
Bisher kann jeder Student, der einen Kurs über neuronale Netze besucht hat, koreanische Zeichen erkennen. Geben Sie ihm ein Muster und einen Computer mit einer Grafikkarte, und nach einer Weile bringt er Ihnen ein Netzwerk, das koreanische Zeichen fast fehlerfrei erkennt.
Eine solche Lösung hat jedoch mehrere Nachteile:
Erstens eine große Anzahl notwendiger Berechnungen, die sich auf die Betriebszeit oder die benötigte Energie auswirken (was für mobile Geräte sehr wichtig ist). Wenn wir mindestens 3000 Zeichen erkennen möchten, entspricht dies der Größe der letzten Schicht des Netzwerks. Und wenn die Eingabe dieser Schicht mindestens 512 beträgt, erhalten wir 512 * 3000 Multiplikationen. Zu viel.
Zweitens die Größe. Die gleiche letzte Schicht aus dem vorherigen Beispiel wiegt 512 × 3001 × 4 Bytes, d. H. Ungefähr 6 Megabyte. Dies ist nur eine Schicht, das gesamte Netzwerk wiegt mehrere zehn Megabyte. Es ist klar, dass dies kein großes Problem für einen Desktop-Computer ist, aber nicht jeder wird bereit sein, so viele Daten auf einem Smartphone zu speichern, um eine Sprache zu erkennen.
Drittens liefert ein solches Netzwerk unvorhersehbare Ergebnisse für Bilder, die keine koreanischen Zeichen sind, aber dennoch in koreanischen Texten verwendet werden. Unter Laborbedingungen ist dies nicht schwierig, aber für die praktische Anwendung der Technologie muss dieses Problem irgendwie gelöst werden.
Und viertens ist das Problem die Anzahl der Zeichen: 3000 ist am wahrscheinlichsten genug, um beispielsweise ein Steak von einer gebratenen Seegurke auf der Speisekarte des Restaurants zu unterscheiden, aber manchmal gibt es komplexere Texte. Es wird schwierig sein, das Netzwerk für eine größere Anzahl von Zeichen zu trainieren: Es wird nicht nur langsamer sein, sondern es wird auch ein Problem mit der Sammlung der Trainingsprobe geben, da die Häufigkeit der Zeichen ungefähr exponentiell abnimmt. Natürlich können Sie Bilder von Schriftarten abrufen und erweitern, aber dies reicht nicht aus, um ein gutes Netzwerk zu trainieren.
Und heute werde ich Ihnen erzählen, wie wir diese Probleme gelöst haben.
Wie funktioniert koreanisches Schreiben?
Die koreanische Schrift Hangul ist eine Kreuzung zwischen chinesischer und europäischer Schrift. Äußerlich sind dies quadratische Zeichen, die Hieroglyphen ähneln, und auf einer Seite des Textes können Sie mehr als hundert eindeutige Zeichen zählen. Andererseits ist es phonetisches Schreiben, das auf der Aufnahme von Tönen basiert. Es gibt ein Alphabet mit 24 Buchstaben (außerdem können Sie zusätzlich Diffraphen und Diphthongs zählen). Im Gegensatz zum lateinischen oder kyrillischen Alphabet werden Töne jedoch nicht in einer Zeile geschrieben, sondern in Blöcken kombiniert. Wenn wir zum Beispiel auf die gleiche Weise geschrieben haben, könnte der Ausdruck „Hallo, Habr“ in drei Blöcken wie folgt geschrieben werden:

Jeder Block kann aus zwei, drei oder vier Buchstaben bestehen. In diesem Fall kommt immer zuerst der Konsonant, dann ein oder zwei Vokale, und am Ende kann es einen anderen Konsonanten geben. Es gibt verschiedene Möglichkeiten, Buchstaben zu Blöcken zu kombinieren, dh in verschiedenen Blöcken steht beispielsweise der zweite Buchstabe an verschiedenen Stellen.
