Schnittstelle
Im
ersten Artikel haben wir erwähnt, dass eine Zugriffsmethode Informationen über sich selbst bereitstellen muss. Schauen wir uns die Struktur der Schnittstelle für Zugriffsmethoden an.
Eigenschaften
Alle Eigenschaften von Zugriffsmethoden werden in der Tabelle "pg_am" gespeichert ("am" steht für Zugriffsmethode). Aus derselben Tabelle können wir auch eine Liste der verfügbaren Methoden abrufen:
postgres=# select amname from pg_am;
amname -------- btree hash gist gin spgist brin (6 rows)
Obwohl der sequentielle Scan zu Recht auf Zugriffsmethoden bezogen werden kann, ist er aus historischen Gründen nicht in dieser Liste enthalten.
In PostgreSQL-Versionen 9.5 und niedriger wurde jede Eigenschaft mit einem separaten Feld in der Tabelle "pg_am" dargestellt. Ab Version 9.6 werden Eigenschaften mit speziellen Funktionen abgefragt und in mehrere Ebenen unterteilt:
- Eigenschaften der Zugriffsmethode - "pg_indexam_has_property"
- Eigenschaften eines bestimmten Index - "pg_index_has_property"
- Eigenschaften einzelner Spalten des Index - "pg_index_column_has_property"
Die Zugriffsmethodenschicht und die Indexschicht sind mit Blick auf die Zukunft getrennt: Ab sofort haben alle Indizes, die auf einer Zugriffsmethode basieren, immer dieselben Eigenschaften.
Die folgenden vier Eigenschaften entsprechen denen der Zugriffsmethode (anhand eines Beispiels für "btree"):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name) from pg_am a, unnest(array['can_order','can_unique','can_multi_col','can_exclude']) p(name) where a.amname = 'btree' order by a.amname;
amname | name | pg_indexam_has_property --------+---------------+------------------------- btree | can_order | t btree | can_unique | t btree | can_multi_col | t btree | can_exclude | t (4 rows)
- can_order.
Mit der Zugriffsmethode können wir die Sortierreihenfolge für Werte angeben, wenn ein Index erstellt wird (gilt bisher nur für "btree"). - can_unique
Unterstützung der eindeutigen Einschränkung und des Primärschlüssels (gilt nur für "btree"). - can_multi_col.
Ein Index kann aus mehreren Spalten bestehen. - can_exclude
Unterstützung der Ausschlussbeschränkung EXCLUDE.
Die folgenden Eigenschaften beziehen sich auf einen Index (betrachten wir beispielsweise einen vorhandenen):
postgres=# select p.name, pg_index_has_property('t_a_idx'::regclass,p.name) from unnest(array[ 'clusterable','index_scan','bitmap_scan','backward_scan' ]) p(name);
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | t (4 rows)
- clusterfähig.
Eine Möglichkeit, Zeilen entsprechend dem Index neu anzuordnen (Clustering mit dem gleichnamigen Befehl CLUSTER). - index_scan.
Unterstützung des Index-Scans. Obwohl diese Eigenschaft seltsam erscheint, können nicht alle Indizes TIDs einzeln zurückgeben - einige geben Ergebnisse auf einmal zurück und unterstützen nur den Bitmap-Scan. - bitmap_scan.
Unterstützung des Bitmap-Scans. - backward_scan.
Das Ergebnis kann in umgekehrter Reihenfolge wie beim Erstellen des Index angegeben zurückgegeben werden.
Schließlich sind die folgenden Spalteneigenschaften: postgres=# select p.name, pg_index_column_has_property('t_a_idx'::regclass,1,p.name) from unnest(array[ 'asc','desc','nulls_first','nulls_last','orderable','distance_orderable', 'returnable','search_array','search_nulls' ]) p(name);
name | pg_index_column_has_property --------------------+------------------------------ asc | t desc | f nulls_first | f nulls_last | t orderable | t distance_orderable | f returnable | t search_array | t search_nulls | t (9 rows)
- asc, desc, nulls_first, nulls_last, orderable.
Diese Eigenschaften beziehen sich auf die Reihenfolge der Werte (wir werden sie diskutieren, wenn wir eine Beschreibung der "btree" -Indizes erhalten). - distance_orderable.
Das Ergebnis kann in der durch die Operation festgelegten Sortierreihenfolge zurückgegeben werden (gilt bisher nur für GiST- und RUM-Indizes). - Mehrweg
Eine Möglichkeit, den Index ohne Zugriff auf die Tabelle zu verwenden, dh Unterstützung von Nur-Index-Scans. - search_array.
Unterstützung der Suche nach mehreren Werten mit dem Ausdruck " indexed-field IN ( list_of_constants )", der mit " indexed-field = ANY ( array_of_constants )" identisch ist . - search_nulls.
Eine Möglichkeit zur Suche nach IS NULL- und IS NOT NULL-Bedingungen.
Wir haben bereits einige der Eigenschaften im Detail besprochen. Einige Eigenschaften sind für bestimmte Zugriffsmethoden spezifisch. Wir werden solche Eigenschaften diskutieren, wenn wir diese spezifischen Methoden betrachten.
Betreiberklassen und Familien
Zusätzlich zu den Eigenschaften einer Zugriffsmethode, die von der beschriebenen Schnittstelle bereitgestellt wird, werden Informationen benötigt, um zu wissen, welche Datentypen und welche Operatoren die Zugriffsmethode akzeptiert. Zu diesem Zweck führt PostgreSQL Konzepte für
Operatorklassen und
Operatorfamilien ein .
Eine Operatorklasse enthält eine minimale Anzahl von Operatoren (und möglicherweise Hilfsfunktionen) für einen Index, um einen bestimmten Datentyp zu bearbeiten.
Eine Operatorklasse ist in einigen Operatorfamilien enthalten. Darüber hinaus kann eine gemeinsame Operatorfamilie mehrere Operatorklassen enthalten, wenn sie dieselbe Semantik haben. Beispielsweise umfasst die Familie "integer_ops" die Klassen "int8_ops", "int4_ops" und "int2_ops" für die Typen "bigint", "integer" und "smallint" mit unterschiedlichen Größen, aber derselben Bedeutung:
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'integer_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype -------------+----------+----------- integer_ops | int2_ops | smallint integer_ops | int4_ops | integer integer_ops | int8_ops | bigint (3 rows)
Ein weiteres Beispiel: Die Familie "datetime_ops" enthält Operatorklassen zum Bearbeiten von Datumsangaben (sowohl mit als auch ohne Zeit):
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'datetime_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype --------------+-----------------+----------------------------- datetime_ops | date_ops | date datetime_ops | timestamptz_ops | timestamp with time zone datetime_ops | timestamp_ops | timestamp without time zone (3 rows)
Eine Operatorfamilie kann auch zusätzliche Operatoren enthalten, um Werte verschiedener Typen zu vergleichen. Durch die Gruppierung in Familien kann der Planer einen Index für Prädikate mit Werten unterschiedlichen Typs verwenden. Eine Familie kann auch andere Hilfsfunktionen enthalten.
In den meisten Fällen müssen wir nichts über Operatorfamilien und -klassen wissen. Normalerweise erstellen wir nur einen Index, wobei standardmäßig eine bestimmte Operatorklasse verwendet wird.
Wir können jedoch die Operatorklasse explizit angeben. Dies ist ein einfaches Beispiel dafür, wann die explizite Angabe erforderlich ist: In einer Datenbank mit einer anderen Sortierung als C unterstützt ein regulärer Index die LIKE-Operation nicht:
postgres=# show lc_collate;
lc_collate ------------- en_US.UTF-8 (1 row)
postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ----------------------------- Seq Scan on t Filter: (b ~~ 'A%'::text) (2 rows)
Wir können diese Einschränkung überwinden, indem wir einen Index mit der Operatorklasse "text_pattern_ops" erstellen (beachten Sie, wie sich die Bedingung im Plan geändert hat):
postgres=# create index on t(b text_pattern_ops); postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ---------------------------------------------------------------- Bitmap Heap Scan on t Filter: (b ~~ 'A%'::text) -> Bitmap Index Scan on t_b_idx1 Index Cond: ((b ~>=~ 'A'::text) AND (b ~<~ 'B'::text)) (4 rows)
Systemkatalog
Zum Abschluss dieses Artikels stellen wir ein vereinfachtes Diagramm von Tabellen im Systemkatalog bereit, die in direktem Zusammenhang mit Operatorklassen und -familien stehen.
