Vor etwas mehr als einem Monat fand in Moskau die größte Konferenz der Post-Gree-Community PGConf.Russia 2019 statt, an der mehr als 700 Personen an der Moskauer Staatsuniversität teilnahmen. Wir haben uns entschlossen, ein Video und eine Abschrift der besten Berichte zu veröffentlichen.
Ivan Frolkovs Präsentation
über typische Fehler bei der Arbeit mit PostgreSQL wurde auf der Konferenz als die beste bezeichnet, daher werden wir damit beginnen.
Der Einfachheit halber haben wir die Entschlüsselung in zwei Teile geteilt. In diesem Artikel werden wir über inkonsistente Benennungen, über Einschränkungen und darüber sprechen, wo es besser ist, Logik zu konzentrieren - in der Datenbank oder in der Anwendung. Der zweite Teil befasst sich mit Fehlerbehandlung, gleichzeitigem Zugriff, nicht stornierbaren Vorgängen, CTE und JSON.

In unserem Unternehmen bin ich im Kundensupport für Probleme im Zusammenhang mit Anwendungen tätig, dh ich helfe bei Verbindungsproblemen, bei der Abfrageoptimierung und ähnlichen Dingen. Ich habe genug von den verschiedensten Anwendungen gesehen. Was ich einfach nicht gesehen habe! Vielleicht sogar mehr als wir möchten. Ein Teil dessen, was ich erzählen werde, gilt nicht nur für PostgreSQL, sondern für jede Datenbank, sondern hauptsächlich für PostgreSQL.
Die wichtigste Schlussfolgerung, die ich aus dem, was ich sah, ziehen konnte, war ziemlich unerwartet: Tatsächlich kann jede Anwendung mit der gebotenen Beharrlichkeit zum Funktionieren gebracht werden. Es gab ein wundervolles Projekt (ich kann nicht alle Unternehmen erwähnen, mit denen wir zusammengearbeitet haben), in dem eine noch wundervollere Anwendung Tabellen von Millionen erstellt hat. Es sah so aus: Am Montag funktioniert das System gut und am Freitag praktisch nicht. Am Wochenende starten sie VACUUM FULL und am Montag funktioniert es wieder gut. Es stellt sich heraus, dass Sie PostgreSQL so verspotten können, und all dies wird für einige Zeit leben und funktionieren. Ein anderer Kamerad tat etwas Seltsames: Alles war auf Auslöser für ihn aufgebaut, es gab überhaupt keine Verfahren. Das heißt, die meisten Tische können nicht berührt werden, etwas konnte nicht getan werden, aber diese Basis lebte auch.
Er erklärte es so: „Die Basis bewegt sich von einem konsistenten Zustand in einen anderen konsistenten. Wenn ich die Daten erneut hochlade, werden sie beschädigt. Da ich jedoch Trigger und einen eindeutigen Schlüssel habe, kann ich die Daten nicht erneut rollen. “ Der Ansatz ist wild, aber gleichzeitig macht es Sinn. Vielleicht war es notwendig, etwas anderes zu tun, aber es ist auch notwendig, die Merkmale der Kunden zu berücksichtigen. Der erste Fehler, über den ich sprechen werde, ist:

Hier ist ein echtes Beispiel, auf das ich gestoßen bin. Auf der Folie sehen Sie, wie dieselbe Entität in verschiedenen Spalten benannt wurde. Man könnte auch mit Leerzeichen. Andere Objekte wurden ebenfalls inkonsistent benannt. Wenn Sie etwas in eine andere Tabelle aufnehmen müssen, müssen Sie sehen, wie es dort heißt, ist es dasselbe. Wenn Sie id_user und user_id in derselben Tabelle haben, beginnt die Arbeit mit der Recherche: Was würde das alles bedeuten?
Für andere Clients wurden alle Objekte wie folgt benannt: zwei Buchstaben, dann fünf Ziffern. Ich muss sagen, dass es nicht "1C" war. Warum sie das getan haben - ich weiß nicht: Es gab keine Logik darin, aber es ist meine Aufgabe, die Abfragen zu optimieren.
Ein weiteres Beispiel: Teil der Namen auf Russisch, Teil auf Nichtrussisch, aber mit einem russischen Akzent. Dies erschwert das Verständnis und führt zu neuen Fehlern. Ich selbst versuche, die Spalten so zu benennen, als würde ich auf einen Dienst zählen. Welcher dieser Spaltennamen führt in einigen Berichten automatisch zu normalen Spaltennamen. Im wirklichen Leben ist es leider nicht sehr erfolgreich, konsequent zu benennen - einschließlich meiner. Dies ist besonders schwierig bei der kollektiven Entwicklung. Aber wir müssen uns bemühen.
Ein weiterer wichtiger Grund für die sequentielle Benennung: Objektnamen sind über Anforderungen für Metadaten verfügbar, dh Namen sind auch Daten. Sie können eine Anfrage schreiben und beispielsweise alle Bilder - im Allgemeinen alle Bilder - aus der Datenbank auswählen.

