Hallo Habr.
Nach der Veröffentlichung des Artikelrankings für
2017 und
2018 lag die nächste Idee auf der Hand - eine allgemeine Bewertung für alle Jahre zu sammeln. Das Sammeln von Links wäre jedoch banal (obwohl auch nützlich). Daher wurde beschlossen, die Datenverarbeitung zu erweitern und weitere nützliche Informationen zu sammeln.

Bewertungen, Statistiken und ein bisschen Quellcode in Python unter der Katze.
Datenverarbeitung
Diejenigen, die sofort an den Ergebnissen interessiert sind, können dieses Kapitel überspringen. In der Zwischenzeit werden wir herausfinden, wie es funktioniert.
Als Quelldaten gibt es eine CSV-Datei vom ungefähr folgenden Typ:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
Der Index aller Artikel in diesem Formular benötigt 42 MB, und das Sammeln dauerte ungefähr 10 Tage, um das Skript auf dem Raspberry Pi auszuführen (der Download erfolgte in einem Stream mit Pausen, um den Server nicht zu überlasten). Nun wollen wir sehen, welche Daten daraus extrahiert werden können.
Site-Zielgruppe
Beginnen wir mit einem relativ einfachen - wir werden das Publikum der Website für all die Jahre bewerten. Für eine grobe Schätzung können Sie die Anzahl der Kommentare zu Artikeln verwenden. Laden Sie die Daten herunter und zeigen Sie eine grafische Darstellung der Anzahl der Kommentare an.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
Die Daten sehen ungefähr so aus:

Das Ergebnis ist interessant - es stellt sich heraus, dass das aktive Publikum der Website (diejenigen, die Kommentare zu Artikeln hinterlassen) seit 2009 praktisch nicht gewachsen ist. Obwohl vielleicht alle IT-Mitarbeiter nur hier sind?
Da wir über das Publikum sprechen, ist es interessant, sich an Habrs neueste Innovation zu erinnern - die Hinzufügung einer englischen Version der Website. Listen Sie Artikel mit "/ de /" im Link auf.
df = df[df['link'].str.contains("/en/")]
Das Ergebnis ist auch interessant (die vertikale Skala bleibt speziell gleich):

Der Anstieg der Anzahl der Veröffentlichungen begann am 15. Januar 2019, als die Ankündigung von
Hello world! Oder Habr auf Englisch , jedoch einige Monate bevor diese 3 Artikel bereits veröffentlicht wurden:
1 ,
2 und
3 . Es war wahrscheinlich Beta-Test?
Kennungen
Der nächste interessante Punkt, den wir in den vorherigen Abschnitten nicht angesprochen haben, ist der Vergleich von Artikelkennungen und Veröffentlichungsdaten. Jeder Artikel hat einen Link vom Typ
habr.com/en/post/N , die Nummerierung der Artikel ist übergreifend, der erste Artikel hat die Kennung 1 und der, den Sie lesen, ist 441740. Es scheint, dass alles einfach ist. Aber nicht wirklich. Überprüfen Sie die Übereinstimmung von Daten und Kennungen.
Laden Sie die Datei in den Pandas-Datenrahmen hoch, wählen Sie Datum und ID aus und zeichnen Sie sie:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
Das Ergebnis ist überraschend - Bezeichner werden nicht immer hintereinander genommen, wie ursprünglich angenommen, es gibt erkennbare „Ausreißer“.
