Unter dem Schnitt ist die Geschichte, wie der Bereich des maschinellen Lernens im Dodo erschien. Spoiler: Ich habe es gestartet. Hardcore technische Details werden nicht hier sein, stellen Sie sicher, dass Sie ihnen einen separaten Artikel widmen. Heute geht es mehr um die Motivation und Unterstützung von Kollegen.

Vorbereitung
Ich bin dreimal auf das Thema maschinelles Lernen gestoßen, bis etwas Wertvolles dabei herauskam.
Russische Schule
Das erste Mal, dass ich an der HSE auf maschinelles Lernen stieß, bekam ich einen zweiten Turm in Richtung Big Data Systems, als ich einen Job in Dodo bekam. Nachdem ich dieses große Hype-Thema auf einer Tangente durchgearbeitet hatte, verstand ich nicht, warum ich überhaupt drei Jahre meines Lebens verbracht hatte. Und noch mehr habe ich nicht darüber nachgedacht, wie dies im Unternehmen nützlich sein könnte. Ich war damals nicht bereit für diese Herausforderung des Schicksals.
Tschechische Reise
Das zweite Mal bin ich in Prag beim geschlossenen Hackathon für maschinelles Lernen von Microsoft auf dieses Thema gestoßen. Zusammen mit Mitarbeitern anderer Unternehmen haben wir an der Prognose der Nachfrage in Dodo in den Ferien und an Spitzentagen gearbeitet. Ich kehrte mit einem vorgefertigten Modell zurück, das die Nachfrage vorhersagt. Nach diesem Hackathon tauchten Gedanken auf, dass ich das erworbene Wissen im Unternehmen anwenden könnte. Da war es.
Hast du ein Model in Jupyter, na und? Wie benutzt man es? Alle Versuche, dies dem Geschäft zu erklären, waren mit einer harten Realität konfrontiert: Es ist daher klar, dass es an Feiertagen und Spitzentagen viele Bestellungen geben wird. Erwachsene Pizzerien können Verkäufe anhand von Daten aus dem letzten Jahr vorhersagen, und neue hatten Probleme ohne diese. Wir haben Versuche, maschinelles Lernen zu entwickeln, verschoben. Aber die Idee, dass wir mit Daten mehr erreichen können, steckt zu fest in meinem Kopf und wollte nicht da raus. Jetzt war ich bereit für die Herausforderung, aber das Unternehmen war es nicht.
Amerikanischer Traum
Das dritte Treffen wurde schicksalhaft. Unser Team hatte eine schwierige, aber interessante Aufgabe: ein maßgeschneidertes Pizzamodul für die USA zu entwickeln. In diesem Fall können Sie Pizza mit beliebigen Zutaten bestellen und Ihr eigenes Rezept erstellen. Im Projekt musste alles ausgearbeitet werden: von Änderungen in der Datenbankarchitektur bis zum Clientcode auf der Site. Wir haben uns der Aufgabe gestellt und ein Produkt entwickelt, das ich für einen echten Sieg halte. Die Hauptbewertung wurde von Alena, unserer CEO in den USA, ins Stocken geraten.