Klare Metadaten sind sehr praktisch. Besonders wenn Sie die typischen Probleme mit der Dokumentation betrachten - und meiner Erfahrung nach fehlt die Dokumentation normalerweise entweder, ist unvollständig oder falsch oder beides: weil die Aufgabe, eine gute Dokumentation zu schreiben, in ihrer Komplexität mit der Aufgabe vergleichbar ist, den Code selbst zu schreiben. Es ist also besser, wenn sich der Code selbst dokumentiert. Eine logische, konsistente Benennung von Objekten trägt dazu bei. Wenn etwas nicht klar ist, müssen Sie Snippet-Code schreiben und beobachten, wie es funktioniert. Sobald es nichts ist, zwei nichts, aber wenn Sie es den ganzen Tag tun, ist es anstrengend.
Der eigentliche Fall: Eine sehr seriöse Organisation, mit der wir zusammengearbeitet haben, hatte einen Basis-Workflow für Oracle. Wir haben es nach Postgres verlegt. Eine der Vertragsbedingungen war, dass wir AUSLÄNDISCHE SCHLÜSSEL auferlegen. Sie waren nicht da und wir konnten sie leider nicht durchsetzen: Es stellte sich heraus, dass die Tabellen viele „linke“ Zeilen hatten und niemand weiß, was er mit ihnen anfangen soll, einschließlich des Kunden.
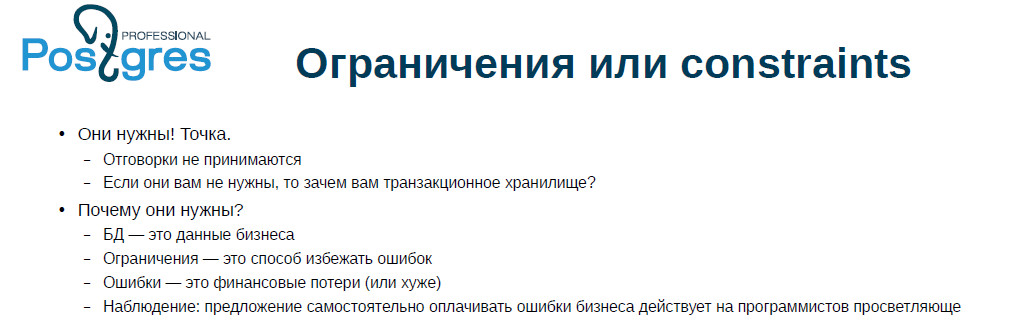
Wenn Sie sich nicht die Fortschrittsbalken ansehen müssen, sondern mit Dokumenten arbeiten müssen, um Geld zu bezahlen, ist die Situation traurig. Es hilft sehr, wenn der Programmierer im Rahmen des Vertrags die Fehler selbst bezahlt und es wünschenswert ist, dass die Beträge groß sind - dann erfolgt die Erleuchtung innerhalb von Minuten, wahrscheinlich fünfzehn. Einschränkungen werden sofort angezeigt, und sofort wird alles überprüft.
Sie können sich nicht einmal vorstellen (vielleicht stellt sich schon jemand vor), wie viel bequemer es ist, mit dem Fall umzugehen, in dem die Zahlung fehlgeschlagen ist, als wenn sie bestanden hat, aber nicht dort. Besonders wenn die Menge groß ist. Dies ist aus persönlicher Erfahrung.

