Als
HighLoad ++ - Teilnehmer zum Bericht von
Alexander Krasheninnikov kamen , hofften sie, etwas über die Verarbeitung von 1.600.000 Ereignissen pro Sekunde zu
erfahren . Die Erwartungen haben sich nicht erfüllt ... Während der Vorbereitung auf die Aufführung stieg diese Zahl auf
1.800.000 - bei HighLoad ++ übertrifft die Realität also die Erwartungen.
Vor drei Jahren erzählte Alexander, wie sie bei Badoo ein skalierbares Echtzeit-Ereignisverarbeitungssystem aufgebaut haben. Seitdem hat es sich weiterentwickelt, das Volumen ist dabei gewachsen, es war notwendig, die Probleme der Skalierung und Fehlertoleranz zu lösen, und irgendwann waren radikale Maßnahmen erforderlich - eine
Änderung des technologischen Stapels .

Durch die Entschlüsselung erfahren Sie, wie Sie in Badoo das Spark + Hadoop-Bundle durch ClickHouse ersetzt,
die Hardware dreimal gespeichert und die Last sechsmal erhöht haben , warum und auf welche Weise Statistiken im Projekt erfasst werden und was dann mit diesen Daten zu tun ist.
Über den Sprecher: Alexander Krasheninnikov (
alexkrash ) - Leiter Data Engineering bei Badoo. Er befasst sich mit der BI-Infrastruktur, der Skalierung für Workloads und verwaltet die Teams, die die Datenverarbeitungsinfrastruktur aufbauen. Er liebt alles, was verteilt wird: Hadoop, Spark, ClickHouse. Ich bin sicher, dass coole verteilte Systeme aus OpenSource vorbereitet werden können.
Statistiksammlung
Wenn wir keine Daten haben, sind wir blind und können unser Projekt nicht verwalten. Deshalb brauchen wir Statistiken,
um die Realisierbarkeit des Projekts zu
überwachen. Wir als Ingenieure sollten uns bemühen, unsere Produkte zu verbessern, und wenn
Sie sie verbessern möchten, messen Sie sie. Das ist mein Motto in der Arbeit. Unser Ziel sind vor allem geschäftliche Vorteile. Statistiken
bieten Antworten auf geschäftliche Fragen . Technische Metriken sind technische Metriken, aber das Unternehmen ist auch an Indikatoren interessiert und muss ebenfalls berücksichtigt werden.
Statistik Lebenszyklus
Ich definiere den Lebenszyklus von Statistiken durch 4 Punkte, die wir jeweils separat diskutieren werden.
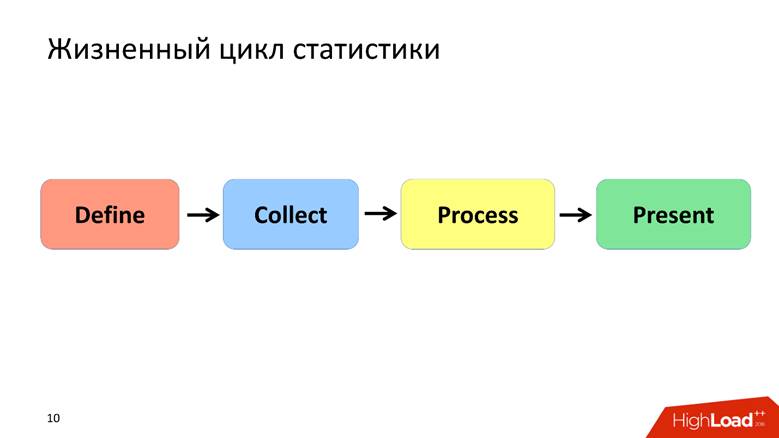
Phase definieren - Formalisierung
In der Anwendung sammeln wir mehrere Metriken. Zuallererst sind dies
Geschäftsmetriken . Wenn Sie beispielsweise einen Fotoservice haben, fragen Sie sich, wie viele Fotos pro Tag, pro Stunde und pro Sekunde hochgeladen werden. Die folgenden Metriken sind
„semi-technisch“ : Reaktionsfähigkeit einer mobilen Anwendung oder Site, API-Vorgang, wie schnell ein Benutzer mit einer Site interagiert, Anwendungsinstallation, UX.
Die Verfolgung des Benutzerverhaltens ist die dritte wichtige Messgröße. Dies sind Systeme wie Google Analytics und Yandex.Metrics. Wir haben unser eigenes cooles Tracking-System, in das wir viel investieren.
An der Arbeit mit Statistiken sind viele Benutzer beteiligt - dies sind Entwickler und Geschäftsanalysen. Es ist wichtig, dass alle dieselbe Sprache sprechen, daher müssen Sie zustimmen.
Es ist möglich, mündlich zu verhandeln, aber viel besser, wenn es formal geschieht - in einer klaren Struktur der Ereignisse.