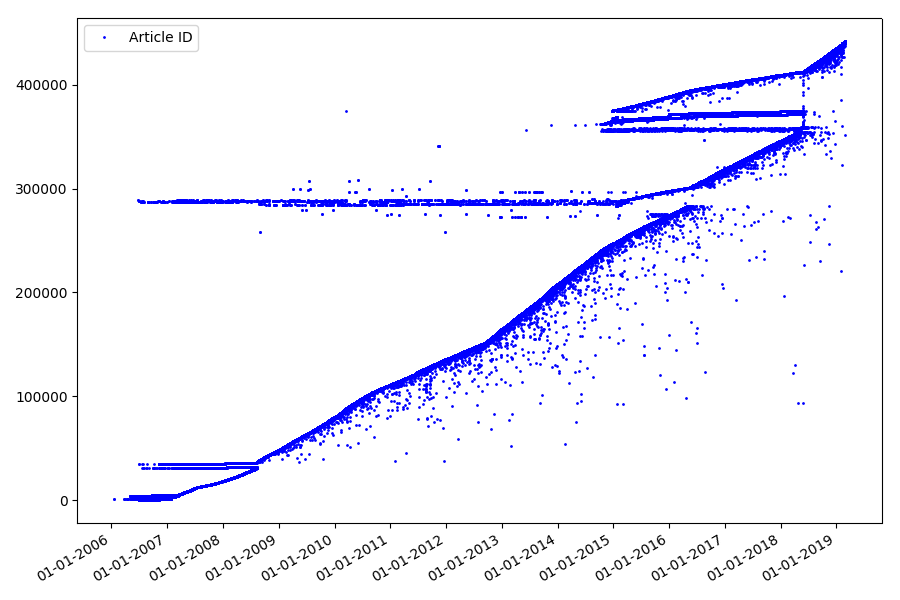
Teilweise wegen ihnen hatte das Publikum Fragen zu den Bewertungen für 2017 und 2018 - solche Artikel mit der „falschen“ ID wurden vom Parser nicht berücksichtigt. Warum so schwer zu sagen und nicht so wichtig.
Was könnte an Identifikatoren interessant sein? Es gibt eine Hypothese, die ich formal nicht beweisen kann, die aber offensichtlich erscheint. Zum Zeitpunkt des Schreibens des Artikelentwurfs wird eine Kennung zugewiesen, und das Veröffentlichungsdatum kommt offensichtlich später. Jemand veröffentlicht den Artikel am selben Tag, jemand veröffentlicht das Material später. Warum das alles? Platzieren Sie die Bezeichner auf der X-Achse und die Daten vertikal und sehen Sie sich ein Fragment des Diagramms genauer an:
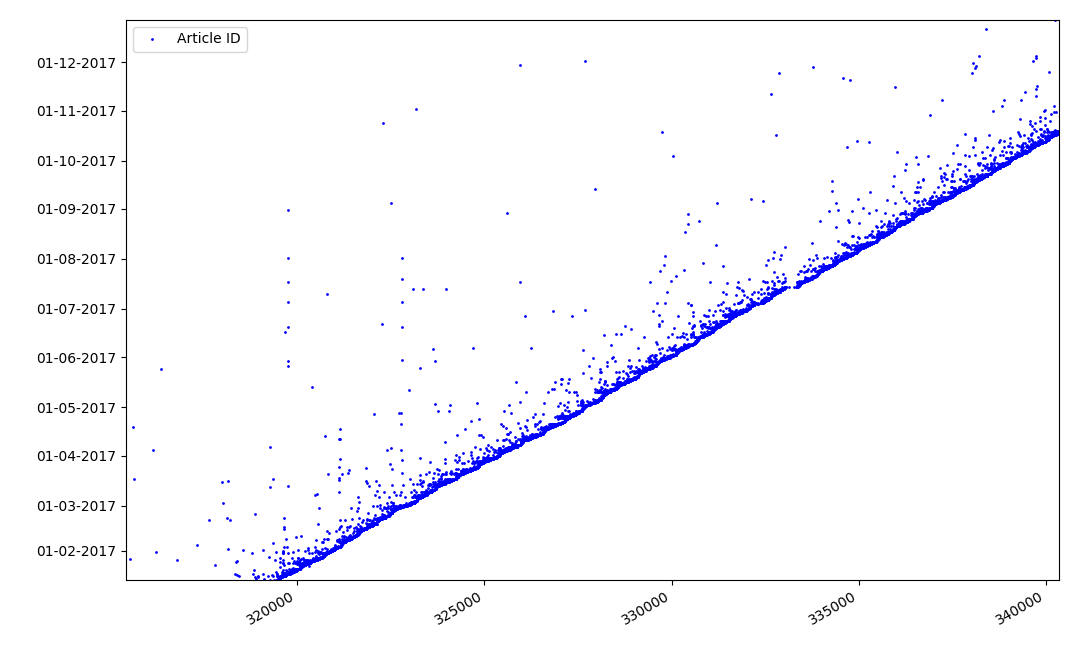
Ergebnis - Wir sehen eine Punktwolke über der durchgezogenen Linie, die uns die Zeitverteilung für die
Dauer der Artikelerstellung zeigt . Wie Sie sehen können, fällt das Maximum auf das Intervall von bis zu 1-2 Wochen. Fast die gesamte Artikelmasse wird in nicht mehr als einem Monat erstellt, obwohl einige Artikel einige Monate nach der Erstellung des Entwurfs veröffentlicht werden (dies garantiert uns natürlich nicht, dass der Autor täglich mehrere Monate an dem Artikel gearbeitet hat, aber das Ergebnis ist immer noch recht interessant).
