Der Hauptvorteil auf dem IoT-Markt sind die Kosten. Daher haben billige, aber unzuverlässige Komponenten Vorrang. Unzuverlässige Geräte brechen, machen Fehler, frieren ein und müssen gewartet werden. Es ist nicht üblich, auf Konferenzen über Unzuverlässigkeit zu sprechen, aber genau dem widmete sich der Bericht von
Stanislav Elizarov (
elstas ) über InoThings ++ - wie nicht alles funktioniert.

Im Rahmen des Schnitts werden Methoden zur Kompensation der Unzuverlässigkeit von Geräten, Kommunikationskanälen und Personal mithilfe von Software erörtert. Fehlertoleranzprobleme und ihre Lösungen; menschlicher Faktor; Klebeband und Socken als universelles Mittel zur Reparatur von Raumfahrzeugen und zur Datenübertragung mit Lastwagen.
Über den Sprecher :
Stanislav Elizarov ist in der Abteilung für Netzwerkinfrastruktur des Unternehmens STRIZH tätig, die Messgeräte, Sensoren und LTE-Basisstationen herstellt und Messwerte sammelt, bei denen andere Kommunikationssysteme einfach nicht funktionieren.
Unsicherheit
"Wenn etwas nicht funktioniert, ist es bereits veraltet."
Dies ist ein Zitat des kanadischen Philosophen
Marshall McLuhan , das den Stand der Technik genau beschreibt. Alles lehnt ab: Computer frieren ein, Smartphones werden langsamer, Aufzüge halten zwischen den Stockwerken an, Raumsonden verirren sich und Menschen machen Fehler.
Erste Fehler
Das Thema Zuverlässigkeit, insbesondere sein Teil, ist Fehlertoleranz, so groß wie Sicherheit. Der Buchstabe S im Begriff IoT ist für die
Sicherheit verantwortlich , und der Buchstabe R ist für die
Zuverlässigkeit verantwortlich.
Wenn wir über Zuverlässigkeit und Fehler sprechen, erinnern wir uns an
Johann Gutenberg . Offiziell ist er der erste Drucker, und laut Ilf und Petrov ist er der
erste Drucker , weil er in seiner Bibel viele Fehler gemacht hat.

Die Technologie von Gutenberg hat Fortschritte gemacht, der Buchmarkt ist gewachsen, das Volumen hat zugenommen und mit ihnen Fehler. 50 Jahre nach dem ersten gedruckten Buch kam
Gabriel Pierry auf Errata - eine Liste von Tippfehlern am Ende des Buches. Es war ein guter Trick, da das erneute Eingeben großer Chargen unpraktisch und wirtschaftlich unrentabel ist. Wenn der Leser einen Tippfehler bemerkt, öffnet er einfach eine Fehlerliste und prüft kritische Korrekturen. Der Anführer der Tippfehler war Thomas von Aquin und seine Summe der Theologie - 180 Seiten mit Fehlern im offiziellen Irrtum.
Moderne Errats werden von Eisenproduzenten hergestellt. Im Bild unten der
offizielle Fehler des beliebtesten
CC1101- Chips, der noch gültig ist. In der Fehlerliste akzeptiert der Chip manchmal etwas nicht, manchmal überträgt er etwas Falsches und manchmal funktioniert die PLL nicht immer. Dies ist nicht das, was Sie von einem Massenprozessor erwarten, der es schon seit Jahrzehnten gibt.

Ein weiteres Beispiel ist der Mikroprozessor
MSP430 , der auf einer Reihe von Anweisungen basiert. Der Mikroprozessor entspricht in etwa dem
PDP-11 , auf dem Kernigan und Ritchie Unix entwickelt haben. Dies ist nicht der Errat Thomas von Aquin, aber der Hersteller bietet uns
27 Seiten mit Fehlern an , von denen viele selbst er selbst nicht zu lösen weiß.
Genau das ist im Internet der Dinge nicht offensichtlich. Wir lesen das Datenblatt eines billigen Chips und sehen, dass alles in Ordnung ist und alles funktioniert, bis wir die letzten Seiten mit einer Liste von Fehlern öffnen.

Menschlicher Faktor
Bei Eisen ist es mehr oder weniger klar, dass Fehler beschrieben und reproduzierbar sind, aber die größte Fehlerquelle in IoT-Systemen ist der
Mensch .
