
Traditionelle Tools auf dem Gebiet der Datenwissenschaft sind Sprachen wie R und Python - eine entspannte Syntax und eine große Anzahl von Bibliotheken für maschinelles Lernen und Datenverarbeitung ermöglichen es Ihnen, schnell einige funktionierende Lösungen zu erhalten. Es gibt jedoch Situationen, in denen die Einschränkungen dieser Tools zu einem erheblichen Hindernis werden - vor allem dann, wenn eine hohe Verarbeitungsgeschwindigkeit und / oder die Arbeit mit wirklich großen Datenmengen erforderlich sind. In diesem Fall muss sich der Spezialist widerstrebend an die "dunkle Seite" wenden und Tools in den "industriellen" Programmiersprachen verbinden: Scala , Java und C ++ .
Aber ist diese Seite so dunkel? Im Laufe der Jahre der Entwicklung haben die Tools der "industriellen" Data Science einen langen Weg zurückgelegt und unterscheiden sich heute erheblich von ihren eigenen Versionen vor 2-3 Jahren. Versuchen wir am Beispiel der Aufgabe SNA Hackathon 2019 herauszufinden, inwieweit das Scala + Spark-Ökosystem Python Data Science entsprechen kann.
Im Rahmen des SNA Hackathon 2019 lösen die Teilnehmer das Problem, den Newsfeed eines Nutzers eines sozialen Netzwerks in einer von drei „Disziplinen“ zu sortieren: anhand von Daten aus Texten, Bildern oder Feature-Logs. In dieser Veröffentlichung werden wir untersuchen, wie es in Spark möglich ist, ein Problem anhand eines Zeichenprotokolls mit klassischen maschinellen Lernwerkzeugen zu lösen.
Bei der Lösung des Problems gehen wir den Standard vor, den jeder Datenanalysespezialist bei der Entwicklung eines Modells durchläuft:
- Wir werden Forschungsdaten analysieren, Diagramme erstellen.
- Wir analysieren die statistischen Eigenschaften von Zeichen in den Daten und untersuchen deren Unterschiede zwischen Trainings- und Testsätzen.
- Wir werden eine erste Auswahl von Merkmalen basierend auf statistischen Eigenschaften durchführen.
- Wir berechnen die Korrelationen zwischen den Zeichen und der Zielvariablen sowie die Kreuzkorrelation zwischen den Zeichen.
- Wir werden die endgültigen Funktionen bilden, das Modell trainieren und seine Qualität überprüfen.
- Analysieren wir die interne Struktur des Modells, um Wachstumspunkte zu identifizieren.
Während unserer „Reise“ werden wir Tools wie das interaktive Zeppelin- Notizbuch, die Spark ML- Bibliothek für maschinelles Lernen und deren Erweiterung PravdaML , das GraphX- Grafikpaket , die Vegas- Visualisierungsbibliothek und natürlich Apache Spark in seiner ganzen Pracht kennenlernen: ) Alle Code- und Versuchsergebnisse sind auf der Zepl-Plattform für kollaborative Notizbücher verfügbar .
Laden von Daten
Die Besonderheit der beim SNA Hackathon 2019 bereitgestellten Daten besteht darin, dass sie direkt mit Python verarbeitet werden können, dies ist jedoch schwierig: Die Originaldaten werden dank der Funktionen des Apache Parquet-Spaltenformats recht effizient gepackt und beim Lesen in den Speicher „über die Stirn“ in mehrere zehn Gigabyte dekomprimiert. Bei der Arbeit mit Apache Spark müssen die Daten nicht vollständig in den Speicher geladen werden. Die Spark-Architektur ist so konzipiert, dass Daten in Teilen verarbeitet und bei Bedarf von der Festplatte geladen werden.