Wir haben das Modul gemacht, aber ich habe ein Problem bei der Skalierung gesehen. Was ist, wenn die Funktionalität nicht in einer oder zwei Pizzerien in den Bundesstaaten, sondern in einem großen Netzwerk angezeigt wird? Wie man ein solches Produkt verwaltet, Lagerbestände plant? Ich entschied, dass dieser Fall die Notwendigkeit für die Entwicklung des maschinellen Lernens in Dodo beweisen könnte. Ich hatte das Gefühl, dass diesmal sowohl ich als auch das Unternehmen bereit waren, eine neue Richtung einzuschlagen.
Eins zu eins mit Autos
Im Hintergrund begann ich, den Verkauf von amerikanischer Pizza nach Maß zu analysieren. Mithilfe von Clustering-Algorithmen konnte gezeigt werden, dass alle von Benutzern erstellten Rezepte auf sechs Grundsätzen von Zutaten sowie einigen zufälligen basieren. Selbst ein einfacher Bericht, der auf diesem Algorithmus basiert, würde halbmanuelle Umsatzprognosen und Planinventare ermöglichen. Aufgrund des Mangels an Bürokratie und der Fähigkeit, unterwegs wieder aufzubauen, erhielten wir grünes Licht, um uns auf diese Richtung einzulassen.
Der technische Direktor und ich haben mehr als einmal verstanden und diskutiert, dass ich das derzeitige Team verlassen und eine neue Richtung entwickeln muss, um zu zeigen, dass wir es brauchen. Ich musste schnell in eine neue Sphäre eintauchen. Ich habe verstanden, dass es zwei Möglichkeiten gibt, wenn es nicht funktioniert. Die erste besteht darin, in einem anderen Dodo-Team zur Entwicklung zurückzukehren. Die zweite besteht darin, Ihren Lebenslauf auf HH zu aktualisieren und nach einem neuen Job zu suchen. Ich wollte weder den einen noch den anderen. Ich war ungefähr drei Monate in diesem Zustand, bis ich mich auf das zusätzliche Verkaufsmodul einließ.
Erstes Projekt
Ein weiterer Spoiler: Es stellte sich heraus, dass man zum Ausführen von ML nicht auf etwas Kompliziertes stoßen muss. Offensichtlich nicht? Aber es ist zu Beginn der Reise sehr schwer zu verstehen.
Das Modul, das vorschlägt, der Bestellung ein zusätzliches Produkt hinzuzufügen, wird von niemandem direkt gesteuert. Das heißt, ich kann mit ihm machen, was ich will. Kirsche auf dem Kuchen - eine Gelegenheit, den Umsatz mithilfe personalisierterer Angebote zu steigern. Bisher funktionierte das Modul einfach: Wenn der Bestellung Pizza hinzugefügt wurde, wurde die Getränkekategorie in zusätzlichen Verkäufen angezeigt, wenn Pizza und Getränk, dann Desserts und so weiter.
Die Gleichgültigkeit einer großen Anzahl von Menschen hat erneut gezeigt, dass ich in einem Unternehmen arbeite, in dem absolut jeder Unterstützung leisten kann. Ich habe stundenlang mit einem Marketingkollegen an Daten und zusätzlichen Angeboten gearbeitet. Wir haben es geschafft, alle Benutzer nach ihren Geschmackspräferenzen und ihrer Loyalität zu gruppieren, damit jede Gruppe statische Angebote basierend auf den Top-Produkten im Cluster macht.
Zahlen und Beweise
Ich habe die Protokollierung zusätzlicher Produkte vermasselt und neue Angebote für eine Stichprobe von 2 Millionen Benutzern veröffentlicht.
Eine Stichprobe von Benutzern ist nur ein kleiner Teil des Umsatzes. Es war notwendig, sich nicht autorisierten und neuen Kunden zuzuwenden. Ich habe genug Artikel und Literatur über kollaboratives Filtern und verschiedene Angebotsalgorithmen für Benutzer geschaufelt. Die Idee von Empfehlungen basierend auf den Produkten im Warenkorb hat gewonnen. Artikelbasierte Empfehlungen und ein Kosinusmaß für die Konvergenz bildeten die Grundlage für ein neues, wenn auch einfaches, aber bereits funktionierendes Modell.
Im Dezember haben wir das Modul Item-Based Recommendations gestartet. Statistiken haben gezeigt, dass Käufer tatsächlich an völlig anderen Produkten interessiert sein können, nicht nur an Getränken. Vielleicht glaubte der Dodo danach, dass die Daten und die Entwicklung des maschinellen Lernens es ihnen ermöglichen würden, in den künftig überlasteten Märkten zu konkurrieren.
Einige Statistiken.
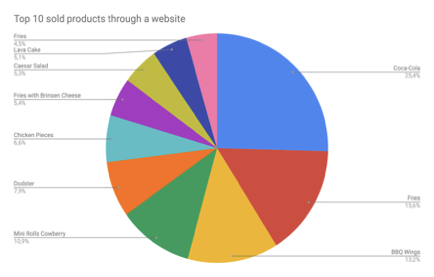
10 meistverkaufte Produkte auf der Website

