
Was macht Sie am meisten wütend, wenn Sie versuchen, lesbare Protokolle in Ihrer NodeJS-Anwendung zu organisieren? Persönlich ärgere ich mich sehr über das Fehlen vernünftiger Standards für die Erstellung von Trace-IDs. In diesem Artikel werden wir über die Optionen zum Erstellen einer Trace-ID sprechen. Schauen wir uns an, wie Continuation-Local Storage oder CLS an unseren Fingern funktioniert, und nutzen Sie die Stärke von Proxy , um alles mit absolut jedem Logger zu erhalten.
Warum gibt es in NodeJS ein Problem beim Erstellen einer Trace-ID für jede Anforderung?
In den alten, alten, alten Zeiten, als Mammuts noch auf der Erde liefen, waren All-All-All-Server Multithread-Server und erstellten einen neuen Thread für eine Anfrage. Im Rahmen dieses Paradigmas ist das Erstellen einer Trace-ID trivial, weil Es gibt so etwas wie threadlokalen Speicher oder TLS , mit dem Sie einige Daten in den Speicher stellen können, die für jede Funktion in diesem Stream verfügbar sind. Zu Beginn der Verarbeitung der Anforderung können Sie die zufällige Ablaufverfolgungs-ID einlösen, in TLS ablegen und dann in einem beliebigen Dienst lesen und etwas damit tun. Das Problem ist, dass dies in NodeJS nicht funktioniert.
NodeJS ist Single-Threaded (angesichts des Erscheinungsbilds von Workern nicht ganz, aber im Rahmen des Problems mit der Trace-ID spielen Worker keine Rolle), sodass Sie TLS vergessen können. Hier ist das Paradigma anders - um eine Reihe verschiedener Rückrufe innerhalb desselben Threads zu jonglieren. Sobald die Funktion etwas Asynchrones ausführen möchte, senden Sie diese asynchrone Anforderung und geben Sie dem Prozessor Zeit für eine andere Funktion in der Warteschlange (wenn Sie daran interessiert sind, wie dieses Ding funktioniert, das stolz als Ereignisschleife bezeichnet wird unter der Haube empfehle ich, diese Artikelserie zu lesen). Wenn Sie darüber nachdenken, wie NodeJS versteht, welcher Rückruf wann angerufen werden soll, können Sie davon ausgehen, dass jeder von ihnen einer ID entsprechen muss. Darüber hinaus verfügt NodeJS sogar über eine API, die den Zugriff auf diese IDs ermöglicht. Wir werden es benutzen.
In der Antike, als Mammuts ausgestorben waren, aber die Menschen die Vorteile des zentralen Abwassers noch nicht kannten (NodeJS v0.11.11), hatten wir addAsyncListener . Darauf aufbauend erstellte Forrest Norvell die erste Implementierung von Continuation-Local Storage oder CLS . Wir werden jedoch nicht darüber sprechen, wie es damals funktioniert hat, da diese API (ich spreche von addAsyncLustener) eine lange Lebensdauer hat. Er ist bereits in NodeJS v0.12 gestorben.
Vor NodeJS 8 gab es keine offizielle Möglichkeit, die Warteschlange asynchroner Ereignisse zu verfolgen. Und schließlich stellten NodeJS-Entwickler in Version 8 die Gerechtigkeit wieder her und präsentierten uns die async_hooks-API . Wenn Sie mehr über async_hooks erfahren möchten, empfehlen wir Ihnen, diesen Artikel zu lesen. Basierend auf async_hooks wurde das Refactoring der vorherigen CLS-Implementierung durchgeführt. Die Bibliothek heißt cls-hooked .