Datum und Uhrzeit der Veröffentlichung
Ein interessanter, wenn auch intuitiver Punkt ist der Zeitpunkt der Veröffentlichung von Artikeln.
Ausgabestatistik an Arbeitstagen:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
Die Abhängigkeit der Anzahl der Artikel vom Zeitpunkt der Veröffentlichung an Wochentagen:
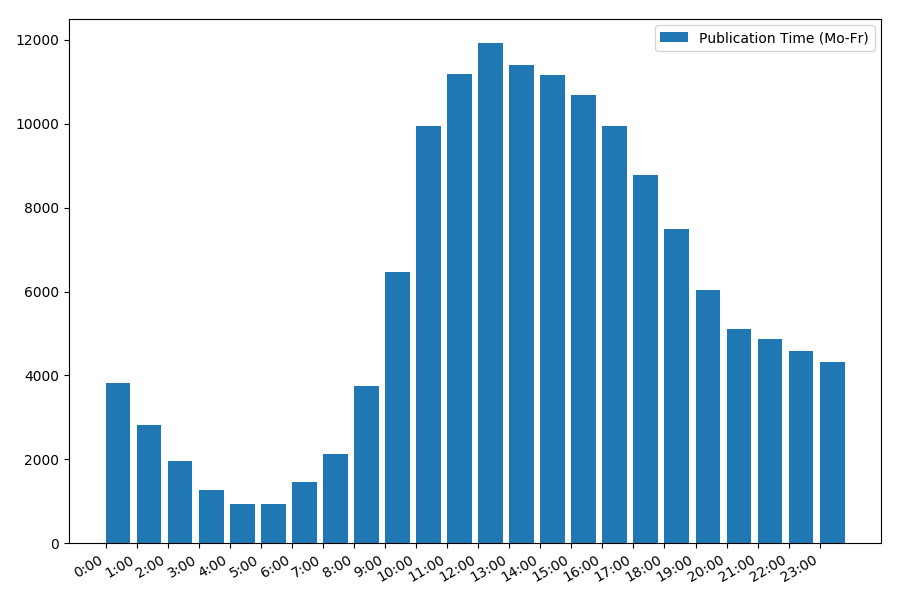
Das Bild ist interessant, die meisten Veröffentlichungen fallen auf die Arbeitszeit. Immer noch interessant, für die meisten Autoren ist das Schreiben von Artikeln die Hauptaufgabe, oder tun sie dies nur während der Arbeitszeit? ;) Aber der Verteilungsplan am Wochenende gibt ein anderes Bild:
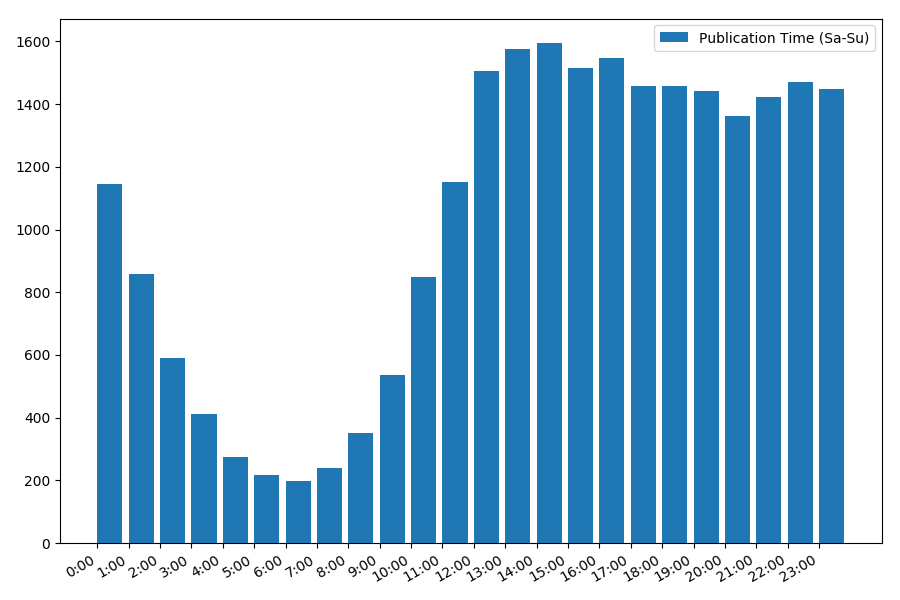
