Hallo, mein Name ist Vladislav und ich bin Mitglied des
Tarantool- Entwicklungsteams. Tarantool ist ein DBMS und ein Anwendungsserver in einem. Heute werde ich die Geschichte erzählen, wie wir die horizontale Skalierung in Tarantool mithilfe des
VShard- Moduls
implementiert haben .
Einige Grundkenntnisse zuerst.
Es gibt zwei Arten der Skalierung: horizontal und vertikal. Es gibt zwei Arten der horizontalen Skalierung: Replikation und Sharding. Die Replikation stellt die rechnerische Skalierung sicher, während das Sharding für die Datenskalierung verwendet wird.
Sharding wird ebenfalls in zwei Typen unterteilt: Range-basiertes Sharding und Hash-basiertes Sharding.
Bereichsbasiertes Sharding impliziert, dass für jeden Clusterdatensatz ein Shard-Schlüssel berechnet wird. Die Shard-Schlüssel werden auf eine gerade Linie projiziert, die in Bereiche unterteilt und verschiedenen physischen Knoten zugeordnet ist.
Hash-basiertes Sharding ist weniger kompliziert: Für jeden Datensatz in einem Cluster wird eine Hash-Funktion berechnet. Datensätze mit derselben Hash-Funktion werden demselben physischen Knoten zugewiesen.
Ich werde mich auf die horizontale Skalierung mit Hash-basiertem Sharding konzentrieren.
Ältere Implementierung
Tarantool Shard war unser ursprüngliches Modul für die horizontale Skalierung. Es wurden einfaches Hash-basiertes Sharding und berechnete Shard-Schlüssel nach Primärschlüssel für alle Datensätze in einem Cluster verwendet.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Aber schließlich wurde Tarantool Shard nicht mehr in der Lage, neue Aufgaben zu bewältigen.
Erstens wurde eine unserer möglichen Anforderungen die garantierte
Lokalität logisch zusammengehöriger Daten . Mit anderen Worten, wenn wir logisch zusammenhängende Daten haben, möchten wir diese immer auf einem einzelnen physischen Knoten speichern, unabhängig von der Clustertopologie und dem Ausgleich von Änderungen. Tarantool Shard kann dies nicht garantieren. Es wurden Hashes nur mit Primärschlüsseln berechnet, sodass ein erneutes Ausgleichen die vorübergehende Trennung von Datensätzen mit demselben Hash verursachen kann, da die Änderungen nicht atomar ausgeführt werden.
Dieser Mangel an Datenlokalität war das Hauptproblem für uns. Hier ist ein Beispiel. Angenommen, es gibt eine Bank, bei der ein Kunde ein Konto eröffnet hat. Die Informationen über das Konto und den Kunden sollten physisch zusammen gespeichert werden, damit sie in einer einzelnen Anfrage abgerufen oder in einer einzelnen Transaktion geändert werden können, z. B. während einer Geldüberweisung. Wenn wir das traditionelle Sharding von Tarantool Shard verwenden, gibt es unterschiedliche Hash-Funktionswerte für Konten und Kunden. Die Daten könnten auf separaten physischen Knoten landen. Dies erschwert das Lesen und die Abwicklung von Kundendaten erheblich.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
Im obigen Beispiel können die ID-Felder der Konten und des Kunden inkonsistent sein. Sie sind durch das Feld customer_id des Kontos und das Feld id des Kunden verbunden. Das gleiche ID-Feld würde die Eindeutigkeitsbeschränkung des Konto-Primärschlüssels verletzen. Und Shard kann kein Sharding auf andere Weise durchführen.
Ein weiteres Problem war das
langsame Resharding , das das grundlegende Problem aller Hash-Shards ist. Unter dem Strich ändert sich beim Ändern von Clusterkomponenten die Shard-Funktion, da sie normalerweise von der Anzahl der Knoten abhängt. Wenn sich die Funktion ändert, müssen alle Datensätze im Cluster durchsucht und die Funktion neu berechnet werden. Es kann auch erforderlich sein, einige Datensätze zu übertragen. Und während der Datenübertragung wissen wir nicht einmal, ob der erforderliche Datensatz? In der Anfrage wurden bereits Daten übertragen oder werden gerade übertragen. Während des Resharding ist es daher erforderlich, Leseanforderungen sowohl mit alten als auch mit neuen Shard-Funktionen zu stellen. Anfragen werden zweimal langsamer bearbeitet, was nicht akzeptabel ist.