Die Formalisierung der Struktur von Geschäftsereignissen erfolgt, wenn der Entwickler angibt, wie viele Registrierungen wir haben. Der Analyst versteht, dass er nicht nur über die Gesamtzahl der Registrierungen informiert wurde, sondern auch nach Land, Geschlecht und anderen Parametern. Alle diese Informationen sind formalisiert und
für alle Benutzer des Unternehmens gemeinfrei . Die Veranstaltung hat eine typisierte Struktur und eine formale Beschreibung. Beispielsweise speichern wir diese Informationen im
Protokollpufferformat .
Beschreibung der Veranstaltung "Anmeldung":
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
Das Registrierungsereignis enthält Informationen über den
Benutzer, das Feld, den Zeitpunkt des Ereignisses und das Registrierungsland des Benutzers. Diese Informationen stehen Analysten zur Verfügung, und in Zukunft versteht das Unternehmen, was wir sammeln.
Warum brauche ich eine formale Beschreibung?
Eine formale Beschreibung ist die
Einheitlichkeit für Entwickler, Analysten und die Produktabteilung. Diese Informationen durchdringen dann die Beschreibung der Geschäftslogik der Anwendung. Zum Beispiel haben wir ein internes System zur Beschreibung von Geschäftsprozessen und in einem Bildschirm haben wir eine neue Funktion.
Im
Produktanforderungsdokument gibt es einen Abschnitt mit der Anweisung, dass, wenn der Benutzer auf diese Weise mit der Anwendung interagiert, ein Ereignis mit genau denselben Parametern gesendet werden muss. Anschließend können wir überprüfen, wie gut unsere Funktionen funktionieren und ob wir sie korrekt gemessen haben. Eine formale Beschreibung ermöglicht es uns, besser zu verstehen, wie diese Daten in einer Datenbank gespeichert werden: NoSQL, SQL oder andere. Wir haben
ein Datenschema , und das ist cool.
In einigen Analysesystemen, die als Dienst bereitgestellt werden, befinden sich nur 10 bis 15 Ereignisse im geheimen Speicher. In unserem Land ist diese Zahl um mehr als 1000 gewachsen und wird nicht aufhören -
es ist unmöglich, ohne eine einzige Registrierung zu leben .
Phasenzusammenfassung definieren
Wir haben entschieden, dass
Statistiken - das ist wichtig und
beschreiben einen bestimmten Themenbereich - gut sind, von denen man leben kann.
Phase sammeln - Datenerfassung
Wir haben uns entschlossen, das System so aufzubauen, dass bei Auftreten eines Geschäftsereignisses - Registrierung, Senden einer Nachricht wie - gleichzeitig mit dem Speichern dieser Informationen ein bestimmtes statistisches Ereignis separat gesendet wird.
Im Code werden Statistiken gleichzeitig mit dem Geschäftsereignis gesendet.
Es wird völlig unabhängig von den Datenspeichern verarbeitet, in denen die Anwendung ausgeführt wird, da der
Datenfluss eine separate Verarbeitungspipeline durchläuft.Beschreibung via EDL:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
Wir haben eine Beschreibung des Registrierungsereignisses. Es wird automatisch eine API generiert, auf die Entwickler über Code zugreifen können. In 4 Zeilen können Sie Statistiken senden.
EDL-basierte API:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
Event Delivery
Dies ist unser externes System. Wir tun dies, weil wir unglaubliche Services haben, die eine API für die Arbeit mit Fotodaten über etwas anderes bieten. Sie alle speichern Daten in coolen neuen Datenbanken wie Aerospike und CockroachDB.
Wenn Sie eine Art Bericht erstellen müssen, müssen Sie nicht kämpfen: "Leute, wie viel davon haben Sie und wie viel?" - Alle Daten werden in einem separaten Fluss gesendet. Verarbeitungsförderer - externes System. Aus dem Anwendungskontext lösen wir alle Daten aus dem Geschäftslogik-Repository und senden sie weiter an eine separate Pipeline.
In der Erfassungsphase wird die Verfügbarkeit von Anwendungsservern vorausgesetzt. Wir haben dieses PHP.
Transport
Dies ist ein Subsystem, mit dem wir das, was wir im Anwendungskontext getan haben, an eine andere Pipeline senden können. Der Transport wird je nach Situation im Projekt ausschließlich aus Ihren Anforderungen ausgewählt.
Der Transport hat Eigenschaften, und die erste ist
Liefergarantien. Merkmale des Transports: Mindestens einmal, genau einmal, wählen Sie Statistiken für Ihre Aufgaben aus, basierend darauf, wie wichtig diese Daten sind. Für Abrechnungssysteme ist es beispielsweise nicht akzeptabel, dass die Statistiken mehr Transaktionen anzeigen als vorhanden - dies ist Geld, es ist nicht möglich.
Der zweite Parameter sind
Bindungen für Programmiersprachen. Wir müssen irgendwie mit dem Transport interagieren, also wird er entsprechend der Sprache ausgewählt, in der das Projekt geschrieben ist.
Der dritte Parameter ist die
Skalierbarkeit. Da es sich um Millionen von Ereignissen pro Sekunde handelt, wäre es schön, die zukünftige Skalierbarkeit im Auge zu behalten.
Es gibt viele Transportmöglichkeiten: RDBMS-Anwendungen, Flume, Kafka oder LSD. Wir verwenden
LSD - das ist unser besonderer Weg.
Live-Streaming-Daemon
LSD hat nichts mit verbotenen Substanzen zu tun. Dies ist ein
lebhafter, sehr schneller Streaming-Daemon , der keinen Agenten zum Schreiben bereitstellt. Wir können es
optimieren , wir haben
Integration mit anderen Systemen : HDFS, Kafka - wir können die gesendeten Daten neu anordnen. Das LSD hat keinen Netzwerkaufruf auf INSERT, und Sie können die darin enthaltene Netzwerktopologie steuern.
Am wichtigsten ist, dass dies
Badoos OpenSource ist - es gibt keinen Grund, dieser Software nicht zu vertrauen.
Wenn es ein perfekter Dämon wäre, würden wir anstelle von Kafka bei jeder Konferenz über LSD diskutieren, aber jeder LSD hat eine Fliege in der Salbe. Wir haben unsere eigenen Einschränkungen, mit denen wir vertraut sind: Wir haben
keine Replikationsunterstützung in LSD und es gibt
mindestens eine Zustellgarantie. Auch für Geldtransaktionen ist dies nicht der am besten geeignete Transport, aber Sie müssen im Allgemeinen ausschließlich über "saure" Datenbanken mit Geld kommunizieren - was
ACID unterstützt.
Phasenzusammenfassung sammeln
Basierend auf den Ergebnissen der vorherigen Serie erhielten wir eine
formale Beschreibung der Daten, generierten daraus eine hervorragende, bequeme
API für Ereignisverteiler und fanden heraus, wie diese Daten
aus dem Anwendungskontext in eine separate Pipeline übertragen werden können . Schon nicht schlecht, und wir nähern uns der nächsten Phase.
Phasenprozess - Datenverarbeitung
Wir haben Daten aus Registrierungen gesammelt, Fotos hochgeladen, Umfragen durchgeführt - was tun mit all dem? Aus diesen Daten möchten wir
Diagramme mit einer langen Geschichte und
Rohdaten erhalten . Diagramme verstehen alles - Sie müssen kein Entwickler sein, um anhand der Kurve zu verstehen, dass der Umsatz des Unternehmens wächst. Wir verwenden Rohdaten für Online-Berichte und Ad-hoc. In komplexeren Fällen möchten unsere Analysten analytische Abfragen für diese Daten durchführen. Sowohl diese als auch diese Funktionalität sind für uns notwendig.
Grafiken
Diagramme gibt es in vielen Formen.
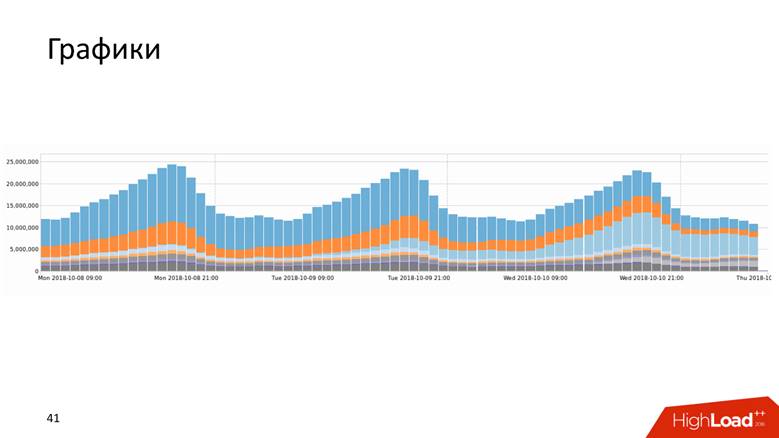
Oder zum Beispiel ein Diagramm mit einem Verlauf, der Daten für 10 Jahre anzeigt.
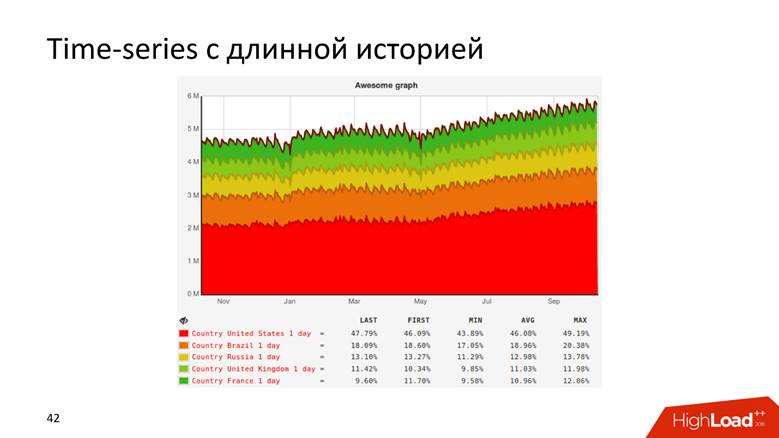
Charts sind sogar so.
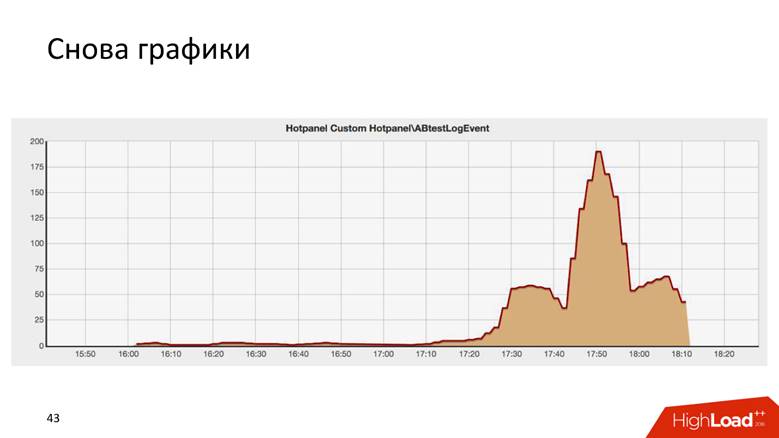
Dies ist das Ergebnis eines AB-Tests und ähnelt überraschend dem Chrysler-Gebäude in New York.
Es gibt zwei Möglichkeiten, ein Diagramm zu zeichnen: eine
Abfrage nach Rohdaten und eine
Zeitreihe . Beide Ansätze haben Nachteile und Vorteile, auf die wir nicht näher eingehen werden. Wir verwenden einen
hybriden Ansatz : Wir halten uns von den Rohdaten für die Betriebsberichterstattung und den Zeitreihen für die Langzeitspeicherung fern. Die zweite wird aus der ersten berechnet.
Wie wir auf 1,8 Millionen Ereignisse pro Sekunde angewachsen sind
Es ist eine lange Geschichte - Millionen von RPS passieren nicht an einem Tag. Badoo ist ein Unternehmen mit einer zehnjährigen Geschichte, und wir können sagen, dass das Datenverarbeitungssystem mit dem Unternehmen gewachsen ist.
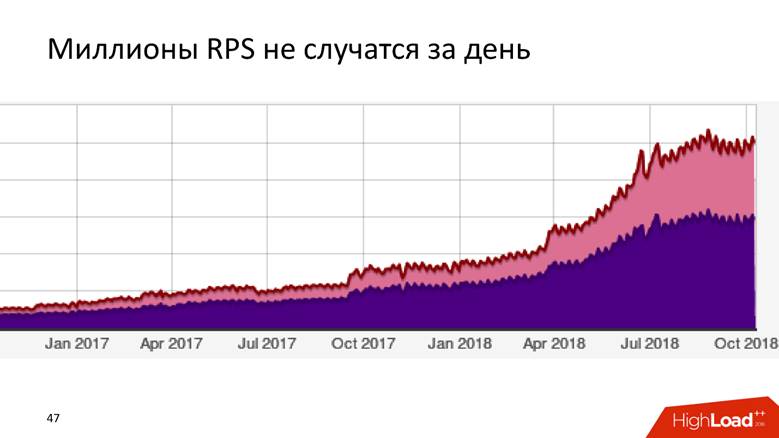
Zuerst hatten wir nichts. Wir haben angefangen, Daten zu sammeln - es stellte sich heraus, dass
5.000 Ereignisse pro Sekunde stattfanden. Ein MySQL-Host und sonst nichts! Jedes relationale DBMS wird diese Aufgabe bewältigen, und es wird damit vertraut sein: Sie haben Transaktionsmöglichkeiten - legen Sie die Daten ab, empfangen Sie Anforderungen von ihr - alles funktioniert cool und gut. Also haben wir eine Weile gelebt.
Irgendwann kam es zu funktionalem Sharding: Registrierungsdaten - hier und über Fotos - dort. Wir lebten also bis zu
200.000 Ereignisse pro Sekunde und begannen, verschiedene kombinierte Ansätze zu verwenden: nicht Rohdaten zu speichern, sondern
aggregiert , aber bisher in der relationalen Datenbank. Wir speichern Zähler, aber das Wesentliche der meisten relationalen Datenbanken ist, dass es dann unmöglich ist, eine
DISTINCT-Abfrage für diese Daten auszuführen - das algebraische Modell der Zähler erlaubt keine Berechnung von DISTINCT.
Wir bei Badoo haben das Motto
„Unaufhaltsame Kraft“ . Wir wollten nicht aufhören und wuchsen weiter. In dem Moment, als wir die Schwelle von
200.000 Ereignissen pro Sekunde überschritten haben, haben wir beschlossen, eine formale Beschreibung zu erstellen, über die ich oben gesprochen habe. Vorher gab es ein gewisses Chaos, und jetzt haben wir ein strukturiertes Ereignisregister: Wir haben begonnen, das System zu skalieren,
Hadoop verbunden , alle Daten wurden in
Hive-Tabellen gespeichert
.Hadoop ist ein riesiges Softwarepaket, ein Dateisystem. Für verteiltes Rechnen sagt Hadoop: "Geben Sie die Daten hier ein, damit Sie analytische Abfragen durchführen können." Also haben wir - eine
regelmäßige Berechnung aller Diagramme geschrieben - es hat sich als gut herausgestellt. Diagramme sind jedoch wertvoll, wenn sie schnell aktualisiert werden. Einmal am Tag macht es nicht so viel Spaß, ein Diagramm zu aktualisieren. Wenn wir etwas einführen, das zu einem schwerwiegenden Produktionsfehler führt, möchten wir, dass das Diagramm sofort und nicht jeden zweiten Tag abfällt. Daher begann sich das gesamte System nach einiger Zeit zu verschlechtern. Wir haben jedoch festgestellt, dass Sie sich zu diesem Zeitpunkt an den ausgewählten Technologie-Stack halten können.
Für uns war Java neu, es hat uns gefallen und wir haben verstanden, was anders gemacht werden kann.
In der Phase von 400.000 bis
800.000 Ereignissen pro Sekunde haben wir Hadoop in seiner reinsten Form ersetzt, und Hive hat als Ausführender von analytischen Abfragen mit
Spark Streaming eine
generische Map / Reduce- und inkrementelle Berechnung von Metriken geschrieben. Vor 3 Jahren habe ich
erzählt, wie wir es gemacht haben. Dann schien es uns, dass Spark für immer leben würde, aber das Leben verfügte etwas anderes - wir stießen auf die Grenzen von Hadoop. Wenn wir andere Bedingungen hätten, würden wir vielleicht weiterhin mit Hadoop leben.
Ein weiteres Problem neben der Berechnung von Diagrammen in Hadoop waren die unglaublichen vierstöckigen SQL-Abfragen, die von Analysten durchgeführt wurden, und die Diagramme wurden nicht schnell aktualisiert. Tatsache ist, dass die Verarbeitung von Betriebsdaten eine ziemlich knifflige Aufgabe ist, so dass sie in Echtzeit, schnell und cool ist.
Badoo wird von zwei Rechenzentren auf zwei Seiten des Atlantischen Ozeans bedient - in Europa und Nordamerika. Um eine einheitliche Berichterstattung zu erstellen, müssen Sie Daten aus Amerika nach Europa senden. Im europäischen Rechenzentrum führen wir alle Statistikstatistiken, weil mehr Rechenleistung vorhanden ist.
Eine Hin- und Rückfahrt zwischen Rechenzentren von ca.
200 ms - das Netzwerk ist ziemlich heikel - eine Anfrage an einen anderen DC zu stellen, ist nicht dasselbe wie zum nächsten Rack zu gehen.
Als wir anfingen, Events und Entwickler zu formalisieren, und Produktmanager sich engagierten, mochten alle alles - es gab nur ein
explosives Wachstum von Events . Zu diesem Zeitpunkt war es Zeit, Eisen im Cluster zu kaufen, aber wir wollten dies nicht wirklich tun.
Als wir den Höchststand von
800.000 Ereignissen pro Sekunde überschritten hatten, fanden wir heraus, was Yandex auf OpenSource
ClickHouse hochgeladen
hatte , und beschlossen, es zu versuchen.
Sie füllten einen Zug mit Zapfen, während sie versuchten, etwas zu tun, und als alles funktionierte, machten sie einen kleinen Buffetempfang über die ersten Millionen Veranstaltungen. Wahrscheinlich hätte ClickHouse den Bericht fertigstellen können.
Nehmen Sie einfach ClickHouse und leben Sie damit.
Dies ist jedoch nicht interessant, daher werden wir weiterhin über die Datenverarbeitung sprechen.
Clickhouse
ClickHouse ist ein Hype der letzten zwei Jahre und muss nicht eingeführt werden: Nur in HighLoad ++ im Jahr 2018 erinnere ich mich
an fünf Berichte darüber sowie an Seminare und Besprechungen.
Dieses Tool wurde entwickelt, um genau die Aufgaben zu lösen, die wir uns selbst gestellt haben. Es gibt
Echtzeit-Updates und Chips, die wir gleichzeitig von Hadoop erhalten haben: Replikation, Sharding. Es gab keinen Grund, ClickHouse nicht auszuprobieren, da sie verstanden hatten, dass wir mit der Implementierung auf Hadoop bereits den Boden gebrochen hatten. Das Tool ist cool und die Dokumentation ist im Allgemeinen Feuer - ich habe dort selbst geschrieben, ich mag wirklich alles und alles ist großartig. Aber wir mussten eine Reihe von Problemen lösen.
Wie verschiebe ich den gesamten Ereignisfluss in ClickHouse? Wie kombiniere ich Daten aus zwei Rechenzentren? Aufgrund der Tatsache, dass wir zu den Administratoren gekommen sind und gesagt haben: "Leute, lasst uns ClickHouse installieren", werden sie das Netzwerk nicht doppelt so dick machen und die Verzögerung ist halb so groß. Nein, das Netzwerk ist immer noch so dünn und klein wie das erste Gehalt.
Wie speichere ich die Ergebnisse ? Bei Hadoop haben wir verstanden, wie man Grafiken zeichnet - aber wie man es auf dem magischen ClickHouse macht? Zauberstab ist nicht enthalten.
Wie liefern Sie Ergebnisse an den Zeitreihenspeicher?
Betrachten Sie, wie mein Dozent am Institut sagte, drei Datenschemata: strategisch, logisch und physisch.
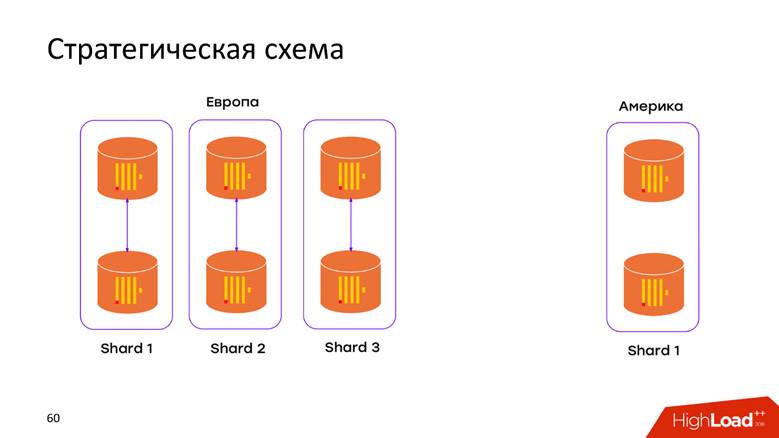
Strategisches Speicherschema
Wir haben
2 Rechenzentren . Wir haben erfahren, dass ClickHouse nichts über DCs weiß, und wir haben den Cluster einfach in jeden DC gepoppt. Jetzt werden die
Daten nicht mehr über das atlantikübergreifende Kabel übertragen. Alle im DC aufgetretenen Daten werden lokal in seinem Cluster gespeichert. Wenn wir beispielsweise eine Anfrage über die kombinierten Daten stellen möchten, um herauszufinden, wie viele Registrierungen sich in beiden Domänencontrollern befinden, bietet uns ClickHouse diese Möglichkeit. Geringe Latenz und Verfügbarkeit für die Anfrage - nur ein Meisterwerk!
Physisches Speicherschema
Nochmals Fragen: Wie werden unsere Daten in das relationale ClickHouse-Modell fallen, was sollte getan werden, um Replikation und Sharding nicht zu verlieren? In der
ClickHouse-Dokumentation wird alles ausführlich beschrieben. Wenn Sie mehr als einen Server haben, werden Sie auf diesen Artikel stoßen. Daher werden wir uns nicht mit dem befassen, was im Handbuch steht: Replikationen, Sharding und Abfragen aller Daten zu Shards.
Speicherlogik
Das Logikdiagramm ist das interessanteste. In einer Pipeline verarbeiten wir heterogene Ereignisse. Dies bedeutet, dass wir einen
Strom heterogener Ereignisse haben : Registrierung, Sprache, Foto-Upload, technische Metriken, Verfolgung des Benutzerverhaltens - all diese Ereignisse haben völlig
unterschiedliche Attribute . Ich habe zum Beispiel auf einem Mobiltelefon auf den Bildschirm geschaut - ich brauche eine Bildschirm-ID, ich habe für jemanden gestimmt - Sie müssen verstehen, ob die Abstimmung dafür oder dagegen war. Alle diese Ereignisse haben unterschiedliche Attribute, es werden unterschiedliche Diagramme darauf gezeichnet, aber all dies muss in einer einzigen Pipeline verarbeitet werden. Wie füge ich es in das ClickHouse-Modell ein?
Ansatz Nr. 1 - pro Ereignistabelle. Diesen ersten Ansatz haben wir aus den Erfahrungen mit MySQL extrapoliert - wir haben
für jedes Ereignis in ClickHouse ein
Tablet erstellt. Es klingt ziemlich logisch, aber wir sind auf eine Reihe von Schwierigkeiten gestoßen.
Wir haben keine Einschränkung, dass das Ereignis seine Struktur ändert, wenn der heutige Build veröffentlicht wird. Dieser Patch kann von jedem Entwickler durchgeführt werden. Das Schema ist im Allgemeinen in alle Richtungen veränderbar. Das einzige
erforderliche Feld ist das
Zeitstempelereignis und das Ereignis. Alles andere ändert sich im laufenden Betrieb, und dementsprechend müssen diese Platten modifiziert werden. ClickHouse kann
ALTER in einem Cluster ausführen. Dies ist jedoch ein heikles, heikles Verfahren, das schwer zu automatisieren ist, damit es reibungslos funktioniert. Daher ist dies ein Minus.
Wir haben mehr als tausend verschiedene Ereignisse, was zu einer
hohen INSERT-Rate pro Maschine führt - wir zeichnen ständig alle Daten in tausend Tabellen auf. Für ClickHouse ist dies ein Anti-Pattern. Wenn Pepsi den Slogan "Leben in großen Schlucken" hat, dann ClickHouse -
"Leben in großen Mengen
" . Wenn dies nicht erfolgt, wird die Replikation gedrosselt. ClickHouse lehnt es ab, neue Einfügungen zu akzeptieren - ein unangenehmes Schema.
Ansatz Nr. 2 - ein breiter Tisch . Sibirische Männer versuchten, die Kettensäge auf die Schiene zu schieben und ein anderes Datenmodell anzuwenden. Wir erstellen eine Tabelle mit
tausend Spalten , in der für jedes Ereignis Spalten für seine Daten reserviert sind. Wir bekommen eine riesige,
spärliche Tabelle - zum Glück ging dies nicht über die Entwicklungsumgebung hinaus, da von den ersten Einfügungen an klar wurde, dass das Schema absolut schlecht ist, und wir werden das nicht tun.
Trotzdem möchte ich ein so cooles Softwareprodukt verwenden, ein bisschen mehr zum Abschluss - und es wird genau das sein, was Sie brauchen.
Ansatz Nr. 3 - generische Tabelle. Wir haben eine große Tabelle, in der wir Daten in Arrays speichern, da ClickHouse
nicht skalare Datentypen unterstützt . Das heißt, wir beginnen eine Spalte, in der die Namen der Attribute gespeichert sind, und eine separate Spalte mit einem Array, in dem die Werte der Attribute gespeichert sind.
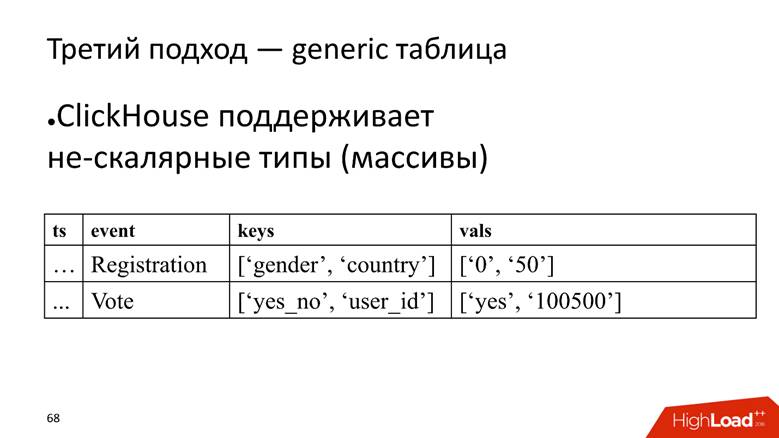
ClickHouse hier erfüllt seine Aufgabe sehr gut. Wenn wir nur Daten einfügen müssten, würden wir in der aktuellen Installation wahrscheinlich noch 10 Mal herausdrücken.
Die Fliege in der Salbe ist jedoch, dass sie auch ein Anti-Pattern für ClickHouse ist -
um Arrays von Strings zu speichern . Dies ist schlecht, da Zeilenarrays
mehr Speicherplatz beanspruchen - sie schrumpfen schlechter als einfache Spalten und sind
schwieriger zu verarbeiten . Für unsere Aufgabe schließen wir jedoch die Augen, da die Vorteile überwiegen.
Wie macht man SELECT aus einer solchen Tabelle? Unsere Aufgabe ist es, Registrierungen nach Geschlecht zu zählen. Zuerst müssen Sie in einem Array herausfinden, welche Position der Geschlechtsspalte entspricht, dann in eine andere Spalte mit diesem Index klettern und die Daten abrufen.
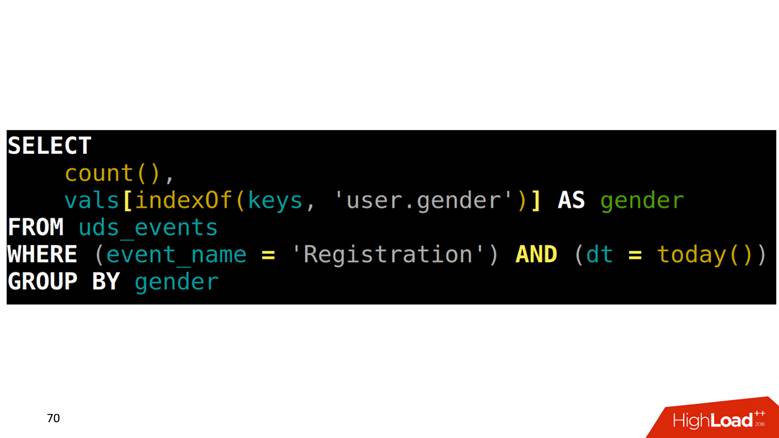
Wie zeichnet man Diagramme auf diesen Daten?