Andererseits kann man oft hören, dass eine Einschränkung die Leistung verringert. Ja, aber wenn Sie die richtigen Daten haben möchten, gibt es einfach keine anderen Optionen für Sie. Wenn Sie eine Anwendung haben, die die Anzahl der Besuche von Kunden im Geschäft berücksichtigt, kann es zu Ungenauigkeiten kommen, die sich nicht besonders auf die Statistik auswirken. Wenn wir Geld zählen, sind Einschränkungen erforderlich.
Einschränkungsnamen werden normalerweise von einem ORM oder System generiert, und normalerweise stört sich niemand speziell daran, Einschränkungen zu benennen - aber vergebens! Wenn Sie den Fehler weiter verarbeiten, können Sie dem Benutzer unter dem Namen der Einschränkung eine eindeutige Meldung geben, den Fehler klassifizieren und wissen lassen, ob Sie versuchen müssen, den Vorgang erneut auszuführen, oder ob dieser Vorgang nicht mehr erforderlich ist oder einfach nicht wiederholt werden kann.
Eine andere Sache, die ich nicht gesehen habe, die ich aber sehr empfehle: Für alle wichtigen finanziellen (und nicht nur finanziellen) Prüfungshandlungen sollten mindestens zwei vorhanden sein. Tatsache ist, dass Sie früher oder später auf etwas stoßen, das Sie im Code ändern müssen, und es kann sehr gut sein, dass Sie eine der Prüfungen brechen. Dann wird der zweite dich retten. Wenn Sie drei machen, ist es auch nicht schlecht.

Oft stellt sich die Frage, wo die Richtigkeit der Daten überprüft werden soll. Auf dem Client oder auf dem Server? Meiner Meinung nach ist es offensichtlich, dass Sie sowohl dort als auch dort überprüfen müssen. Sie haben einen Fehler im Client, der Server jedoch nicht
Wird es fehlen oder Sie haben einen Fehler auf dem Server, dann hilft zumindest der Client, ihn zu verfolgen. Die Frage ist etwas umstritten, und wir gehen reibungslos zum Thema über: Wo soll die Basislogik aufbewahrt werden: in der Anwendung oder in der Datenbank?
Dies ist in der Datenbank praktisch, da ein Unternehmen meiner Erfahrung nach regelmäßig dringende Änderungen vornimmt: Entfernen oder Einfügen dieses und jenes in dieser Sekunde. Wenn der kompilierte Code logisch ist, müssen Sie sammeln, bereitstellen und sehen, was passiert ist. Oft ist das einfach unmöglich. In der Datenbank ist dies bequemer. Aber es gibt einen bekannten Aphorismus: Erfahrene Fortran-Programmierer schreiben in Fortran in jeder Sprache. Ungefähr 80 Servercode wird in einem vollständig prozeduralen Stil geschrieben: Wir haben die Funktion "get_user ()" und es wird der Typ "user" zurückgegeben, und wenn "get_list_users ()", dann wird ein Array von "users" zurückgegeben. Es ist wirklich bequemer, solche Dinge in Java zu schreiben als in SQL oder pgsql.

Auf der anderen Seite: Warum brauchen Sie die Funktion "get_user ()"? Sie nehmen es einfach in eine Tabelle oder in eine Ansicht. Da Sie eine relationale Datenbank haben, müssen Sie, wie mir scheint, relational schreiben. Zunächst ist es wichtig, klar zu bestimmen, mit welchen Daten wir arbeiten: Wenn es sich bei unseren Daten um Müll oder Halbmüll handelt, ist das Ergebnis angemessen und sollte wahrscheinlich nicht getötet werden. Wenn Daten für uns wichtig sind, wenn es sich um Geld, Eigentum oder rechtliche Operationen handelt, sind Einschränkungen erforderlich und je mehr desto besser. Ich wiederhole: Es ist besser, die Operation nicht auszuführen, als sie falsch auszuführen. Und schreiben Sie keinen prozeduralen Code in eine relationale Datenbank: Sie werden es sehr bereuen.

Ich sah eine Tabelle mit 30.000 Zeilen (Produkten), in der die Anforderung „Liste der relevanten Waren anzeigen“ etwa eine Sekunde lang ausgeführt wurde. Anscheinend ist es ihnen gelungen, ein „schönes und komplexes“ Datenbankschema zu erstellen. Persönlich denke ich, wenn Sie etwas sehr Kniffliges tun, dann machen Sie höchstwahrscheinlich entweder etwas Falsches oder Sie haben wirklich eine sehr, sehr schwierige Aufgabe. Wenn Sie eine Art Geschäft oder eine reguläre Anwendung für Buchhalter haben, ist es unwahrscheinlich, dass zwischen Unternehmen sehr komplexe Beziehungen bestehen.
Als ich meine berufliche Laufbahn begann, schien die Tabelle in einer 60-Megabyte-DBF-Datei im Bankensystem sehr groß zu sein, und jetzt sind 60 Megabyte überhaupt nichts mehr - Hardware ist besser, Software ist besser, alles funktioniert schneller, aber die Frage bleibt: Woher bekommen Sie so viel? Daten? Sehr große, geschwollene Basen werden normalerweise aufgrund von Archiven so. In jedem DBMS und in PostgreSQL wurden große Anstrengungen unternommen, um einen konsistenten, wettbewerbsfähigen Betrieb der Anwendung sicherzustellen. Das Archiv ändert sich höchstwahrscheinlich nicht, und die meisten DBMS-Funktionen für die Arbeit damit werden überhaupt nicht benötigt. Es lohnt sich darüber nachzudenken, es aus dem DBMS herauszunehmen.

Hin und wieder stellen sie mit einer Art Kommissar-Schielen die Frage: Wird PostgreSQL eine Basis für dieses und jenes Volumen ziehen? Aber hier ist die Frage selbst seltsam: Sie können so viel Daten in die Datenbank einfügen, wie Sie möchten, solange genügend Speicherplatz vorhanden ist, wird so viel lügen. Die Frage ist zum Beispiel, wie Archive auf Petabyte gesichert werden, wo Sie die vollständige Sicherung ablegen und wie viel Sie davon entfernen werden. Ich vermute sehr, dass diese Volumenanforderungen zumindest teilweise mit dem Wunsch der Geräteverkäufer zusammenhängen, Ihnen mehr zu verkaufen.
Wenn Sie Dokumente in der Datenbank speichern, ist es unwahrscheinlich, dass Sie sie dort verarbeiten: Die Excel-Tabelle kann natürlich auf dem Server geändert werden, aber dies ist eine seltsame Beschäftigung. Höchstwahrscheinlich sind solche Dateien im Allgemeinen schreibgeschützt. Es ist besser, Links zu Dokumenten und sich selbst in einem externen Speicher zu speichern. Am Ende können Sie die digitale Signatur der Tabelle behalten - damit sie sich nicht ändert (wenn Sie die relevanten rechtlichen Fragen entscheiden).
Eine weitere Beobachtung: Wenn Sie kein Mega-Mega-Geschäft haben, beispielsweise kein Bundesunternehmen, ist es unwahrscheinlich, dass Sie eine sehr große Basis haben. Wenn Sie kein Video darin speichern, natürlich.

Ein weiterer Grund für die große Datenbank sind unnötige Indizes. Basen ohne Indizes habe ich nicht getroffen, aber ziemlich oft habe ich Basen getroffen, bei denen mehrere Indizes auf denselben Spalten in derselben Reihenfolge waren. Die Basis ermöglicht es Ihnen, dies zu tun. Überprüfen Sie beim Erstellen eines Index, ob ein vorhandener Index dupliziert wird. Sie können sehen, welche Indizes nicht benötigt werden, indem Sie unter pg_stat_user_indexes nachsehen, wie aktiv der Index verwendet wird. Vielleicht wird er überhaupt nicht benötigt.
Ich bin auf eine Situation gestoßen (übrigens typisch), in der eine sehr große Tabelle nicht partitioniert ist. In allen DBMS sind große Tabellen am besten partitioniert, aber in PostgreSQL gilt dies insbesondere aufgrund unseres geliebten VACUUM. Ich würde empfehlen, Tabellen zu partitionieren, die wahrscheinlich mit 100 Gigabyte beginnen. Vielleicht ab 50. Ich habe nicht partitionierte Terabyte-Tabellen gesehen, und sie lebten jedoch von SSDs. Aber das ist ein bisschen viel, es wäre besser, sie zu schneiden.

Und noch eine Bemerkung: Fast alle Datenbanken eines großen Volumens sind nur angehängte Archive. Live, sich ändernde Daten werden in solchen Datenbanken selten gefunden. Eine Determinante für das, was Sie haben - wenn das Archiv, dann können Sie darüber nachdenken, wie Sie es irgendwohin bringen können. Übrigens können Sie von der Datenbank aus darauf zugreifen. Dann muss die Anwendung nicht geändert werden: Es wird sich nichts daran ändern.
Einige dieser Beobachtungen stammen aus der Kategorie „Es ist besser, reich und gesund zu sein als arm und krank“. Oft gibt es erstens Legacy-Code. Zweitens ist etwas Unerwartetes passiert, sie haben nicht an etwas gedacht und es stellt sich heraus, dass nicht alles so schön ist, wie wir es gerne hätten. Aber trotzdem: sei nicht sehr schlau. Denken Sie daran, wenn Sie sehr klug sind, dann machen Sie höchstwahrscheinlich etwas falsch.
[Fortsetzung folgt.]