Ein weiteres Problem mit Tarantool Shard war die geringe Verfügbarkeit von Lesevorgängen bei einem Knotenausfall in einem Replikatsatz.
Neue Lösung
Wir haben
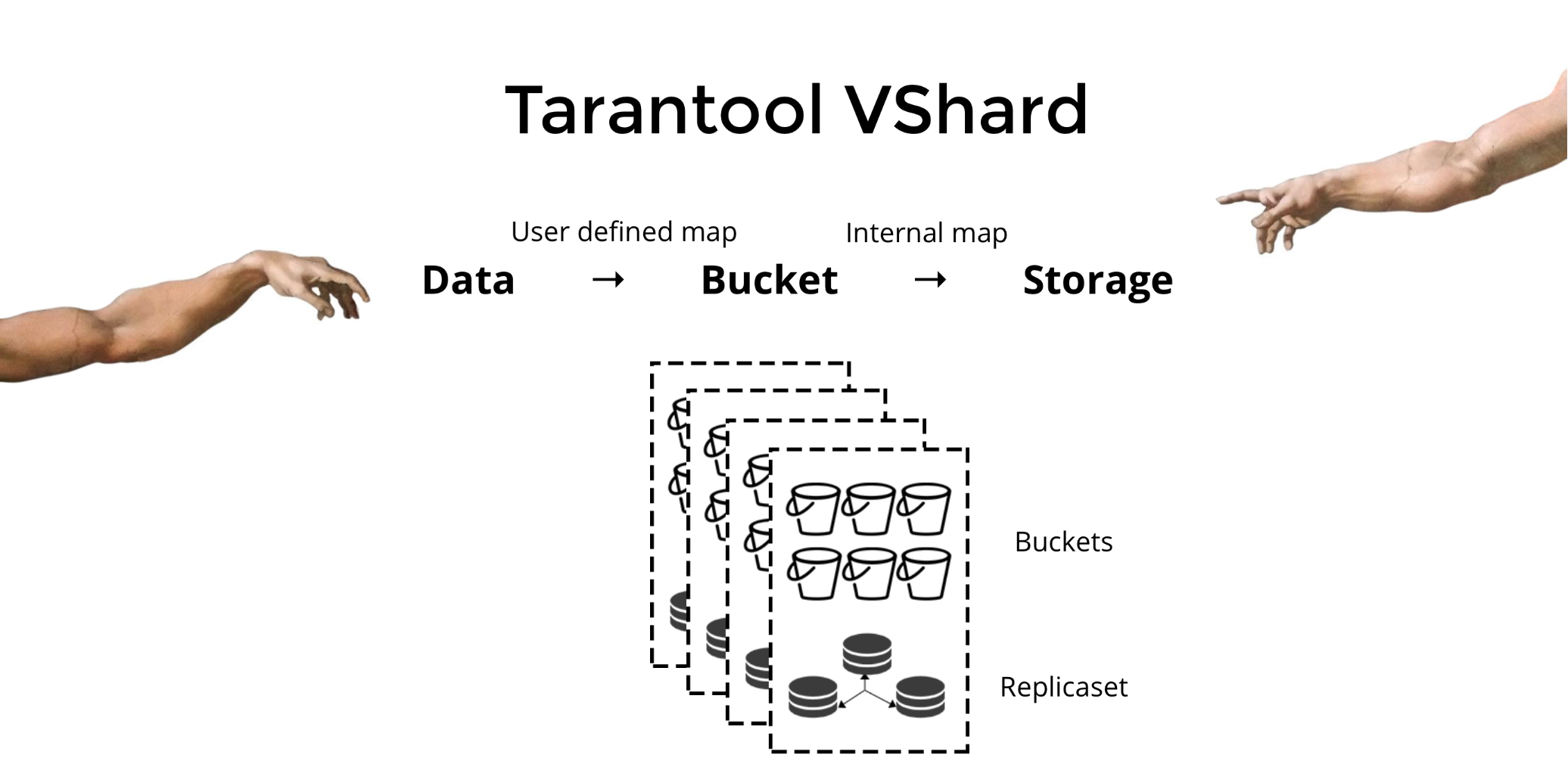
Tarantool VShard entwickelt , um die drei oben genannten Probleme zu lösen. Der Hauptunterschied besteht darin, dass seine Datenspeicherebene virtualisiert ist, d. H. In physischen Speichern werden virtuelle Speicher gehostet, und Datensätze werden den virtuellen Speichern zugewiesen. Diese Speicher werden
Eimer genannt . Der Benutzer muss sich keine Gedanken darüber machen, was sich auf einem bestimmten physischen Knoten befindet. Ein Bucket ist eine atomare unteilbare Dateneinheit, wie ein Tupel beim herkömmlichen Sharding. VShard speichert immer einen gesamten Bucket auf einem physischen Knoten und migriert während des Resharding alle Daten atomar von einem Bucket. Diese Methode stellt die Datenlokalität sicher. Wir legen die Daten einfach in einen Bucket und können immer sicher sein, dass sie bei Clusterwechseln nicht getrennt werden.