Am 13. Januar 2018 erhielten alle Einwohner Hawaiis auf Mobiltelefonen
eine Warnung über eine Raketenbedrohung und dass sie sich in einem Luftschutzbunker verstecken mussten.

Es ist nicht klar, wer genau falsch lag: der Bediener oder die Person, die die Schnittstelle entworfen hat. Aber wenn Sie sich das Bild ansehen, bietet sich die Antwort an. Was muss gedrückt werden, um einen Test auszulösen, anstatt vor einer Raketenbedrohung zu warnen? Wenn Sie die Antwort nicht kennen, irren Sie sich.

Richtige AntwortBMD-Fehlalarm
Der Bediener drückte die falsche Taste und das Massenmailing begann. Das System hatte keine Parameter, mit denen der Versand verhindert oder bestätigt werden konnte: "Sind Sie sicher, dass Sie vor der Raketenbedrohung warnen möchten?" Es dauerte 30 Minuten, bis die Mitarbeiter des Zentrums erkannten, was passiert war, und eine Nachricht sendeten, dass der Angriff falsch war.
Der Mensch ist ein zuverlässiges System
Warum sehen wir diese Fehler nicht und denken nicht, dass etwas nicht stimmt? Weil der Mann selbst alle Fehler korrigiert.
Wir sind es gewohnt, Fehler zu beheben.
Wenn wir der Meinung sind, dass der Computer nicht sehr gut funktioniert, werden wir ihn neu starten. Wenn wir sehen, dass die mobile Kommunikation verschwunden ist, suchen wir nach einem Ort, an dem sie ankommt. Wenn die Maschine nicht funktioniert, reparieren wir sie.
Das Foto unten zeigt einen menschlichen Verstand, auf den Sie stolz sein können. Drei Menschen baumelten im
Apollo 13 zwischen Erde und Mond und konnten die nicht triviale Aufgabe lösen, einen quadratischen Filter in ein rundes Loch zu schieben. Zusätzlich zu den quadratischen Filtern hatte die Mission Pech bei einer anderen: einer Explosion der Sauerstoffflasche, Wassermangel, Motorschäden. Das Team versuchte mit Hilfe von Socken, Klebeband und Paketen aus Anzügen zu überleben.

Man, wie sie bei der NASA sagten, ist ein sehr gutes Backup-System und behebt viel. Das Lösen von Problemen auf einem Raumschiff mit Klebeband und Socken kann als nahezu zuverlässig bezeichnet werden: Es ist in kurzer Zeit erledigt, funktioniert mit Garantie und die Menschen kehren lebend zurück, aber dies kann nicht in die Produktion aufgenommen werden.
Fehlertoleranzproblem
Das Problem der Fehlertoleranz für das Internet der Dinge ist sehr wichtig, da die Anzahl der Geräte zunimmt. Laut einem
McKinsey- Beratungsunternehmen waren 2013 weltweit 10 Milliarden IoT-Geräte in Betrieb, und bis 2020 wird diese Zahl auf 30 Milliarden ansteigen.

Wir können einfach nicht alle diese Zähler physisch reparieren - es wird einfach nicht genug Zeit geben. Systeme, die für die Wartung durch Personen konzipiert wurden, helfen uns nicht, sondern werden von uns repariert.
Im Jahr 2018 wurde in Medien und Fachzeitschriften bekannt, dass die Chinesen
100.000 Sensoren mit zwei Kanälen und einer Gesamtlänge von 1.400 km abgedeckt hatten. Insgesamt 130 Arten von Sensoren: Wasser, Wind, Kameras. Unter dem Gesichtspunkt der Betriebskosten ist das System einfach katastrophal: Wie viele Personen benötigen Sie, um Kameras abzuwischen oder Fehler zu entfernen? Das gesamte Personal wird nur mit der Reinigung und Wartung des Systems beschäftigt sein - es ist nicht sehr autonom.
Daher möchte ich ein wenig über
Fehlertoleranz und die Gewährleistung des Betriebs des Systems sprechen. Anhand einfacher Beispiele werde ich über Tricks sprechen, die in kurzer Zeit helfen, eine garantierte funktionierende Lösung zu finden, um Investoren ein Produkt zu präsentieren, und dann darüber nachdenken, wie die Zuverlässigkeit schrittweise erhöht werden kann. Diese Tricks sind sehr vielseitig und werden immer helfen. Das einzige, was sie für die Verwendung in der Produktion nicht sehr empfohlen werden, weil sie wie dieser Filter sind.