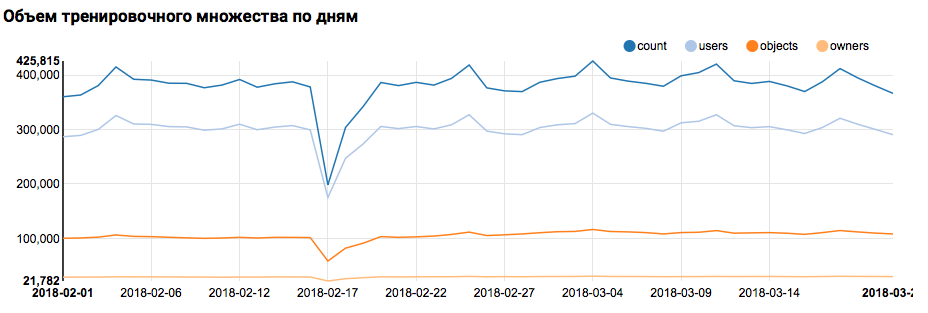
Daher kann der erste Schritt - Überprüfen der Datenverteilung nach Tag - problemlos mit Box-Tools ausgeführt werden:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
Was die entsprechende Grafik in Zeppelin anzeigt:
Ich muss sagen, dass die Scala-Syntax sehr flexibel ist und derselbe Code beispielsweise folgendermaßen aussehen kann:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
Hier ist eine wichtige Warnung zu beachten: Wenn man in einem großen Team arbeitet, in dem jeder das Schreiben von Scala-Code ausschließlich aus der Sicht seines eigenen Geschmacks betrachtet, ist die Kommunikation viel schwieriger. Es ist daher besser, ein einheitliches Konzept für den Codestil zu entwickeln.
Aber zurück zu unserer Aufgabe. Eine einfache Analyse am Tag zeigte das Vorhandensein abnormaler Punkte am 17. und 18. Februar; Wahrscheinlich wurden heutzutage unvollständige Daten gesammelt und die Verteilung der Merkmale kann verzerrt sein. Dies sollte bei der weiteren Analyse berücksichtigt werden. Darüber hinaus fällt auf, dass die Anzahl der eindeutigen Benutzer sehr nahe an der Anzahl der Objekte liegt. Daher ist es sinnvoll, die Verteilung der Benutzer mit unterschiedlicher Anzahl von Objekten zu untersuchen:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
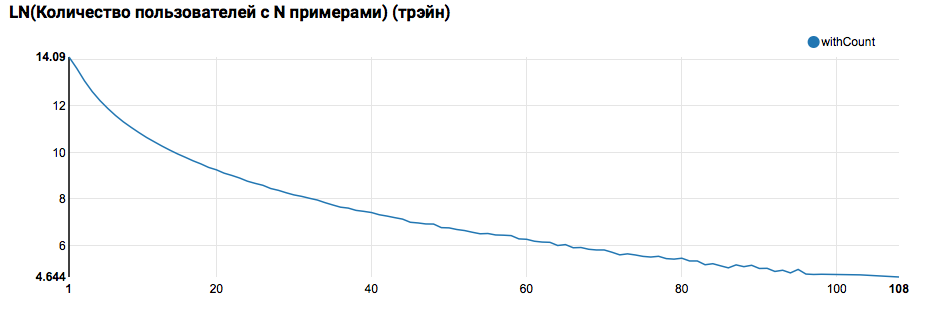
Es wird eine nahezu exponentielle Verteilung mit einem sehr langen Schwanz erwartet. Bei solchen Aufgaben ist es in der Regel möglich, die Arbeitsqualität zu verbessern, indem Modelle für Benutzer mit unterschiedlichen Aktivitätsstufen segmentiert werden. Um zu überprüfen, ob es sich lohnt, dies zu tun, vergleichen Sie die Verteilung der Anzahl der Objekte nach Benutzer im Testsatz:
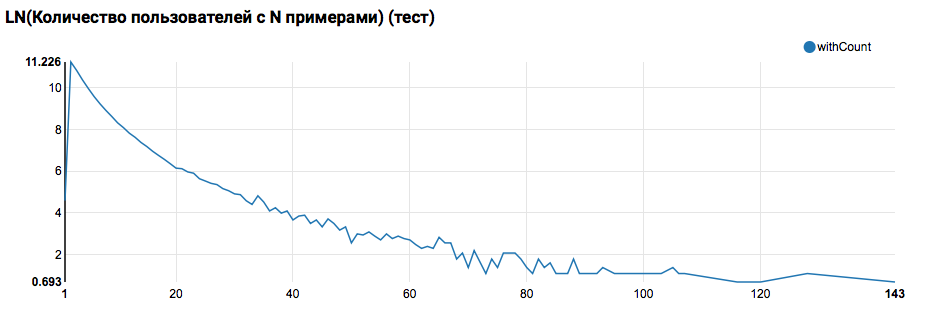
Ein Vergleich mit dem Test zeigt, dass Testbenutzer mindestens zwei Objekte in den Protokollen haben (da das Ranking-Problem beim Hackathon gelöst ist, ist dies eine notwendige Voraussetzung für die Bewertung der Qualität). In Zukunft empfehle ich, die Benutzer im Trainingssatz, für die wir die benutzerdefinierte Funktion mit einem Filter deklarieren, genauer zu betrachten:
Auch hier ist eine wichtige Bemerkung zu machen: Unter dem Gesichtspunkt der Definition von UDF unterscheidet sich die Verwendung von Spark unter Scala / Java und unter Python deutlich. Während der PySpark-Code die Grundfunktionalität verwendet, funktioniert alles fast genauso schnell, aber wenn überschriebene Funktionen angezeigt werden, verschlechtert sich die Leistung von PySpark um eine Größenordnung.