Wie packen wir Daten in einen Bucket? Fügen wir der Tabelle für unseren Bankkunden ein neues Bucket-ID-Feld hinzu. Wenn dieser Feldwert für verwandte Daten identisch ist, befinden sich alle Datensätze in einem Bucket. Der Vorteil ist, dass wir Datensätze mit derselben Bucket-ID in verschiedenen Räumen und sogar in verschiedenen Engines speichern können. Die Datenlokalität basierend auf der Bucket-ID ist unabhängig von der Speichermethode garantiert.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Warum ist das so wichtig? Bei Verwendung von herkömmlichem Sharding würden sich die Daten auf verschiedene vorhandene physische Speicher erstrecken. In unserem Bankbeispiel müssten wir jeden Knoten kontaktieren, wenn wir alle Konten für einen bestimmten Kunden anfordern. Wir erhalten also eine Lesekomplexität O (N), wobei N die Anzahl der physischen Speicher ist. Es ist unglaublich langsam.
Durch die Verwendung von Buckets und der Lokalität nach Bucket-ID können die erforderlichen Daten von einem Knoten mit einer Anforderung gelesen werden - unabhängig von der Clustergröße.

In VShard berechnen Sie Ihre Bucket-ID und weisen sie zu. Für einige Menschen ist dies ein Vorteil, während andere dies als Nachteil betrachten. Ich glaube, dass die Möglichkeit, Ihre eigene Funktion für die Bucket-ID-Berechnung auszuwählen, von Vorteil ist.
Was ist der Hauptunterschied zwischen herkömmlichem Sharding und virtuellem Sharding mit Eimern?
Im ersteren Fall haben wir beim Ändern von Clusterkomponenten zwei Zustände: den aktuellen (alten) und den neuen, der implementiert werden soll. Während des Übergangsprozesses müssen nicht nur Daten migriert, sondern auch die Hash-Funktion für jeden Datensatz neu berechnet werden. Dies ist nicht sehr praktisch, da wir zu einem bestimmten Zeitpunkt nicht wissen, ob die erforderlichen Daten bereits migriert wurden oder nicht. Darüber hinaus ist diese Methode nicht zuverlässig und die Änderungen sind nicht atomar, da die atomare Migration des Datensatzes mit demselben Hash-Funktionswert eine dauerhafte Speicherung des Migrationsstatus erfordern würde, falls eine Wiederherstellung erforderlich ist. Infolgedessen gibt es Konflikte und Fehler, und der Vorgang muss mehrmals neu gestartet werden.
Virtuelles Sharding ist viel einfacher. Wir haben keine zwei verschiedenen Clusterzustände. Wir haben nur Bucket State. Der Cluster ist flexibler und wechselt reibungslos von einem Status in einen anderen. Es gibt jetzt mehr als zwei Staaten? (unklar). Mit dem reibungslosen Übergang ist es möglich, das Auswuchten im laufenden Betrieb zu ändern oder neu hinzugefügte Speicher zu entfernen. Das heißt, die Auswuchtkontrolle hat stark zugenommen und ist granularer geworden.
