
Was nervt Sie am meisten, wenn Sie daran denken, sich bei NodeJS anzumelden? Wenn Sie mich fragen, werde ich sagen, dass es an Industriestandards für die Erstellung von Trace-IDs mangelt. In diesem Artikel werden wir einen Überblick darüber geben, wie wir diese Trace-IDs erstellen können (dh wir werden kurz untersuchen, wie die Fortsetzung des lokalen Speichers, auch bekannt als CLS, funktioniert) und uns eingehend damit befassen , wie wir Proxy verwenden können , damit es mit JEDEM Logger funktioniert.
Warum ist es überhaupt ein Problem, für jede Anforderung in NodeJS eine Ablaufverfolgungs-ID zu haben?
Nun, auf Plattformen, die Multithreading verwenden und für jede Anforderung einen neuen Thread erzeugen. Es gibt einen so genannten Thread-lokalen Speicher, auch bekannt als TLS , der es ermöglicht, beliebige Daten für alles innerhalb eines Threads verfügbar zu halten. Wenn Sie dazu über eine native API verfügen, ist es ziemlich trivial, für jede Anforderung eine zufällige ID zu generieren. Fügen Sie diese in TLS ein und verwenden Sie sie später in Ihrem Controller oder Dienst. Also, was ist mit NodeJS los?
Wie Sie wissen, ist NodeJS eine Single-Thread-Plattform (die nicht mehr wirklich stimmt, da wir jetzt Mitarbeiter haben, aber das ändert nichts am Gesamtbild), die TLS überflüssig macht. Anstatt verschiedene Threads zu betreiben, führt NodeJS verschiedene Rückrufe innerhalb desselben Threads aus (es gibt eine große Reihe von Artikeln zur Ereignisschleife in NodeJS, wenn Sie interessiert sind), und NodeJS bietet uns die Möglichkeit, diese Rückrufe eindeutig zu identifizieren und ihre Beziehungen zueinander zu verfolgen .
Früher (v0.11.11) hatten wir addAsyncListener, mit dem wir asynchrone Ereignisse verfolgen konnten. Darauf aufbauend baute Forrest Norvell die erste Implementierung von Continuation Local Storage, auch bekannt als CLS . Wir werden diese Implementierung von CLS nicht behandeln, da wir als Entwickler diese API bereits in Version 0.12 entfernt haben.
Bis NodeJS 8 hatten wir keine offizielle Möglichkeit, eine Verbindung zur asynchronen Ereignisverarbeitung von NodeJS herzustellen. Und schließlich hat uns NodeJS 8 die Leistung gewährt, die wir über async_hooks verloren haben (wenn Sie async_hooks besser verstehen möchten, lesen Sie diesen Artikel ). Dies bringt uns zur modernen async_hooks-basierten Implementierung von CLS - cls-hooked.
CLS-Übersicht
Hier ist ein vereinfachter Ablauf der Funktionsweise von CLS:
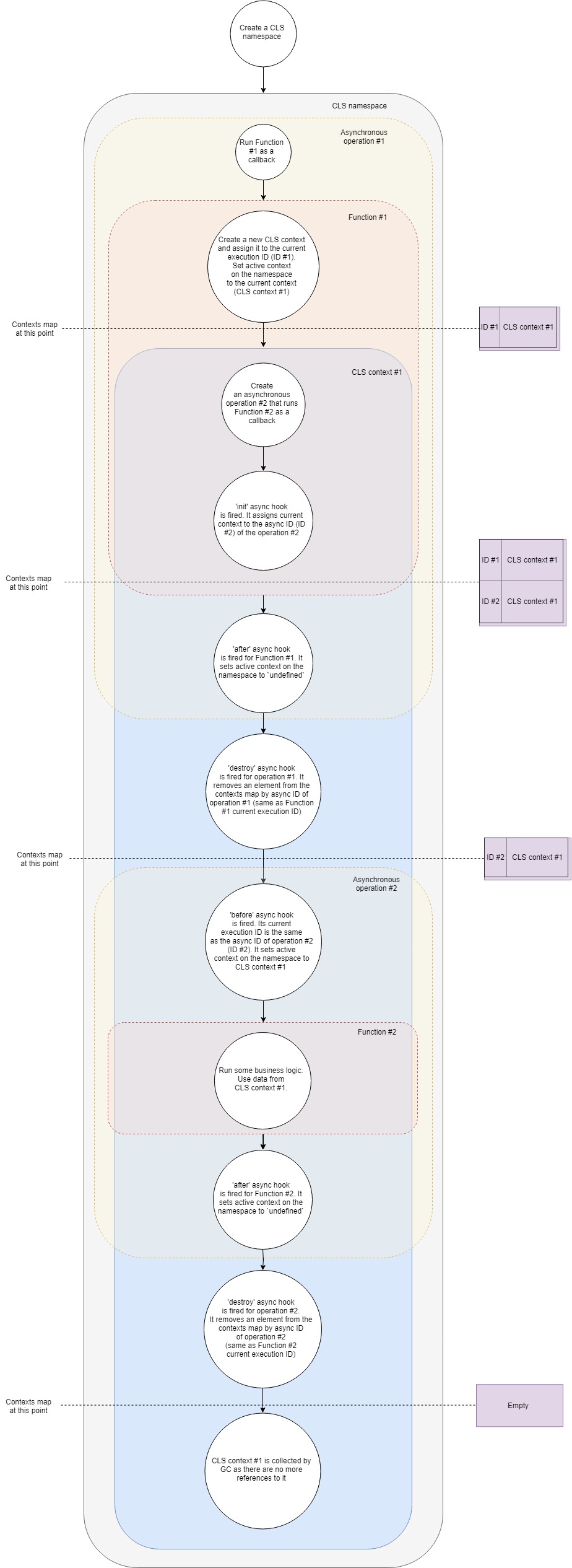
Lassen Sie es uns Schritt für Schritt aufschlüsseln:
- Angenommen, wir haben einen typischen Webserver. Zuerst müssen wir einen CLS-Namespace erstellen. Einmal für die gesamte Lebensdauer unserer Anwendung.
- Zweitens müssen wir eine Middleware konfigurieren, um für jede Anforderung einen neuen CLS-Kontext zu erstellen. Nehmen wir der Einfachheit halber an, dass diese Middleware nur ein Rückruf ist, der beim Empfang einer neuen Anforderung aufgerufen wird.
- Wenn also eine neue Anfrage eintrifft, rufen wir diese Rückruffunktion auf.
- Innerhalb dieser Funktion erstellen wir einen neuen CLS-Kontext (eine der Möglichkeiten ist die Verwendung des Run- API-Aufrufs).
- Zu diesem Zeitpunkt fügt CLS den neuen Kontext anhand der aktuellen Ausführungs-ID in eine Kontextkarte ein .
- Jeder CLS-Namespace verfügt über eine
active Eigenschaft. Zu diesem Zeitpunkt weist CLS dem Kontext active zu. - Innerhalb des Kontexts rufen wir eine asynchrone Ressource auf, beispielsweise fordern wir einige Daten aus der Datenbank an. Wir übergeben einen Rückruf an den Anruf, der ausgeführt wird, sobald die Anforderung an die Datenbank abgeschlossen ist.
- Der asynchrone init- Hook wird für einen neuen asynchronen Betrieb ausgelöst. Es fügt den aktuellen Kontext der Karte der Kontexte nach asynchroner ID hinzu (betrachten Sie ihn als Kennung der neuen asynchronen Operation).
- Da unser erster Rückruf keine Logik mehr enthält, wird er beendet und beendet unsere erste asynchrone Operation.
- Nachdem der asynchrone Hook für den ersten Rückruf ausgelöst wurde. Der aktive Kontext im Namespace wird auf
undefined (dies ist nicht immer der Fall, da möglicherweise mehrere verschachtelte Kontexte vorhanden sind, im einfachsten Fall jedoch). - Der Zerstörungshaken wird für die erste Operation abgefeuert. Der Kontext wird durch seine asynchrone ID aus unserer Kontextkarte entfernt (entspricht der aktuellen Ausführungs-ID unseres ersten Rückrufs).
- Die Anforderung an die Datenbank ist abgeschlossen und unser zweiter Rückruf steht kurz vor dem Auslösen.
- Zu diesem Zeitpunkt kommt der asynchrone Hook ins Spiel. Die aktuelle Ausführungs-ID entspricht der asynchronen ID der zweiten Operation (Datenbankanforderung). Es setzt die
active Eigenschaft des Namespace auf den Kontext, der durch seine aktuelle Ausführungs-ID gefunden wird. Es ist der Kontext, den wir zuvor erstellt haben. - Jetzt führen wir unseren zweiten Rückruf durch. Führen Sie eine Geschäftslogik aus. Innerhalb dieser Funktion können wir jeden Wert per Schlüssel vom CLS abrufen und er wird alles zurückgeben, was er durch den Schlüssel in dem zuvor erstellten Kontext findet.