Die erste ML-Pipeline
Im nächsten Schritt werden wir versuchen, die grundlegenden Statistiken zu Aktionen und Attributen zu berechnen. Dafür benötigen wir jedoch die Funktionen von SparkML. Zunächst werden wir uns die allgemeine Architektur ansehen:

SparkML basiert auf folgenden Konzepten:
- Transformator - Nimmt einen Datensatz als Eingabe und gibt einen geänderten Satz (Transformation) zurück. In der Regel wird es zur Implementierung von Vor- und Nachbearbeitungsalgorithmen sowie zur Merkmalsextraktion verwendet und kann auch die resultierenden ML-Modelle darstellen.
- Schätzer - Nimmt einen Datensatz als Eingabe und gibt Transformer (fit) zurück. Natürlich kann Estimator den ML-Algorithmus darstellen.
- Pipeline ist ein Sonderfall von Estimator, der aus einer Kette von Transformatoren und Schätzern besteht. Wenn die Methode aufgerufen wird, durchläuft fit die Kette, und wenn es einen Transformator sieht, wendet es ihn auf die Daten an, und wenn es einen Schätzer sieht, trainiert es den Transformator damit, wendet ihn auf die Daten an und geht weiter.
- PipelineModel - Das Ergebnis von Pipeline enthält auch eine Kette im Inneren, die jedoch ausschließlich aus Transformatoren besteht. Dementsprechend ist PipelineModel selbst auch ein Transformator.
Ein solcher Ansatz zur Bildung von ML-Algorithmen trägt zu einer klaren modularen Struktur und einer guten Reproduzierbarkeit bei - sowohl Modelle als auch Pipelines können gespeichert werden.
Zunächst erstellen wir eine einfache Pipeline, mit der wir die Statistik der Verteilung der Aktionen (Feedbackfeld) der Benutzer im Trainingssatz berechnen:
val feedbackAggregator = new Pipeline().setStages(Array(
In dieser Pipeline wird die Funktionalität von PravdaML aktiv genutzt - Bibliotheken mit erweiterten nützlichen Blöcken für SparkML, nämlich:
- MultinominalExtractor wird verwendet, um ein Zeichen vom Typ "Array of Strings" nach dem One-Hot-Prinzip in einen Vektor zu codieren. Dies ist der einzige Schätzer in der Pipeline (um eine Codierung zu erstellen, müssen Sie eindeutige Zeilen aus dem Datensatz erfassen).
- Mit VectorStatCollector werden Vektorstatistiken berechnet.
- Mit VectorExplode wird das Ergebnis in ein für die Visualisierung geeignetes Format konvertiert.
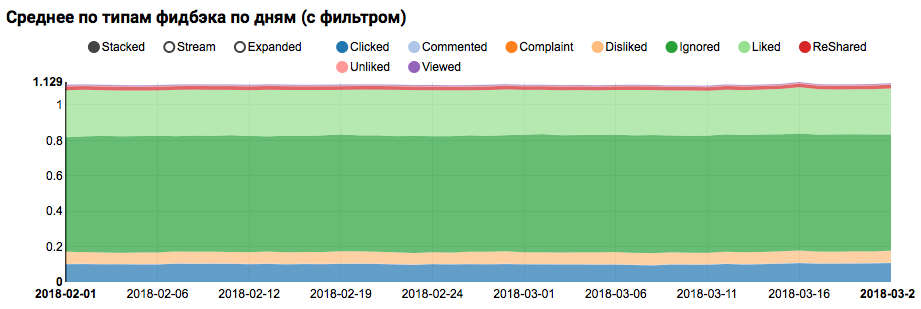
Das Ergebnis der Arbeit wird eine Grafik sein, die zeigt, dass die Klassen im Datensatz nicht ausgeglichen sind. Das Ungleichgewicht für die Zielklasse "Gefällt mir" ist jedoch nicht extrem:

Die Analyse einer ähnlichen Verteilung unter Benutzern, die Testbenutzern ähnlich sind (mit "positiv" und "negativ" in den Protokollen), zeigt, dass sie auf die positive Klasse ausgerichtet ist:
Statistische Analyse von Zeichen
In der nächsten Phase werden wir eine detaillierte Analyse der statistischen Eigenschaften der Attribute durchführen. Diesmal brauchen wir einen größeren Förderer:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
Da wir jetzt nicht mit einem separaten Feld arbeiten müssen, sondern mit allen Attributen gleichzeitig, werden wir zwei weitere nützliche PravdaML- Dienstprogramme verwenden:
- Mit NullToDefaultReplacer können Sie fehlende Elemente in den Daten durch ihre Standardwerte ersetzen (0 für Zahlen, false für logische Variablen usw.). Wenn Sie diese Konvertierung nicht durchführen, werden NaN-Werte in den resultierenden Vektoren angezeigt, was für viele Algorithmen fatal ist (obwohl beispielsweise XGBoost dies überleben kann). Eine Alternative zum Ersetzen durch Nullen kann das Ersetzen durch Durchschnittswerte sein. Dies ist in NaNToMeanReplacerEstimator implementiert.
