Wenn Sie nur einen Ansatz für das Web-Scraping kennen, wird das Problem kurzfristig gelöst, aber alle Methoden haben ihre Stärken und Schwächen. Das Bewusstsein dafür spart Zeit und hilft, das Problem effizienter zu lösen.

Zahlreiche Ressourcen sprechen von der einzig wahren Methode zum Abrufen von Daten von einer Webseite. Die Realität ist jedoch, dass Sie hierfür verschiedene Lösungen und Tools verwenden können.
- Welche Möglichkeiten gibt es, um programmgesteuert Daten von einer Webseite abzurufen?
- Vor- und Nachteile jedes Ansatzes?
- Wie können Cloud-Ressourcen verwendet werden, um den Automatisierungsgrad zu erhöhen?
Der Artikel hilft, Antworten auf diese Fragen zu erhalten.
Ich
gehe davon aus, dass Sie bereits wissen, was
HTTP- Anforderungen,
DOM (Document Object Model),
HTML ,
CSS-Selektoren und
Async JavaScript sind .
Wenn nicht, rate ich Ihnen, sich mit der Theorie zu befassen und dann zum Artikel zurückzukehren.
Statischer Inhalt
HTML-QuellenBeginnen wir mit dem einfachsten Ansatz.
Wenn Sie Webseiten verschrotten möchten, ist dies das erste, mit dem Sie beginnen. Es erfordert wenig Computerleistung und ein Minimum an Zeit.
Dies funktioniert jedoch nur, wenn der HTML-Quellcode die Daten enthält, auf die Sie abzielen. Um dies in Chrome zu testen, klicken Sie mit der rechten Maustaste auf die Seite und wählen Sie Seitencode anzeigen. Sie sollten jetzt den HTML-Quellcode sehen.
Wenn Sie die Daten gefunden haben, schreiben Sie einen
CSS-Selektor , der zum Wrapping-Element gehört, damit Sie später einen Link haben.
Zur Implementierung können Sie eine HTTP-GET-Anforderung an die URL der Seite senden und den HTML-Quellcode zurückerhalten.
In
Node können Sie das
CheerioJS- Tool verwenden,
um Roh-HTML zu
analysieren und Daten mithilfe eines Selektors abzurufen. Der Code sieht folgendermaßen aus:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
Dynamischer Inhalt
In vielen Fällen können Sie nicht auf Informationen aus rohem HTML-Code zugreifen, da das DOM von JavaScript gesteuert wurde, das im Hintergrund ausgeführt wird. Ein typisches Beispiel hierfür ist ein SPA (Single-Page-Anwendung), bei dem ein HTML-Dokument nur minimale Informationen enthält und diese zur Laufzeit von JavaScript ausgefüllt werden.
In dieser Situation besteht die Lösung darin, das DOM zu erstellen und die im HTML-Quellcode enthaltenen Skripts auszuführen, wie dies der Browser tut. Danach können Daten mit Selektoren aus diesem Objekt extrahiert werden.
Headless BrowserDer kopflose Browser ist der gleiche wie ein normaler Browser, nur ohne Benutzeroberfläche. Es wird im Hintergrund ausgeführt und kann programmgesteuert gesteuert werden, anstatt über die Tastatur zu klicken und zu tippen.
Puppenspieler ist einer der beliebtesten Headless-Browser. Dies ist eine benutzerfreundliche Knotenbibliothek, die eine allgemeine API für die Offline-Verwaltung von Chrome bietet. Es kann so konfiguriert werden, dass es ohne Header ausgeführt wird, was während der Entwicklung sehr praktisch ist. Der folgende Code macht dasselbe wie zuvor, funktioniert jedoch mit dynamischen Seiten:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
Natürlich können Sie mit Puppeteer interessantere Dinge tun, lesen Sie also die
Dokumentation . Hier ist ein Codeausschnitt, der durch die URL navigiert, einen Screenshot macht und ihn speichert:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
Der Browser benötigt viel mehr Rechenleistung als das Senden einer einfachen GET-Anfrage und das Analysieren der Antwort. Daher ist die Ausführung relativ langsam. Nicht nur das, sondern auch das Hinzufügen eines Browsers als Abhängigkeit macht das Paket massiv.
Andererseits ist diese Methode sehr flexibel. Sie können damit Seiten navigieren, Klicks und Mausbewegungen simulieren und die Tastatur verwenden, Formulare ausfüllen, Screenshots erstellen oder PDF-Seiten erstellen, Befehle in der Konsole ausführen und Elemente zum Extrahieren von Textinhalten auswählen. Grundsätzlich alles, was manuell in einem Browser erledigt werden kann.
Ein DOM bauenSie werden denken, dass es nicht notwendig ist, einen ganzen Browser zu simulieren, nur um ein DOM zu erstellen. Tatsächlich ist dies zumindest unter bestimmten Umständen der Fall.
Jsdom ist eine
Knotenbibliothek , die das übertragene HTML analysiert, genau wie ein Browser. Dies ist jedoch kein Browser, sondern ein
Tool zum Erstellen des DOM aus einem bestimmten HTML-Quellcode sowie zum Ausführen von JavaScript-Code in diesem HTML.
Dank dieser Abstraktion kann Jsdom schneller als ein kopfloser Browser ausgeführt werden. Wenn es schneller ist, warum nicht die ganze Zeit anstelle von Headless-Browsern verwenden?
Zitat aus der Dokumentation :
Bei der Verwendung von jsdom treten häufig Probleme beim asynchronen Laden von Skripten auf. Viele Seiten laden Skripte asynchron, aber es ist unmöglich zu bestimmen, wann dies passiert ist und wann der Code ausgeführt und die resultierende DOM-Struktur überprüft werden muss. Dies ist eine grundlegende Einschränkung.
Diese Lösung ist im Beispiel dargestellt. Alle 100 ms wird überprüft, ob ein Element aufgetreten ist oder eine Zeitüberschreitung aufgetreten ist (nach 2 Sekunden).
Es werden auch häufig Fehlermeldungen ausgegeben, wenn Jsdom einige Browserfunktionen auf der Seite nicht implementiert, z.
B .: "
Fehler: Nicht implementiert: window.alert ..." oder "Fehler: Nicht implementiert: window.scrollTo ... ". Dieses Problem kann auch mit einigen Problemumgehungen (
virtuellen Konsolen ) gelöst werden.
Dies ist normalerweise eine API auf niedrigerer Ebene als Puppeteer, daher müssen Sie einige Dinge selbst implementieren.
Dies erschwert die Verwendung ein wenig, wie aus dem Beispiel hervorgeht.
Jsdom bietet eine schnelle Lösung für denselben Job.
Schauen wir uns das gleiche Beispiel an, aber mit
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
Reverse EngineeringJsdom ist eine schnelle und einfache Lösung, aber Sie können es noch einfacher machen.
Müssen wir das DOM modellieren?
Die Webseite, die Sie verschrotten möchten, besteht aus demselben HTML und JavaScript, denselben Technologien, die Sie bereits kennen.
Wenn Sie also einen Code finden, aus dem die Zieldaten abgerufen wurden, können Sie denselben Vorgang wiederholen, um dasselbe Ergebnis zu erzielen .
Zur Vereinfachung können folgende Daten gesucht werden:
- Teil des HTML-Quellcodes (wie aus dem ersten Teil des Artikels ersichtlich),
- Teil einer statischen Datei, auf die in einem HTML-Dokument verwiesen wird (z. B. eine Zeile in einer Javascript-Datei),
- Antwort auf eine Netzwerkanforderung (z. B. hat ein JavaScript-Code eine AJAX-Anforderung an einen Server gesendet, der mit einer JSON-Zeichenfolge geantwortet hat).
Auf diese Datenquellen kann über Netzwerkabfragen zugegriffen werden . Es spielt keine Rolle, ob die Webseite HTTP, WebSockets oder ein anderes Kommunikationsprotokoll verwendet, da alle theoretisch reproduzierbar sind.
Sobald Sie eine Ressource mit Daten gefunden haben, können Sie eine ähnliche Netzwerkanforderung an denselben Server wie auf der Originalseite senden. Als Ergebnis erhalten Sie eine Antwort mit den Zieldaten, die einfach mit regulären Ausdrücken, Zeichenfolgenmethoden, JSON.parse usw. extrahiert werden können.
Mit einfachen Worten, Sie können die Ressource verwenden, auf der sich die Daten befinden, anstatt das gesamte Material zu verarbeiten und zu laden. Somit kann das in den vorherigen Beispielen gezeigte Problem mit einer einzelnen HTTP-Anforderung gelöst werden, anstatt einen Browser oder ein komplexes JavaScript-Objekt zu steuern.
Diese Lösung scheint theoretisch einfach zu sein, kann jedoch in den meisten Fällen zeitaufwändig sein und erfordert Erfahrung mit Webseiten und Servern.
Beginnen Sie mit der Überwachung des Netzwerkverkehrs. Ein großartiges Tool hierfür ist die Registerkarte "
Netzwerk" in Chrome DevTools . Sie sehen alle ausgehenden Anforderungen mit Antworten (einschließlich statischer Dateien, AJAX-Anforderungen usw.), um sie zu durchlaufen und nach Daten zu suchen.
Wenn die Antwort durch einen Code geändert wird, bevor sie auf dem Bildschirm angezeigt wird, ist der Vorgang langsamer. In diesem Fall müssen Sie diesen Teil des Codes finden und verstehen, was los ist.
Wie Sie sehen können, erfordert eine solche Methode möglicherweise viel mehr Arbeit als die oben beschriebenen Methoden. Auf der anderen Seite bietet es die beste Leistung.
Das Diagramm zeigt die erforderliche Laufzeit und Paketgröße im Vergleich zu Jsdom und Puppeteer:
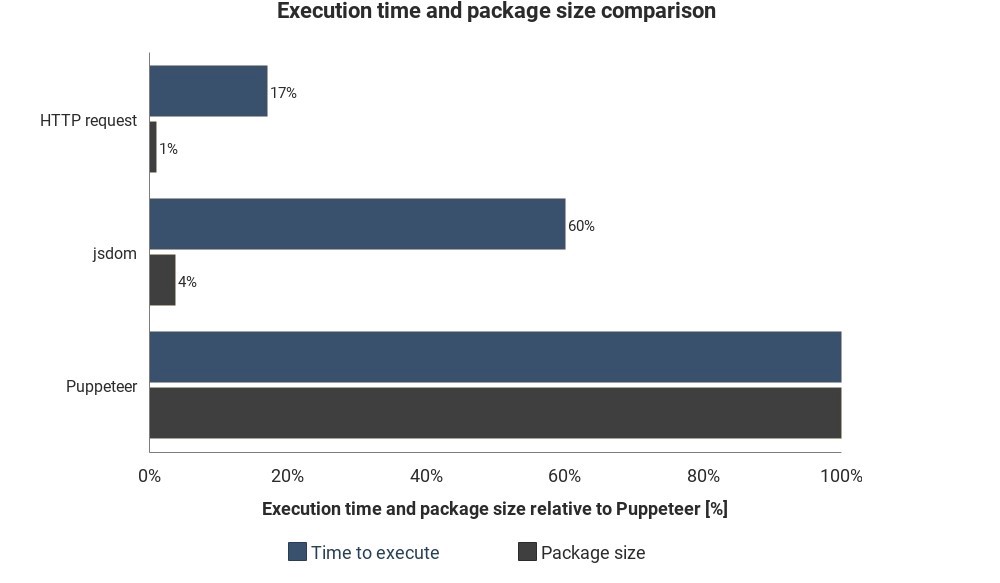
Die Ergebnisse basieren nicht auf genauen Messungen und können variieren, zeigen jedoch gute ungefähre Unterschiede zwischen diesen Methoden.
Cloud-Service-Integration
Angenommen, Sie haben eine dieser Lösungen implementiert. Eine Möglichkeit, das Skript auszuführen, besteht darin, den Computer einzuschalten, das Terminal zu öffnen und manuell zu starten.
Es wird jedoch ärgerlich und ineffizient. Daher ist es besser, wenn Sie das Skript einfach auf den Server hochladen und den Code abhängig von den Einstellungen regelmäßig ausführen.
Dies kann durch Starten des eigentlichen Servers und Festlegen der Regeln für die Ausführung des Skripts erfolgen. In anderen Fällen ist die Cloud-Funktion einfacher.
Cloud-Funktionen sind Speicher, in denen heruntergeladener Code ausgeführt wird, wenn ein Ereignis eintritt. Dies bedeutet, dass Sie die Server nicht verwalten müssen. Dies wird automatisch von Ihrem Cloud-Anbieter durchgeführt.
Ein Auslöser kann ein Zeitplan, eine Netzwerkanforderung und viele andere Ereignisse sein. Sie können die gesammelten Daten in einer Datenbank speichern, in ein
Google-Blatt schreiben oder per
E-Mail senden. Es hängt alles von Ihrer Vorstellungskraft ab.
Beliebte Cloud-Anbieter -
Amazon Web Services (AWS),
Google Cloud Platform (GCP) und
Microsoft Azure :
Sie können diese Dienste kostenlos, aber nicht lange nutzen.
Wenn Sie Puppeteer verwenden, sind
Google Cloud-
Funktionen die einfachste Lösung. Die Paketgröße im Headless Chrome-Format (~ 130 MB) überschreitet die maximal zulässige Archivgröße in AWS Lambda (50 MB). Es gibt verschiedene Methoden, damit es mit Lambda funktioniert, aber GCP-Funktionen
unterstützen standardmäßig
Chrome ohne Header . Sie müssen Puppeteer lediglich als Abhängigkeit in
package.json einfügen .
Wenn Sie mehr über Cloud-Funktionen im Allgemeinen erfahren möchten, lesen Sie die Architekturinformationen ohne Server. Zu diesem Thema wurden bereits viele gute Tutorials geschrieben, und die meisten Anbieter verfügen über eine leicht verständliche Dokumentation.