
Bei Prozessen, die sich auf die Datenbank beziehen, treten früher oder später Probleme mit der Leistung von Abfragen an diese Datenbank auf.
Das Data Warehouse von Rostelecom basiert auf Greenplum. Die meisten Berechnungen (Transformationen) werden von SQL-Abfragen durchgeführt, die den ETL-Mechanismus starten (oder generieren und starten). DBMS hat seine eigenen Nuancen, die die Leistung erheblich beeinflussen. Dieser Artikel ist ein Versuch, die wichtigsten Aspekte der Arbeit mit Greenplum in Bezug auf Leistung und Erfahrungsaustausch hervorzuheben.
Kurz gesagt über GreenplumGreenplum -
MPP- Datenbankserver, dessen Kern auf PostgreSql basiert.
Repräsentiert verschiedene Instanzen des PostgreSql-Prozesses (Instanzen). Eine davon ist der Einstiegspunkt für den Client und wird als Master-Instanz (Master) bezeichnet. Alle anderen werden als Segment-Instanzen (Segment, unabhängige Instanzen, von denen jede ihre eigenen Daten hat) bezeichnet. Jeder Server (Segmenthost) kann von einem bis zu mehreren Diensten (Segment) ausgeführt werden. Dies geschieht, um Serverressourcen und vor allem Prozessoren besser zu nutzen. Der Assistent speichert Metadaten, ist für die Kommunikation der Clients mit Daten verantwortlich und verteilt die Arbeit auf die Segmente.
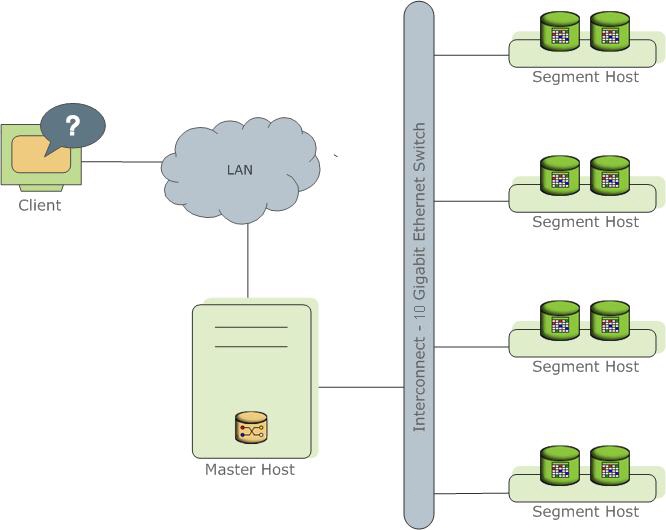
Lesen Sie mehr in der
offiziellen Dokumentation .
Weiter im Artikel wird es viele Verweise auf den Anforderungsplan geben. Informationen zu Greenplum finden Sie
hier .
Wie man gute Anfragen zu Greenplum schreibt (na ja, oder zumindest nicht ganz traurig)
Da es sich um eine verteilte Datenbank handelt, ist es nicht nur wichtig, wie die SQL-Abfrage geschrieben wird, sondern auch, wie die Daten gespeichert werden.
1. Verteilung
Daten werden physisch in verschiedenen Segmenten gespeichert. Sie können Daten zufällig nach Segmenten oder nach dem Wert der Hash-Funktion eines Felds oder einer Reihe von Feldern trennen.
Syntax (beim Erstellen einer Tabelle):
DISTRIBUTED BY (some_field)
Oder so:
DISTRIBUTED RANDOMLY
Das Verteilungsfeld sollte eine gute Selektivität aufweisen und keine Nullwerte (oder ein Minimum solcher Werte) aufweisen, da Datensätze mit solchen Feldern auf ein Segment verteilt werden, was zu Datenverzerrungen führen kann.
Der Feldtyp ist vorzugsweise eine ganze Zahl. Das Feld wird zum Verknüpfen von Tabellen verwendet. Die Hash-Verknüpfung ist eine der besten Möglichkeiten zum Verknüpfen von Tabellen (in Bezug auf die Ausführung von Abfragen). Sie funktioniert am besten mit diesem Datentyp.