Verwendung
Angenommen, wir haben eine Funktion für unsere Bucket-ID ausgewählt und so viele Daten in den Cluster hochgeladen, dass kein Speicherplatz mehr vorhanden ist. Jetzt möchten wir einige Knoten hinzufügen und Daten automatisch auf diese verschieben. So machen wir es in VShard: Zuerst starten wir neue Knoten und führen dort Tarantool aus, dann aktualisieren wir unsere VShard-Konfiguration. Es enthält Informationen zu jeder Clusterkomponente, jedem Replikat, Replikatsätzen, Mastern, zugewiesenen URIs und vielem mehr. Jetzt fügen wir unsere neuen Knoten zur Konfigurationsdatei hinzu und wenden sie mit VShard.storage.cfg auf alle Clusterknoten an.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Wie Sie sich vielleicht erinnern, ändert sich beim Ändern der Anzahl der Knoten beim herkömmlichen Sharding auch die Shard-Funktion selbst. Dies ist in VShard nicht der Fall. Hier haben wir eine feste Anzahl von virtuellen Speichern oder Eimern. Dies ist eine Konstante, die Sie beim Starten des Clusters auswählen. Es mag den Anschein haben, dass die Skalierbarkeit eingeschränkt ist, aber das ist es wirklich nicht. Sie können eine große Anzahl von Eimern angeben, Zehntausende und Hunderttausende. Es ist wichtig zu wissen, dass mindestens zwei Größenordnungen mehr Buckets vorhanden sein sollten als die maximale Anzahl von Replikatsätzen, die Sie jemals im Cluster haben werden.
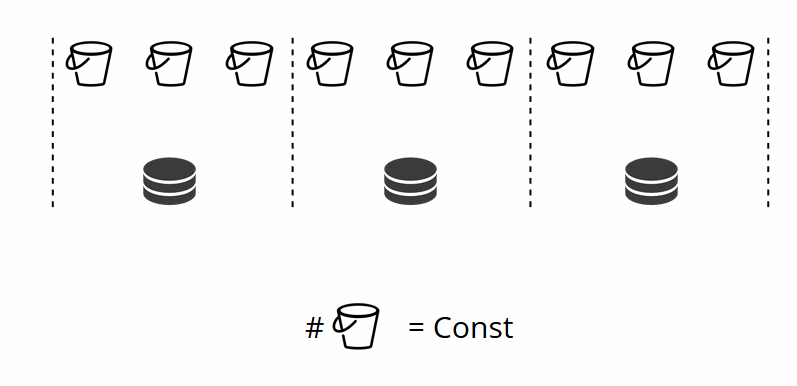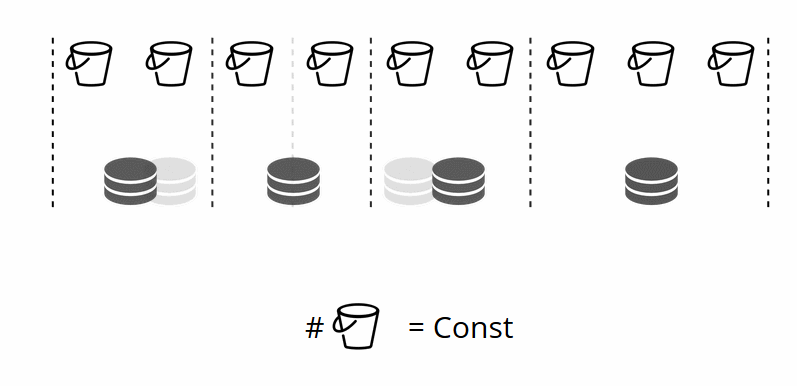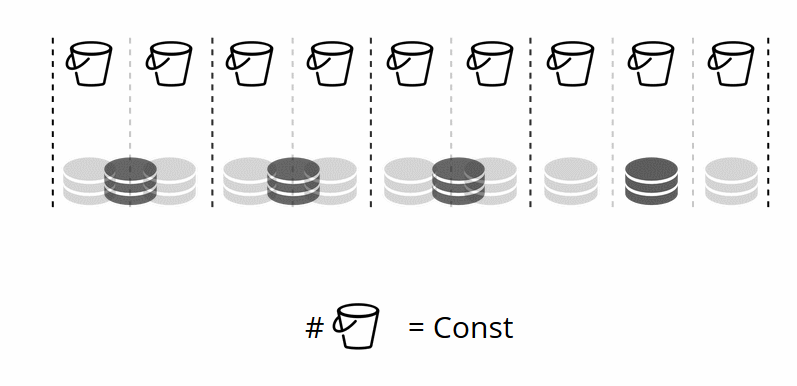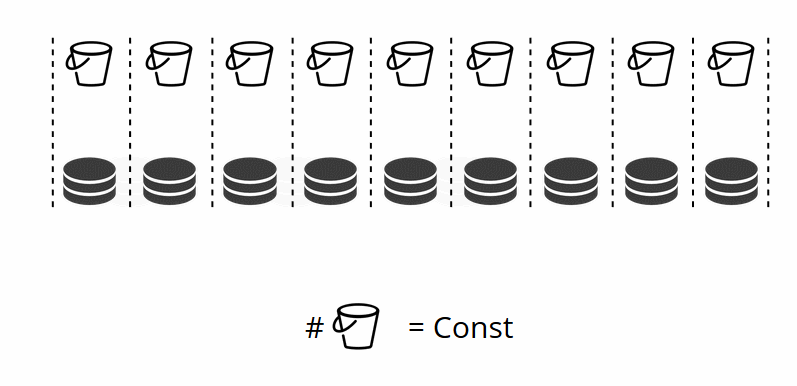
Da sich die Anzahl der virtuellen Speicher nicht ändert und die Shard-Funktion nur von diesem Wert abhängt, können wir so viele physische Speicher hinzufügen, wie wir möchten, ohne die Shard-Funktion neu zu berechnen.
Wie sind die Eimer den physischen Lagern zugeordnet? Wenn VShard.storage.cfg aufgerufen wird, wird ein Neuausgleichsprozess auf einem der Knoten aktiviert. Dies ist ein Analyseprozess, der das perfekte Gleichgewicht für den Cluster berechnet. Der Prozess geht zu jedem physischen Knoten und ruft seine Anzahl von Buckets ab und erstellt dann Routen ihrer Bewegungen, um die Zuordnung auszugleichen. Dann sendet der Rebalancer die Routen an die überlasteten Speicher, die wiederum Eimer senden. Etwas später ist der Cluster ausgeglichen.
In realen Projekten ist ein perfektes Gleichgewicht möglicherweise nicht so einfach zu erreichen. Beispielsweise könnte ein Replikatsatz weniger Daten enthalten als der andere, da er weniger Speicherkapazität hat. In diesem Fall könnte VShard denken, dass alles ausgeglichen ist, aber tatsächlich steht der erste Speicher kurz vor einer Überlastung. Um dem entgegenzuwirken, haben wir einen Mechanismus zur Korrektur der Ausgleichsregeln mittels Gewichten bereitgestellt. Jedem Replikatsatz oder Speicher kann eine Gewichtung zugewiesen werden. Wenn der Ausgleicher entscheidet, wie viele Eimer und wohin gesendet werden sollen, berücksichtigt er die
Beziehungen aller Gewichtspaare.
Wenn beispielsweise ein Speicher 100 und der andere 200 wiegt, speichert der zweite doppelt so viele Eimer wie der erste. Bitte beachten Sie, dass ich speziell über Gewichtsbeziehungen spreche. Absolutwerte haben keinerlei Einfluss. Sie wählen Gewichte basierend auf einer 100% igen Verteilung in einem Cluster: 30% für einen Speicher ergeben also 70% für den anderen. Sie können die Speicherkapazität in Gigabyte als Basis nehmen oder das Gewicht in der Anzahl der Buckets messen. Das Wichtigste ist, das notwendige Verhältnis einzuhalten.

Diese Methode hat einen interessanten Nebeneffekt: Wenn einem Speicher das Gewicht Null zugewiesen wird, veranlasst der Neuausgleicher, dass dieser Speicher alle seine Buckets neu verteilt. Danach können Sie den gesamten Replikatsatz aus der Konfiguration entfernen.
Atomic Bucket Migration
Wir haben einen Eimer; Es akzeptiert einige Lese- und Schreibvorgänge, und zu einem bestimmten Zeitpunkt fordert der Neuausgleich die Migration in einen anderen Speicher an. Der Bucket akzeptiert keine Schreibanforderungen mehr, andernfalls wird er während der Migration aktualisiert und dann während der Update-Migration erneut aktualisiert. Anschließend wird das Update aktualisiert und so weiter. Daher werden Schreibanforderungen blockiert, aber das Lesen aus dem Bucket ist weiterhin möglich. Die Daten werden jetzt an den neuen Speicherort migriert. Nach Abschluss der Migration nimmt der Bucket erneut Anforderungen an. Es ist an der alten Stelle noch vorhanden, aber es ist als Müll markiert, und später löscht der Müllsammler es Stück für Stück.
Auf der Festplatte, die jedem Bucket zugeordnet ist, sind einige Metadaten physisch gespeichert. Alle oben beschriebenen Schritte werden auf der Festplatte gespeichert. Unabhängig davon, was mit dem Speicher passiert, wird der Bucket-Status automatisch wiederhergestellt.
Möglicherweise haben Sie folgende Fragen:
- Was passiert mit den Anforderungen, die mit dem Bucket arbeiten, wenn die Migration beginnt?
In den Metadaten jedes Buckets gibt es zwei Arten von Referenzen: RO und RW. Wenn ein Benutzer eine Anfrage an einen Bucket stellt, gibt er an, ob die Arbeit schreibgeschützt oder schreibgeschützt sein soll. Für jede Anforderung wird der entsprechende Referenzzähler erhöht.
Warum benötigen wir Referenzzähler für Schreibanforderungen? Angenommen, ein Bucket wird migriert, und der Garbage Collector möchte ihn plötzlich löschen. Der Garbage Collector erkennt, dass der Referenzzähler über Null liegt, sodass der Bucket nicht gelöscht wird. Wenn alle Anforderungen abgeschlossen sind, kann der Garbage Collector seine Arbeit erledigen.
Der Referenzzähler für Schreibvorgänge stellt außerdem sicher, dass die Migration des Buckets nicht gestartet wird, wenn mindestens eine Schreibanforderung in Bearbeitung ist. Andererseits könnten Schreibanforderungen nacheinander eingehen, und der Bucket würde niemals migriert. Wenn der Neuausgleicher den Bucket verschieben möchte, blockiert das System neue Schreibanforderungen, während es darauf wartet, dass die aktuellen Anforderungen während eines bestimmten Zeitlimits abgeschlossen werden. Wenn die Anforderungen nicht innerhalb des angegebenen Zeitlimits abgeschlossen werden, akzeptiert das System erneut neue Schreibanforderungen, während die Bucket-Migration verschoben wird. Auf diese Weise versucht der Rebalancer, den Bucket zu migrieren, bis die Migration erfolgreich ist.
VShard verfügt über eine Bucket_Ref-API auf niedriger Ebene, falls Sie mehr als nur Funktionen auf hoher Ebene benötigen. Wenn Sie wirklich etwas selbst tun möchten, lesen Sie bitte diese API. - Ist es möglich, die Datensätze freizugeben?
Nein, nein. Wenn der Bucket wichtige Daten enthält und permanenten Schreibzugriff erfordert, müssen Sie die Migration vollständig blockieren. Wir haben eine Bucket_Pin-Funktion, um genau das zu tun. Der Bucket wird an den aktuellen Replikatsatz angeheftet, sodass der Rebalancer den Bucket nicht migrieren kann. In diesem Fall können sich benachbarte Eimer jedoch ohne Einschränkungen bewegen.

Eine Replikatsatzsperre ist ein noch stärkeres Werkzeug als Bucket_pin. Dies geschieht nicht mehr im Code, sondern in der Konfiguration. Eine Replikatsatzsperre deaktiviert die Migration eines Buckets innerhalb / außerhalb des Replikatsatzes. So sind alle Daten permanent für Schreibvorgänge verfügbar.

VShard.router
VShard besteht aus zwei Submodulen: VShard.storage und VShard.router. Wir können diese unabhängig voneinander in einer einzigen Instanz erstellen und skalieren. Wenn wir einen Cluster anfordern, wissen wir nicht, wo sich ein bestimmter Bucket befindet, und VShard.router durchsucht ihn nach der Bucket-ID für uns.
Lassen Sie uns auf unser Beispiel zurückblicken, den Bankcluster mit Kundenkonten. Ich möchte in der Lage sein, alle Konten eines bestimmten Kunden aus dem Cluster abzurufen. Dies erfordert eine Standardfunktion für die lokale Suche:

Es sucht nach allen Konten des Kunden anhand seiner ID. Jetzt muss ich mich entscheiden, wo ich die Funktion ausführen soll. Zu diesem Zweck berechne ich die Bucket-ID anhand der Kundenkennung in meiner Anfrage und fordere VShard.router auf, die Funktion in dem Speicher aufzurufen, in dem sich der Bucket mit der Ziel-Bucket-ID befindet. Das Submodul verfügt über eine Routing-Tabelle, die die Positionen der Buckets in den Replikatsätzen beschreibt. VShard.router leitet meine Anfrage weiter.
Es kann durchaus vorkommen, dass das Splittern genau in diesem Moment beginnt und sich die Eimer in Bewegung setzen. Der Router im Hintergrund aktualisiert die Tabelle schrittweise in großen Blöcken, indem er aktuelle Bucket-Tabellen von den Speichern anfordert.
Möglicherweise fordern wir sogar einen kürzlich migrierten Bucket an, wobei der Router seine Routing-Tabelle noch nicht aktualisiert hat. In diesem Fall wird der alte Speicher angefordert, der entweder den Router zu einem anderen Speicher umleitet oder einfach antwortet, dass er nicht über die erforderlichen Daten verfügt. Dann durchsucht der Router jeden Speicher auf der Suche nach dem erforderlichen Bucket. Und wir werden nicht einmal einen Fehler in der Routing-Tabelle bemerken.
Failover lesen
Erinnern wir uns an unsere anfänglichen Probleme:
- Keine Datenlokalität. Mit Eimern gelöst.
- Resharding-Prozess blockiert und hält alles zurück. Wir haben die atomare Datenübertragung mithilfe von Buckets implementiert und die Neuberechnung der Shard-Funktion beseitigt.
- Failover lesen.
Das letzte Problem wird von VShard.router behoben, das vom automatischen Lesefailover-Subsystem unterstützt wird.
Von Zeit zu Zeit pingt der Router die in der Konfiguration angegebenen Speicher an. Angenommen, der Router kann keinen von ihnen anpingen. Der Router verfügt über eine Hot-Backup-Verbindung zu jedem Replikat. Wenn das aktuelle Replikat nicht reagiert, wechselt es einfach zu einem anderen. Die Leseanforderungen werden normal verarbeitet, da wir die Replikate lesen (aber nicht schreiben) können. Und wir können die Priorität für Replikate als Faktor angeben, damit der Router das Failover für Lesevorgänge auswählt. Dies erfolgt mittels Zoning.

Wir weisen jedem Replikat und jedem Router eine Zonennummer zu und geben eine Tabelle an, in der wir den Abstand zwischen jedem Zonenpaar angeben. Wenn der Router entscheidet, wohin er eine Leseanforderung senden soll, wählt er ein Replikat in der nächsten Zone aus.
So sieht es in der Konfiguration aus:

Im Allgemeinen können Sie jedes Replikat anfordern. Wenn der Cluster jedoch groß, komplex und stark verteilt ist, kann das Zoning sehr nützlich sein. Verschiedene Server-Racks können als Zonen ausgewählt werden, damit das Netzwerk nicht durch Datenverkehr überlastet wird. Alternativ können geografisch isolierte Punkte ausgewählt werden.
Das Zoning hilft auch, wenn Replikate unterschiedliche Verhaltensweisen aufweisen. Beispielsweise verfügt jeder Replikatsatz über ein Sicherungsreplikat, das keine Anforderungen akzeptieren, sondern nur eine Kopie der Daten speichern soll. In diesem Fall platzieren wir es in einer Zone weit entfernt von allen Routern in der Tabelle, sodass der Router dieses Replikat nur dann adressiert, wenn dies unbedingt erforderlich ist.
Failover schreiben
Wir haben bereits über Lese-Failover gesprochen. Was ist mit Schreibfailover beim Wechsel des Masters? In VShard ist das Bild nicht mehr so rosig wie zuvor: Die Masterauswahl ist nicht implementiert, daher müssen wir es selbst tun. Wenn wir irgendwie einen Master benannt haben, sollte die bezeichnete Instanz nun als Master übernehmen. Anschließend aktualisieren wir die Konfiguration, indem wir für den alten Master master = false und für den neuen master = true angeben, die Konfiguration mithilfe von VShard.storage.cfg anwenden und für jeden Speicher freigeben. Alles andere wird automatisch erledigt. Der alte Master akzeptiert keine Schreibanforderungen mehr und beginnt mit der Synchronisierung mit dem neuen, da möglicherweise Daten vorhanden sind, die bereits auf den alten Master angewendet wurden, jedoch nicht auf den neuen. Danach ist der neue Master verantwortlich und beginnt, Anforderungen anzunehmen, und der alte Master ist eine Replik. So funktioniert Write Failover in VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Wie verfolgen wir diese verschiedenen Ereignisse?
VShard.storage.info und VShard.router.info reichen aus.
VShard.storage.info zeigt Informationen in mehreren Abschnitten an.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
Der erste Abschnitt dient der Replikation. Hier sehen Sie den Status des Replikatsatzes, in dem die Funktion aufgerufen wird: die Replikationsverzögerung, die verfügbaren und nicht verfügbaren Verbindungen, die Hauptkonfiguration usw.
Im Bucket-Bereich können Sie in Echtzeit die Anzahl der Buckets anzeigen, die zum / vom aktuellen Replikatsatz migriert werden, die Anzahl der im regulären Modus arbeitenden Buckets, die Anzahl der als Müll markierten Buckets und die Anzahl der angehefteten Buckets.
