Der erste Artikel beschrieb die
PostgreSQL-Indizierungs-Engine , der zweite befasste sich mit
der Schnittstelle von Zugriffsmethoden , und jetzt sind wir bereit, bestimmte Arten von Indizes zu diskutieren. Beginnen wir mit dem Hash-Index.
Hash
Struktur
Allgemeine Theorie
Viele moderne Programmiersprachen enthalten Hash-Tabellen als Basisdatentyp. Äußerlich sieht eine Hash-Tabelle wie ein reguläres Array aus, das mit einem beliebigen Datentyp (z. B. einer Zeichenfolge) und nicht mit einer Ganzzahl indiziert ist. Der Hash-Index in PostgreSQL ist ähnlich aufgebaut. Wie funktioniert das?
Datentypen haben in der Regel sehr große Bereiche zulässiger Werte: Wie viele verschiedene Zeichenfolgen können wir uns möglicherweise in einer Spalte vom Typ "Text" vorstellen? Wie viele verschiedene Werte werden gleichzeitig in einer Textspalte einer Tabelle gespeichert? Normalerweise nicht so viele von ihnen.
Die Idee des Hashings besteht darin, einem Wert eines beliebigen Datentyps eine kleine Zahl (von 0 bis
N −1, insgesamt
N Werte) zuzuordnen.
Eine solche Assoziation wird als
Hash-Funktion bezeichnet . Die erhaltene Nummer kann als Index eines regulären Arrays verwendet werden, in dem Verweise auf Tabellenzeilen (TIDs) gespeichert werden. Elemente dieses Arrays werden als
Hash-Tabellen-Buckets bezeichnet. Ein Bucket kann mehrere TIDs speichern, wenn derselbe indizierte Wert in verschiedenen Zeilen angezeigt wird.
Je gleichmäßiger eine Hash-Funktion die Quellwerte nach Buckets verteilt, desto besser ist sie. Aber selbst eine gute Hash-Funktion führt manchmal zu gleichen Ergebnissen für verschiedene Quellwerte - dies wird als
Kollision bezeichnet . Ein Bucket kann also TIDs speichern, die verschiedenen Schlüsseln entsprechen, und daher müssen die aus dem Index erhaltenen TIDs erneut überprüft werden.
Nur zum Beispiel: Welche Hash-Funktion für Strings können wir uns vorstellen? Die Anzahl der Buckets sei 256. Dann können wir beispielsweise für eine Bucket-Nummer den Code des ersten Zeichens verwenden (unter der Annahme einer Einzelbyte-Zeichencodierung). Ist das eine gute Hash-Funktion? Offensichtlich nicht: Wenn alle Zeichenfolgen mit demselben Zeichen beginnen, werden alle in einen Bucket verschoben, sodass die Einheitlichkeit nicht in Frage kommt, alle Werte erneut überprüft werden müssen und Hashing keinen Sinn ergibt. Was ist, wenn wir Codes aller Zeichen Modulo 256 zusammenfassen? Dies wird viel besser sein, aber alles andere als ideal. Wenn Sie an den Interna einer solchen Hash-Funktion in PostgreSQL interessiert sind, lesen Sie die Definition von hash_any () in
hashfunc.c .
Indexstruktur
Kehren wir zum Hash-Index zurück. Für einen Wert eines Datentyps (einen Indexschlüssel) besteht unsere Aufgabe darin, schnell die passende TID zu finden.
Berechnen wir beim Einfügen in den Index die Hash-Funktion für den Schlüssel. Hash-Funktionen in PostgreSQL geben immer den Typ "Integer" zurück, der im Bereich von 2
32 ≈ 4 Milliarden Werten liegt. Die Anzahl der Buckets beträgt anfangs zwei und nimmt dynamisch zu, um sich an die Datengröße anzupassen. Die Bucket-Nummer kann aus dem Hash-Code unter Verwendung der Bit-Arithmetik berechnet werden. Und dies ist der Eimer, in den wir unsere TID stellen werden.
Dies ist jedoch nicht ausreichend, da TIDs, die mit verschiedenen Schlüsseln übereinstimmen, in denselben Bucket gestellt werden können. Was sollen wir tun? Es ist möglich, den Quellwert des Schlüssels zusätzlich zur TID in einem Bucket zu speichern, dies würde jedoch die Indexgröße erheblich erhöhen. Um Platz zu sparen, speichert der Bucket anstelle eines Schlüssels den Hash-Code des Schlüssels.