- AutoAssembler ist ein sehr leistungsfähiges Dienstprogramm, das das Tabellenlayout analysiert und für jede Spalte ein Vektorisierungsschema auswählt, das dem Spaltentyp entspricht.
Mit der resultierenden Pipeline berechnen wir die Statistiken für drei Sätze (Training, Training mit Benutzerfilter und Test) und speichern sie in separaten Dateien:
Nachdem wir drei Datensätze mit Attributstatistiken erhalten haben, analysieren wir die folgenden Dinge:
- Haben wir Zeichen, für die es große Emissionen gibt?
- Solche Zeichen sollten begrenzt oder Ausreißerdatensätze herausgefiltert werden. - Haben wir Zeichen mit einer großen Abweichung des Mittelwerts relativ zum Median?
- Eine solche Verschiebung tritt häufig bei Vorhandensein einer Leistungsverteilung auf. Es ist sinnvoll, diese Vorzeichen zu logarithmieren. - Gibt es eine Verschiebung der durchschnittlichen Verteilungen zwischen Trainings- und Testsätzen?
- Wie dicht unsere Feature-Matrix gefüllt ist.
Um diese Aspekte zu klären, hilft uns eine solche Anfrage:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
In dieser Phase ist die Frage nach der Visualisierung dringend: Es ist schwierig, alle Aspekte mit normalen Zeppelin-Werkzeugen sofort anzuzeigen, und Notebooks mit einer großen Anzahl von Grafiken verlangsamen sich aufgrund des aufgeblähten DOM merklich. Die Vegas - DSL - Bibliothek auf Scala zum Erstellen von Vega-Lite - Spezifikationen kann dieses Problem lösen. Vegas bietet nicht nur umfassendere Visualisierungsfunktionen (vergleichbar mit matplotlib), sondern zeichnet sie auch auf Canvas, ohne das DOM aufzublasen :).
Die Spezifikation des Diagramms, an dem wir interessiert sind, sieht folgendermaßen aus:
vegas.Vegas(width = 1024, height = 648)
Die folgende Tabelle sollte folgendermaßen lauten:
- Die X-Achse zeigt die Verschiebung der Verteilungszentren zwischen Test- und Trainingssatz (je näher an 0, desto stabiler das Vorzeichen).
- Der Prozentsatz der Elemente ungleich Null ist entlang der Y-Achse aufgetragen (je höher, desto mehr Daten sind für die größere Anzahl von Punkten pro Attribut vorhanden).
- Die Größe zeigt die Verschiebung des Durchschnitts relativ zum Median (je größer der Punkt, desto wahrscheinlicher ist die Verteilung des Potenzgesetzes dafür).
- Farbe zeigt Emissionen an (je röter, desto mehr Emissionen).
- Nun, das Formular zeichnet sich durch einen Vergleichsmodus aus: mit einem Benutzerfilter im Trainingssatz oder ohne Filter.