Im Abschnitt "Warnungen" werden die Probleme angezeigt, die VShard selbst feststellen konnte: "Der Master ist nicht konfiguriert", "Es ist nicht genügend Redundanz vorhanden", "Der Master ist vorhanden, aber alle Replikate sind fehlgeschlagen" usw.
Und der letzte Abschnitt (q: ist das "Status"?) Ist ein Licht, das rot wird, wenn alles schief geht. Es ist eine Zahl von null bis drei, wobei eine höhere Zahl schlechter ist.
VShard.router.info hat die gleichen Abschnitte, aber ihre Bedeutung ist etwas anders.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
Der erste Abschnitt befasst sich mit der Replikation, enthält jedoch keine Informationen zu Replikationsverzögerungen, sondern Informationen zur Verfügbarkeit: Router-Verbindungen zu einem Replikatsatz; Hot-Verbindung und Backup-Verbindung für den Fall, dass der Master ausfällt; der ausgewählte Master; und die Anzahl der verfügbaren RW-Buckets und RO-Buckets auf jedem Replikatsatz.
Im Bucket-Bereich wird die Gesamtzahl der Lese- / Schreib- und Nur-Lese-Buckets angezeigt, die derzeit für diesen Router verfügbar sind. die Anzahl der Eimer mit unbekanntem Standort; und die Anzahl der Buckets mit einem bekannten Standort, jedoch ohne Verbindung zum erforderlichen Replikatsatz.
Der Abschnitt "Warnungen" beschreibt hauptsächlich Verbindungen, Failover-Ereignisse und nicht identifizierte Buckets.
Schließlich gibt es auch den einfachen Status? Anzeige von null bis drei.
Was brauchst du, um VShard zu benutzen?
Zuerst müssen Sie eine konstante Anzahl von Eimern auswählen. Warum nicht einfach auf int32_max setzen? Da Metadaten zusammen mit jedem Bucket gespeichert werden, werden 30 Bytes und 16 Bytes auf dem Router gespeichert. Je mehr Buckets Sie haben, desto mehr Speicherplatz wird von den Metadaten belegt. Gleichzeitig wird die Bucket-Größe jedoch kleiner, was eine höhere Cluster-Granularität und eine höhere Migrationsgeschwindigkeit pro Bucket bedeutet. Sie müssen also auswählen, was für Sie wichtiger ist und welche Skalierbarkeit erforderlich ist.
Zweitens müssen Sie eine Shard-Funktion zur Berechnung der Bucket-ID auswählen. Die Regeln sind die gleichen wie bei der Auswahl einer Shard-Funktion beim herkömmlichen Sharding, da ein Bucket hier der festen Anzahl von Speichern beim traditionellen Sharding entspricht. Die Funktion sollte die Ausgabewerte gleichmäßig verteilen, da sonst das Wachstum der Schaufelgröße nicht ausgeglichen wird und VShard nur mit der Anzahl der Schaufeln arbeitet. Wenn Sie Ihre Shard-Funktion nicht ausgleichen, müssen Sie die Daten von einem Bucket in einen anderen migrieren und die Shard-Funktion ändern. Daher sollten Sie sorgfältig auswählen.
Zusammenfassung
VShard sorgt dafür:
- Datenlokalität
- atomares Resharding
- höhere Clusterflexibilität
- automatisches Lesefailover
- mehrere Bucket-Controller.
VShard befindet sich in der aktiven Entwicklung. Einige geplante Aufgaben werden bereits umgesetzt. Die erste Aufgabe ist der
Lastausgleich des Routers . Bei starken Leseanforderungen wird nicht immer empfohlen, diese an den Master zu richten. Der Router sollte Anforderungen für verschiedene Lesereplikate selbst ausgleichen.
Die zweite Aufgabe ist die
sperrfreie Bucket-Migration . Es wurde bereits ein Algorithmus implementiert, mit dem die Buckets auch während der Migration nicht blockiert werden. Der Bucket wird erst am Ende blockiert, um die Migration selbst zu dokumentieren.
Die dritte Aufgabe ist die
atomare Anwendung der Konfiguration . Es ist nicht bequem oder atomar, die Konfiguration separat anzuwenden, da möglicherweise kein Speicher verfügbar ist. Was tun wir als Nächstes, wenn die Konfiguration nicht angewendet wird? Aus diesem Grund arbeiten wir an einem Mechanismus für die automatische Konfigurationsübertragung.