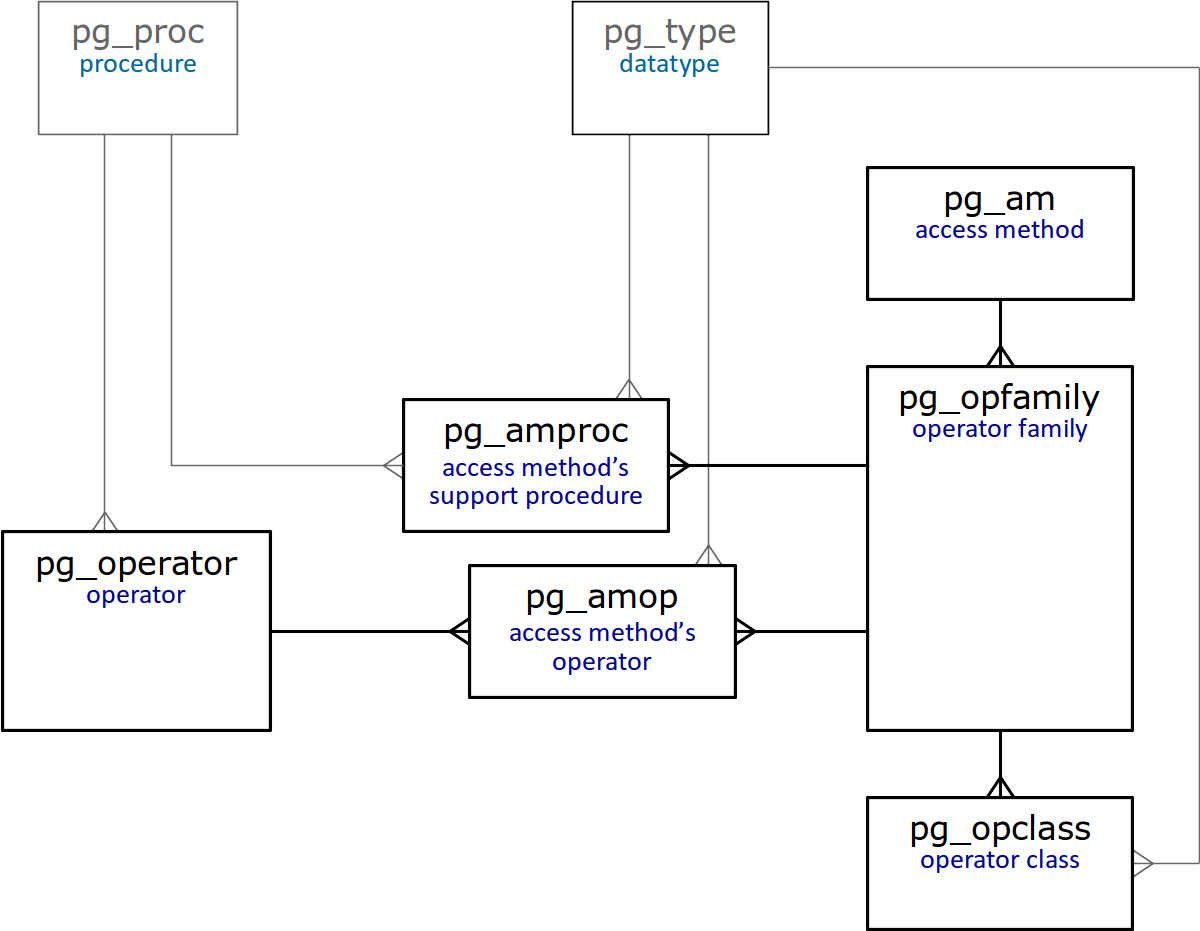
Es versteht sich von selbst, dass alle diese Tabellen
ausführlich beschrieben werden .
Der Systemkatalog ermöglicht es uns, Antworten auf eine Reihe von Fragen zu finden, ohne in die Dokumentation zu schauen. Welche Datentypen kann beispielsweise eine bestimmte Zugriffsmethode bearbeiten?
postgres=# select opcname, opcintype::regtype from pg_opclass where opcmethod = (select oid from pg_am where amname = 'btree') order by opcintype::regtype::text;
opcname | opcintype ---------------------+----------------------------- abstime_ops | abstime array_ops | anyarray enum_ops | anyenum ...
Welche Operatoren enthält eine Operatorklasse (und daher kann der Indexzugriff für eine Bedingung verwendet werden, die einen solchen Operator enthält)?
postgres=# select amop.amopopr::regoperator from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'btree' and amop.amoplefttype = opc.opcintype;
amopopr ----------------------- <(anyarray,anyarray) <=(anyarray,anyarray) =(anyarray,anyarray) >=(anyarray,anyarray) >(anyarray,anyarray) (5 rows)
Lesen Sie weiter .