Stellen Sie sich vor: Der Tag wird kommen, an dem Investoren zu Ihnen kommen, um einen Projektbericht zu erhalten, und Sie müssen ein funktionierendes Produkt zeigen. Wo soll ich anfangen, um es nicht zu vermasseln?
Vereinfachung
In der Abbildung unten sind zwei nicht verbundene Geräte dargestellt. Auf der linken Seite befindet sich ein Spielzeug, das als
„Sortierer“ bezeichnet wird : Runde in Runde und Quadrat in Quadrat einfügen. Ein einjähriges Kind lernt in 2-3 Versuchen, ein Spielzeug zu benutzen, da es unmöglich ist, mit dem „Gerät“ einen Fehler zu machen - ein Dreieck passt nicht in ein Quadrat.

Die gleiche Idee wurde von der Firma Harris vorgeschlagen, die Militärradiosender produziert. Das Bild rechts zeigt
Harris Falcon 3 , ein Wunder der Technik. Schauen Sie sich die Schnittstellen an, sie sind alle unterschiedlich. In einem Kampfzustand, in dem keine Zeit zum Nachdenken bleibt, kann der Bediener physisch nichts falsch machen. Das Stromkabel wird nicht von der Antenne in den Anschluss eingeführt, und durch eine einfache Unterbrechung verbindet der Funker alle Systeme, auch nicht das Gehirn. Dies ist eine einfache und funktionierende Methode, um Fehler zu vermeiden und ihre Wahrscheinlichkeit zu verringern. Sie werden sagen:
- Und wenn wir morgen eine Präsentation haben. Müssen wir alle Schnittstellen löten? Wir haben dort alles gleich gemacht: 4 USB-Ports, 5 Ethernet-Ports, wir werden definitiv einen Fehler machen.Keine Frage, Vereinfachung funktioniert auch hier - alles schließen. Wenn Sie 4 USB-Anschlüsse haben und einer davon garantiert funktioniert, lassen Sie ihn und schließen Sie den Rest. Zum Beispiel mit Klebeband - fühlen Sie sich wie ein Astronaut.
Durch die Vereinfachung wird nicht nur eine Schnittstelle geschaffen, in der Fehler unmöglich sind, sondern auch alles Überflüssige entfernt. Hier beginnt die Zuverlässigkeit.
Wir haben ein einfaches Gerät erstellt - einen Prototyp, der gezeigt werden kann. Was weiter? Denken Sie als nächstes an Redundanz.
Redundanz
Geräte des Internet der Dinge arbeiten auf der Grundlage
der Informationstheorie : Es gibt eine Signalquelle, einen Empfänger, einen Codierer, einen Modulator, ein Ausbreitungsmedium und eine Fehlerquelle, die die reale Situation stören und verzerren. Eine gute Möglichkeit, Störungen zu reduzieren, besteht darin
, Redundanz hinzuzufügen , mit deren Hilfe wir eine kritische Situation erkennen und deren Auswirkungen ausgleichen können: Benachrichtigen Sie den Bediener oder korrigieren Sie den Fehler.

Ein Beispiel für Redundanz ist das STRIZH-Netzwerk. Die meisten Geräte im Netzwerk werden ohne Bestätigung übertragen: Das Gerät sendet ein Signal und die Basisstation empfängt es.
Stellen Sie sich die Situation vor. Wir haben eine Interferenzzone, in der die Wahrscheinlichkeit der Nachrichtenübermittlung an die Basisstation 90% beträgt, und bei der Präsentation muss nicht mehr als 1% Verlust angezeigt werden. Es scheint, dass es viel Arbeit gibt: die Protokolle zu korrigieren, die Reichweite zu verringern, aber eine schnelle und einfache Lösung ist Redundanz. Stellen Sie neben die Station, die das Signal mit einer Zustellwahrscheinlichkeit von 0,9 empfängt, die zweite mit der gleichen Zustellwahrscheinlichkeit, und die Ausfallwahrscheinlichkeit beider Stationen zur gleichen Zeit beträgt 0,01. Hier gilt der Wahrscheinlichkeitsmultiplikationssatz: Die Ausfallwahrscheinlichkeit jeder Station beträgt 0,1, und der Ausfall beider beträgt nur 1%, sofern die Basisstationen unabhängig sind. In diesem Bereich besteht die höchste Empfangswahrscheinlichkeit zwischen Basisstationen.