Für die Verteilung ist es ratsam, nicht mehr als zwei Felder auszuwählen, und natürlich ist eines besser als zwei. Zusätzliche Felder in Verteilungsschlüsseln erfordern zum einen zusätzliche Zeit für das Hashing und zum anderen (in den meisten Fällen) die Übertragung von Daten zwischen Segmenten, wenn Verknüpfungen ausgeführt werden.
Sie können die Zufallsverteilung verwenden, wenn Sie nicht in der Lage sind, ein oder zwei geeignete Felder sowie kleine Etiketten auszuwählen. Wir müssen jedoch berücksichtigen, dass eine solche Verteilung am besten für das Einfügen von Massendaten und nicht für einen Datensatz geeignet ist. GreenPlum verteilt Daten gemäß dem
zyklischen Algorithmus und startet einen neuen Zyklus für jede Einfügeoperation, beginnend mit dem ersten Segment, was bei häufigen kleinen Einfügungen zu Verzerrungen (Datenversatz) führt.
Mit einem gut ausgewählten Verteilungsfeld werden alle Berechnungen für das Segment durchgeführt, ohne dass Daten an andere Segmente gesendet werden. Für eine optimale Verknüpfung von Tabellen (Verknüpfung) sollten sich dieselben Werte im selben Segment befinden.
Verteilung in BildernGuter Verteilungsschlüssel: Schlechter Verteilungsschlüssel:
Schlechter Verteilungsschlüssel: Zufällige Verteilung:
Zufällige Verteilung:
Die Art der im Join verwendeten Felder muss in allen Tabellen gleich sein.
Wichtig: Verwenden Sie nicht als Verteilungsfelder diejenigen, die zum Filtern von Abfragen verwendet werden, da in diesem Fall die Last während der Abfrage auch nicht gleichmäßig verteilt wird.
2. Partitionierung
Durch die Partitionierung können Sie große Tabellen, z. B.
Fakten , in logisch getrennte Teile unterteilen. Greenplum unterteilt Ihre Tabelle physisch in separate Tabellen, von denen jede basierend auf den Einstellungen ab S. 1 in Segmente unterteilt ist.
Tabellen sollten logisch in Abschnitte unterteilt werden. Wählen Sie zu diesem Zweck das Feld aus, das häufig im where-Block verwendet wird. In der Tat Tabellen wird dies der Zeitraum sein. Bei ordnungsgemäßem Zugriff auf die Tabelle in Abfragen arbeiten Sie daher nur mit einem Teil der gesamten großen Tabelle.
Im Allgemeinen ist die Partitionierung ein ziemlich bekanntes Thema, und ich wollte betonen, dass Sie nicht dasselbe Feld für die Partitionierung und Verteilung auswählen sollten. Dies führt dazu, dass die Anforderung vollständig in einem Segment ausgeführt wird.
Es ist Zeit, tatsächlich zu den Anfragen zu gehen. Die Anforderung wird für Segmente gemäß einem bestimmten
Plan ausgeführt :
3. Der Optimierer
Greenplum verfügt über zwei Optimierer, den integrierten Legacy-Optimierer und den Orca-Optimierer von Drittanbietern: GPORCA - Orca - Pivotal Query Optimizer.
Aktivieren Sie GPORCA auf Anfrage:
set optimizer = on;
In der Regel ist der GPORCA-Optimierer besser als der eingebaute. Es funktioniert besser mit Unterabfragen und
CTE (mehr Details
hier ).
Aufruf einer großen Tabelle in CTE mit maximaler Datenfilterung (Partitionsbereinigung nicht vergessen) und einer explizit angegebenen Liste von Feldern - dies funktioniert sehr gut.
Der Abfrageplan wird beispielsweise geringfügig geändert, andernfalls werden die gescannten Partitionen angezeigt:
Standardoptimierer: Orca:
Orca:
GPORCA ermöglicht auch das Aktualisieren von Partitions- / Verteilungsfeldern. Es gibt zwar Situationen, in denen der integrierte Optimierer eine bessere Leistung erbringt. Ein Optimierer von Drittanbietern stellt hohe Anforderungen an die Statistik. Es ist wichtig, die
Analyse nicht zu vergessen.
Egal wie gut der Optimierer ist, eine schlecht geschriebene Abfrage wird Orca nicht einmal dehnen:
4. Manipulationen mit Feldern in den Where-Block- oder Join-Bedingungen
Es ist wichtig zu beachten, dass die auf das Filterfeld angewendete Funktion oder die Bedingungen des Joins auf
jeden Datensatz angewendet
werden .
Im Fall des Partitionierungsfelds (z. B. date_trunc zum Partitionierungsfeld - date) kann selbst GPORCA in diesem Fall nicht korrekt funktionieren. Das
Abschneiden von Partitionen funktioniert nicht.
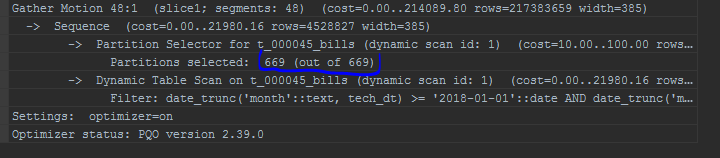
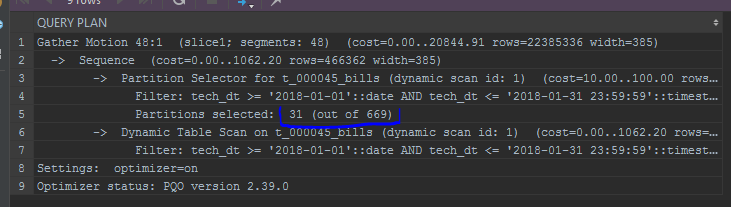 Ich mache auch auf die Anzeige von Partitionen aufmerksam. Das integrierte Optimierungsprogramm zeigt Partitionen in einer Liste an:
Ich mache auch auf die Anzeige von Partitionen aufmerksam. Das integrierte Optimierungsprogramm zeigt Partitionen in einer Liste an:
Wenden Sie Funktionen sorgfältig auf Konstanten in denselben Partitionsfiltern an. Ein Beispiel ist das gleiche date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

GPORCA wird mit einer solchen Finte vollständig fertig und funktioniert korrekt, der Standardoptimierer wird nicht mehr damit fertig. Durch eine explizite Typkonvertierung können Sie jedoch Folgendes erreichen:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

Und wenn alles falsch gemacht wird?
5. Anträge
Eine andere Art von Operation, die im
Abfrageplan beobachtet werden kann, sind Bewegungen. So markierte Datenbewegungen zwischen Segmenten:
- Bewegung sammeln - wird in fast jedem Plan angezeigt. Dies bedeutet, dass die Ergebnisse der Abfrageausführung aus allen Segmenten in einem Stream zusammengefasst werden (normalerweise an den Master).
Zwei Tabellen, die auf einen Schlüssel verteilt sind und für den Join verwendet werden, führen alle Operationen an Segmenten aus, ohne Daten zu verschieben. Andernfalls tritt eine Broadcast- oder Umverteilungsbewegung auf: - Broadcast-Bewegung - Jedes Segment sendet seine Kopie der Daten an andere Segmente. Im Idealfall erfolgt Broadcast nur für kleine Tabellen.
- Umverteilungsbewegung - Um große Tabellen zu verbinden, die auf verschiedene Schlüssel verteilt sind, wird eine Umverteilung durchgeführt, um Verbindungen lokal herzustellen. Bei großen Tischen kann dies eine ziemlich teure Operation sein.
Broadcast und Redistribution sind recht nachteilige Vorgänge. Sie werden jedes Mal ausgeführt, wenn die Anforderung ausgeführt wird. Es wird empfohlen, sie zu vermeiden. Nachdem Sie solche Punkte im Abfrageplan gesehen haben, sollten Sie auf die Verteilungsschlüssel achten. Unterschiedliche und gewerkschaftliche Operationen verursachen ebenfalls Bewegungen.
Diese Liste erhebt keinen Anspruch auf Vollständigkeit und basiert hauptsächlich auf den Erfahrungen des Autors. Es hat nicht funktioniert, alles sofort im Internet zu finden. Hier habe ich versucht, die kritischsten Faktoren zu identifizieren, die die Leistung der Anforderung beeinflussen, und zu verstehen, warum und warum dies geschieht.
Dieser Artikel wurde vom Datenverwaltungsteam von Rostelecom erstellt