Neuronale gewöhnliche Differentialgleichungen
Ein erheblicher Teil der Prozesse wird durch Differentialgleichungen beschrieben. Dies kann die zeitliche Entwicklung des physischen Systems, der Gesundheitszustand des Patienten, grundlegende Merkmale der Börse usw. sein. Die Daten zu solchen Prozessen sind konsistenter und kontinuierlicher Natur, in dem Sinne, dass Beobachtungen lediglich Manifestationen eines sich ständig ändernden Zustands sind.
Es gibt auch eine andere Art von seriellen Daten, nämlich diskrete Daten, z. B. NLP-Aufgabendaten. Der Status in solchen Daten variiert diskret: von einem Zeichen oder Wort zum anderen.
Jetzt werden beide Arten solcher serieller Daten normalerweise von rekursiven Netzwerken verarbeitet, obwohl sie unterschiedlicher Natur sind und unterschiedliche Ansätze zu erfordern scheinen.
Auf der letzten
NIPS-Konferenz wurde ein sehr interessanter Artikel vorgestellt, der zur Lösung dieses Problems beitragen kann. Die Autoren schlagen einen Ansatz vor, den sie als
neuronale ODEs bezeichnen .
Hier habe ich versucht, die Ergebnisse dieses Artikels zu reproduzieren und zusammenzufassen, um ihre Idee etwas einfacher kennenzulernen. Es scheint mir, dass diese neue Architektur neben Faltungsnetzwerken und wiederkehrenden Netzwerken durchaus einen Platz in den Standardwerkzeugen eines Datenwissenschaftlers finden könnte.
Abbildung 1: Kontinuierliche Gradienten- Backpropagation erfordert die zeitliche Lösung der erweiterten Differentialgleichung.
Die Pfeile repräsentieren die Anpassung von rückwärts propagierten Gradienten durch Gradienten aus den Beobachtungen.
Illustration aus dem Originalartikel.
Problemstellung
Es gebe einen Prozess, der einer unbekannten ODE gehorcht, und es gebe mehrere (verrauschte) Beobachtungen entlang der Flugbahn des Prozesses
So finden Sie eine Annäherung

Lautsprecherfunktionen

?
Betrachten Sie zunächst eine einfachere Aufgabe: Es gibt nur zwei Beobachtungen am Anfang und am Ende der Flugbahn.

.
Die Systementwicklung beginnt mit dem Zustand

auf Zeit

mit einigen parametrisierten Dynamikfunktionen unter Verwendung einer beliebigen Evolutionsmethode von ODE-Systemen. Nachdem sich das System in einem neuen Zustand befindet

wird es mit dem Staat verglichen

und der Unterschied zwischen ihnen wird durch Variieren der Parameter minimiert

Dynamikfunktionen.
Oder formeller in Betracht ziehen, die Verlustfunktion zu minimieren

::
Zu minimieren

müssen Sie die Verläufe für alle Parameter berechnen:

. Dazu müssen Sie zunächst festlegen, wie
hängt zu jedem Zeitpunkt vom Zustand ab

::

wird ein
adjungierter Zustand genannt, dessen Dynamik durch eine andere Differentialgleichung gegeben ist, die als kontinuierliches Analogon der Differenzierung einer komplexen Funktion (
Kettenregel ) betrachtet werden kann:
Die Ausgabe dieser Formel finden Sie im Anhang des Originalartikels.
Die Vektoren in diesem Artikel sollten als Kleinbuchstabenvektoren betrachtet werden, obwohl der ursprüngliche Artikel sowohl eine Zeilen- als auch eine Spaltendarstellung verwendet.Wenn wir diffur (4) in der Zeit zurücklösen, erhalten wir eine Abhängigkeit vom Ausgangszustand

::
Berechnung des Gradienten in Bezug auf

und
können Sie sie einfach als Teil des Staates betrachten. Dieser Zustand wird als
erweitert bezeichnet . Die Dynamik dieses Zustands ergibt sich trivial aus der ursprünglichen Dynamik:
Dann der konjugierte Zustand zu diesem erweiterten Zustand:
Gradient Augmented Dynamics:
Die Differentialgleichung des konjugierten Augmented State aus Formel (4) lautet dann:
Das Lösen dieser ODE in der Zeit ergibt:
Was ist mit
Gibt dem
ODESolve ODE-
Solver Farbverläufe in allen Eingabeparametern.
Alle Gradienten (10), (11), (12), (13) können zusammen in einem
ODESolve- Aufruf mit der Dynamik des konjugierten erweiterten Zustands (9) berechnet werden.
 Illustration aus dem Originalartikel.
Illustration aus dem Originalartikel.Der obige Algorithmus beschreibt die umgekehrte Ausbreitung des Gradienten der ODE-Lösung für aufeinanderfolgende Beobachtungen.
Bei mehreren Beobachtungen auf einer Trajektorie wird alles auf die gleiche Weise berechnet, aber zum Zeitpunkt der Beobachtungen muss die Umkehrung des propagierten Gradienten mit Gradienten aus der aktuellen Beobachtung angepasst werden, wie in
Abbildung 1 gezeigt .
Implementierung
Der folgende Code ist meine Implementierung von
neuronalen ODEs . Ich habe es nur getan, um besser zu verstehen, was passiert. Es kommt jedoch dem sehr nahe, was im
Repository der Autoren des Artikels implementiert ist. Es enthält den gesamten Code, den Sie zum Verständnis benötigen, an einer Stelle und ist etwas auskommentierter. Für reale Anwendungen und Experimente ist es immer noch besser, die Implementierung des Originalartikels durch die Autoren zu verwenden.
import math import numpy as np from IPython.display import clear_output from tqdm import tqdm_notebook as tqdm import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.color_palette("bright") import matplotlib as mpl import matplotlib.cm as cm import torch from torch import Tensor from torch import nn from torch.nn import functional as F from torch.autograd import Variable use_cuda = torch.cuda.is_available()
Zunächst müssen Sie eine Methode zur Entwicklung von ODE-Systemen implementieren. Der Einfachheit halber wird hier die Euler-Methode implementiert, obwohl jede explizite oder implizite Methode geeignet ist.
def ode_solve(z0, t0, t1, f): """ - """ h_max = 0.05 n_steps = math.ceil((abs(t1 - t0)/h_max).max().item()) h = (t1 - t0)/n_steps t = t0 z = z0 for i_step in range(n_steps): z = z + h * f(z, t) t = t + h return z
Es beschreibt auch die Oberklasse einer parametrisierten Dynamikfunktion mit einigen nützlichen Methoden.
Erstens: Sie müssen alle Parameter, von denen die Funktion abhängt, in Form eines Vektors zurückgeben.
Zweitens: Es ist notwendig, die erweiterte Dynamik zu berechnen. Diese Dynamik hängt vom Gradienten der parametrisierten Funktion in Bezug auf Parameter und Eingabedaten ab. Um den Gradienten nicht mit jeder Hand für jede neue Architektur registrieren zu müssen, verwenden wir die Methode
torch.autograd.grad .
class ODEF(nn.Module): def forward_with_grad(self, z, t, grad_outputs): """Compute f and a df/dz, a df/dp, a df/dt""" batch_size = z.shape[0] out = self.forward(z, t) a = grad_outputs adfdz, adfdt, *adfdp = torch.autograd.grad( (out,), (z, t) + tuple(self.parameters()), grad_outputs=(a), allow_unused=True, retain_graph=True )
Der folgende Code beschreibt die Vorwärts- und Rückwärtsausbreitung für
neuronale ODEs . Es ist erforderlich, diesen Code vom Hauptmodul
torch.nn.Module in Form der Funktion
torch.autograd.Function zu trennen , da Sie in letzterem im Gegensatz zu einem Modul eine beliebige
Backpropagation- Methode implementieren können. Das ist also nur eine Krücke.
Diese Funktion liegt dem gesamten Ansatz der
neuronalen ODE zugrunde.
class ODEAdjoint(torch.autograd.Function): @staticmethod def forward(ctx, z0, t, flat_parameters, func): assert isinstance(func, ODEF) bs, *z_shape = z0.size() time_len = t.size(0) with torch.no_grad(): z = torch.zeros(time_len, bs, *z_shape).to(z0) z[0] = z0 for i_t in range(time_len - 1): z0 = ode_solve(z0, t[i_t], t[i_t+1], func) z[i_t+1] = z0 ctx.func = func ctx.save_for_backward(t, z.clone(), flat_parameters) return z @staticmethod def backward(ctx, dLdz): """ dLdz shape: time_len, batch_size, *z_shape """ func = ctx.func t, z, flat_parameters = ctx.saved_tensors time_len, bs, *z_shape = z.size() n_dim = np.prod(z_shape) n_params = flat_parameters.size(0)