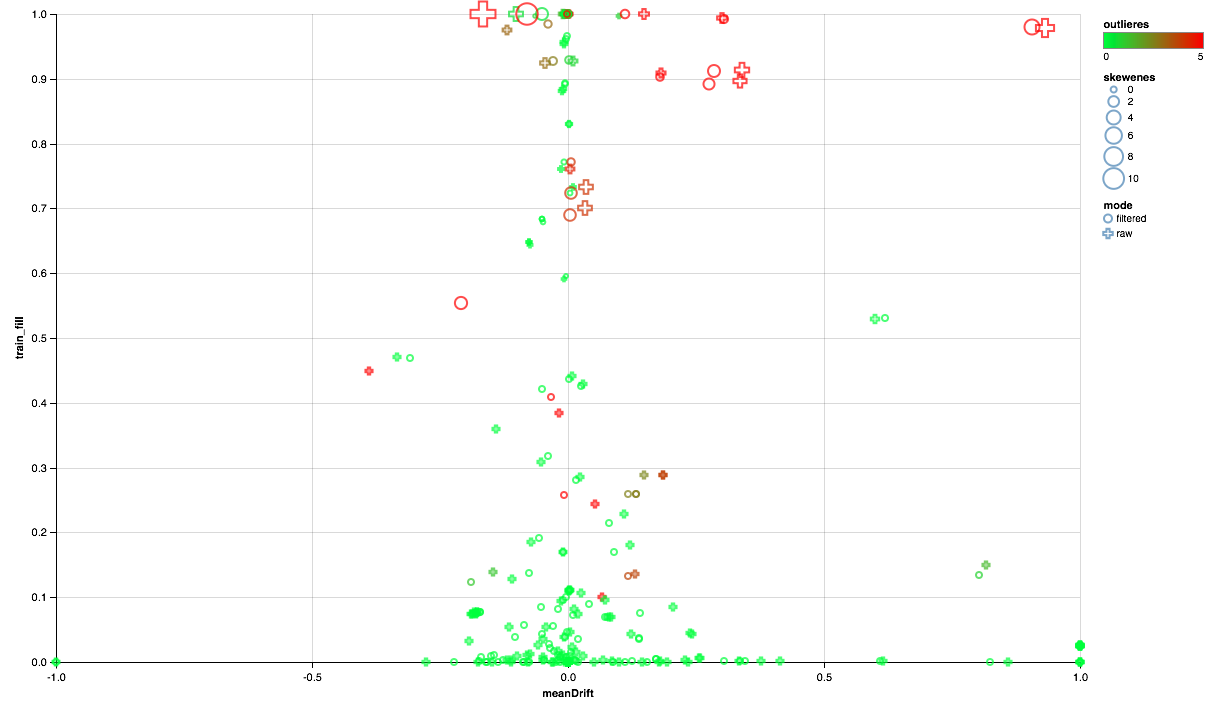
Wir können also die folgenden Schlussfolgerungen ziehen:
- Einige Zeichen benötigen einen Emissionsfilter - wir begrenzen die Maximalwerte für das 90. Perzentil.
- Einige Zeichen zeigen eine Verteilung nahe der Exponentialverteilung - wir nehmen den Logarithmus.
- Einige Funktionen werden im Test nicht vorgestellt - wir werden sie vom Training ausschließen.
Korrelationsanalyse
Nachdem Sie eine allgemeine Vorstellung davon erhalten haben, wie die Attribute verteilt sind und wie sie sich zwischen den Trainings- und Testsätzen verhalten, versuchen wir, die Korrelationen zu analysieren. Konfigurieren Sie dazu den Feature-Extraktor basierend auf früheren Beobachtungen:
Von den neuen Maschinen in dieser Pipeline fällt das Dienstprogramm SQLTransformer auf, das beliebige SQL-Transformationen der Eingabetabelle ermöglicht.