CLS unter der Haube
Im Allgemeinen kann das CLS-Operationsschema wie folgt dargestellt werden:
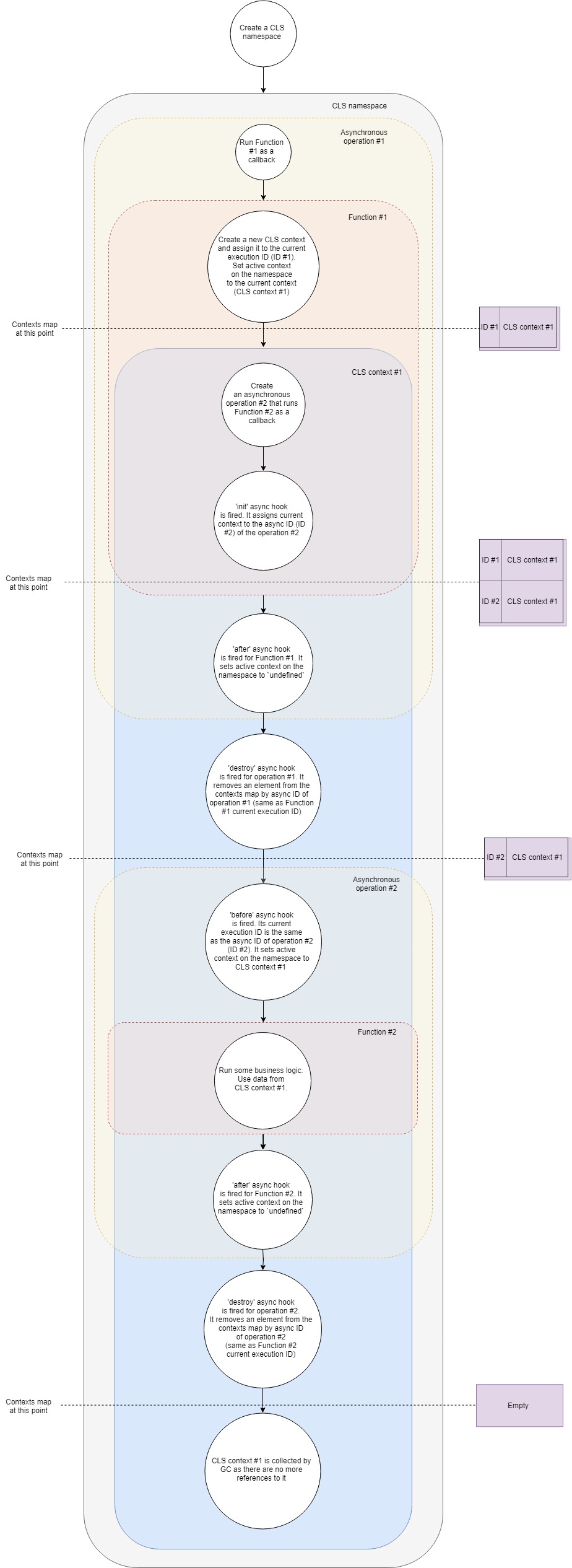
Nehmen wir es etwas genauer:
- Angenommen, wir haben einen typischen Express -Webserver. Erstellen Sie zunächst einen neuen CLS-Namespace. Ein für alle Mal für die gesamte Lebensdauer der Anwendung.
- Zweitens werden wir Middleware erstellen, die für jede Anforderung unseren eigenen CLS-Kontext erstellt.
- Wenn eine neue Anforderung eingeht, wird diese Middleware (Funktion 1) aufgerufen.
- Erstellen Sie in dieser Funktion einen neuen CLS-Kontext (als eine Option können Sie Namespace.run verwenden ). In Namespace.run übergeben wir eine Funktion, die im Rahmen unseres Kontexts ausgeführt wird.
- CLS fügt Map einen neu erstellten Kontext mit Kontexten mit dem aktuellen Ausführungs-ID- Schlüssel hinzu.
- Jeder CLS-Namespace verfügt über eine
active Eigenschaft. CLS weist dieser Eigenschaft einen Verweis auf unseren Kontext zu. - In einem Kontextbereich führen wir beispielsweise eine Art asynchrone Abfrage an die Datenbank durch. Wir übergeben den Rückruf an den Datenbanktreiber, der aufgerufen wird, wenn die Anforderung abgeschlossen ist.
- Der asynchrone Init- Hook wird ausgelöst . Es fügt der Karte den aktuellen Kontext mit Kontexten nach asynchroner ID (ID der neuen asynchronen Operation) hinzu.
- Weil Unsere Funktion hat keine zusätzlichen Anweisungen mehr und schließt die Ausführung ab.
- Ein asynchroner After Hook funktioniert für sie. Es weist die
active Eigenschaft einem undefined Namespace zu (in der Tat nicht immer, da wir mehrere verschachtelte Kontexte haben können, aber im einfachsten Fall ist dies der Fall). - Der asynchrone Zerstörungshaken wird für unsere erste asynchrone Operation ausgelöst. Es entfernt den Kontext aus der Zuordnung mit Kontexten anhand der asynchronen ID dieser Operation (sie entspricht der aktuellen Ausführungs-ID des ersten Rückrufs).
- Die Abfrage in der Datenbank ist abgeschlossen und der zweite Rückruf wird aufgerufen.