- Unter der Annahme, dass die Verarbeitung der Anforderung beendet ist, gibt unsere Funktion zurück.
- nachdem der asynchrone Hook für den zweiten Rückruf ausgelöst wurde. Es setzt den aktiven Kontext im Namespace auf
undefined . destroy wird für die zweite asynchrone Operation ausgelöst. Es entfernt unseren Kontext von der Karte der Kontexte durch seine asynchrone ID und lässt ihn absolut leer.- Da wir keine Verweise mehr auf das Kontextobjekt haben, gibt unser Garbage Collector den damit verbundenen Speicher frei.
Es ist eine vereinfachte Version dessen, was unter der Haube vor sich geht, deckt jedoch alle wichtigen Schritte ab. Wenn Sie tiefer graben möchten, können Sie sich den Quellcode ansehen. Es sind weniger als 500 Zeilen.
Trace-IDs generieren
Sobald wir ein umfassendes Verständnis von CLS haben, überlegen wir, wie wir es zu unserem eigenen Wohl nutzen können. Eine traceID besteht darin, eine Middleware zu erstellen, die jede Anforderung in einen Kontext traceID , eine zufällige Kennung generiert und diese über die Schlüssel- traceID in CLS traceID . Später, innerhalb eines unserer Millionen Controller und Services, konnten wir diese Kennung von CLS erhalten.
Für Express könnte diese Middleware folgendermaßen aussehen:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Dann könnten wir in unserem Controller die Trace-ID wie folgt generieren lassen:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Diese Trace-ID wird nur dann verwendet, wenn wir sie unseren Protokollen hinzufügen.
Fügen wir es unserem Winston hinzu .
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Wenn alle Logger Formatierer in Form von Funktionen unterstützen würden (viele von ihnen tun dies aus gutem Grund nicht), würde dieser Artikel nicht existieren. Wie würde man meinem geliebten Pino eine Trace-ID hinzufügen? Stellvertreter zur Rettung!
Proxy und CLS kombinieren
Proxy ist ein Objekt, das unser ursprüngliches Objekt umschließt und es uns ermöglicht, sein Verhalten in bestimmten Situationen zu überschreiben. Die Liste dieser Situationen (sie werden eigentlich als Fallen bezeichnet) ist begrenzt, und Sie können sich hier das gesamte Set ansehen, aber wir sind nur an Fallen interessiert. Es bietet uns die Möglichkeit, den Zugriff auf Immobilien abzufangen. Wenn wir ein Objekt const a = { prop: 1 } und es in einen Proxy a.prop können wir mit get trap alles zurückgeben, was wir für a.prop wollen.
Die Idee ist also, für jede Anforderung eine zufällige Trace-ID zu generieren und einen untergeordneten Pino-Logger mit der Trace-ID zu erstellen und in CLS abzulegen. Dann könnten wir unseren ursprünglichen Logger mit einem Proxy umschließen, der alle Protokollierungsanforderungen an den untergeordneten Logger in CLS umleitet, wenn einer gefunden wird, und ansonsten den ursprünglichen Logger weiter verwendet.
In diesem Szenario könnte unser Proxy folgendermaßen aussehen:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Unsere Middleware würde sich in so etwas verwandeln:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Und wir könnten den Logger so verwenden:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Basierend auf der obigen Idee wurde eine kleine Bibliothek namens cls-proxify erstellt. Es ist sofort in Express , Koa und Fastify integriert.
Dies gilt nicht nur für das ursprüngliche Objekt, sondern auch für viele andere . Es gibt also endlos mögliche Anwendungen. Sie könnten Funktionsaufrufe, Klassenaufbau, so ziemlich alles vertreten! Sie sind nur durch Ihre Vorstellungskraft begrenzt!
Schauen Sie sich Live-Demos zur Verwendung mit Pino an und beschleunigen Sie, Pino und Express .
Hoffentlich haben Sie etwas Nützliches für Ihr Projekt gefunden. Zögern Sie nicht, mir Ihr Feedback mitzuteilen! Ich freue mich über Kritik und Fragen.