10 meistverkaufte mobile App-Produkte

Wöchentliches Umsatzwachstum
Technischer Trailer
Im Folgenden finden Sie einige technische Details, warum das Modell auf einem Kosinus-Ähnlichkeitsmaß basiert. Dies ist eine Vorschau des Artikels, der in ein paar Monaten veröffentlicht wird. Wenn Sie Mathematik nicht mögen, können Sie zum letzten Abschnitt springen.
Die folgende Tabelle zeigt die Anzahl der Bestellungen mit den gekauften Waren jedes Benutzers. Wir können die Ähnlichkeit von Einkäufen eines Benutzers mit einem anderen bestimmen - dazu müssen wir den Abstand zwischen Benutzervektoren berechnen.
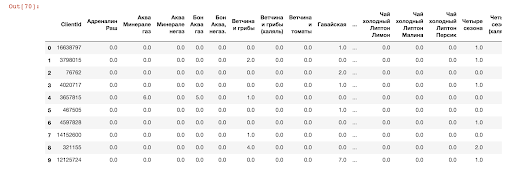
Kundenverkaufstabelle
Die Entfernung hängt von der ausgewählten Metrik ab. Die Berechnung des euklidischen Raums umfasst das Gewicht und die Größe des Vektors:

Dabei sind a und b zwei verschiedene Clientvektoren aus der Tabelle. Mal sehen, wie dieser Abstand in einem abstrakten Beispiel aussehen wird.
Angenommen, wir betrachten die Geschichte von drei Kunden - a, b und c. Lassen Sie uns eine Matrix ihrer Einkäufe erstellen.

Nachdem wir die euklidischen Abstände zwischen Kunden berechnet haben, erhalten wir die folgenden Werte:
d (a, b) = 16,22;
d (b, c) = 13,38;
d (a, c) = 13,64.
Diese Werte zeigen an, dass die Clients b und c einander am nächsten sind. Wenn Sie sich jedoch die Quelldaten ansehen, ist das Bild umgekehrt. Kunden a und b bestellen lieber mehr Pepperoni und gelegentlich andere Produkte, während Kunde c Supreme Pizza bevorzugt. Wir können daraus schließen, dass sich die Größe des Vektors negativ auf die Berechnung der Entfernungen zwischen Kunden auswirkt. Das Kosinus-Ähnlichkeitsmaß berücksichtigt nur den Winkel zwischen den Vektoren und verwirft die Bedeutung der Größe des Vektors:

Wenn wir die Entfernung mit dieser Formel berechnen, erhalten wir:
d (a, b) = 0,9183;
d (b, c) = 0,5848;
d (a, c) = 0,7947;
Wir sehen, dass die Kunden a und b näher beieinander liegen. Sie bevorzugen einen Warensatz ohne Berücksichtigung der unterschiedlichen Anzahl der Bestellungen. Diese Logik stimmt mit unserer Expertenmeinung überein und legt nahe, dass die Präferenzen der Kunden a und b einander am nächsten sind.
Dies ist ein Trailer, Details in zwei Monaten.
Suchen Sie nach Ihrem
Jetzt bilden wir ein Team, in dem Spezialisten für die Organisation der Datenspeicherung, die Entwicklung von Modellen für maschinelles Lernen und deren Umsetzung in die Produktion tätig sein werden. Vor allem aber verstehen wir jetzt besser, warum wir das alles brauchen. Es steht uns frei, wirklich coole Dinge zu tun, von der Organisation eines intelligenten Logistiksystems und der Bestandsplanung bis hin zu fantastischen Ideen für die Automatisierung von Pizzerien mithilfe von Computer Vision-Technologien.
Glauben Sie an sich und Ihre Stärken, auch wenn das Ergebnis am Horizont nicht sichtbar ist. Ich möchte den Artikel mit dem Gedanken eines anderen beenden - einem Zitat von Max Weber aus seinem Bericht an Studenten der Universität München: "Mit Traurigkeit und Erwartung kann man nichts anfangen, und man muss anders handeln - man muss sich seiner Arbeit zuwenden und die" Nachfrage des Tages "erfüllen - als Mensch. so professionell. Und diese Anforderung wird einfach und klar sein, wenn jeder seinen eigenen Dämon findet und diesem Dämon gehorcht und den Faden seines Lebens webt. “ Finde deine.