Da es sich um Datum und Uhrzeit handelt, sehen wir uns den Durchschnittswert der Aufrufe und die Anzahl der Artikel pro Wochentag an.
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
Das Ergebnis ist interessant:
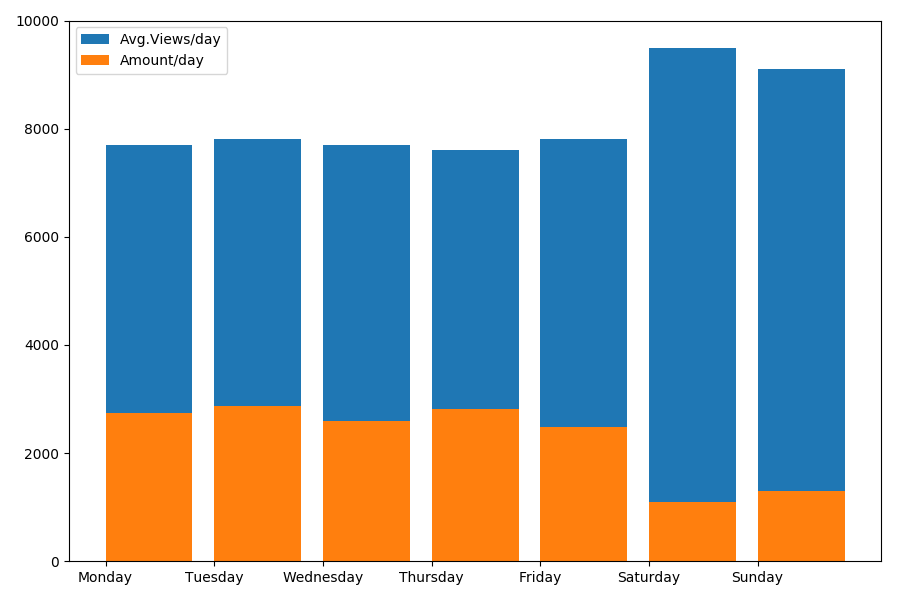
Wie Sie sehen, werden an Wochenenden deutlich weniger Artikel veröffentlicht. Aber dann gewinnt jeder Artikel mehr Aufrufe, so dass das Veröffentlichen von Artikeln am Wochenende sehr ratsam erscheint (wie im
ersten Teil festgestellt wurde, beträgt die aktive Lebensdauer des Artikels nicht mehr als 3-4 Tage, daher sind die ersten Tage ziemlich kritisch).
Der Artikel wird vielleicht zu lang. Das Ende im
zweiten Teil .