Da alle Ereignisse beschrieben sind und eine strikte Struktur haben, erstellen wir für jeden Ereignistyp eine vierstöckige SQL-Abfrage, führen sie aus und speichern die Ergebnisse in einer anderen Tabelle.
Das Problem ist, dass Sie
die gesamte Tabelle scannen müssen,
um zwei benachbarte Punkte in der Grafik zu zeichnen. Beispiel: Wir sehen uns die Registrierung pro Tag an. Dieses Ereignis ist von der obersten bis zur vorletzten Zeile. Einmal gescannt - ausgezeichnet. Nach 5 Minuten möchten wir einen neuen Punkt auf dem Diagramm zeichnen. Wieder scannen wir den Datenbereich, der sich mit dem vorherigen Scan überschneidet, und so weiter für jedes Ereignis. Klingt logisch, sieht aber nicht gut aus.
Wenn wir einige Zeilen nehmen, müssen wir außerdem
die Ergebnisse unter Aggregation lesen . Zum Beispiel gibt es eine Tatsache, dass Gottes Diener in Skandinavien registriert war und ein Mann war, und wir müssen die zusammenfassende Statistik berechnen: Wie viele Registrierungen, wie viele Männer, wie viele von ihnen sind Menschen und wie viele sind aus Norwegen. Dies wird in Bezug auf die Analysedatenbanken
ROLLUP, CUBE und
GROUPING SETS genannt - verwandeln Sie eine Zeile in mehrere.
Wie zu behandeln
Glücklicherweise verfügt ClickHouse über ein Tool zur Lösung dieses Problems, nämlich den
serialisierten Status von Aggregatfunktionen . Dies bedeutet, dass Sie ein Datenelement einmal scannen und diese Ergebnisse speichern können. Dies ist eine
Killer-Funktion . Vor 3 Jahren haben wir genau das bei Spark und Hadoop gemacht, und es ist cool, dass die besten Yandex-Köpfe parallel zu uns ein Analogon in ClickHouse implementiert haben.
Langsame Anfrage
Wir haben eine langsame Anfrage - eindeutige Benutzer für heute und gestern zu zählen.
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
Auf der physischen Ebene können wir SELECT für den gestrigen Zustand festlegen, seine binäre Darstellung abrufen und irgendwo speichern.
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
Für heute ändern wir nur die Bedingung, dass es heute sein wird:
'yyy' AS ts und
WHERE dt = today() und Zeitstempel werden wir "xxx" und "yyy" nennen. , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
8 ClickHouse , 6 - , 2 : 2 — , .
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
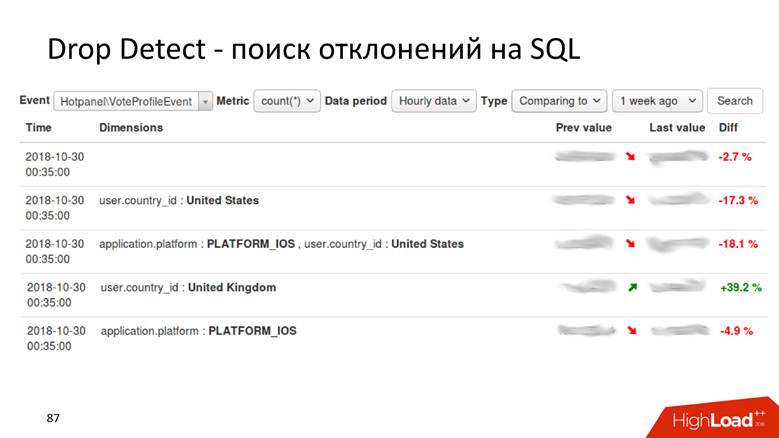
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
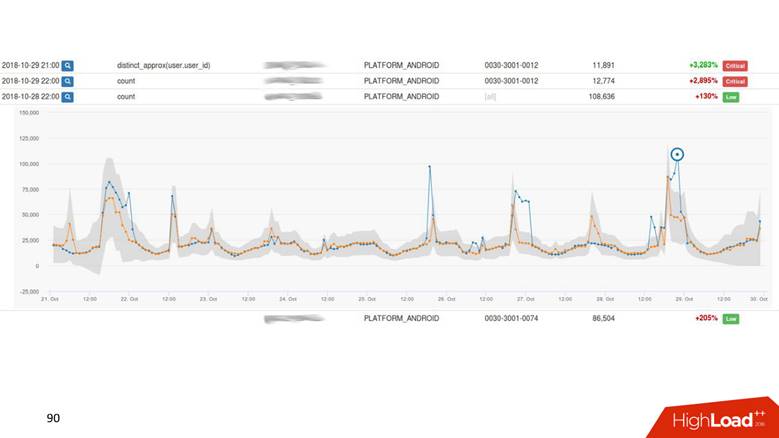
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .