
Ich werde eine Geschichte über ein kleines Projekt erzählen: Wie finde ich die Antworten des Autors in den Kommentaren, ohne zu wissen, wer der Autor des Beitrags ist?
Ich habe mein Projekt mit minimalen Kenntnissen über maschinelles Lernen begonnen und ich denke, dass es hier nichts Neues für Spezialisten geben wird. Dieses Material ist in gewisser Weise eine Zusammenstellung verschiedener Artikel. Darin werde ich erläutern, wie es sich der Aufgabe näherte. Im Code finden Sie nützliche Kleinigkeiten und Tricks zur Verarbeitung natürlicher Sprache.
Meine anfänglichen Daten waren wie folgt: Eine Datenbank mit 2,5 Millionen Medienmaterialien und 39,5 Millionen Kommentaren dazu. Für 1M-Posts war auf die eine oder andere Weise der Autor des Materials bekannt (diese Informationen waren entweder in der Datenbank vorhanden oder wurden durch Analyse von Daten aus indirekten Gründen erhalten). Auf dieser Basis wurde
ein Datensatz aus 215.000 markierten Datensätzen erstellt.
Anfangs habe ich einen heuristischen Ansatz verwendet, der von der natürlichen Intelligenz ausgegeben und in SQL-Abfragen mit Volltextsuche oder regulären Ausdrücken übersetzt wurde. Die einfachsten Beispiele für zu analysierende Texte: "Danke für den Kommentar" oder "Danke für die guten Bewertungen". Dies ist in 99,99% der Fälle der Autor und "Danke für die Arbeit" oder "Danke!". Senden Sie Material per Post. Vielen Dank!" - gewöhnliche Überprüfung. Mit einem solchen Ansatz konnten nur offensichtliche Zufälle herausgefiltert werden, außer in Fällen banaler Tippfehler oder wenn der Autor mit Kommentatoren im Dialog steht. Daher wurde beschlossen, neuronale Netze zu verwenden, diese Idee kam nicht ohne die Hilfe eines Freundes.
Eine typische Folge von Kommentaren, welcher von ihnen ist der Autor?
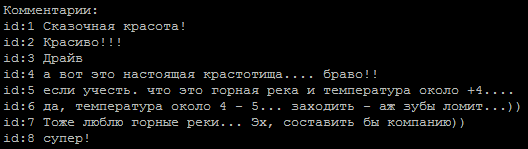
Die Methode zur Bestimmung der Tonalität des Textes wurde als Grundlage genommen. Die Aufgabe ist für uns in zwei Klassen einfach: der Autor und nicht der Autor. Zum Trainieren von Modellen habe ich einen
Dienst von Google verwendet, der virtuellen Maschinen eine GPU und eine Jupiter-Notebook-Oberfläche zur Verfügung stellt.
Beispiele für Netzwerke im Internet:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
In den Zeilen, die von HTML-Tags und Sonderzeichen befreit waren, ergaben sie eine Genauigkeit von 65 bis 74 Prozent, was sich nicht wesentlich vom Werfen einer Münze unterschied.
Ein interessanter Punkt ist, dass die Ausrichtung von Eingabesequenzen durch
pad_sequences(x_train, maxlen=max_len, padding='pre') einen signifikanten Unterschied in den Ergebnissen ergab. In meinem Fall war das beste Ergebnis mit padding = 'post'.
Der nächste Schritt war die Verwendung der Lemmatisierung, die sofort eine Erhöhung der Genauigkeit um bis zu 80% ergab und an der weiter gearbeitet werden konnte. Das Hauptproblem ist nun das korrekte Löschen des Textes. Beispielsweise wurden Tippfehler im Wort "Danke" in einen solchen regulären Ausdruck umgewandelt (Tippfehler wurden nach Verwendungshäufigkeit ausgewählt) (solche Ausdrücke haben ein halbes bis zwei Dutzend angesammelt).
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
An dieser Stelle möchte ich mich ganz besonders bei übermäßig höflichen Menschen bedanken, die es für notwendig halten, dieses Wort jedem ihrer Sätze hinzuzufügen.
Eine Reduzierung des Anteils an Tippfehlern war notwendig, weil Am Ausgang des Lemmatisators geben sie seltsame Worte und wir verlieren nützliche Informationen.
Aber es gibt einen Silberstreifen, wir haben es satt, uns mit Tippfehlern und komplexer Textbereinigung zu befassen. Ich habe die Vektordarstellung von Wörtern verwendet - word2vec. Die Methode erlaubte es, alle Tippfehler, Tippfehler und Synonyme in eng beieinander liegende Vektoren zu übersetzen.

Wörter und ihre Beziehungen im Vektorraum.
Die Reinigungsregeln wurden erheblich vereinfacht (Aha, Geschichtenerzähler), alle Nachrichten und Benutzernamen wurden in Sätze unterteilt und in eine Datei hochgeladen. Ein wichtiger Punkt: Aufgrund der Kürze unserer Kommentatoren benötigen Wörter zusätzliche Kontextinformationen, beispielsweise aus dem Forum und Wikipedia, um qualitativ hochwertige Vektoren zu erstellen. An der resultierenden Datei wurden drei Modelle trainiert: klassisches word2vec, Glove und FastText. Nach vielen Experimenten entschied er sich schließlich für FastText, das in meinem Fall qualitativ am besten unterscheidende Wortcluster.
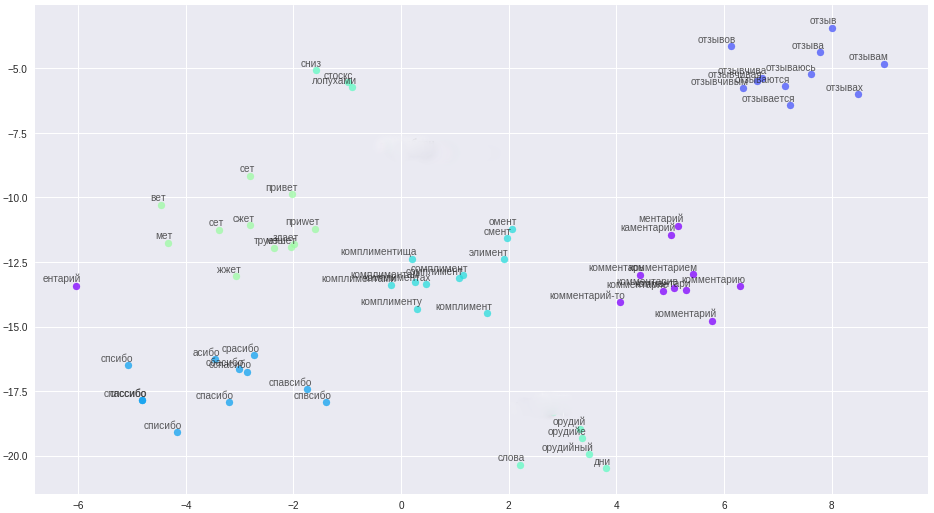
Alle diese Änderungen brachten eine stabile Genauigkeit von 84 bis 85 Prozent.
Modellbeispiele def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
und 6 weitere Modelle im
Code . Einige der Modelle stammen aus dem Netzwerk, andere werden unabhängig voneinander erfunden.
Es wurde festgestellt, dass unterschiedliche Kommentare zu unterschiedlichen Modellen auffielen. Dies veranlasste die Idee, Ensembles von Modellen zu verwenden. Zuerst habe ich das Ensemble manuell zusammengestellt, die besten Modellpaare ausgewählt und dann einen Generator hergestellt. Um die umfassende Suche zu optimieren, habe ich den Gray-Code zugrunde gelegt.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
Mit dem Ensemble „hat das Leben mehr Spaß gemacht“ und der aktuelle Prozentsatz der Modellgenauigkeit wird bei 86-87% gehalten, was hauptsächlich mit einer minderwertigen Klassifizierung einiger Autoren im Datensatz zusammenhängt.

Die Probleme, die ich getroffen habe:
- Unausgeglichener Datensatz. Die Anzahl der Kommentare der Autoren war deutlich geringer als bei anderen Kommentatoren.
- Die Klassen in der Stichprobe sind streng geordnet. Das Fazit ist, dass sich Anfang, Mitte und Ende in der Qualität der Klassifizierung erheblich unterscheiden. Dies ist im Lernprozess im Zeitplan der f1-Maßnahme deutlich sichtbar.
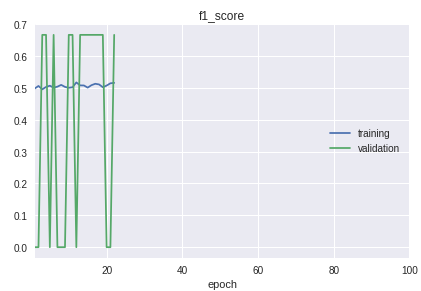
Für die Lösung wurde ein Fahrrad zur Trennung in Trainings- und Validierungsproben hergestellt. Obwohl in der Praxis in den meisten Fällen die Prozedur train_test_split aus der sklearn-Bibliothek ausreicht.
Grafik des aktuellen Arbeitsmodells:

Als Ergebnis erhielt ich aus kurzen Kommentaren ein Modell mit einer sicheren Definition der Autoren. Weitere Verbesserungen werden mit der Bereinigung und Übertragung der Ergebnisse der Klassifizierung realer Daten in den Trainingsdatensatz verbunden sein.
Der gesamte Code mit zusätzlichen Erklärungen befindet sich im
Repository .
Als Postskriptum: Wenn Sie große Textmengen klassifizieren müssen, schauen Sie sich das
VDCNN-Modell „Very Deep Convolutional Neural Network“ (
Implementierung auf Keras) an. Dies ist ein Analogon von ResNet für Texte.
Verwendete Materialien:
•
Übersicht über maschinelle Lernkurse•
Faltungsanalyse mit Faltung•
Faltungsnetzwerke in NLP•
Metriken beim maschinellen Lernenhttps://ld86.imtqy.com/ml-slides/unbalanced.html•
Ein Blick in das Modell