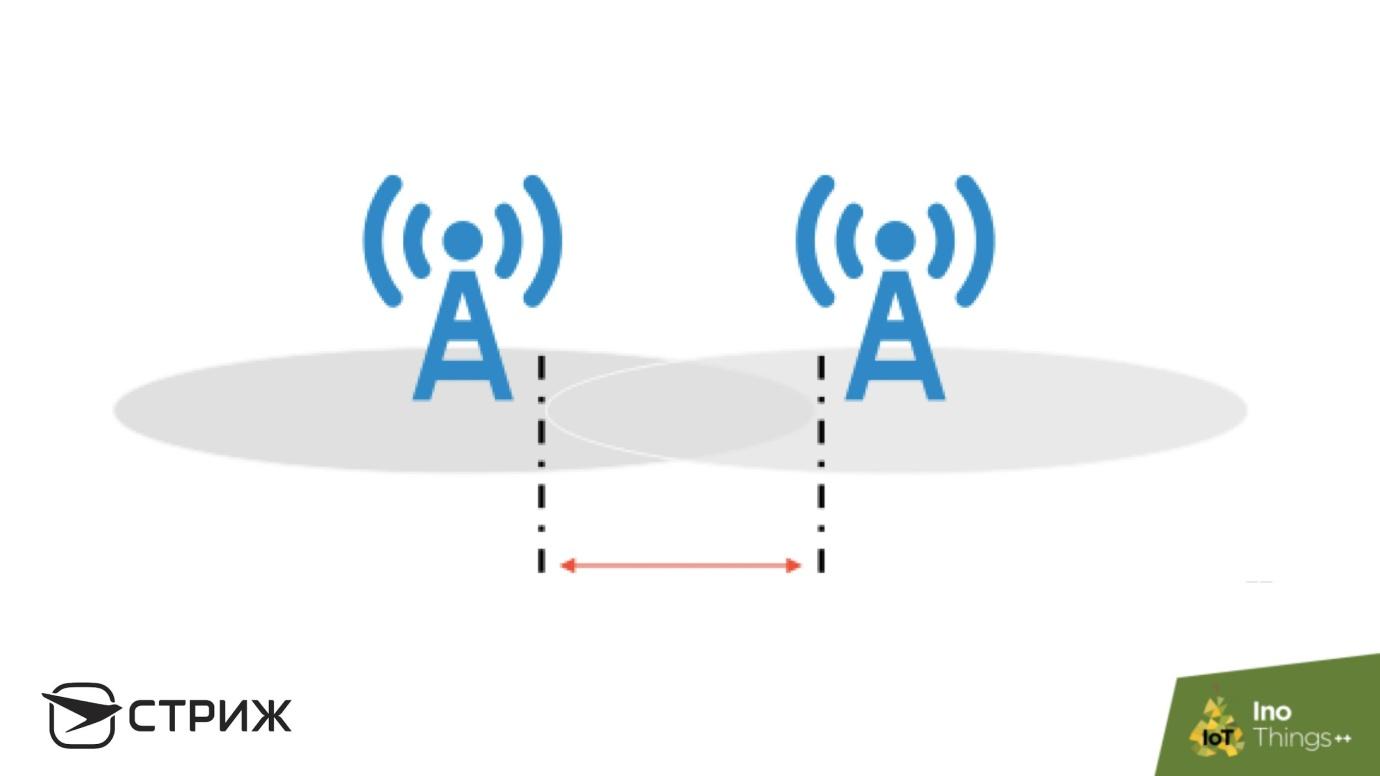
Eine andere Möglichkeit, das Prinzip der Redundanz zu demonstrieren, ist der
Watchdog-Timer . Dies ist ein physisches Gerät, das von den meisten Prozessorherstellern integriert wird. Wenn der Watchdog-Timer nach einer bestimmten Zeit kein Signal vom Computer empfangen hat, startet das Gerät den Computer neu.

Die Verwendung von WT verbessert nicht die Zuverlässigkeit, sondern die
Verfügbarkeit . Der Computer erkennt das Problem, ergreift Steuerungsmaßnahmen und startet den Computer neu. Es liebt die NASA sehr und
kennt viele verschiedene Möglichkeiten, Watchdog Timer zu verwenden.
Im Folgenden finden Sie ein Beispiel für einen mehrstufigen Watchdog-Timer: Wenn bestimmte Ereignisse auftreten, wird ein
NMI gesendet - ein Hardware-Interrupt , der für die Arbeit am Prozessor erforderlich ist. Wenn ein Ereignis auftritt, teilt Watchdog dem Computer mit: "Versuchen Sie, sich selbst neu zu starten, andernfalls schalten Sie den Strom aus." Wenn der erste Timer nicht funktioniert, funktioniert der zweite.

Redundanz funktioniert gut innerhalb des Betriebssystems. Unsere Basisstation ist so aufgebaut. Es besteht aus verschiedenen und
unabhängigen Modulen . Die Autonomie der Module verhindert Fehler von einem Modul zum anderen - es entsteht ein „Pool“ mit Fehlern, den wir blockieren. Weiter oben in der Hierarchie befindet sich eine
Reihe von Supervisoren : Skripte, die die Situation anhand bestimmter Parameter überwachen. Wenn sich der Prozess beispielsweise im Betriebssystem befindet, ist er kein Zombie und fließt nicht aus dem Speicher. Das Stammelement ist ein
Scheduler , z. B. cron.
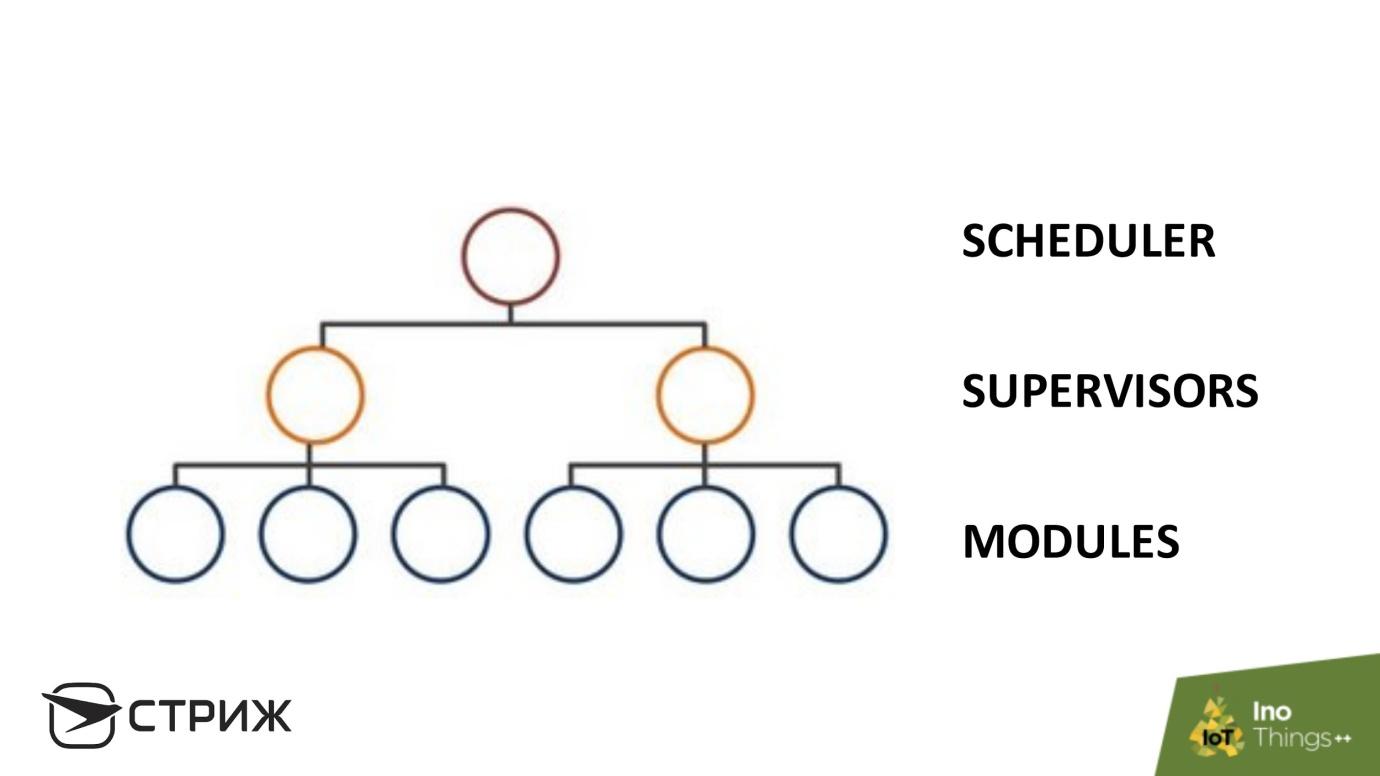
Die hierarchische Struktur schafft gute Parameter für die Verfügbarkeit des Systems: Wenn das Modul ausfällt, sieht der Supervisor und startet neu, es gibt eine gewisse Redundanz in den Modulen, einige Module übernehmen die Funktion anderer.
Übergang zu einem anderen Referenzsystem
Meine beliebteste und beliebteste Methode unter Mathematikern. Wenn bekannt ist, unter welchen Bedingungen das Gerät arbeitet, muss unter diesen Bedingungen ein Pilot durchgeführt werden. Ich werde Ihnen Beispiele zeigen.
Beispiel Nr. 1 . Wir haben ein Gerät entwickelt, das bei Raumtemperatur gut funktioniert, und sie sagen uns:
- Wir demonstrieren das Projekt im hohen Norden. Jetzt gibt es −40, aber lass es funktionieren.Wir laufen im Internet und suchen nach einer Lösung:
- Wir brauchen thermostabile Quarz- und Flash-Laufwerke, die bei -40 nicht ausfallen.Die Zeit läuft ab, die Ressourcen werden kleiner und die Panik nimmt zu. Wir denken, dass das Projekt ein Fehlschlag ist, aber wir werden durch den Übergang zu dem Referenzsystem, in dem die Basisstation arbeitet, gerettet. Wir platzieren das Gerät in der Box, in der sich die Heizung und das Thermorelais befinden. Sie sind ziemlich stabile Leute und arbeiten fast immer. Wenn es draußen kalt ist - die Box heizt sich auf und das Gerät funktioniert unter normalen Bedingungen -, haben wir auf ein Referenzsystem umgestellt, in dem wir die Lösung kennen und verwenden.
 Beispiel Nr. 2
Beispiel Nr. 2 . Übergang zu beweglichen Frames. Stellen Sie sich vor, wir sammeln Containerdaten von einem Zug. Die erste Standardlösung ist die Verwendung von GSM-Modems. Diese Methode ist nicht geeignet: Für sich schnell bewegende Objekte sollten Sie LTE- oder 5G-Geräte verwenden, die mit Doppler gute Arbeit leisten, was teuer ist. Wenn der Zug quer durch Russland fährt, werden alle Modems beim Eintreffen am Bahnhof mit dem Bahnhof verbunden und stürzen einfach aufgrund einer Überlastung des Netzwerks ab.
Lösung: Übergang zu einem festen Referenzrahmen. Erinnern wir uns an die Relativität der Bewegung: Wir platzieren die Basisstation im Zug und sie ist relativ zum fahrenden Zug bewegungslos. Die Station sammelt Informationen von allen Sensoren und sendet sie über ein Gateway, einen Satelliten oder ein LTE-Modem weiter.
Dieser Ansatz erhöht die Zuverlässigkeit, hilft bei der Lösung unmöglicher Aufgaben und organisiert
verzögerungstolerante Netzwerke - ein
Netzwerk, das gegen Unterbrechungen resistent ist . Aus irgendeinem Grund mögen sie den Ansatz in Russland nicht, aber sie fördern aktiv die
Disney Research- Abteilung desselben Unternehmens. Sie haben nicht das Internet der Dinge, sondern das Internet der Spielzeuge - das
Internet der Spielzeuge . Das Unternehmen befürchtet, dass afrikanische Kinder keine Disney-Cartoons sehen. Das Ausführen von Datennetzen, das Installieren von Türmen und das Ziehen von Glasfasern in Afrika ist teuer, aber sie werden es trotzdem stehlen, also gingen sie in die andere Richtung und verwendeten
Richard Hammings Ideen:
Die Fernübertragung ist die gleiche wie die zeitliche Übertragung, d. H. Die Speicherung. Wenn Sie nicht senden können, speichern Sie die Informationen und übertragen Sie sie an den Empfänger.