Bei der Analyse von Korrelationen ist es wichtig, das Rauschen herauszufiltern, das durch die natürliche Korrelation von One-Hot-Features erzeugt wird. Dazu möchte ich verstehen, welche Elemente des Vektors welchen Quellenspalten entsprechen. Diese Aufgabe in Spark wird mithilfe von Spaltenmetadaten (mit Daten gespeichert) und Attributgruppen ausgeführt. Der folgende Codeblock wird verwendet, um Paare von Attributnamen zu filtern, die aus derselben Spalte vom Typ String stammen:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
Wenn Sie einen Datensatz mit einer Vektorspalte zur Hand haben, ist die Berechnung von Kreuzkorrelationen mit Spark recht einfach. Das Ergebnis ist jedoch eine Matrix, für deren Bereitstellung Sie ein wenig in eine Reihe von Paaren spielen müssen:
val pearsonCorrelation =
Und natürlich Visualisierung: Wir brauchen wieder Vegas Hilfe, um eine Heatmap zu zeichnen:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
Das Ergebnis ist besser in Zepl-e zu sehen . Für ein allgemeines Verständnis:
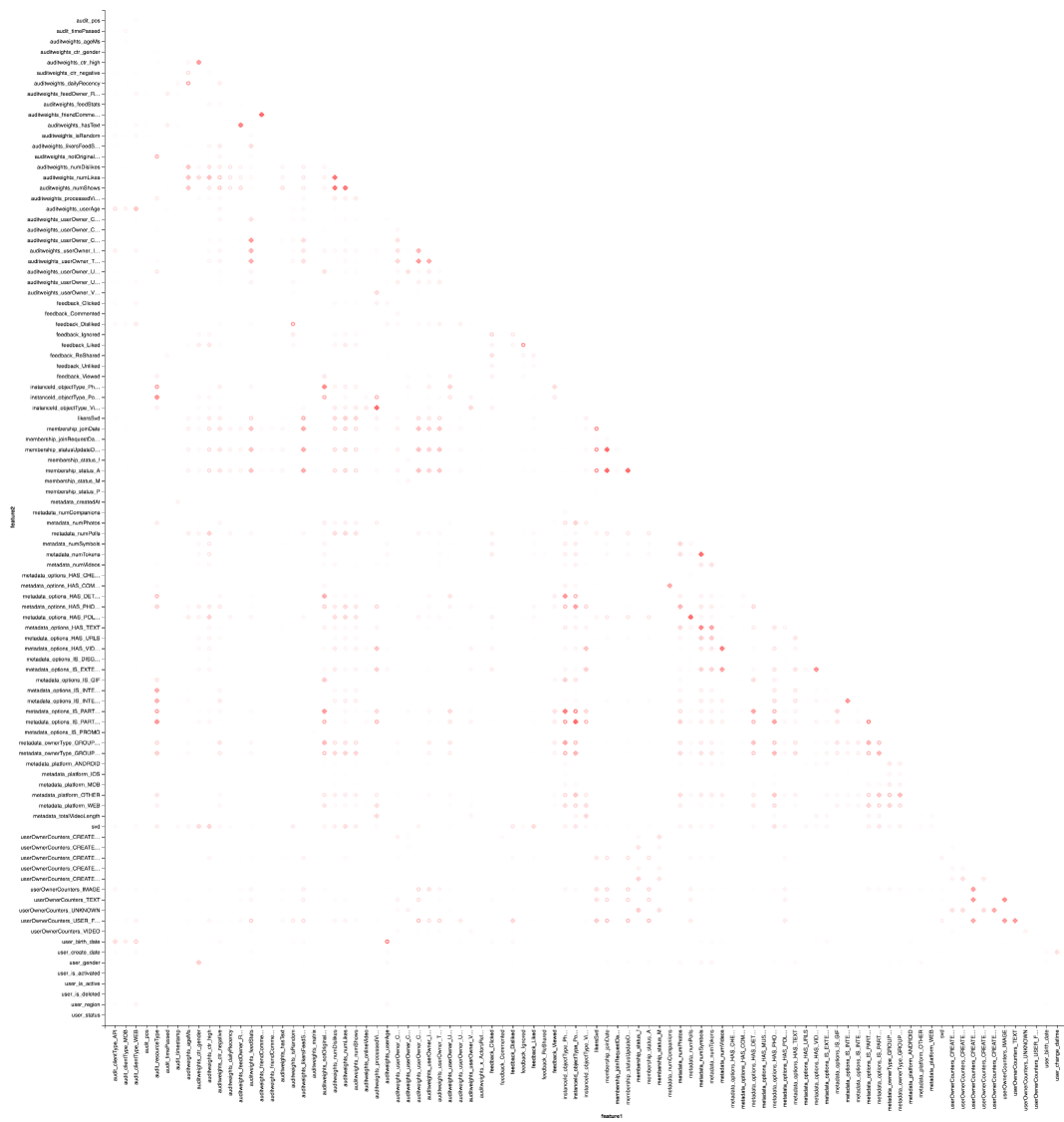
Die Wärmekarte zeigt, dass einige Korrelationen eindeutig vorhanden sind. Versuchen wir, die Blöcke der am stärksten korrelierten Merkmale auszuwählen. Dazu verwenden wir die GraphX- Bibliothek: Wir wandeln die Korrelationsmatrix in ein Diagramm um, filtern die Kanten nach Gewicht. Danach finden wir die verbundenen Komponenten und lassen nur nicht entartete (von mehr als einem Element) übrig. Ein solches Verfahren ähnelt im Wesentlichen der Anwendung des DBSCAN- Algorithmus und ist wie folgt:
Das Ergebnis wird in Form einer Tabelle dargestellt:
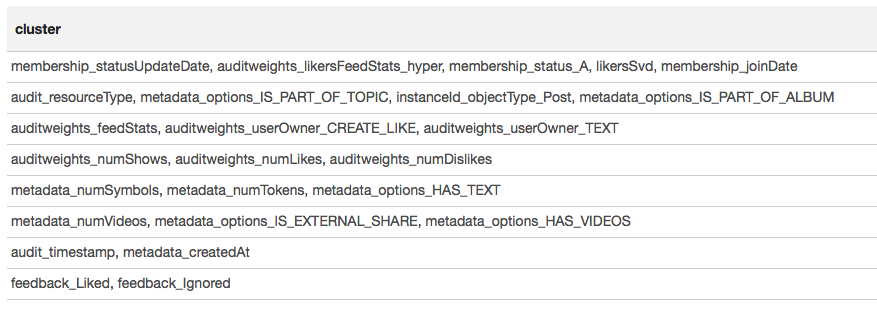