Schließen Sie diese Funktion der
Einfachheit halber in
nn.Module ein .
class NeuralODE(nn.Module): def __init__(self, func): super(NeuralODE, self).__init__() assert isinstance(func, ODEF) self.func = func def forward(self, z0, t=Tensor([0., 1.]), return_whole_sequence=False): t = t.to(z0) z = ODEAdjoint.apply(z0, t, self.func.flatten_parameters(), self.func) if return_whole_sequence: return z else: return z[-1]
Anwendung
Wiederherstellung der realen Dynamikfunktion (Annäherungsverifizierung)
Lassen Sie uns nun als
Basistest überprüfen, ob die
neuronale ODE mithilfe von Beobachtungsdaten die wahre Funktion der Dynamik wiederherstellen kann.
Dazu bestimmen wir zunächst die Dynamikfunktion der ODE, entwickeln die darauf basierende Trajektorie weiter und versuchen dann, sie aus der zufällig parametrisierten Dynamikfunktion wiederherzustellen.
Lassen Sie uns zunächst den einfachsten Fall einer linearen ODE überprüfen. Die Funktion der Dynamik ist einfach die Wirkung einer Matrix.
Die trainierte Funktion wird durch eine Zufallsmatrix parametrisiert.
Weiter etwas ausgefeiltere Dynamik (ohne GIF, weil der Lernprozess nicht so schön ist :))
Die Lernfunktion ist hier ein vollständig verbundenes Netzwerk mit einer verborgenen Schicht.
Code class LinearODEF(ODEF): def __init__(self, W): super(LinearODEF, self).__init__() self.lin = nn.Linear(2, 2, bias=False) self.lin.weight = nn.Parameter(W) def forward(self, x, t): return self.lin(x)
Die Dynamikfunktion ist nur eine Matrix
class SpiralFunctionExample(LinearODEF): def __init__(self): matrix = Tensor([[-0.1, -1.], [1., -0.1]]) super(SpiralFunctionExample, self).__init__(matrix)
Zufällig parametrisierte Matrix
class RandomLinearODEF(LinearODEF): def __init__(self): super(RandomLinearODEF, self).__init__(torch.randn(2, 2)/2.)
Dynamik für anspruchsvollere Flugbahnen
class TestODEF(ODEF): def __init__(self, A, B, x0): super(TestODEF, self).__init__() self.A = nn.Linear(2, 2, bias=False) self.A.weight = nn.Parameter(A) self.B = nn.Linear(2, 2, bias=False) self.B.weight = nn.Parameter(B) self.x0 = nn.Parameter(x0) def forward(self, x, t): xTx0 = torch.sum(x*self.x0, dim=1) dxdt = torch.sigmoid(xTx0) * self.A(x - self.x0) + torch.sigmoid(-xTx0) * self.B(x + self.x0) return dxdt
Lerndynamik in Form eines vollständig vernetzten Netzwerks
class NNODEF(ODEF): def __init__(self, in_dim, hid_dim, time_invariant=False): super(NNODEF, self).__init__() self.time_invariant = time_invariant if time_invariant: self.lin1 = nn.Linear(in_dim, hid_dim) else: self.lin1 = nn.Linear(in_dim+1, hid_dim) self.lin2 = nn.Linear(hid_dim, hid_dim) self.lin3 = nn.Linear(hid_dim, in_dim) self.elu = nn.ELU(inplace=True) def forward(self, x, t): if not self.time_invariant: x = torch.cat((x, t), dim=-1) h = self.elu(self.lin1(x)) h = self.elu(self.lin2(h)) out = self.lin3(h) return out def to_np(x): return x.detach().cpu().numpy() def plot_trajectories(obs=None, times=None, trajs=None, save=None, figsize=(16, 8)): plt.figure(figsize=figsize) if obs is not None: if times is None: times = [None] * len(obs) for o, t in zip(obs, times): o, t = to_np(o), to_np(t) for b_i in range(o.shape[1]): plt.scatter(o[:, b_i, 0], o[:, b_i, 1], c=t[:, b_i, 0], cmap=cm.plasma) if trajs is not None: for z in trajs: z = to_np(z) plt.plot(z[:, 0, 0], z[:, 0, 1], lw=1.5) if save is not None: plt.savefig(save) plt.show() def conduct_experiment(ode_true, ode_trained, n_steps, name, plot_freq=10):
Wie Sie sehen können, leistet
Neural ODE einen ziemlich guten Beitrag zur Wiederherstellung der Dynamik. Das heißt, das Konzept als Ganzes funktioniert.
Überprüfen Sie nun ein etwas komplizierteres Problem (MNIST, haha).
Von ResNets inspirierte neuronale ODE
In ResNet'ax ändert sich der versteckte Zustand gemäß der Formel
wo

Ist die Blocknummer und

Dies ist eine Funktion, die von den Ebenen innerhalb des Blocks gelernt wird.
Wenn wir im Grenzfall eine unendliche Anzahl von Blöcken mit immer kleineren Schritten nehmen, erhalten wir die kontinuierliche Dynamik der verborgenen Schicht in Form einer ODE, genau wie oben.
Ausgehend von der Eingabeebene

Wir können die Ausgabeebene definieren

als Lösung für diese ODE zum Zeitpunkt T.
Jetzt können wir zählen
als verteilte (
gemeinsam genutzte ) Parameter zwischen allen infinitesimalen Blöcken.
Validierung der neuronalen ODE-Architektur auf MNIST
In diesem Teil werden wir die Fähigkeit von
Neural ODE testen, als Komponenten in bekannteren Architekturen verwendet zu werden.
Insbesondere werden wir die Restblöcke im MNIST-Klassifikator durch
Neural ODE ersetzen.
Code def norm(dim): return nn.BatchNorm2d(dim) def conv3x3(in_feats, out_feats, stride=1): return nn.Conv2d(in_feats, out_feats, kernel_size=3, stride=stride, padding=1, bias=False) def add_time(in_tensor, t): bs, c, w, h = in_tensor.shape return torch.cat((in_tensor, t.expand(bs, 1, w, h)), dim=1) class ConvODEF(ODEF): def __init__(self, dim): super(ConvODEF, self).__init__() self.conv1 = conv3x3(dim + 1, dim) self.norm1 = norm(dim) self.conv2 = conv3x3(dim + 1, dim) self.norm2 = norm(dim) def forward(self, x, t): xt = add_time(x, t) h = self.norm1(torch.relu(self.conv1(xt))) ht = add_time(h, t) dxdt = self.norm2(torch.relu(self.conv2(ht))) return dxdt class ContinuousNeuralMNISTClassifier(nn.Module): def __init__(self, ode): super(ContinuousNeuralMNISTClassifier, self).__init__() self.downsampling = nn.Sequential( nn.Conv2d(1, 64, 3, 1), norm(64), nn.ReLU(inplace=True), nn.Conv2d(64, 64, 4, 2, 1), norm(64), nn.ReLU(inplace=True), nn.Conv2d(64, 64, 4, 2, 1), ) self.feature = ode self.norm = norm(64) self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(64, 10) def forward(self, x): x = self.downsampling(x) x = self.feature(x) x = self.norm(x) x = self.avg_pool(x) shape = torch.prod(torch.tensor(x.shape[1:])).item() x = x.view(-1, shape) out = self.fc(x) return out func = ConvODEF(64) ode = NeuralODE(func) model = ContinuousNeuralMNISTClassifier(ode) if use_cuda: model = model.cuda() import torchvision img_std = 0.3081 img_mean = 0.1307 batch_size = 32 train_loader = torch.utils.data.DataLoader( torchvision.datasets.MNIST("data/mnist", train=True, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((img_mean,), (img_std,)) ]) ), batch_size=batch_size, shuffle=True ) test_loader = torch.utils.data.DataLoader( torchvision.datasets.MNIST("data/mnist", train=False, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((img_mean,), (img_std,)) ]) ), batch_size=128, shuffle=True ) optimizer = torch.optim.Adam(model.parameters()) def train(epoch): num_items = 0 train_losses = [] model.train() criterion = nn.CrossEntropyLoss() print(f"Training Epoch {epoch}...") for batch_idx, (data, target) in tqdm(enumerate(train_loader), total=len(train_loader)): if use_cuda: data = data.cuda() target = target.cuda() optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() train_losses += [loss.item()] num_items += data.shape[0] print('Train loss: {:.5f}'.format(np.mean(train_losses))) return train_losses def test(): accuracy = 0.0 num_items = 0 model.eval() criterion = nn.CrossEntropyLoss() print(f"Testing...") with torch.no_grad(): for batch_idx, (data, target) in tqdm(enumerate(test_loader), total=len(test_loader)): if use_cuda: data = data.cuda() target = target.cuda() output = model(data) accuracy += torch.sum(torch.argmax(output, dim=1) == target).item() num_items += data.shape[0] accuracy = accuracy * 100 / num_items print("Test Accuracy: {:.3f}%".format(accuracy)) n_epochs = 5 test() train_losses = [] for epoch in range(1, n_epochs + 1): train_losses += train(epoch) test() import pandas as pd plt.figure(figsize=(9, 5)) history = pd.DataFrame({"loss": train_losses}) history["cum_data"] = history.index * batch_size history["smooth_loss"] = history.loss.ewm(halflife=10).mean() history.plot(x="cum_data", y="smooth_loss", figsize=(12, 5), title="train error")
Testing... 100% 79/79 [00:01<00:00, 45.69it/s] Test Accuracy: 9.740% Training Epoch 1... 100% 1875/1875 [01:15<00:00, 24.69it/s] Train loss: 0.20137 Testing... 100% 79/79 [00:01<00:00, 46.64it/s] Test Accuracy: 98.680% Training Epoch 2... 100% 1875/1875 [01:17<00:00, 24.32it/s] Train loss: 0.05059 Testing... 100% 79/79 [00:01<00:00, 46.11it/s] Test Accuracy: 97.760% Training Epoch 3... 100% 1875/1875 [01:16<00:00, 24.63it/s] Train loss: 0.03808 Testing... 100% 79/79 [00:01<00:00, 45.65it/s] Test Accuracy: 99.000% Training Epoch 4... 100% 1875/1875 [01:17<00:00, 24.28it/s] Train loss: 0.02894 Testing... 100% 79/79 [00:01<00:00, 45.42it/s] Test Accuracy: 99.130% Training Epoch 5... 100% 1875/1875 [01:16<00:00, 24.67it/s] Train loss: 0.02424 Testing... 100% 79/79 [00:01<00:00, 45.89it/s] Test Accuracy: 99.170%
Nach einem sehr rauen Training in nur 5 Epochen und 6 Minuten Training hat das Modell bereits einen Testfehler von weniger als 1% erreicht. Wir können sagen, dass sich
neuronale ODEs als Komponente gut in traditionellere Netzwerke integrieren lassen.
In ihrem Artikel vergleichen die Autoren diesen Klassifikator (ODE-Net) auch mit einem regulären, vollständig verbundenen Netzwerk, mit ResNet mit einer ähnlichen Architektur und mit genau derselben Architektur, in der sich der Gradient direkt durch Operationen in
ODESolve ausbreitet (ohne die konjugierte Gradientenmethode) ( RK-Net).
Illustration aus dem Originalartikel.Demnach weist ein vollständig verbundenes 1-Schicht-Netzwerk mit ungefähr der gleichen Anzahl von Parametern wie
Neural ODE einen viel höheren Fehler im Test auf, ResNet mit dem gleichen Fehler hat viel mehr Parameter und RK-Net ohne die konjugierte Gradientenmethode weist einen etwas höheren Fehler auf und mit linear steigendem Speicherverbrauch (je kleiner der zulässige Fehler ist, desto mehr Schritte muss
ODESolve ausführen , wodurch sich der Speicherverbrauch linear mit der Anzahl der Schritte erhöht).
Die Autoren verwenden bei ihrer Implementierung die implizite Runge-Kutta-Methode mit adaptiver Schrittgröße, im Gegensatz zur einfacheren Euler-Methode hier. Sie untersuchen auch einige Eigenschaften der neuen Architektur.
ODE-Net-Funktion (NFE Forward - die Anzahl der Funktionsberechnungen in einem direkten Durchgang)
Illustration aus dem Originalartikel.- (a) Durch Ändern des akzeptablen Niveaus des numerischen Fehlers wird die Anzahl der Schritte bei der direkten Verteilung geändert.
- (b) Die für die direkte Verteilung aufgewendete Zeit ist proportional zur Anzahl der Berechnungen der Funktion.
- (c) Die Anzahl der Berechnungen der Funktion für die Rückausbreitung beträgt ungefähr die Hälfte der direkten Ausbreitung, was darauf hinweist, dass das konjugierte Gradientenverfahren rechnerisch effizienter sein kann als die Ausbreitung des Gradienten direkt durch ODESolve .
- (d) Da ODE-Net immer mehr trainiert wird, erfordert es immer mehr Berechnungen einer Funktion (ein immer kleinerer Schritt), die sich möglicherweise an die zunehmende Komplexität des Modells anpassen.
Versteckte generative Funktion für die Zeitreihenmodellierung
Neuronale ODE eignet sich zur Verarbeitung kontinuierlicher serieller Daten, selbst wenn der Pfad in einem unbekannten verborgenen Raum liegt.
In diesem Abschnitt werden wir experimentieren
und die Erzeugung kontinuierlicher Sequenzen mit
neuronaler ODE ändern und einen Blick auf den erlernten verborgenen Raum werfen.
Die Autoren vergleichen dies auch mit ähnlichen Sequenzen, die von wiederkehrenden Netzwerken erzeugt werden.
Das Experiment hier unterscheidet sich geringfügig von dem entsprechenden Beispiel im Autoren-Repository. Hier gibt es eine vielfältigere Reihe von Trajektorien.
Daten
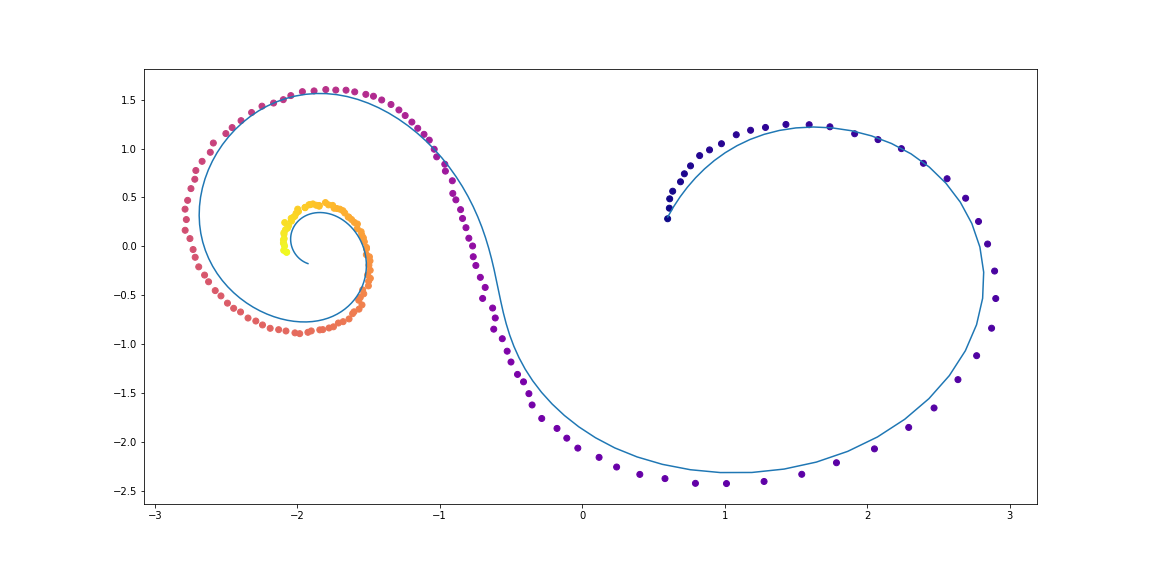
Die Trainingsdaten bestehen aus zufälligen Spiralen, von denen die Hälfte im Uhrzeigersinn und die zweite gegen den Uhrzeigersinn sind. Ferner werden zufällige Teilsequenzen aus diesen Spiralen abgetastet, die vom Codierungswiederholungsmodell in die entgegengesetzte Richtung verarbeitet werden, was zu einem verborgenen Startzustand führt, der sich dann entwickelt und eine Flugbahn im verborgenen Raum erzeugt. Dieser latente Pfad wird dann auf den Datenraum abgebildet und mit der abgetasteten Teilsequenz verglichen. Auf diese Weise lernt das Modell, Trajektorien ähnlich einem Datensatz zu generieren.
Beispiele für DatensatzspiralenVAE als generatives Modell
Generatives Modell durch ein Stichprobenverfahren:
Welches mit dem Variations-Auto-Encoder-Ansatz trainiert werden kann.
- Gehen Sie durch einen wiederkehrenden Encoder durch eine Zeitsequenz in der Zeit zurück, um die Parameter zu erhalten
 ,
,  Variations-Posterior-Verteilung und dann Probe daraus:
Variations-Posterior-Verteilung und dann Probe daraus:
- Holen Sie sich versteckte Flugbahn:
- Ordnen Sie einen versteckten Pfad einem Pfad in den Daten mithilfe eines anderen neuronalen Netzwerks zu:

- Maximieren Sie die Bewertung der unteren Gültigkeitsgrenze (ELBO) für den abgetasteten Pfad:
Und im Fall einer Gaußschen posterioren Verteilung

und bekannter Geräuschpegel

::
Das Berechnungsdiagramm eines versteckten ODE-Modells kann wie folgt dargestellt werden
Illustration aus dem Originalartikel.Dieses Modell kann dann getestet werden, wie es den Pfad nur unter Verwendung der anfänglichen Beobachtungen interpoliert.
CodeModelle definieren
class RNNEncoder(nn.Module): def __init__(self, input_dim, hidden_dim, latent_dim): super(RNNEncoder, self).__init__() self.input_dim = input_dim self.hidden_dim = hidden_dim self.latent_dim = latent_dim self.rnn = nn.GRU(input_dim+1, hidden_dim) self.hid2lat = nn.Linear(hidden_dim, 2*latent_dim) def forward(self, x, t):
Datensatzgenerierung
t_max = 6.29*5 n_points = 200 noise_std = 0.02 num_spirals = 1000 index_np = np.arange(0, n_points, 1, dtype=np.int) index_np = np.hstack([index_np[:, None]]) times_np = np.linspace(0, t_max, num=n_points) times_np = np.hstack([times_np[:, None]] * num_spirals) times = torch.from_numpy(times_np[:, :, None]).to(torch.float32)
Schulung
vae = ODEVAE(2, 64, 6) vae = vae.cuda() if use_cuda: vae = vae.cuda() optim = torch.optim.Adam(vae.parameters(), betas=(0.9, 0.999), lr=0.001) preload = False n_epochs = 20000 batch_size = 100 plot_traj_idx = 1 plot_traj = orig_trajs[:, plot_traj_idx:plot_traj_idx+1] plot_obs = samp_trajs[:, plot_traj_idx:plot_traj_idx+1] plot_ts = samp_ts[:, plot_traj_idx:plot_traj_idx+1] if use_cuda: plot_traj = plot_traj.cuda() plot_obs = plot_obs.cuda() plot_ts = plot_ts.cuda() if preload: vae.load_state_dict(torch.load("models/vae_spirals.sd")) for epoch_idx in range(n_epochs): losses = [] train_iter = gen_batch(batch_size) for x, t in train_iter: optim.zero_grad() if use_cuda: x, t = x.cuda(), t.cuda() max_len = np.random.choice([30, 50, 100]) permutation = np.random.permutation(t.shape[0]) np.random.shuffle(permutation) permutation = np.sort(permutation[:max_len]) x, t = x[permutation], t[permutation] x_p, z, z_mean, z_log_var = vae(x, t) z_var = torch.exp(z_log_var) kl_loss = -0.5 * torch.sum(1 + z_log_var - z_mean**2 - z_var, -1) loss = 0.5 * ((x-x_p)**2).sum(-1).sum(0) / noise_std**2 + kl_loss loss = torch.mean(loss) loss /= max_len loss.backward() optim.step() losses.append(loss.item()) print(f"Epoch {epoch_idx}") frm, to, to_seed = 0, 200, 50 seed_trajs = samp_trajs[frm:to_seed] ts = samp_ts[frm:to] if use_cuda: seed_trajs = seed_trajs.cuda() ts = ts.cuda() samp_trajs_p = to_np(vae.generate_with_seed(seed_trajs, ts)) fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(15, 9)) axes = axes.flatten() for i, ax in enumerate(axes): ax.scatter(to_np(seed_trajs[:, i, 0]), to_np(seed_trajs[:, i, 1]), c=to_np(ts[frm:to_seed, i, 0]), cmap=cm.plasma) ax.plot(to_np(orig_trajs[frm:to, i, 0]), to_np(orig_trajs[frm:to, i, 1])) ax.plot(samp_trajs_p[:, i, 0], samp_trajs_p[:, i, 1]) plt.show() print(np.mean(losses), np.median(losses)) clear_output(wait=True) spiral_0_idx = 3 spiral_1_idx = 6 homotopy_p = Tensor(np.linspace(0., 1., 10)[:, None]) vae = vae if use_cuda: homotopy_p = homotopy_p.cuda() vae = vae.cuda() spiral_0 = orig_trajs[:, spiral_0_idx:spiral_0_idx+1, :] spiral_1 = orig_trajs[:, spiral_1_idx:spiral_1_idx+1, :] ts_0 = samp_ts[:, spiral_0_idx:spiral_0_idx+1, :] ts_1 = samp_ts[:, spiral_1_idx:spiral_1_idx+1, :] if use_cuda: spiral_0, ts_0 = spiral_0.cuda(), ts_0.cuda() spiral_1, ts_1 = spiral_1.cuda(), ts_1.cuda() z_cw, _ = vae.encoder(spiral_0, ts_0) z_cc, _ = vae.encoder(spiral_1, ts_1) homotopy_z = z_cw * (1 - homotopy_p) + z_cc * homotopy_p t = torch.from_numpy(np.linspace(0, 6*np.pi, 200)) t = t[:, None].expand(200, 10)[:, :, None].cuda() t = t.cuda() if use_cuda else t hom_gen_trajs = vae.decoder(homotopy_z, t) fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(15, 5)) axes = axes.flatten() for i, ax in enumerate(axes): ax.plot(to_np(hom_gen_trajs[:, i, 0]), to_np(hom_gen_trajs[:, i, 1])) plt.show() torch.save(vae.state_dict(), "models/vae_spirals.sd")
Das passiert nach einer Nacht des TrainingsPunkte sind verrauschte Beobachtungen der ursprünglichen Flugbahn (blau),
gelb sind rekonstruierte und interpolierte Flugbahnen, wobei Punkte als Eingaben verwendet werden.
Die Farbe des Punktes zeigt die Zeit.Rekonstruktionen einiger Beispiele sehen nicht besonders gut aus. Vielleicht ist das Modell nicht komplex genug oder nicht lange genug untersucht. In jedem Fall sieht die Rekonstruktion sehr vernünftig aus.Nun wollen wir sehen, was passiert, wenn wir eine versteckte Variable im Uhrzeigersinn in einen Anti-Uhr-Pfad interpolieren.Die Autoren vergleichen auch Rekonstruktionen und Pfadinterpolationen zwischen neuronaler ODE und einem einfachen rekursiven Netzwerk.Illustration aus dem Originalartikel.Kontinuierliche Normalisierung von Streams
Der Originalartikel bringt auch viel zum Thema Normalisieren von Streams. Normalisierende Flüsse werden verwendet, wenn Sie eine Stichprobe aus einer komplexen Verteilung erstellen müssen, die durch eine Änderung von Variablen aus einer einfachen Verteilung (z. B. Gauß) entsteht, und dennoch die Wahrscheinlichkeitsdichte am Punkt jeder Stichprobe kennen.Die Autoren zeigen, dass die Verwendung der kontinuierlichen Variablensubstitution viel rechnerisch effizienter und interpretierbarer ist als frühere Methoden.Das Normalisieren von Flüssen ist in Modellen wie Variation AutoCoders , Bayesian Neural Networks und anderen aus dem Bayesian-Ansatz sehr nützlich .Dieses Thema ist jedoch über den Rahmen diesesArtikel, und diejenigen, die interessiert sind, sollten den ursprünglichen wissenschaftlichen Artikel lesen.Für Saatgut:Visualisierung der Transformation von Rauschen (einfache Verteilung) zu Daten (komplexe Verteilung) für zwei Datensätze;
Die X-Achse zeigt die Transformation von Dichte und Proben im Verlauf von „Zeit“ (für NS) und „Tiefe“ (für NS).
Illustration aus dem OriginalartikelVielen Dank an bekemax für die Hilfe bei der Bearbeitung der englischen Version des Textes und für interessante physische Kommentare.Damit ist meine kleine Forschung zu neuronalen ODEs abgeschlossen . Vielen Dank für Ihre Aufmerksamkeit!
Nützliche Links