Disney
hat genau das getan : Sie haben Bushaltestellen und Busse mit einem System der billigsten WLAN-Router und einer Reihe von Festplatten ausgestattet. Der Bus fährt zum Bahnhof, lädt schnell eine Reihe von Disney-Filmen über WLAN auf Laufwerke hoch und fährt weiter. Er kommt in ein Dorf, in ein anderes und lädt Filme hoch - afrikanische Kinder sind zufrieden. Dies sind die sogenannten
Mul-Netzwerke - billige Maultiere, die sich langsam bewegen, schlecht mit Doppler umgehen, aber Informationen an alle Punkte liefern.
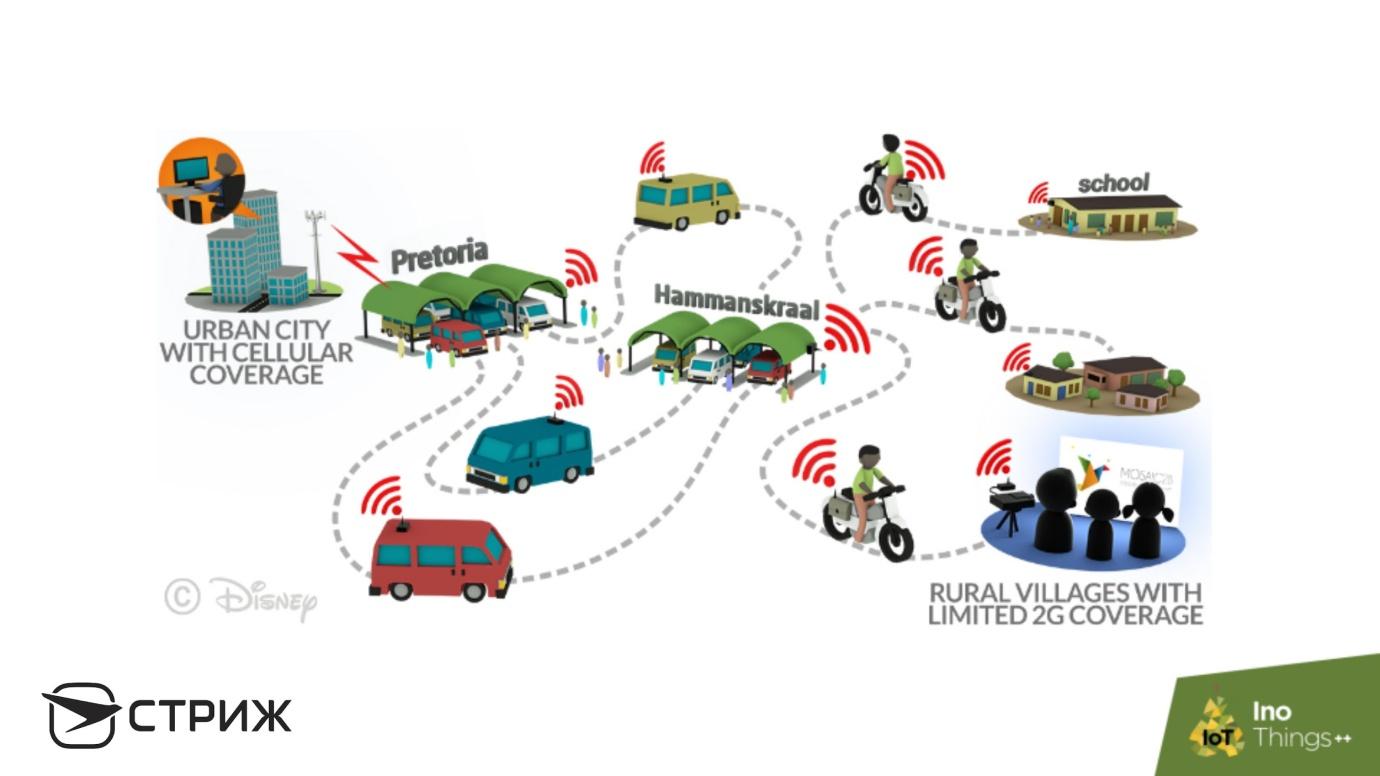
Ähnliche Entwicklungen gibt es in Disney beim Versenden von E-Mails - ein Brief wird mit dem Bus bei Ihnen eintreffen. Sehr lustige Technologie, aber Amazon zum Beispiel liebt sie.