- Asynchroner Hook vorher . Die aktuelle Ausführungs-ID entspricht der asynchronen ID der zweiten Operation (Datenbankabfrage). Der
active Eigenschaft des Namespace wird der in der Map gefundene Kontext mit Kontexten anhand der aktuellen Ausführungs-ID zugewiesen. Dies ist der Kontext, den wir zuvor erstellt haben. - Nun wird der zweite Rückruf ausgeführt. Eine Art Geschäftslogik funktioniert, die Teufel tanzen, Wodka gießt. Darin können wir jeden Wert aus dem Kontext per Schlüssel erhalten . CLS versucht, den angegebenen Schlüssel im aktuellen Kontext zu finden oder gibt
undefined . - Der asynchrone After- Hook für diesen Rückruf wird ausgelöst, wenn er abgeschlossen ist. Es setzt die
active Eigenschaft des Namespace auf undefined . - Der asynchrone Zerstörungshaken wird für diesen Vorgang ausgelöst. Es entfernt den Kontext aus der Karte mit Kontexten anhand der asynchronen ID dieser Operation (sie entspricht der aktuellen Ausführungs-ID des zweiten Rückrufs).
- Der Garbage Collector (GC) gibt Speicher frei, der dem Kontextobjekt zugeordnet ist, weil In unserer Anwendung gibt es keine Links mehr dazu.
Dies ist eine vereinfachte Ansicht dessen, was unter der Haube geschieht, deckt jedoch die Hauptphasen und -schritte ab. Wenn Sie etwas tiefer graben möchten, empfehle ich Ihnen, sich mit den Sorten vertraut zu machen. Es gibt nur 500 Codezeilen.
Trace-ID erstellen
Nachdem wir uns mit dem CLS befasst haben, werden wir versuchen, dieses Ding zum Wohle der Menschheit zu nutzen. Erstellen wir eine Middleware, die für jede Anforderung einen eigenen CLS-Kontext erstellt, eine zufällige Trace-ID erstellt und diese mithilfe der Schlüssel-Trace-ID zum Kontext traceID . Dann erhalten wir innerhalb des Ofigilliard unserer Controller und Services diese Trace-ID.
Für Express könnte eine ähnliche Middleware folgendermaßen aussehen:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Und in unserem Controller oder Service können wir diese traceID in nur einer Codezeile erhalten:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Ohne diese Trace-ID zu den Protokollen hinzuzufügen, profitiert sie davon, wie bei einer Schneefräse im Sommer.
Schreiben wir einen einfachen Winston- Formatierer, der automatisch die Trace-ID hinzufügt.
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Und wenn alle Logger benutzerdefinierte Formatierer in Form von Funktionen unterstützen würden (viele von ihnen haben Gründe, dies nicht zu tun), wäre dieser Artikel wahrscheinlich nicht gewesen. Wie können Sie also eine Protokoll-ID zu den Protokollen des verehrten Pinos hinzufügen?
Wir rufen Proxy an, um JEDEN Logger und CLS zu finden
Ein paar Worte zu Proxy selbst: Dies ist so etwas, das unser ursprüngliches Objekt umhüllt und es uns ermöglicht, sein Verhalten in bestimmten Situationen neu zu definieren. In einer streng definierten begrenzten Liste von Situationen (in der Wissenschaft werden sie traps ). Die vollständige Liste finden Sie hier , wir sind nur an Trap Get interessiert. Es gibt uns die Möglichkeit, den Rückgabewert beim Zugriff auf die Eigenschaft des Objekts zu überschreiben, d. H. Wenn wir das Objekt const a = { prop: 1 } und es in Proxy a.prop können wir mit Hilfe von trap get alles zurückgeben, was wir wollen, wenn wir a.prop .
Im Fall von pino lautet pino Idee: Wir erstellen für jede Anforderung eine zufällige Ablaufverfolgungs-ID, erstellen eine untergeordnete Pino-Instanz, an die wir diese Ablaufverfolgungs-ID übergeben, und fügen diese untergeordnete Instanz in das CLS ein. Anschließend verpacken wir unseren Quelllogger in Proxy, der dieselbe untergeordnete Instanz für die Protokollierung verwendet, wenn ein aktiver Kontext vorhanden ist und sich ein untergeordneter Logger darin befindet, oder verwenden den ursprünglichen Logger.
In einem solchen Fall sieht der Proxy folgendermaßen aus:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Unsere Middleware sieht folgendermaßen aus:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Und wir können den Logger so verwenden:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Basierend auf der obigen Idee wurde eine kleine cls-proxify-Bibliothek erstellt. Sie arbeitet sofort mit Express , Koa und Fastify . Zusätzlich zum Erstellen einer Falle für get werden andere Fallen erstellt , um dem Entwickler mehr Freiheit zu geben. Aus diesem Grund können wir Proxy verwenden, um Funktionen, Klassen und mehr zu verpacken. Es gibt eine Live-Demo zur Integration von Pino und Fastify, Pino und Express .
Ich hoffe, Sie haben keine Zeit umsonst verschwendet, und der Artikel war zumindest ein wenig nützlich für Sie. Bitte treten und kritisieren. Wir werden lernen, gemeinsam besser zu codieren.