Einführung
Netcracker ist ein internationales Unternehmen, das integrierte IT-Lösungen entwickelt, einschließlich Services für die Platzierung und den Support von Client-Geräten sowie das Hosting des erstellten IT-Systems für Telekommunikationsbetreiber.
Dies sind hauptsächlich Entscheidungen im Zusammenhang mit der Organisation der operativen und geschäftlichen Aktivitäten von Telekommunikationsbetreibern. Weitere Details finden Sie
hier .
Die ständige Verfügbarkeit der zu entwickelnden Lösung ist sehr wichtig. Wenn der Telekommunikationsbetreiber mindestens eine Stunde lang nicht mehr arbeitet, führt dies zu großen finanziellen und Reputationsverlusten sowohl für den Betreiber als auch für den Softwareanbieter. Eine der Hauptanforderungen für die Lösung ist daher der
Verfügbarkeitsparameter , dessen Wert je nach Lösungstyp zwischen 99,995% und 99,95% variiert.
Die Lösung selbst besteht aus einem komplexen Satz zentraler monolithischer IT-Systeme, einschließlich komplexer Telekommunikationsgeräte und Service-Software in einer öffentlichen Cloud sowie vieler in einen zentralen Kern integrierter Mikrodienste.
Daher ist es für das Support-Team sehr wichtig, alle in einer einzigen Lösung integrierten Hardware- und Softwaresysteme zu überwachen. Am häufigsten verwendet das Unternehmen die traditionelle Überwachung. Dieser Prozess ist gut etabliert: Wir können ein ähnliches Überwachungssystem von Grund auf neu aufbauen und wissen, wie Vorfallreaktionsprozesse richtig organisiert werden. Es gibt jedoch einige Schwierigkeiten bei diesem Ansatz, mit denen wir von Projekt zu Projekt konfrontiert sind.
- Was zu überwachen
Welche Metrik ist aktuell wichtig und welche wird in Zukunft wichtig sein? Da es hier keine eindeutige Antwort gibt, versuchen wir, alles zu überwachen . Schwierigkeit Nummer eins - die Anzahl der Metriken. Es gibt Leistungsprobleme, Betriebs-Dashboards ähneln zunehmend einem Bedienfeld eines Raumfahrzeugs.
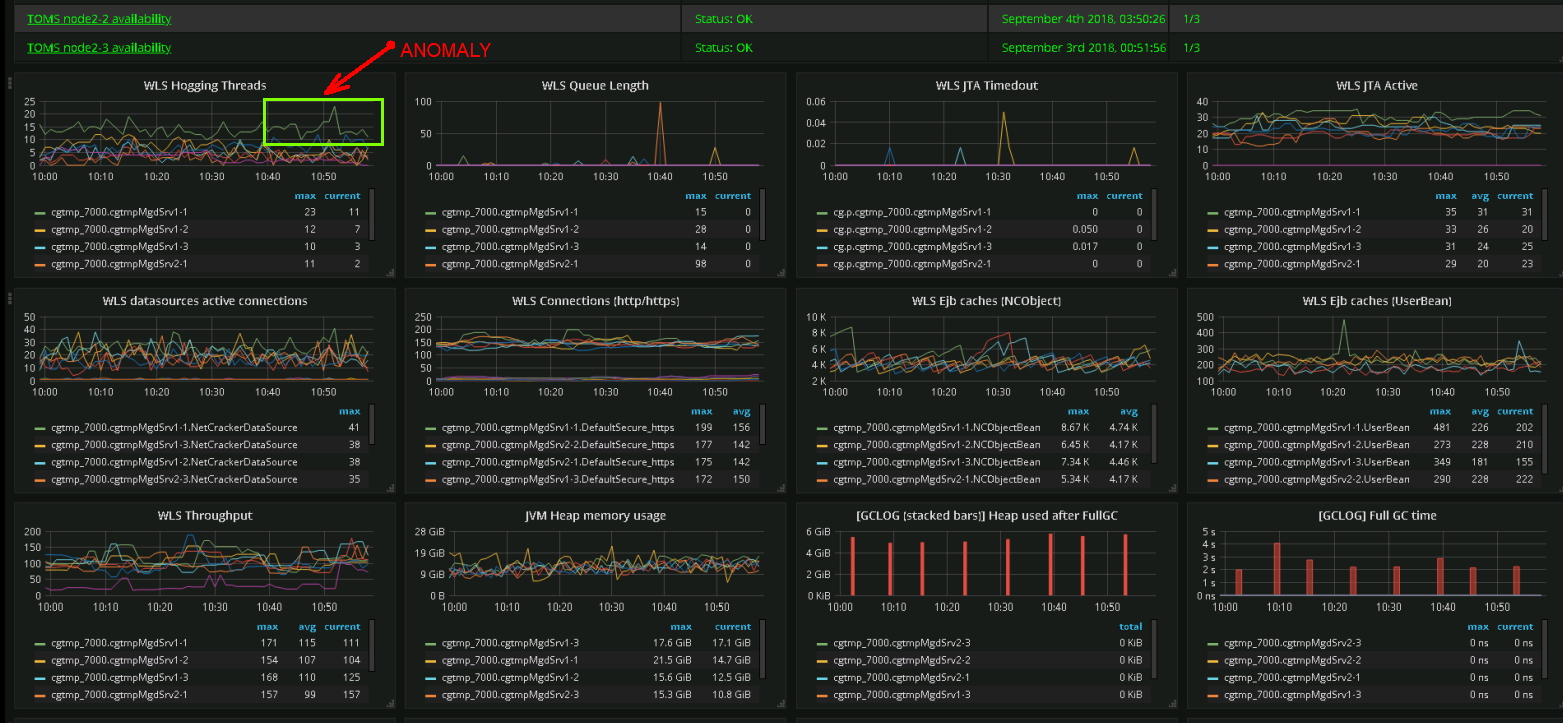
Screenshot eines echten Dashboards. Die Ingenieure des Supportteams können Anomalien im Systemverhalten anhand ihrer grafischen Darstellung identifizieren
- Alarm / Schwellenwert
Trotz der Tatsache, dass wir Erfahrung mit dem Betrieb vieler großer Systeme haben, ist die Überwachung aufgrund der Besonderheiten der verwendeten Geräte und der Softwareversionen verschiedener Anbieter immer noch eine schwierige Aufgabe. Erfahrung und vorgefertigte Regeln können oft nicht vollständig von einer Lösung auf eine andere übertragen werden. Es gibt eine bestimmte Grundmenge, deren Verbesserung iterativ erfolgt, beispielsweise die Analyse von Vorfällen, die sich aus dem Betrieb der Lösung ergeben.
Schwierigkeit Nummer zwei ist das Fehlen klarer Regeln für die Anpassung. - Interpretation des Ergebnisses
Wenn ein Vorfall auftritt, ist es sehr wichtig, ihn schnell zu lokalisieren. Dies hängt weitgehend von der Erfahrung des Supportteams ab, da Sie unter den sekundären Meldungen zu Fehlern die Hauptursache der Probleme nicht erkennen und bei einer betrieblichen Reaktion Zeit verlieren können. Und das ist Komplexität drei.
Mit Hilfe ordnungsgemäß organisierter Prozesse ist das Team in der Lage, die oben genannten Schwierigkeiten zu bewältigen. Die moderne Forderung nach einer reaktiven Entscheidungsänderung - wenn die Zeit für den Übergang von einer Idee zur Umsetzung in Tagen gemessen wird - erschwert die Aufgabe jedoch erheblich. Kontinuierliches Teamtraining ist erforderlich. Ständige Änderungen führen dazu, dass bestimmte Regeln und Ursache-Wirkungs-Beziehungen ihre Bedeutung verlieren und der Vorfall, der nicht umgehend behoben wird, zu einem Unfall werden kann.
Wie maschinelles Lernen uns hilft
Die Vorhersage von Fehlfunktionen von Hardware- und Softwaresystemen wird zu einer sehr beliebten Funktion einer vorbeugenden oder reaktiven Reaktion auf Vorfälle.
Die NEC Corporation, unsere Muttergesellschaft, investiert stark in die Entwicklung der Überwachungsidee. Ein Ergebnis dieser Investition ist die patentierte
System Invariant Analysis Technology (SIAT) .
SIAT ist eine Technologie für maschinelles Lernen, die aus dem Datensatz von Sensoren oder Metriken, die als Zeitreihen dargestellt werden, mithilfe von ML-Algorithmen konstante funktionale Beziehungen findet und ein allgemeines Modell erstellt - ein Diagramm dieser Beziehungen. Details finden Sie
hier .
Abbildung zur Darstellung der Beziehung zwischen Sensoren physischer Objekte
Die ursprünglich für IT-Systeme entwickelte Idee hat sich derzeit nur zur Überwachung physikalischer Komplexe wie Fabriken, Fabriken und Kernkraftwerke verbreitet.
Lockheed Martin beispielsweise
implementiert diese Technologien in seiner Raumfahrtabteilung. Im Jahr 2018
überarbeitete Netcracker zusammen mit
NEC diese Idee und entwickelte ein Produkt zur Überwachung von IT-Systemen als Werkzeug für zusätzliche Analysen.
Wichtig : Dies ist nur eine Ergänzung des Überwachungssystems, nicht jedoch dessen Ersatz.
SIAT-Anwendungen für IT-Systeme
Was ist der Unterschied zwischen einem physischen Komplex und einer Software? In Softwaresystemen werden Metriken verwendet, in physischen - Sensoren. Die Metrik wird viel häufiger verwendet, da ein physikalischer Sensor immer das Geld wert ist und nur dort platziert wird, wo es Sinn macht. Software-Metriken kosten bei richtiger Organisation nichts. Darüber hinaus ist es viel schwieriger, Datenmetriken von Informationssystemen korrekt auf den Zustand des Systems zu interpolieren. Für eine Person ist es einfacher, Sensoren zu verstehen, die sich auf die physische Welt beziehen, während bestimmte Werte von Softwaremetriken nur in Bezug auf eine bestimmte Hardware, Konfiguration und Last sinnvoll sind.
Die
funktionale Verbindung im Modell legt auch nahe, dass wenn wir die Hardware- oder Softwareversion (z. B. Betriebssystem-Patches) ersetzen und alle Vorgänge gleichermaßen schneller oder langsamer werden, dies nicht zu falschen Meldungen über Unfälle führt, da wir keine Änderungen vorgenommen haben
Schwellenwerte . Wenn die Metriken nicht mehr miteinander korrelieren, bedeutet dies eine Abweichung von der Norm im Verhalten des Systems. Darüber hinaus können mit der
SIAT- Technologie auch kleine Verhaltensabweichungen in Echtzeit erkannt werden, einschließlich der sogenannten
stillen Ausfälle - Fehlfunktionen, die nicht von Fehlermeldungen begleitet werden. Und wenn diese Abweichung nur ein Vorbote eines größeren Fehlers ist, haben wir Zeit, richtig zu reagieren.
Wir haben diese Aussage überprüft, indem wir einen kleinen Apache-Webserver unter Last simuliert und interne Fehler mithilfe des
Fehlerinjektionsmechanismus unter Linux emuliert haben.
Das Ergebnis wird in Form eines numerischen metrischen
Anomalie-Scores dargestellt , dessen Wert diesem Modell zugeordnet ist. Je größer der Wert, desto schwerwiegender der Fehler: Je mehr Metriken verhalten sich abnormal. Der Grenzwert ist 100% der Metriken sind abnormal, das System funktioniert nicht. Darüber hinaus zeigt das Ergebnis diejenigen Metriken an, deren Verhalten im Moment als abnormal angesehen werden kann. Dies beschleunigt die Analyse der Ursache und die Identifizierung des Subsystems, das derzeit im aktuellen Verhaltensmodell ausfällt, erheblich.
Im Allgemeinen können
Sie mit
SIAT auch auf geringfügige Verhaltensänderungen reagieren, die mit der herkömmlichen Überwachung oder der Basisüberwachung kaum erkennbar sind.
Abbildung zeigt eine Störung in der Beziehung zwischen Sensoren
Ein zusätzlicher Vorteil von
SIAT ist der Algorithmus zum Erstellen eines Verhaltensmodells, bei dem kein geschäftlicher Sinn für die Metriken angegeben werden muss. Der Algorithmus wählt automatisch alle Metriken aus, deren Verhalten miteinander verbunden ist, und diese Beziehung ist konstant. Die verbleibenden isolierten Metriken sind entweder Punktsubsysteme, die sich nicht auf die IT-Lösung auswirken, oder Metriken, die für den aktuellen Status der Lösung nicht wichtig sind. Wenn es sinnvoll ist, wird die Überwachung solcher Metriken im Rahmen des traditionellen Ansatzes implementiert, der auf
Schwellenwertwarnungen basiert.
Es ist sehr wichtig, dass für die Erstellung eines Modells Daten erforderlich sind, die sich auf die normale Funktionsweise des Systems beziehen. Dies ist
viel einfacher als bei der Annäherung an das Unfalltraining.
Das Modell wird weiter verfeinert und neu erstellt, wenn sich das Verhalten geändert hat oder wir neue Metriken hinzugefügt haben.
Da das normale Verhalten des Systems ein variables Merkmal ist, das von der Tageszeit und anderen Geschäftsbedingungen abhängt, ist es für eine genauere Reaktion sinnvoll, mehrere Modelle zu erstellen, die das Verhalten des Systems unter bestimmten Bedingungen beschreiben.
Wie sieht der Prozess aus?
Der Prozess der Überwachungsorganisation ist wie folgt.
- Wir beginnen mit der traditionellen Überwachung. Die richtige Wahl des Namens der Metriken ist sehr wichtig. Tatsache ist, dass das Ergebnis die Namen von Metriken enthält, deren Verhalten abnormal ist. Dies bedeutet, dass das Ergebnis umso schneller erhalten wird, je genauer die Metrik den Ort und die Bedeutung beschreibt. Zum Beispiel eine Metrik namens ncp. erp_netcracker _com.apps.erp. clust4.wls .jdbc. LMSDataSource . ActiveConnectionsCurrentCount gibt an, dass im Netcracker-ERP-System eine Metrik mit dem Namen ActiveConnectionsCurrentCount im vierten Weblogic-Cluster für die LMSDataSource fehlschlägt . Für den Experten sind solche Informationen mehr als ausreichend, um die Anomalie genau zu lokalisieren.
- Als Nächstes integrieren wir das Datenspeichersystem für Metriken - in unserem Fall ClickHouse - und erhalten die Daten für alle Metriken für einen bestimmten Zeitraum des normalen Verhaltens der Lösung: Die besten Modelle werden auf der Grundlage von 30-Tage-Überwachungsergebnissen erstellt. Um genauere Modelle zu erhalten, verwenden wir Metrikdaten pro Minute ohne Aggregation.
- Wir erstellen ein Modell mit SIAT basierend auf Daten eines Überwachungssystems. Im Rahmen des konstruierten Modells filtern wir die funktionalen Beziehungen nach dem Grad der Ähnlichkeit heraus. Kurz gesagt, dies ist der Grad der Abweichung des Verhaltens von einer bestimmten, ausgedrückt als Prozentsatz.
- Wir überprüfen das Modell anhand der Daten der vergangenen Tage, bei denen mithilfe des herkömmlichen Überwachungs- und Supportteams Fehler festgestellt wurden.
- Wir beginnen mit der Online-Überwachung: Alle 10 Minuten werden die Daten aller Metriken auf das Modell oder die Modelle übertragen. Wir erhalten das Ergebnis - Anomalie-Score, und wenn das Ergebnis nicht Null ist, erhalten wir zusätzlich eine Liste von Metriken, deren Verhalten derzeit abnormal ist.
- Das Ergebnis wird an das allgemeine Überwachungssystem gesendet, wo es Teil der allgemeinen Dashboards und anderer traditioneller Überwachungstools wird.
Test
Keine einzige Implementierung erfolgt ohne Überprüfung. Als getestete Systeme haben wir unser eigenes
ERP (Monolith,
Weblogic ,
Oracle , 4500 Metriken) und das Routing-System unseres gesamten Überwachungssystems ausgewählt, 7 Millionen Metriken pro Minute -
Carbon-C-Relay (1200 Metriken).
Dumps aller Metriken wurden als Eingabe verwendet, und die Tage, an denen Fehler aufgezeichnet wurden, wurden ebenfalls angegeben. Um das Ergebnis zu bewerten, haben wir folgende Konzepte eingeführt:
- Die Anzahl der Fehler der zweiten Art ist, wenn ein herkömmliches Überwachungssystem oder Support-Team einen Fehler festgestellt hat, SIAT jedoch nicht.
- Die Anzahl der korrekten Erkennungen - wenn sowohl die herkömmliche Überwachung als auch SIAT ein Problem festgestellt haben.
- Die Anzahl der Fehler der ersten Art - als der SIAT eine Abweichung des Verhaltens feststellte, das Support-Team sie jedoch nicht fand.
Wir haben für beide getesteten Systeme keine Fehler der zweiten Art gefunden. Die Anzahl der korrekten Erkennungen - 85% der Gesamtzahl der von
SIAT gefundenen Fehler und im Falle eines Geräteausfalls - ein RAID-Array in der Datenbank ist
fehlgeschlagen. -
SIAT hat sieben Stunden vor Erreichen eine Verschlechterung des Verhaltens mit einer genauen Angabe der mit der Datenbank verbundenen Metriken festgestellt Schwellenwert im Überwachungssystem einstellen.
Die verbleibenden 15% der angegebenen
SIAT- Fehler sind Fehler der ersten Art - abnormales Verhalten, das das Support-Team nicht erklären kann. Dies ist wahrscheinlich auf die Tatsache zurückzuführen, dass bei der Erstellung des Modells automatisch die Metriken einbezogen wurden, die eine funktionale Bedeutung haben, sich jedoch nicht merklich auf das allgemeine Verhalten des Systems auswirken. Nach mehreren Fehlalarmen kann ein IT-Experte diese Kennzahlen als unwichtig markieren und aus dem Modell entfernen, nachdem er dies zuvor mit dem
KMU vereinbart hat.
Die Ergebnisse zeigten, dass dieses Produkt den Prozess der Erkennung von Fehlern (einschließlich versteckter Fehler), der rechtzeitigen Lokalisierung des Vorfalls und der Bewertung seines Ausmaßes vollständig automatisiert.
Was weiter
Jetzt sammeln wir Erfahrung im Betrieb des Produkts für verschiedene Arten von Hardware- und Softwaresystemen, um die Anwendbarkeit dieses Ansatzes auf verschiedene Systeme zu analysieren: Netzwerkgeräte,
IoT- Geräte, Cloud-Mikrodienste usw.
Im Moment ist die Aufgabe des Wiederaufbaus des Modells der Engpass. Dies erfordert eine erhebliche Rechenleistung, aber glücklicherweise kann die Nachzählung auf einer isolierten Maschine durchgeführt werden, wobei das Ergebnis als fertiges Modell exportiert wird. Die Echtzeitüberwachung selbst erfordert keine wesentlichen Ressourcen und wird parallel zur herkömmlichen Überwachung auf demselben Gerät durchgeführt.
Fazit
Zusammenfassend möchte ich darauf hinweisen, dass Sie mithilfe einer Kombination aus herkömmlichen Überwachungstechniken und Algorithmen für maschinelles Lernen ein einfaches Modell erstellen können, mit dem Sie rechtzeitig reagieren, herausfinden können, wo das Problem entstanden ist, und das System in einem funktionsfähigen Zustand halten können.
Neben der vielversprechenden
SIAT- Technologie analysieren wir die Möglichkeiten einer weiteren
NEC- Technologie -
Next Generation Log Analytics . Die Technologie ermöglicht die Verwendung von Algorithmen für maschinelles Lernen und die Verwendung von Systemprotokollen, um Anomalien im Zusammenhang mit dem internen Status des Produkts zu ermitteln, die die Gesamtverschlechterung des Systems in Bezug auf die Leistung nicht beeinflussen.
Welche Analysen verwenden Sie zur Überwachung von IT-Systemen?