eine Nachricht senden, um Ressourcen in einer Warteschlange zu generieren. Er erwartet, dass seine Nachricht verarbeitet wird. Aber er weiß nicht, dass es aus irgendeinem Grund keinen einzigen Empfänger der Nachricht gibt. Beispielsweise stürzten Empfänger aufgrund eines Fehlers ab.
Während der gesamten Wartezeit sendet der Server viele Nachrichten mit einer Anfrage, weshalb eine Warteschlange mit Nachrichten angezeigt wird. Wenn Arbeitsserver angezeigt werden, müssen sie daher zuerst die akkumulierte Warteschlange verarbeiten, was einige Zeit in Anspruch nimmt. Auf der Benutzerseite führt dies dazu, dass das von ihm hochgeladene Bild nicht sofort angezeigt wird. Er ist nicht bereit zu warten, also verlässt er das Brett.
Infolgedessen geben wir Serverkapazität für die Generierung von Ressourcen aus, und niemand benötigt das Ergebnis.
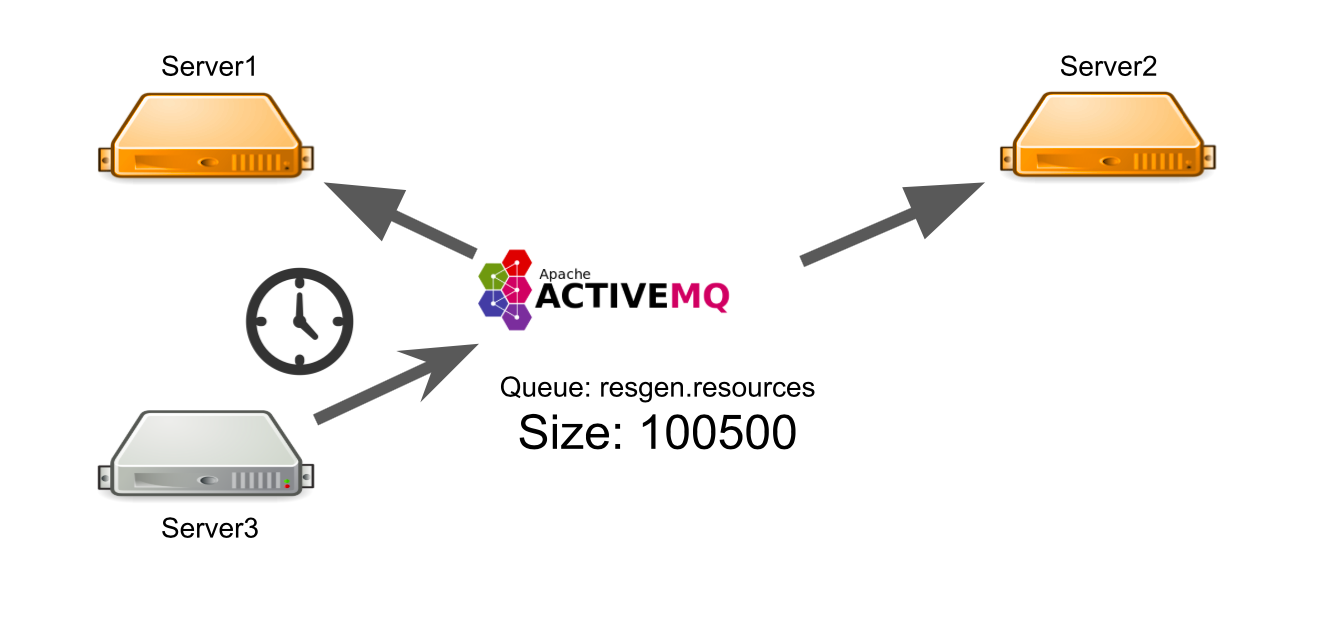
Wie kann ich das Problem lösen? Wir können eine Überwachung einrichten, die Sie über das Geschehen informiert. Aber von dem Moment an, in dem die Überwachung etwas meldet, bis zu dem Moment, in dem wir verstehen, dass unsere Server schlecht sind, wird die Zeit vergehen. Das passt nicht zu uns.
Eine andere Option ist das Ausführen von Service Discovery oder einer Registrierung von Diensten, die wissen, welche Server mit welchen Rollen ausgeführt werden. In diesem Fall erhalten wir sofort eine Fehlermeldung, wenn keine freien Server vorhanden sind.
Einige Dienste können nicht horizontal skaliert werden
Dies ist ein Problem unseres frühen Codes, nicht von ActiveMQ. Lassen Sie mich Ihnen ein Beispiel zeigen:
Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER);
Wir haben einen Service für die Arbeit mit Benutzerrechten auf dem Board: Der Benutzer kann der Eigentümer des Boards oder dessen Editor sein. Es kann nur ein Eigentümer an der Tafel sein. Angenommen, wir haben ein Szenario, in dem wir das Eigentum an einem Board von einem Benutzer auf einen anderen übertragen möchten. In der ersten Zeile erhalten wir den aktuellen Eigentümer des Boards, in der zweiten den Benutzer, der der Herausgeber war, und werden nun zum Eigentümer. Als jetzigen Eigentümer haben wir die Rolle des HERAUSGEBERS und des ehemaligen Herausgebers die Rolle des EIGENTÜMERS übernommen.
Mal sehen, wie dies in einer Multithread-Umgebung funktioniert. Wenn der erste Thread die EDITOR-Rolle einrichtet und der zweite Thread versucht, den aktuellen EIGENTÜMER zu übernehmen, kann es vorkommen, dass der EIGENTÜMER nicht vorhanden ist, es jedoch zwei EDITOR gibt.
Der Grund ist die fehlende Synchronisation. Wir können das Problem lösen, indem wir einen Synchronisationsblock auf der Karte hinzufügen.
synchronized (board) { Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER); }
Diese Lösung funktioniert im Cluster nicht. Die SQL-Datenbank könnte uns dabei mit Hilfe von Transaktionen helfen. Aber wir haben Redis.
Eine andere Lösung besteht darin, dem Cluster verteilte Sperren hinzuzufügen, sodass die Synchronisierung im gesamten Cluster und nicht nur auf einem Server erfolgt.
Ein einzelner Fehlerpunkt beim Betreten der Platine
Das Modell der Interaktion zwischen Client und Server ist statusbehaftet. Wir müssen also den Status der Karte auf dem Server speichern. Aus diesem Grund haben wir eine separate Rolle für Server festgelegt - BoardServer, der Benutzeranforderungen in Bezug auf Boards verarbeitet.
Stellen Sie sich vor, wir haben drei BoardServer, von denen einer der wichtigste ist. Der Benutzer sendet ihm eine Anfrage „Öffne mir die Karte mit der ID = 123“ → Der Server prüft in seiner Datenbank, ob die Karte geöffnet ist und auf welchem Server sie sich befindet. In diesem Beispiel ist die Karte geöffnet.
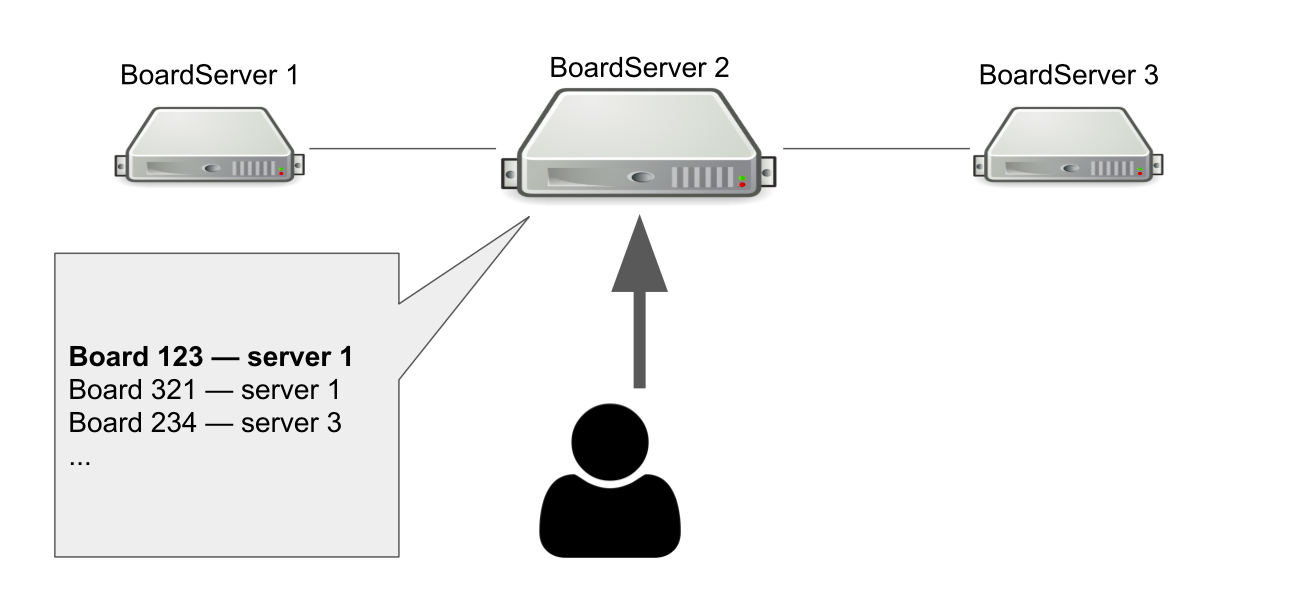
Der Hauptserver antwortet, dass Sie eine Verbindung zum Server Nr. 1 herstellen müssen → Der Benutzer stellt eine Verbindung her. Wenn der Hauptserver ausfällt, kann der Benutzer offensichtlich nicht mehr auf neue Karten zugreifen.
Warum brauchen wir dann einen Server, der weiß, wo die Boards geöffnet sind? Damit wir einen einzigen Entscheidungspunkt haben. Wenn etwas mit den Servern passiert, müssen wir verstehen, ob die Karte tatsächlich verfügbar ist, um die Karte aus der Registrierung zu entfernen oder an einer anderen Stelle erneut zu öffnen. Es wäre möglich, dies mit Hilfe eines Quorums zu organisieren, wenn mehrere Server ein ähnliches Problem lösen, aber zu diesem Zeitpunkt hatten wir nicht das Wissen, das Quorum unabhängig zu implementieren.
Wechseln Sie zu Hazelcast
Auf die eine oder andere Weise haben wir die aufgetretenen Probleme bewältigt, aber es ist vielleicht nicht der schönste Weg. Jetzt mussten wir verstehen, wie man sie richtig löst, und formulierten eine Liste der Anforderungen für eine neue Clusterlösung:
- Wir brauchen etwas, das den Status aller Server und ihre Rollen überwacht. Nennen Sie es Service Discovery.
- Wir benötigen Clustersperren, die die Konsistenz bei der Ausführung gefährlicher Abfragen gewährleisten.
- Wir benötigen eine verteilte Datenstruktur, die sicherstellt, dass sich die Karten auf bestimmten Servern befinden, und darüber informiert, wenn ein Fehler aufgetreten ist.
Es war das Jahr 2015. Wir haben uns für Hazelcast - In-Memory Data Grid entschieden, ein Clustersystem zum Speichern von Informationen im RAM. Dann dachten wir, wir hätten eine Wunderlösung gefunden, den heiligen Gral der Welt der Cluster-Interaktion, ein Wunder-Framework, das alles kann und verteilte Datenstrukturen, Sperren, RPC-Nachrichten und Warteschlangen kombiniert.
Wie bei ActiveMQ haben wir fast alles auf Hazelcast übertragen:
- Generierung von Benutzerressourcen durch ExecutorService;
- verteilte Sperre, wenn Rechte geändert werden;
- Rollen und Attribute von Servern (Service Discovery);
- eine einzige Registrierung von offenen Brettern usw.
Hazelcast-Topologien
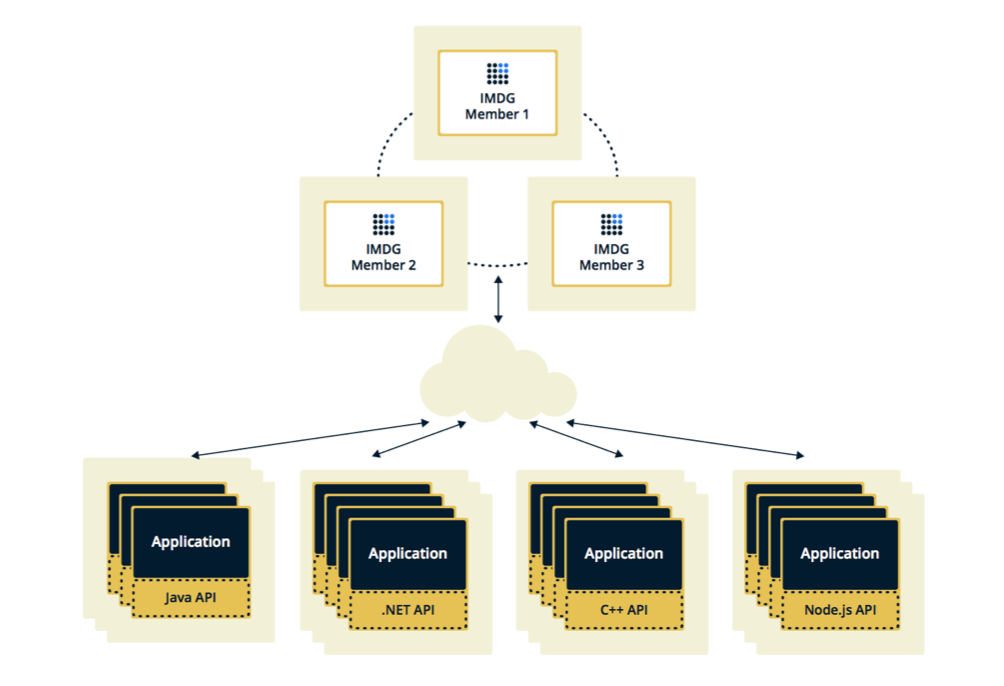
Hazelcast kann in zwei Topologien konfiguriert werden. Die erste Option ist Client-Server. Wenn sich Mitglieder getrennt von der Hauptanwendung befinden, bilden sie selbst einen Cluster und alle Anwendungen stellen als Datenbank eine Verbindung zu ihnen her.
Die zweite Topologie ist eingebettet, wenn Hazelcast-Mitglieder in die Anwendung selbst eingebettet sind. In diesem Fall können wir weniger Instanzen verwenden. Der Zugriff auf Daten ist schneller, da sich die Daten und die Geschäftslogik selbst an derselben Stelle befinden.
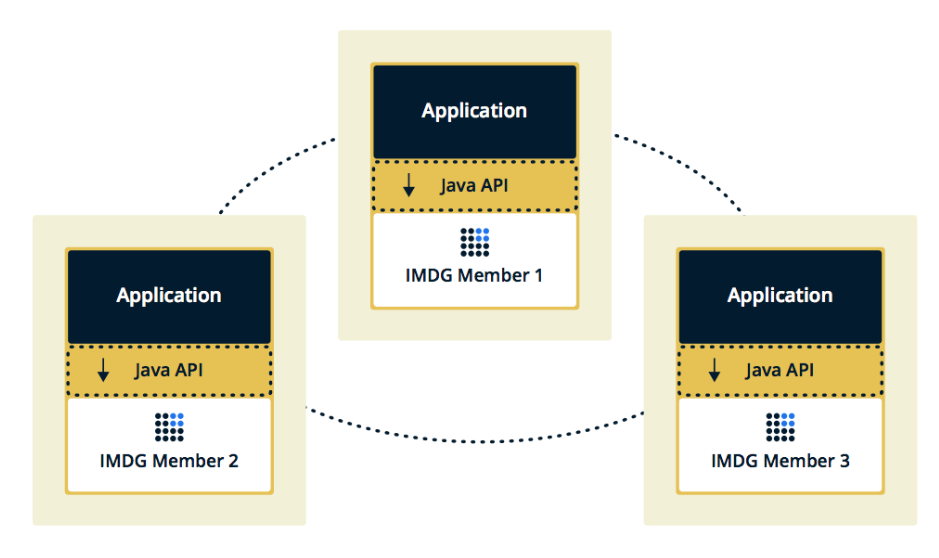
Wir haben uns für die zweite Lösung entschieden, weil wir die Implementierung für effektiver und wirtschaftlicher hielten. Effektiv, da die Geschwindigkeit für den Zugriff auf Hazelcast-Daten geringer ist, weil Möglicherweise befinden sich diese Daten auf dem aktuellen Server. Wirtschaftlich, weil wir kein Geld für zusätzliche Instanzen ausgeben müssen.
Cluster hängt, wenn Mitglied hängt
Ein paar Wochen nach dem Einschalten von Hazelcast traten Probleme auf dem Produkt auf.
Unsere Überwachung ergab zunächst, dass einer der Server den Speicher allmählich überlastete. Während wir diesen Server beobachteten, wurde auch der Rest der Server geladen: Die CPU wuchs, dann der RAM, und nach fünf Minuten verwendeten alle Server den gesamten verfügbaren Speicher.
An diesem Punkt in den Konsolen sahen wir diese Nachrichten:
2015-07-15 15:35:51,466 [WARN] (cached18) com.hazelcast.spi.impl.operationservice.impl.Invocation: [my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7 2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService', op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783, waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0, tryCount=250, tryPauseMillis=500, invokeCount=1, callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Hier prüft Hazelcast, ob der Vorgang ausgeführt wird, der an den ersten "sterbenden" Server gesendet wurde. Hazelcast versuchte, auf dem Laufenden zu bleiben und überprüfte mehrmals pro Sekunde den Status der Operation. Infolgedessen hat er alle anderen Server mit dieser Operation als Spam versendet, und nach einigen Minuten ist ihnen der Speicher ausgegangen, und wir haben mehrere GB Protokolle von jedem von ihnen gesammelt.
Die Situation wurde mehrmals wiederholt. Es stellte sich heraus, dass dies ein Fehler in Hazelcast Version 3.5 ist, in der der Heartbeat-Mechanismus implementiert wurde, der den Status von Anforderungen überprüft. Einige der Grenzfälle, auf die wir gestoßen sind, wurden nicht überprüft. Ich musste die Anwendung optimieren, um nicht in diese Fälle zu geraten, und nach einigen Wochen konnte Hazelcast den Fehler zu Hause beheben.
Häufig Hinzufügen und Entfernen von Mitgliedern zu Hazelcast
Das nächste Problem, das wir entdeckt haben, ist das Hinzufügen und Entfernen von Mitgliedern zu Hazelcast.
Zunächst werde ich kurz beschreiben, wie Hazelcast mit Partitionen funktioniert. Zum Beispiel gibt es vier Server, von denen jeder einen Teil der Daten speichert (in der Abbildung haben sie unterschiedliche Farben). Die Einheit ist die primäre Partition, die Zwei ist die sekundäre Partition, d.h. Sicherung der Hauptpartition.

Wenn ein Server ausgeschaltet ist, werden Partitionen an andere Server gesendet. Falls der Server ausfällt, werden Partitionen nicht von ihm übertragen, sondern von den Servern, die noch am Leben sind und eine Sicherung dieser Partitionen enthalten.
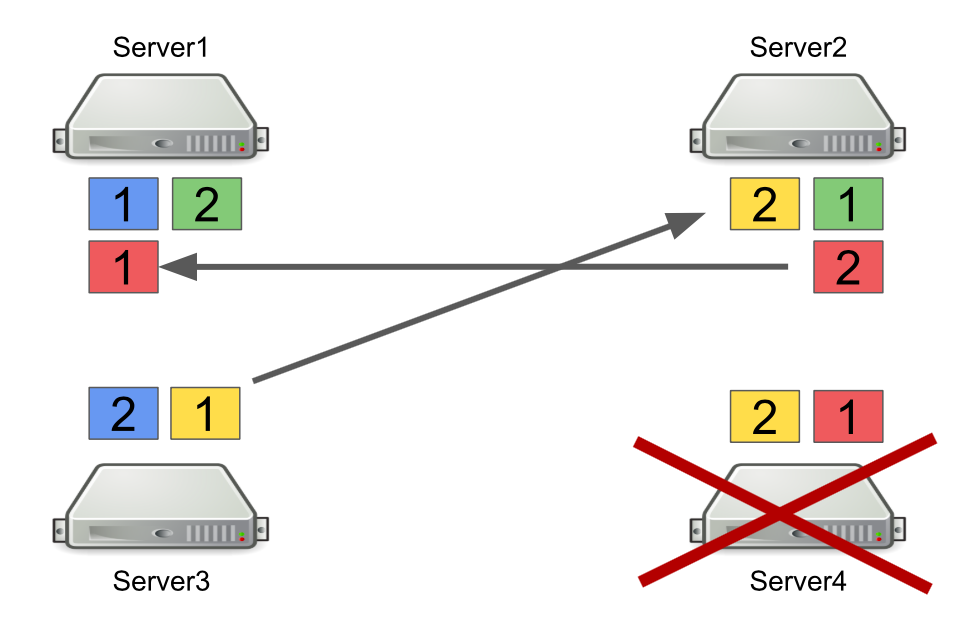
Dies ist ein zuverlässiger Mechanismus. Das Problem ist, dass wir Server häufig ein- und ausschalten, um die Last auszugleichen, und das Neuausgleichen von Partitionen auch Zeit in Anspruch nimmt. Und je mehr Server ausgeführt werden und je mehr Daten wir in Hazelcast speichern, desto länger dauert es, die Partitionen neu auszugleichen.
Natürlich können wir die Anzahl der Sicherungen reduzieren, d. H. sekundäre Partitionen. Dies ist jedoch nicht sicher, da definitiv etwas schief gehen wird.
Eine andere Lösung besteht darin, zur Client-Server-Topologie zu wechseln, damit das Ein- und Ausschalten von Servern keinen Einfluss auf den Hazelcast-Kerncluster hat. Wir haben versucht, dies zu tun, und es stellte sich heraus, dass RPC-Anforderungen nicht auf Clients ausgeführt werden können. Mal sehen warum.
Betrachten Sie dazu das Beispiel des Sendens einer RPC-Anforderung an einen anderen Server. Wir verwenden den ExecutorService, mit dem Sie RPC-Nachrichten senden und mit einer neuen Aufgabe senden können.
hazelcastInstance .getExecutorService(...) .submit(new Task(), ...);
Die Aufgabe selbst sieht aus wie eine reguläre Java-Klasse, die Callable implementiert.
public class Task implements Callable<Long> { @Override public Long call() { return 42; } }
Das Problem ist, dass Hazelcast-Clients nicht nur Java-Anwendungen sein können, sondern auch C ++ - Anwendungen, .NET und andere. Natürlich können wir unsere Java-Klasse nicht generieren und auf eine andere Plattform konvertieren.
Eine Möglichkeit besteht darin, auf http-Anfragen umzusteigen, falls wir etwas von einem Server an einen anderen senden und eine Antwort erhalten möchten. Aber dann müssen wir Hazelcast teilweise aufgeben.
Als Lösung haben wir uns daher für die Verwendung von Warteschlangen anstelle von ExecutorService entschieden. Zu diesem Zweck haben wir unabhängig einen Mechanismus implementiert, der darauf wartet, dass ein Element in der Warteschlange ausgeführt wird. Dieser verarbeitet Grenzfälle und gibt das Ergebnis an den anfordernden Server zurück.
Was haben wir gelernt?
Legen Sie Flexibilität in das System. Die Zukunft ändert sich ständig, daher gibt es keine perfekten Lösungen. Richtig zu machen „richtig“ funktioniert nicht, aber Sie können versuchen, flexibel zu sein und es in das System zu integrieren. Dies ermöglichte es uns, wichtige architektonische Entscheidungen so lange aufzuschieben, bis es nicht mehr unmöglich ist, sie zu akzeptieren.
Robert Martin in Clean Architecture schreibt über dieses Prinzip:
„Ziel des Architekten ist es, eine Form für das System zu schaffen, die die Politik zum wichtigsten Element macht und die Details nicht mit der Politik in Verbindung bringt. Dies wird Entscheidungen über Details verzögern und verzögern. “
Universelle Werkzeuge und Lösungen existieren nicht. Wenn es Ihnen so scheint, als ob ein Framework alle Ihre Probleme löst, ist dies höchstwahrscheinlich nicht der Fall. Daher ist es bei der Implementierung eines Frameworks wichtig, nicht nur zu verstehen, welche Probleme es lösen wird, sondern auch welche.
Schreiben Sie nicht sofort alles neu. Wenn Sie mit einem Problem in der Architektur konfrontiert sind und es scheint, dass die einzig richtige Lösung darin besteht, alles von Grund auf neu zu schreiben, warten Sie. Wenn das Problem wirklich schwerwiegend ist, finden Sie eine schnelle Lösung und beobachten Sie, wie das System in Zukunft funktionieren wird. Höchstwahrscheinlich wird dies nicht das einzige Problem in der Architektur sein, mit der Zeit werden Sie mehr finden. Und nur wenn Sie eine ausreichende Anzahl von Problembereichen erfassen, können Sie mit dem Refactoring beginnen. Nur in diesem Fall ergeben sich mehr Vorteile als sein Wert.