Amazon hat einen Dienst zum Transportieren von
Exabyte an Daten - eine Million Terabyte. Wenn Sie ein großes Rechenzentrum haben und daran denken, zu Amazon zu wechseln, weil bereits alles vorhanden ist, können sie in Amerika einen solchen LKW zu Ihnen bringen und Ihre Daten transportieren. Wenn Verzögerungen für Sie nicht wichtig sind, ist dies ein guter Weg: Datenübertragungsraten in der Größenordnung von zehn oder Hunderten von Gbit / s. Zusätzlich zu LKWs kann Amazon Ihnen eine Tasche mit Festplatten schicken - Schneeball.

Wir haben erkannt, dass Zuverlässigkeit wichtig ist, weil sowohl Menschen als auch Technologie versagen. Zuverlässigkeit muss als Sicherheit betrachtet werden. Aktivieren Sie für Pilotpräsentationen Watchdog, fügen Sie Redundanz hinzu und vereinfachen Sie, damit Sie keinen Fehler machen können. Überlegen Sie, wie Sie in Bedingungen gehen, unter denen das System garantiert funktioniert. Und jetzt gehen wir zur letzten Methode über, die sich von den anderen unterscheidet, und die Technikfreaks ignorieren sie oft.
Schönheit
Sie werden Ihnen viel vergeben, wenn Ihr Prototyp schön aussieht. Wenn während der Präsentation etwas schief geht und alles fehlschlägt, werden Sie hören: „Ja, alles ist kaputt, aber Sie haben ein so cooles Produkt. Ich denke, Sie müssen noch einen Versuch unternehmen, sich zu verbessern. “ Das Prinzip funktioniert für Tesla: Das Unternehmen hat Probleme mit Versand, Autopilot und Unfällen, aber jeder liebt sie, weil die Autos ein cooles Design haben. Dafür vergeben sie alle.

Schlussfolgerungen
Die Zukunft des Internet der Dinge ist
Unsicherheit : IoT richtet sich an Massenmärkte, und für den Massenmarkt ist der Preis der entscheidende Faktor. Das Internet der Dinge wird also aus vielen
billigen und unzuverlässigen Geräten bestehen . Mit zunehmender Anzahl von Geräten steigt die Anzahl von Fehlern. Wir haben einfach nicht genug Hände, um alle Fehler zu korrigieren. Der einzige Weg -
Geräte müssen daher unabhängig mit den Folgen von Ausfällen umgehen . Dies sind autonome Systeme, die lernen müssen, sich selbst zu reparieren.
Ich würde vorschlagen, dass Sie sich mit dem Thema Zuverlässigkeit befassen und lernen, wie Sie Piloten auf coole Weise mit drei Methoden zeigen können:
Vereinfachen Sie
alles ,
was Sie können,
fügen Sie Redundanz hinzu und
schaffen Sie die Bedingungen, unter denen der Pilot garantiert arbeitet. Vergessen Sie nicht, dass wir alle Menschen sind und uns
nicht von Logik, sondern von Gefühlen leiten lassen. Schaffen Sie also
schöne Projekte .
Es gibt keine Bücher oder Artikel zum Thema Zuverlässigkeit. Um tiefer in das Thema einzutauchen, beginnen Sie mit einem Artikel über
Bedienbarkeit, Zuverlässigkeit und Sicherheit und studieren Sie dann die Erfahrungen
des NASA Jet Propulsion Laboratory . Sie haben Voyager und Curiosity kreiert und
wissen alles über Zuverlässigkeit . Lassen Sie sich von den Großen inspirieren.
Noch etwas mehr als ein Monat bis zur nächsten InoThings ++ Internet of Things- Entwicklerkonferenz , die am 4. April stattfinden wird. Wir werden ein Programm vorbereiten, das alle Aspekte der Welt des Internet der Dinge abdeckt: Entwicklung von Hardware und Software für Geräte, Sicherheit für Benutzer, Methoden zur Übertragung von Informationen zwischen Geräten und dem „Server“ sowie deren Prüfung, Betrieb und Änderung von Geschäftsprozessen unter dem Einfluss von IoT-Technologien. Aber vielleicht reicht Ihr Bericht nicht aus, um alle Themen abzudecken - reichen Sie Ihre Bewerbung vor dem 1. März ein.