Hallo allerseits! Der Frühling ist gekommen, was bedeutet, dass weniger als ein Monat vor dem Start des
Python Developer- Kurses verbleibt. Diesem Kurs widmet sich unsere heutige Veröffentlichung.

 Aufgaben:
Aufgaben:- Erfahren Sie mehr über die interne Struktur von Python;
- die Prinzipien der Erstellung eines abstrakten Syntaxbaums (AST) verstehen;
- Schreiben Sie effizienteren Code in Zeit und Speicher.
Vorläufige Empfehlungen:- Grundlegendes Verständnis des Dolmetschers (AST, Token usw.).
- Kenntnisse in Python.
- Grundkenntnisse von C.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
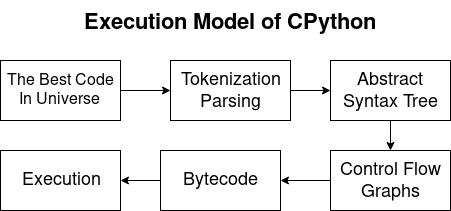
CPython-AusführungsmodellPython ist eine kompilierte und interpretierte Sprache. Somit generiert der Python-Compiler Bytecodes und der Interpreter führt sie aus. Während des Artikels werden wir die folgenden Punkte betrachten:
- Analyse und Tokenisierung:
- Transformation in AST;
- Kontrollflussdiagramm (CFG);
- Bytecode
- Wird auf einer virtuellen CPython-Maschine ausgeführt.
Analyse und Tokenisierung.
Grammatik.Grammatik definiert die Semantik der Python-Sprache. Es ist auch nützlich, um anzugeben, wie der Parser die Sprache interpretieren soll. Die Python-Grammatik verwendet eine Syntax ähnlich der erweiterten Backus-Naur-Form. Es hat eine eigene Grammatik für einen Übersetzer aus der Ausgangssprache. Sie finden die Grammatikdatei im Verzeichnis „cpython / Grammar / Grammar“.
Das Folgende ist ein Beispiel für eine Grammatik:
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
Einfache Ausdrücke enthalten kleine Ausdrücke und Klammern, und der Befehl endet mit einer neuen Zeile. Kleine Ausdrücke sehen aus wie eine Liste von Ausdrücken, die ...
Einige andere Ausdrücke :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
Tokenisierung (Lexing)Bei der Tokenisierung wird ein Textdatenstrom abgerufen und in Token mit signifikanten (für den Interpreter) Wörtern mit zusätzlichen Metadaten aufgeteilt (z. B. wo das Token beginnt und endet und wie hoch der Zeichenfolgenwert dieses Tokens ist).
TokenEin Token ist eine Header-Datei, die Definitionen aller Token enthält. In Python gibt es 59 Arten von Token (Include / token.h).
Unten finden Sie ein Beispiel für einige von ihnen:
Sie sehen sie, wenn Sie Python-Code in Token aufteilen.
Tokenisierung mit CLIHier ist die Datei tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
Dann tokenisieren wir es mit dem Befehl python -m tokenize und es wird Folgendes ausgegeben:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
Hier zeigen die Zahlen (z. B. 1.4-1.13), wo der Token begann und wo er endete. Ein Codierungstoken ist immer das allererste Token, das wir erhalten. Es enthält Informationen zur Codierung der Quelldatei. Wenn Probleme damit auftreten, löst der Interpreter eine Ausnahme aus.
Tokenisierung mit tokenize.tokenizeWenn Sie die Datei aus Ihrem Code tokenisieren müssen, können Sie das
Tokenize- Modul von
stdlib verwenden .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
Der Token-Typ ist seine ID in der Header-Datei
token.h. String ist der Wert des Tokens. Start und Ende zeigen an, wo der Token beginnt bzw. endet.
In anderen Sprachen werden Blöcke durch Klammern oder begin / end-Anweisungen angezeigt, Python verwendet jedoch Einrückungen und verschiedene Ebenen. Einrückungs- und DEDENT-Token und zeigen Einrückung an. Diese Token werden benötigt, um relationale Analysebäume und / oder abstrakte Syntaxbäume zu erstellen.
Parser-GenerierungParser-Generierung - Ein Prozess, der einen Parser gemäß einer bestimmten Grammatik generiert. Parser-Generatoren werden als PGen bezeichnet. Cpython verfügt über zwei Parser-Generatoren. Eines ist das Original (
Parser/pgen ) und eines wurde in Python (
/Lib/lib2to3/pgen2 )
/Lib/lib2to3/pgen2 .
"Der ursprüngliche Generator war der erste Code, den ich für Python geschrieben habe"
-GuidoAus dem obigen Zitat wird deutlich, dass
pgen das Wichtigste in einer Programmiersprache ist. Wenn Sie pgen (in
Parser / pgen )
aufrufen , werden eine Header-Datei und eine C-Datei (der Parser selbst) generiert. Wenn Sie sich den generierten C-Code ansehen, erscheint er möglicherweise sinnlos, da sein aussagekräftiges Erscheinungsbild optional ist. Es enthält viele statische Daten und Strukturen. Als nächstes werden wir versuchen, die Hauptkomponenten zu erklären.
DFA (Defined State Machine)Der Parser definiert einen DFA für jedes Nichtterminal. Jeder DFA ist als Array von Zuständen definiert.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
Für jeden DFA gibt es ein Starter-Kit, das zeigt, mit welchen Token ein spezielles Nicht-Terminal beginnen kann.
ZustandJeder Zustand wird durch ein Array von Übergängen / Kanten (Bögen) definiert.
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
Übergänge (Bögen)Jedes Übergangsarray hat zwei Zahlen. Die erste Zahl ist der Name des Übergangs (Bogenbezeichnung) und bezieht sich auf die Symbolnummer. Die zweite Nummer ist das Ziel.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
Namen (Labels)Dies ist eine spezielle Tabelle, die die ID des Zeichens dem Namen des Übergangs zuordnet.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
Die Nummer 1 entspricht allen Bezeichnern. Somit erhält jeder von ihnen unterschiedliche Übergangsnamen, auch wenn sie alle dieselbe Zeichen-ID haben.
Ein einfaches Beispiel:Angenommen, wir haben einen Code, der "Hi" ausgibt, wenn 1 - true:
if 1: print('Hi')
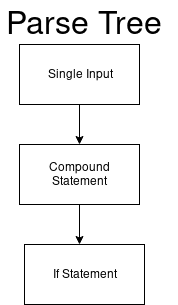
Der Parser betrachtet diesen Code als single_input.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
Dann beginnt unser Parsing-Baum am Wurzelknoten einer einmaligen Eingabe.

Und der Wert unseres DFA (single_input) ist 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
Es wird so aussehen:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2},
};
Hier besteht
arc_0_0 aus drei Elementen. Die erste ist
NEWLINE , die zweite ist
simple_stmt und die letzte ist
compound_stmt .
Angesichts der anfänglichen Menge von
simple_stmt wir schließen, dass
simple_stmt nicht mit
if beginnen
if . Selbst wenn
if keine neue Zeile ist, kann
compound_stmt dennoch mit
if beginnen. Daher fahren wir mit dem letzten
arc ({4;2}) fügen den Knoten connect_stmt zum Analysebaum hinzu und wechseln zum neuen DFA, bevor wir mit Nummer 2 fortfahren. Wir erhalten einen aktualisierten Analysebaum:

Das neue DFA analysiert zusammengesetzte Anweisungen.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
Und wir bekommen folgendes:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
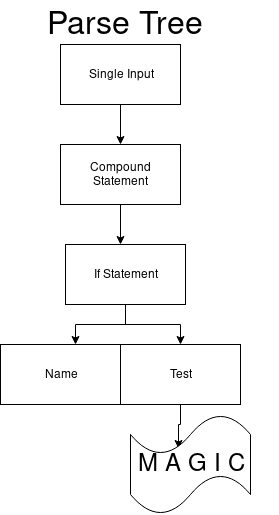
Nur der erste Sprung kann mit
if beginnen. Wir erhalten einen aktualisierten Analysebaum.
Dann ändern wir wieder den DFA und das nächste DFA ifs.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
Als Ergebnis erhalten wir den einzigen Übergang mit der Bezeichnung 97. Er stimmt mit dem
if Token überein.
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
Wenn wir zum nächsten Status wechseln und im selben DFA verbleiben, hat der nächste arcs_41_1 auch nur einen Übergang. Dies gilt für das Testterminal. Es muss mit einer Zahl beginnen (z. B. 1).
Es gibt nur einen Übergang in arc_41_2, der das Doppelpunkt-Token (:) erhält.

Wir erhalten also einen Satz, der mit einem Druckwert beginnen kann. Gehen Sie schließlich zu arcs_41_4. Der erste Übergang in der Menge ist ein elif-Ausdruck, der zweite ist ein else und der dritte ist für den letzten Zustand. Und wir bekommen die endgültige Ansicht des Analysebaums.
 Python-Schnittstelle für Parser.
Python-Schnittstelle für Parser.
Mit Python können Sie den Analysebaum für Ausdrücke mithilfe eines Moduls namens Parser bearbeiten.
>>> import parser >>> code = "if 1: print('Hi')"
Mit parser.suite können Sie einen bestimmten Syntaxbaum (Concrete Syntax Tree, CST) generieren.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
Der Ausgabewert ist eine verschachtelte Liste. Jede Liste in der Struktur enthält 2 Elemente. Die erste ist die ID des Zeichens (0-256 - Terminals, 256+ - Nicht-Terminals) und die zweite ist die Zeichenfolge für das Terminal.
Abstrakter SyntaxbaumTatsächlich ist ein abstrakter Syntaxbaum (AST) eine strukturelle Darstellung des Quellcodes in Form eines Baums, wobei jeder Scheitelpunkt verschiedene Arten von Sprachkonstrukten bezeichnet (Ausdruck, Variable, Operator usw.).
Was ist ein Baum?Ein Baum ist eine Datenstruktur mit einem Wurzelscheitelpunkt als Ausgangspunkt. Der Wurzelscheitelpunkt wird durch Zweige (Übergänge) zu anderen Scheitelpunkten abgesenkt. Jeder Scheitelpunkt mit Ausnahme der Wurzel hat einen eindeutigen übergeordneten Scheitelpunkt.
Es gibt einen gewissen Unterschied zwischen dem abstrakten Syntaxbaum und dem Analysebaum.
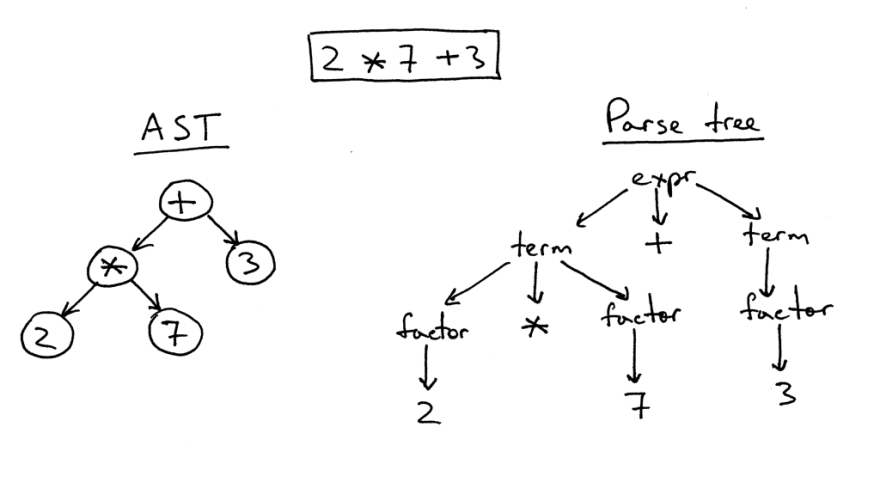
Rechts ist ein Analysebaum für den Ausdruck 2 * 7 + 3. Dies ist buchstäblich ein Eins-zu-Eins-Quellbild in Form eines Baumes. Alle Ausdrücke, Begriffe und Werte sind darauf sichtbar. Ein solches Bild ist jedoch für ein einfaches Stück Code zu kompliziert, sodass wir einfach alle syntaktischen Ausdrücke entfernen können, die wir im Code für die Berechnungen definieren mussten.
Ein solcher vereinfachter Baum wird als abstrakter Syntaxbaum (AST) bezeichnet. Links in der Abbildung wird es genau für den gleichen Code angezeigt. Alle Syntaxausdrücke wurden zum besseren Verständnis verworfen. Beachten Sie jedoch, dass bestimmte Informationen verloren gegangen sind.
Beispiel
Python bietet ein integriertes AST-Modul für die Arbeit mit AST. Um Code aus AST-Bäumen zu generieren, können Sie Module von Drittanbietern verwenden, z. B.
Astor .
Betrachten Sie beispielsweise denselben Code wie zuvor.
>>> import ast >>> code = "if 1: print('Hi')"
Um AST zu erhalten, verwenden wir die ast.parse-Methode.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
Versuchen Sie es mit der
ast.dump Methode, um einen besser lesbaren abstrakten Syntaxbaum zu erhalten.
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
AST wird im Allgemeinen als visueller und leichter zu verstehen angesehen als der Parsing-Baum.
Kontrollfluss Graf (CFG)Kontrollflussdiagramme sind Richtungsdiagramme, die den Ablauf eines Programms mithilfe von Basisblöcken modellieren, die eine Zwischendarstellung enthalten.
In der Regel ist CFG der vorherige Schritt, bevor die Ausgabecodewerte abgerufen werden. Der Code wird direkt aus den Basisblöcken mithilfe einer Rückwärts-Tiefensuche in CFG generiert, beginnend von oben.
BytecodePython-Bytecode ist ein Zwischensatz von Anweisungen, die in einer virtuellen Python-Maschine funktionieren. Wenn Sie den Quellcode ausführen, erstellt Python ein Verzeichnis mit dem Namen __pycache__. Der kompilierte Code wird gespeichert, um beim Neustart der Kompilierung Zeit zu sparen.
Betrachten Sie eine einfache Python-Funktion in func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
Der
say_hello ist eine Funktion.
>>> type(say_hello) <class 'function'>
Es hat das Attribut
__code__ .
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
CodeobjekteCodeobjekte sind unveränderliche Datenstrukturen, die die Anweisungen oder Metadaten enthalten, die zum Ausführen des Codes erforderlich sind. Einfach ausgedrückt sind dies Darstellungen von Python-Code. Sie können Codeobjekte auch abrufen, indem Sie abstrakte Syntaxbäume mithilfe der
Kompilierungsmethode kompilieren .
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
Jedes Codeobjekt verfügt über Attribute, die bestimmte Informationen enthalten (mit dem Präfix co_). Hier erwähnen wir nur einige von ihnen.
co_nameZunächst einmal - ein Name. Wenn eine Funktion vorhanden ist, muss sie jeweils einen Namen haben. Dieser Name ist der Name der Funktion, ähnlich wie bei der Klasse. Im AST-Beispiel verwenden wir Module und können dem Compiler genau mitteilen, wie wir sie benennen möchten. Lassen Sie sie nur ein
module .
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnamesDies ist ein Tupel, das alle lokalen Variablen einschließlich der Argumente enthält.
>>> say_hello.__code__.co_varnames ('name',)
co_contsEin Tupel, das alle Literale und konstanten Werte enthält, auf die wir im Hauptteil der Funktion zugegriffen haben. Es ist erwähnenswert, den Wert von None zu beachten. Wir haben None nicht in den Hauptteil der Funktion aufgenommen, Python hat dies jedoch angegeben. Wenn die Funktion ausgeführt wird und dann endet, ohne Rückgabewerte zu erhalten, wird None zurückgegeben.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
Bytecode (co_code)Das Folgende ist der Bytecode unserer Funktion.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
Dies ist keine Zeichenfolge, sondern ein Byte-Objekt, dh eine Folge von Bytes.
>>> type(bytecode) <class 'bytes'>
Das erste gedruckte Zeichen ist "t". Wenn wir nach seinem numerischen Wert fragen, erhalten wir Folgendes.
>>> ord('t') 116
116 ist dasselbe wie Bytecode [0].
>>> assert bytecode[0] == ord('t')
Ein Wert von 116 bedeutet für uns nichts. Glücklicherweise bietet Python eine Standardbibliothek namens dis (from disassembly). Dies ist nützlich, wenn Sie mit der Opname-Liste arbeiten. Dies ist eine Liste aller Bytecode-Anweisungen, wobei jeder Index der Name der Anweisung ist.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
Lassen Sie uns eine weitere komplexere Funktion erstellen.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
Und wir finden die erste Anweisung im Bytecode heraus.
>>> dis.opname[bytecode[0]] 'LOAD_FAST
Die LOAD_FAST-Anweisung besteht aus zwei Elementen.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
Der Befehl Loadfast 0 sucht zufällig nach Variablennamen in einem Tupel und schiebt ein Element mit einem Nullindex in ein Tupel im Ausführungsstapel.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
Unser Code kann mit dis.dis zerlegt und der Bytecode in eine vertraute Ansicht konvertiert werden. Hier sind die Zahlen (2,3,4) die Zeilennummern. Jede Codezeile in Python wird als Befehlssatz erweitert.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
VorlaufzeitCPython ist eine stapelorientierte virtuelle Maschine, keine Sammlung von Registern. Dies bedeutet, dass Python-Code für eine virtuelle Maschine mit einer Stapelarchitektur kompiliert wird.
Beim Aufrufen einer Funktion verwendet Python zwei Stapel zusammen. Der erste ist der Ausführungsstapel und der zweite ist der Blockstapel. Die meisten Aufrufe erfolgen auf dem Ausführungsstapel. Der Blockstapel verfolgt, wie viele Blöcke derzeit aktiv sind, sowie andere Parameter, die sich auf Blöcke und Bereiche beziehen.
Wir freuen uns auf Ihre Kommentare zu dem Material und laden Sie zu
einem offenen Webinar zum Thema „Release it: Praktische Aspekte der Veröffentlichung zuverlässiger Software“ ein, das von unserem Lehrer, dem Programmierer des Werbesystems in Mail.Ru,
Stanislav Stupnikov, durchgeführt wird .