Beim Durchsuchen des Index berechnen wir die Hash-Funktion für den Schlüssel und erhalten die Bucket-Nummer. Jetzt müssen Sie nur noch den Inhalt des Buckets durchgehen und nur übereinstimmende TIDs mit den entsprechenden Hash-Codes zurückgeben. Dies geschieht effizient, da gespeicherte "Hash-Code-TID" -Paare bestellt werden.
Es kann jedoch vorkommen, dass zwei verschiedene Schlüssel nicht nur in einen Bucket gelangen, sondern auch dieselben 4-Byte-Hash-Codes haben - niemand hat die Kollision beseitigt. Daher fordert die Zugriffsmethode die allgemeine Indizierungs-Engine auf, jede TID zu überprüfen, indem sie die Bedingung in der Tabellenzeile erneut überprüft (die Engine kann dies zusammen mit der Sichtbarkeitsprüfung tun).
Zuordnen von Datenstrukturen zu Seiten
Wenn wir einen Index aus Sicht des Puffer-Cache-Managers und nicht aus Sicht der Abfrageplanung und -ausführung betrachten, stellt sich heraus, dass alle Informationen und alle Indexzeilen in Seiten gepackt werden müssen. Solche Indexseiten werden im Puffercache gespeichert und von dort genauso wie Tabellenseiten entfernt.
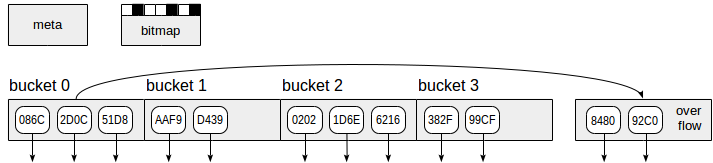
Der Hash-Index verwendet, wie in der Abbildung gezeigt, vier Arten von Seiten (graue Rechtecke):
- Metaseite - Seitenzahl Null, die Informationen darüber enthält, was sich im Index befindet.
- Bucket-Seiten - Hauptseiten des Index, auf denen Daten als "Hash-Code-TID" -Paare gespeichert sind.
- Überlaufseiten - werden wie Bucket-Seiten strukturiert und verwendet, wenn eine Seite für einen Bucket nicht ausreicht.
- Bitmap-Seiten - Verfolgen von Überlaufseiten, die derzeit gelöscht sind und für andere Buckets wiederverwendet werden können.
Abwärtspfeile, die bei Indexseitenelementen beginnen, repräsentieren TIDs, dh Verweise auf Tabellenzeilen.
Jedes Mal, wenn der Index erhöht wird, erstellt PostgreSQL sofort doppelt so viele Buckets (und damit Seiten) wie zuletzt erstellt. Um zu vermeiden, dass diese potenziell große Anzahl von Seiten gleichzeitig zugewiesen wird, wurde die Größe in Version 10 reibungsloser erhöht. Überlaufseiten werden nach Bedarf zugewiesen und in Bitmap-Seiten nachverfolgt, die bei Bedarf ebenfalls zugewiesen werden.
Beachten Sie, dass der Hash-Index nicht kleiner werden kann. Wenn wir einige indizierte Zeilen löschen, werden einmal zugewiesene Seiten nicht an das Betriebssystem zurückgegeben, sondern erst nach VACUUMING für neue Daten wiederverwendet. Die einzige Möglichkeit, die Indexgröße zu verringern, besteht darin, sie mit dem Befehl REINDEX oder VACUUM FULL von Grund auf neu zu erstellen.
Beispiel
Mal sehen, wie der Hash-Index erstellt wird. Um zu vermeiden, dass wir unsere eigenen Tabellen erstellen, werden wir von nun an
die Demo-Datenbank des Luftverkehrs verwenden und diesmal die Flugtabelle berücksichtigen.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN ---------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (flight_no = 'PG0001'::bpchar) -> Bitmap Index Scan on flights_flight_no_idx Index Cond: (flight_no = 'PG0001'::bpchar) (4 rows)
Was bei der aktuellen Implementierung des Hash-Index unpraktisch ist, ist, dass Operationen mit dem Index nicht im Write-Ahead-Protokoll aufgezeichnet werden (vor dem PostgreSQL beim Erstellen des Index warnt). Infolgedessen können Hash-Indizes nach einem Fehler nicht wiederhergestellt werden und nehmen nicht an Replikationen teil. Außerdem liegt der Hash-Index in seiner Vielseitigkeit weit unter "B-Tree", und seine Effizienz ist ebenfalls fraglich. Daher ist es jetzt unpraktisch, solche Indizes zu verwenden.
Dies wird sich jedoch bereits im Herbst (2017) ändern, sobald Version 10 von PostgreSQL veröffentlicht wird. In dieser Version erhielt der Hash-Index endlich Unterstützung für das Write-Ahead-Protokoll. Zusätzlich wurde die Speicherzuordnung optimiert und die gleichzeitige Arbeit effizienter gestaltet.
Das stimmt. Seit PostgreSQL 10 haben Hash-Indizes volle Unterstützung und können ohne Einschränkungen verwendet werden. Die Warnung wird nicht mehr angezeigt.
Hashing-Semantik
Aber warum hat der Hash-Index fast von der Geburt von PostgreSQL bis 9.6 überlebt und war unbrauchbar? Die Sache ist, dass DBMS den Hashing-Algorithmus in großem Umfang verwendet (insbesondere für Hash-Joins und -Gruppierungen), und das System muss wissen, welche Hash-Funktion auf welche Datentypen angewendet werden soll. Diese Entsprechung ist jedoch nicht statisch und kann nicht ein für allemal festgelegt werden, da mit PostgreSQL neue Datentypen im laufenden Betrieb hinzugefügt werden können. Und dies ist eine Zugriffsmethode durch Hash, bei der diese Korrespondenz gespeichert wird, dargestellt als Zuordnung von Hilfsfunktionen zu Operatorfamilien.
demo=# select opf.opfname as opfamily_name, amproc.amproc::regproc AS opfamily_procedure from pg_am am, pg_opfamily opf, pg_amproc amproc where opf.opfmethod = am.oid and amproc.amprocfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_procedure;
opfamily_name | opfamily_procedure --------------------+-------------------- abstime_ops | hashint4 aclitem_ops | hash_aclitem array_ops | hash_array bool_ops | hashchar ...
Obwohl diese Funktionen nicht dokumentiert sind, können sie verwendet werden, um den Hash-Code für einen Wert des entsprechenden Datentyps zu berechnen. Beispiel: "Hashtext" -Funktion, wenn sie für die Operatorfamilie "text_ops" verwendet wird:
demo=# select hashtext('one');
hashtext ----------- 127722028 (1 row)
demo=# select hashtext('two');
hashtext ----------- 345620034 (1 row)
Eigenschaften
Schauen wir uns die Eigenschaften des Hash-Index an, bei denen diese Zugriffsmethode dem System Informationen über sich selbst liefert. Wir haben beim
letzten Mal Fragen gestellt. Jetzt gehen wir nicht über die Ergebnisse hinaus:
name | pg_indexam_has_property ---------------+------------------------- can_order | f can_unique | f can_multi_col | f can_exclude | t name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | t name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Eine Hash-Funktion behält die Ordnungsbeziehung nicht bei: Wenn der Wert einer Hash-Funktion für einen Schlüssel kleiner als für den anderen Schlüssel ist, kann keine Schlussfolgerung gezogen werden, wie die Schlüssel selbst geordnet sind. Daher kann der Hash-Index im Allgemeinen die einzige Operation "gleich" unterstützen:
demo=# select opf.opfname AS opfamily_name, amop.amopopr::regoperator AS opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_operator;
opfamily_name | opfamily_operator ---------------+---------------------- abstime_ops | =(abstime,abstime) aclitem_ops | =(aclitem,aclitem) array_ops | =(anyarray,anyarray) bool_ops | =(boolean,boolean) ...
Folglich kann der Hash-Index keine geordneten Daten zurückgeben ("can_order", "orderable"). Der Hash-Index manipuliert NULL-Werte aus demselben Grund nicht: Die Operation "equals" ist für NULL ("search_nulls") nicht sinnvoll.
Da der Hash-Index keine Schlüssel (sondern nur deren Hash-Codes) speichert, kann er nicht für den reinen Indexzugriff verwendet werden ("returnable").
Diese Zugriffsmethode unterstützt auch keine mehrspaltigen Indizes ("can_multi_col").
Interna
Ab Version 10 können über die Erweiterung "
pageinspect " Hash-Index-Interna
untersucht werden . So wird es aussehen:
demo=# create extension pageinspect;
Die Metaseite (wir erhalten die Anzahl der Zeilen im Index und die maximal verwendete Bucket-Nummer):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type ---------------- metapage (1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket ---------+----------- 33121 | 127 (1 row)
Eine Bucket-Seite (wir erhalten die Anzahl der lebenden und toten Tupel, dh derjenigen, die gesaugt werden können):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type ---------------- bucket (1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items ------------+------------ 407 | 0 (1 row)
Und so weiter. Es ist jedoch kaum möglich, die Bedeutung aller verfügbaren Felder herauszufinden, ohne den Quellcode zu untersuchen. Wenn Sie dies wünschen, sollten Sie mit
README beginnen .
Lesen Sie weiter .