Basierend auf den Ergebnissen des Clusters können wir schließen, dass die am meisten korrelierten Gruppen um Zeichen gebildet werden, die mit der Benutzermitgliedschaft in der Gruppe verbunden sind (Membership_status_A) sowie um den Objekttyp (instanceId_objectType). Für die beste Modellierung der Interaktion von Zeichen ist es sinnvoll, eine Modellsegmentierung anzuwenden, um verschiedene Modelle für verschiedene Objekttypen zu trainieren, getrennt für Gruppen, in denen der Benutzer ist und nicht.
Maschinelles Lernen
Wir nähern uns dem Interessantesten - dem maschinellen Lernen. Die Pipeline zum Trainieren des einfachsten Modells (logistische Regression) unter Verwendung von SparkML- und PravdaML- Erweiterungen lautet wie folgt:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
Hier sehen wir nicht nur viele bekannte Elemente, sondern auch einige neue:
- LogisticRegressionLBFSG ist ein Schätzer mit verteiltem Training der logistischen Regression.
- Um mit verteilten ML-Algorithmen maximale Leistung zu erzielen. Daten sollten optimal auf Partitionen verteilt werden. Das Dienstprogramm UnwrappedStage.repartition hilft dabei, indem es der Pipeline eine Neupartitionsoperation hinzufügt, sodass sie nur in der Schulungsphase verwendet wird (schließlich ist es beim Erstellen von Prognosen nicht mehr erforderlich).
- Damit könnte das lineare Modell ein gutes Ergebnis liefern. Daten müssen skaliert werden, für die das Dienstprogramm Scaler.scale verantwortlich ist. Das Vorhandensein von zwei aufeinanderfolgenden linearen Transformationen (Skalierung und Multiplikation mit den Regressionsgewichten) führt jedoch zu unnötigen Kosten, und es ist wünschenswert, diese Operationen zu reduzieren. Bei Verwendung von PravdaML ist die Ausgabe ein sauberes Modell mit einer Transformation :).
- Natürlich benötigen Sie für solche Modelle ein kostenloses Mitglied, das wir mithilfe der Operation Interceptor.intercept hinzufügen.