Das Bild unten zeigt zwei Blöcke, die zusammen das Wort "Hangul" bilden. Der erste Buchstabe jedes Blocks wird rot angezeigt, die Vokale werden blau hervorgehoben und der Endkonsonant wird grün hervorgehoben.
Bildquelle: Wikipedia.Ändern Sie den Hangul-Block
Das heißt, es stellt sich heraus, dass ein Hangul-Block durch die Formel beschrieben werden kann: Ci V [V] [Cf], wobei Ci der Anfangskonsonant (möglicherweise doppelt), V der Vokal und Cf der Endkonsonant (kann auch doppelt sein) ist. Eine solche Darstellung ist für die Anerkennung unpraktisch, daher ändern wir sie.
Kombinieren Sie zunächst beide Vokale. Wir erhalten die Formel Ci V '[Cf], wobei V' - alle möglichen Optionen zum Kombinieren von Buchstaben unter Berücksichtigung des Fehlens des zweiten Buchstabens. Da die Sprache 10 Vokale enthält, würde man erwarten, dass wir als Ergebnis 10 * (10 + 1) Optionen erhalten, aber in der Praxis sind nicht alle möglich, sondern nur 21.
Ferner kann der letzte Buchstabe nicht sein. Fügen Sie zu den vielen erwarteten Buchstaben am Ende einen leeren hinzu. Dann erhalten wir die Formel Ci V 'Cf *. Es stellt sich also heraus, dass das koreanische Symbol jetzt immer aus drei „Buchstaben“ besteht. Sie können das Raster lernen.
Wir bauen ein Netzwerk auf
Die Idee ist, dass wir, anstatt den gesamten Charakter zu erkennen, die einzelnen Buchstaben in ihnen erkennen. Anstelle eines großen Softmax am Ende erhalten wir also drei kleine mit einer Größe von jeweils einigen zehn. Sie entsprechen dem ersten, zweiten und dritten "Buchstaben" in der Silbe. Als Ergebnis haben wir die folgende Architektur erhalten:
anklickbares Bild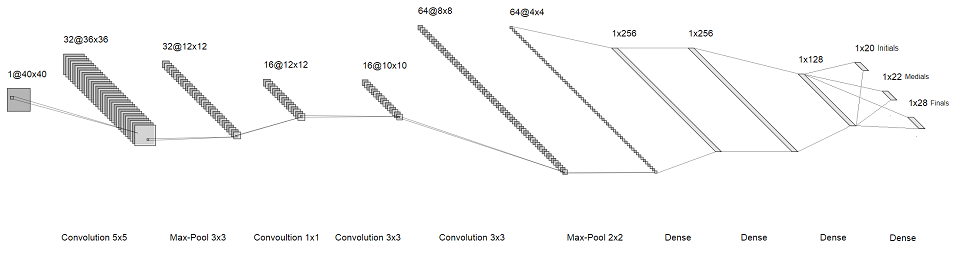
Wir trainieren, laufen auf einer separaten Probe. Die Qualität ist gut, das Gitter ist schnell und es wiegt wenig. Versuchen wir, es aus dem Labor in die reale Welt zu bringen.
Wir lösen Probleme
Das erste Problem tritt sofort auf: Manchmal werden Bilder, die überhaupt keine koreanischen Zeichen sind, in die Eingabe eingegeben, und das Netzwerk in ihnen verhält sich äußerst unvorhersehbar. Sie können natürlich ein anderes Netzwerk trainieren, das koreanische Blöcke von allem anderen unterscheidet, aber wir werden es einfacher machen.
Machen wir dasselbe wie bei der dritten Buchstabengruppe: Fügen Sie eine Ausgabe hinzu, wenn kein Buchstabe vorhanden ist. Dann sieht die Symbolformel folgendermaßen aus: Ci * V '* Cf *. Und im Trainingsset werden wir alle Arten von Müll hinzufügen - chinesische Schriftzeichen, falsch geschnittene Schriftzeichen, europäische Buchstaben, und wir werden dem Netzwerk beibringen, drei leere Buchstaben darauf zu markieren.
Wir trainieren, testen. Es funktioniert, aber die Probleme bleiben bestehen. Es stellt sich heraus, dass beispielsweise solche Bilder häufig in das Raster fallen:
Dies ist der richtige koreanische Block, an den ein einfaches Anführungszeichen gebunden ist. Und es ist offensichtlich, dass das Netzwerk auf ihnen alle drei Buchstaben, aus denen der Block besteht, perfekt findet. Das ist nur, dass das Bild nicht korrekt ist, und wir müssen darüber signalisieren. Es ist falsch, hier leere Buchstaben zurückzugeben, wie sie im Bild sind. Versuchen wir, das anzuwenden, was sich bereits als gut erwiesen hat: Fügen Sie zwei weitere Ausgänge hinzu, um solche klebrigen Interpunktionszeichen zu erkennen. Jeder von ihnen hat eine zusätzliche Ausgabe für die Situation, in der das Bild nichts Überflüssiges enthält, aber zusätzlich muss eine weitere Ausgabe für die Situation hinzugefügt werden, dass "ein Interpunktionszeichen vorhanden ist, aber es wird nicht erkannt, wahrscheinlich Müll".
Ausgebildet In einem solchen Raster ist es schlecht, Satzzeichen zu erkennen: Es unterscheidet ein Komma von einer Klammer, aber von einem Punkt aus ist es bereits schwierig. Sie können die Komplexität des Rasters erhöhen, möchten dies aber nicht. Wir werden uns später mit der Erkennung von Interpunktionszeichen befassen, aber im Moment werden wir einfach herausfinden, ob dort etwas ist oder nicht. Dieses Gitter hat gut gelernt.
Wir haben die geklebten Interpunktionszeichen herausgefunden, aber was ist, wenn im Gegenteil ein Teil des Schlüssels im Bild fehlt? Es gab so ein zweistelliges Wort, aber wir haben es falsch in Zeichen geschnitten:
Das Netzwerk hier bestimmt ohne Probleme den zentralen Buchstaben. Dies wäre eine sehr nützliche Eigenschaft, wenn unsere Aufgabe darin bestand, nur eine Auswahl von Zeichen zu erkennen, aber in der realen Welt wäre dies schädlich: Wenn wir die Zeichenfolge falsch in Zeichen schneiden, müssen wir diese Informationen oben weitergeben, da sonst das verbleibende Stück dann als eine Art erkannt wird Interpunktion, und im resultierenden Text wird ein zusätzliches Zeichen angezeigt.
Um dieses Problem zu lösen, werden wir die Überreste einiger alter Experimente von vor vielen Jahren verwenden. Die Idee, koreanische Schriftzeichen anhand von Buchstaben zu erkennen, ist schon vor langer Zeit aufgetaucht, und die ersten Versuche wurden bereits vor der Ära der neuronalen Netze unternommen, fanden jedoch keine praktische Anwendung. Aber seitdem sind interessante Dinge geblieben:
- Markieren, wo jeder Block einen Buchstaben hat.
- Hochwertige, wenn auch schnelle, die diese Buchstaben aus Symbolen ausschneiden.
Nachdem wir den Staub abgewischt haben, werden wir mit Hilfe dieses Gutes eine ausreichende Anzahl solcher problematischer Bilder ohne einen der Buchstaben erzeugen und dem Netzwerk speziell beibringen, zu antworten, dass es sich um einen leeren Buchstaben handelt.
Das ist alles, es gibt keine Probleme mehr, koreanische Schriftzeichen zu erkennen, aber das Leben steckt wieder Stöcke in die Räder.
Tatsache ist, dass koreanische Texte neben Hangeul-Zeichen auch aus einer Vielzahl anderer Zeichen bestehen: Interpunktionszeichen, europäische Zeichen (mindestens Zahlen) und chinesische Zeichen. Aber sie kommen natürlich viel seltener vor. Wir werden sie in zwei Gruppen einteilen: Hieroglyphen und alles andere, und wir werden unser Gitter für jede von ihnen trainieren. Und wir werden einen einfachen Klassifikator erstellen, der gemäß den Ergebnissen des Netzwerks zur Erkennung koreanischer Zeichen und für einige andere Zeichen (in erster Linie geometrisch) antwortet, ob und wenn ja, welches von ihnen gestartet werden muss. Sie müssen ein paar europäische Zeichen erkennen, damit das Raster klein ist, aber für Hieroglyphen ... Es spart, dass sie selten in Texten vorkommen. Drehen wir also unseren Klassifikator so, dass es sehr selten vorschlägt, sie zu erkennen.
Im Allgemeinen tritt bei diesen beiden Gittern das Problem einer angemessenen Antwort in Bildern auf, die keine Symbole sind, auf denen sie trainiert wurde, aber wir werden darüber sprechen, wie dieses Problem ein anderes Mal gelöst werden kann.
Experimente durchführen
Erster . Es gibt zwei Bildbasen, nennen wir sie Real und Synthetic. Real besteht aus realen Bildern, die aus gescannten Dokumenten stammen, und synthetischen Bildern, die aus Schriftarten stammen. In der ersten Basis befinden sich Bilder für 2374 Blöcke (der Rest ist sehr selten), und von den Schriftarten haben wir alle möglichen 11172 Zeichen erhalten. Lassen Sie uns versuchen, das Netzwerk auf den Blöcken zu trainieren, die sich in Real befinden (wir werden die Bilder von beiden Basen nehmen), und auf denen testen, die sich nur in Synthetic befinden. Ergebnisse:

Das heißt, in etwa 60% der Fälle kann das Netzwerk diese Blöcke erkennen, für die es während des Trainings überhaupt keine Beispiele gesehen hat. Die Qualität hätte höher sein können, wenn nicht ein Problem aufgetreten wäre: Unter den letzten Buchstaben gibt es sehr seltene, und während des Trainings sah das Netzwerk nur sehr wenige Bilder von Blöcken darin. Dies erklärt die geringe Qualität in der letzten Spalte. Wenn es möglich wäre, die 2374 Blöcke, an denen wir studieren, auf andere Weise auszuwählen, wäre die Qualität höchstwahrscheinlich merklich höher.
Zweiter . Vergleichen Sie unser Netzwerk mit einem „normalen“ Netzwerk, das am Ende Softmax hat. Ich würde es gerne 11172 groß machen, aber wir können nicht genügend echte Bilder für seltene Blöcke finden, deshalb beschränken wir uns auf 2374. Die Qualität und Geschwindigkeit dieses Netzwerks hängt von der Größe der verborgenen Schichten ab. Wir werden nur auf Real unterrichten, es testen (auf der anderen Seite natürlich).

Das heißt, selbst wenn wir uns darauf beschränken, nur 2374 Blöcke zu erkennen, ist unser Netzwerk schneller und von gleicher Qualität.
Drittens . Nehmen wir an, wir könnten irgendwo eine riesige Basis aller 11172 koreanischen Blöcke finden. Wenn wir ein Netzwerk mit Softmax trainieren, wie lange wird es pünktlich funktionieren? Die Durchführung aller Experimente ist teuer, daher wird nur ein Netzwerk mit 256 verborgenen Schichtgrößen betrachtet:

Wir bekommen die Ergebnisse
Ohne sie wäre nichts passiert
Ich bedanke mich bei meinem Kollegen Jura Chulinin, dem ursprünglichen Autor der Idee. Es ist in Russland
patentiert , und außerdem wurde eine ähnliche Anmeldung
beim American Patent Office (USPTO)
eingereicht . Vielen Dank an die Entwicklerin Misha Zatsepin, die all dies umgesetzt und alle Experimente durchgeführt hat.
Yuri Vatlin,
Leiter der Gruppe Komplexe Skripte