Die resultierende Pipeline, die auf alle Daten angewendet wird, ergibt AUC 0,6889 pro Benutzer (Validierungscode ist auf Zepl verfügbar). Jetzt müssen wir alle unsere Forschungen anwenden: Daten filtern, Merkmale transformieren und Segmentmodelle. Die endgültige Pipeline sieht folgendermaßen aus:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
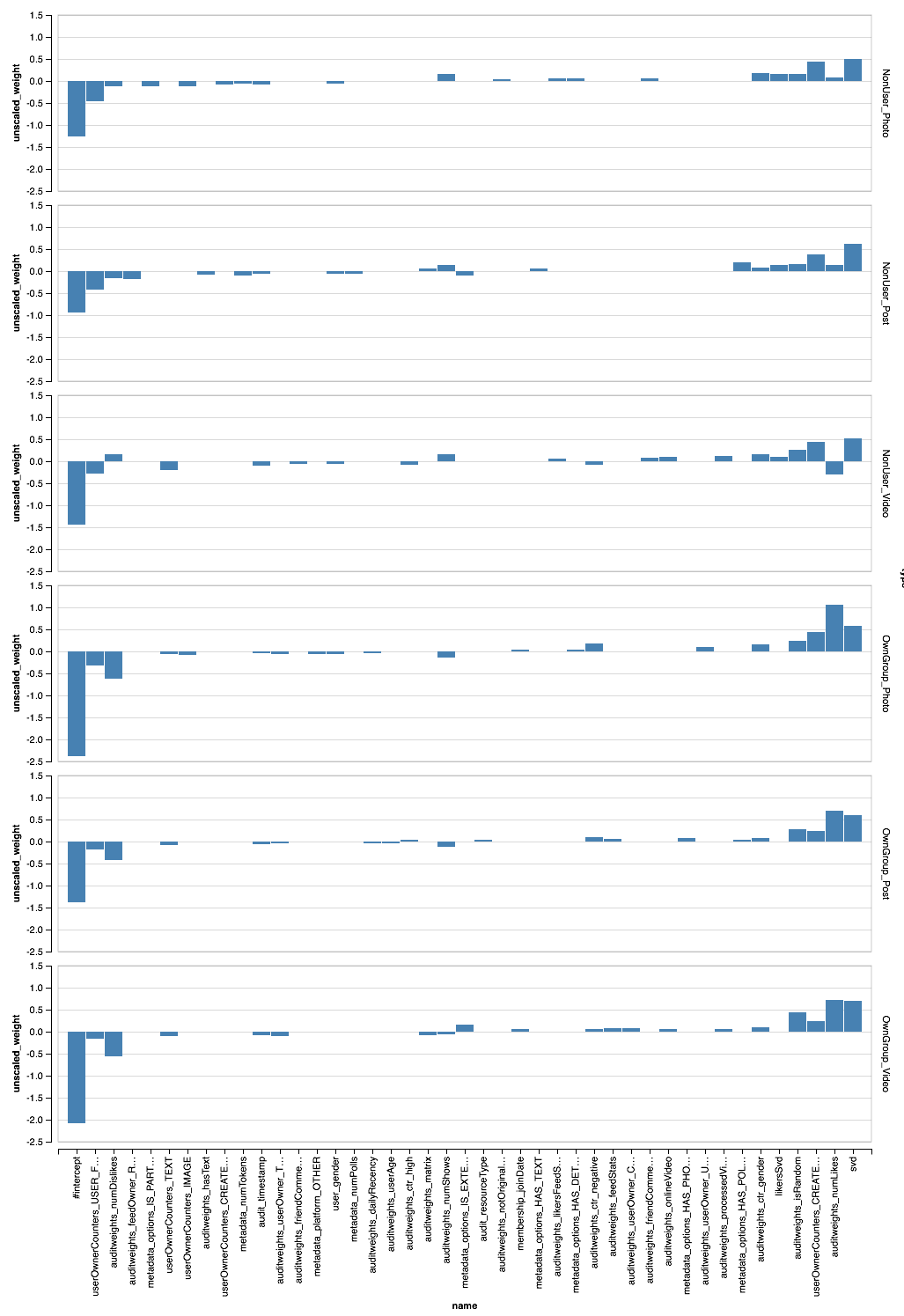
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
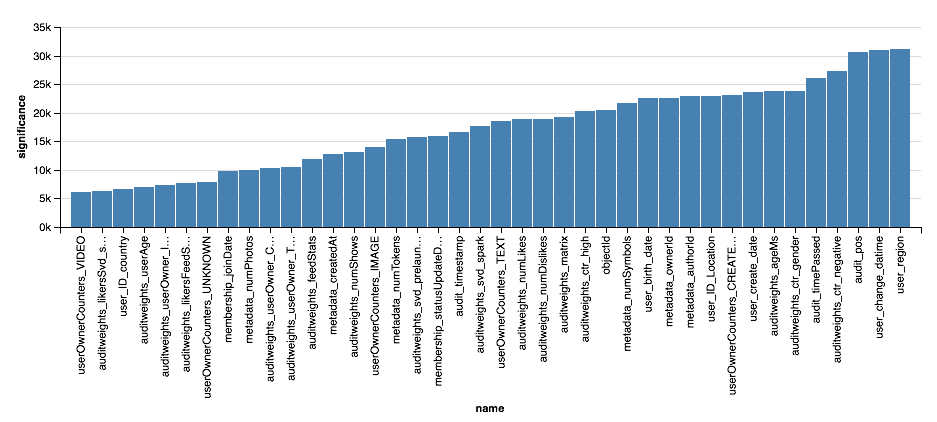
, , XGBoost, , . . , XGBoost , , .
Schlussfolgerungen
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .