
Bei der Diagnose von Problemen in einem Kubernetes-Cluster stellen wir häufig fest, dass manchmal einer der Clusterknoten nieselt *, und dies ist natürlich selten und seltsam. Wir kamen zu der Notwendigkeit eines Tools, das
von jedem Knoten zu jedem Knoten pingt und die Ergebnisse seiner Arbeit in Form
von Prometheus-Metriken präsentiert . Wir müssten nur Diagramme in Grafana zeichnen und den ausgefallenen Knoten schnell lokalisieren (und ggf. alle Pods daraus entfernen und dann die entsprechende Arbeit erledigen **) ...
* Unter "Nieselregen" verstehe ich, dass der Knoten in den NotReady Status NotReady und plötzlich zur Arbeit zurückkehren kann. Beispielsweise kann ein Teil des Verkehrs in Pods die Pods auf benachbarten Knoten nicht erreichen.** Warum entstehen solche Situationen? Eine der häufigsten Ursachen können Netzwerkprobleme auf dem Switch im Rechenzentrum sein. Zum Beispiel haben wir in Hetzner vswitch konfiguriert, aber zu einem wunderbaren Zeitpunkt war einer der Knoten an diesem vswitch-Port nicht mehr zugänglich: Aus diesem Grund stellte sich heraus, dass der Knoten im lokalen Netzwerk vollständig unzugänglich war.Darüber hinaus möchten wir einen
solchen Dienst direkt in Kubernetes starten , damit die gesamte Bereitstellung über die Installation des Helm-Charts erfolgt. (Vorwegnahme von Fragen - Wenn wir denselben Ansible verwenden, müssten wir Rollen für verschiedene Umgebungen schreiben: AWS, GCE, Bare Metal ...) Nachdem wir ein bisschen im Internet nach vorgefertigten Tools für die Aufgabe gesucht hatten, fanden wir nichts Passendes. Deshalb haben sie ihre eigenen gemacht.
Skript und Konfigurationen
Die Hauptkomponente unserer Lösung ist also ein
Skript , das die Änderung in allen Knoten des
.status.addresses überwacht und, wenn ein Knoten dieses Feld geändert hat (d. H. Ein neuer Knoten hinzugefügt wurde), Helmwerte mit an das Diagramm sendet Diese Liste von Knoten in Form von ConfigMap:
--- apiVersion: v1 kind: ConfigMap metadata: name: node-ping-config namespace: kube-prometheus data: nodes.json: > {{ .Values.nodePing.nodes | toJson }}
Es wird
auf jedem Knoten ausgeführt und sendet zweimal pro Sekunde ICMP-Pakete an alle anderen Kubernetes-Clusterinstanzen. Die Ergebnisse werden in die Textdateien geschrieben.
Das Skript ist im
Docker-Image enthalten :
FROM python:3.6-alpine3.8 COPY rootfs / WORKDIR /app RUN pip3 install --upgrade pip && pip3 install -r requirements.txt && apk add --no-cache fping ENTRYPOINT ["python3", "/app/node-ping.py"]
Außerdem wurde ein
ServiceAccount und eine Rolle dafür erstellt, mit der nur eine Liste von Knoten empfangen werden kann (um deren Adressen zu kennen):
--- apiVersion: v1 kind: ServiceAccount metadata: name: node-ping namespace: kube-prometheus --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:node-ping rules: - apiGroups: [""] resources: ["nodes"] verbs: ["list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:kube-node-ping subjects: - kind: ServiceAccount name: node-ping namespace: kube-prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-prometheus:node-ping
Schließlich benötigen Sie
DaemonSet , das auf allen Instanzen des Clusters ausgeführt wird:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: node-ping namespace: kube-prometheus labels: tier: monitoring app: node-ping version: v1 spec: updateStrategy: type: RollingUpdate template: metadata: labels: name: node-ping spec: terminationGracePeriodSeconds: 0 tolerations: - operator: "Exists" serviceAccountName: node-ping priorityClassName: cluster-low containers: - resources: requests: cpu: 0.10 image: private-registry.flant.com/node-ping/node-ping-exporter:v1 imagePullPolicy: Always name: node-ping env: - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: PROMETHEUS_TEXTFILE_DIR value: /node-exporter-textfile/ - name: PROMETHEUS_TEXTFILE_PREFIX value: node-ping_ volumeMounts: - name: textfile mountPath: /node-exporter-textfile - name: config mountPath: /config volumes: - name: textfile hostPath: path: /var/run/node-exporter-textfile - name: config configMap: name: node-ping-config imagePullSecrets: - name: antiopa-registry
Zusammenfassende Striche in Worten:
- Python-Skriptergebnisse - d.h. Textdateien, die auf dem Hostcomputer im Verzeichnis
/var/run/node-exporter-textfile exporter /var/run/node-exporter-textfile textfile abgelegt werden, werden in den DaemonSet-Knotenexporter verschoben. Die Argumente zum Ausführen geben --collector.textfile.directory /host/textfile , wobei /host/textfile der hostPath in /var/run/node-exporter-textfile . (Informationen zum Textdateisammler im Node-Exporter finden Sie hier .) - Infolgedessen liest der Node-Exporter diese Dateien und Prometheus sammelt alle Daten vom Node-Exporter.
Was ist passiert?
Nun zum lang erwarteten Ergebnis. Wenn solche Metriken erstellt wurden, können wir sie betrachten und natürlich visuelle Grafiken zeichnen. So sieht es aus.
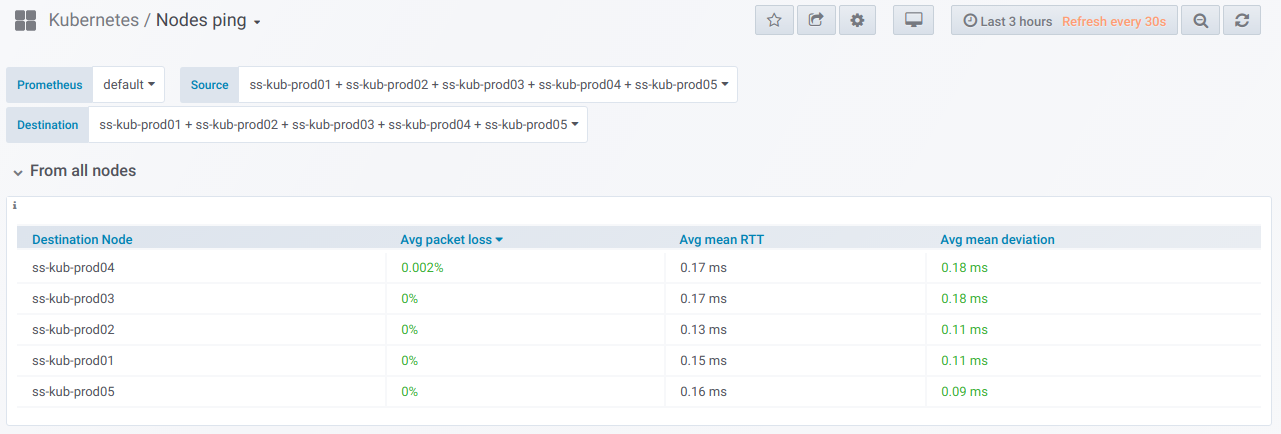
Erstens gibt es einen allgemeinen Block mit der Fähigkeit (unter Verwendung des Selektors), eine Liste von Knoten auszuwählen,
von denen Ping ausgeführt wird und
auf denen. Dies ist die
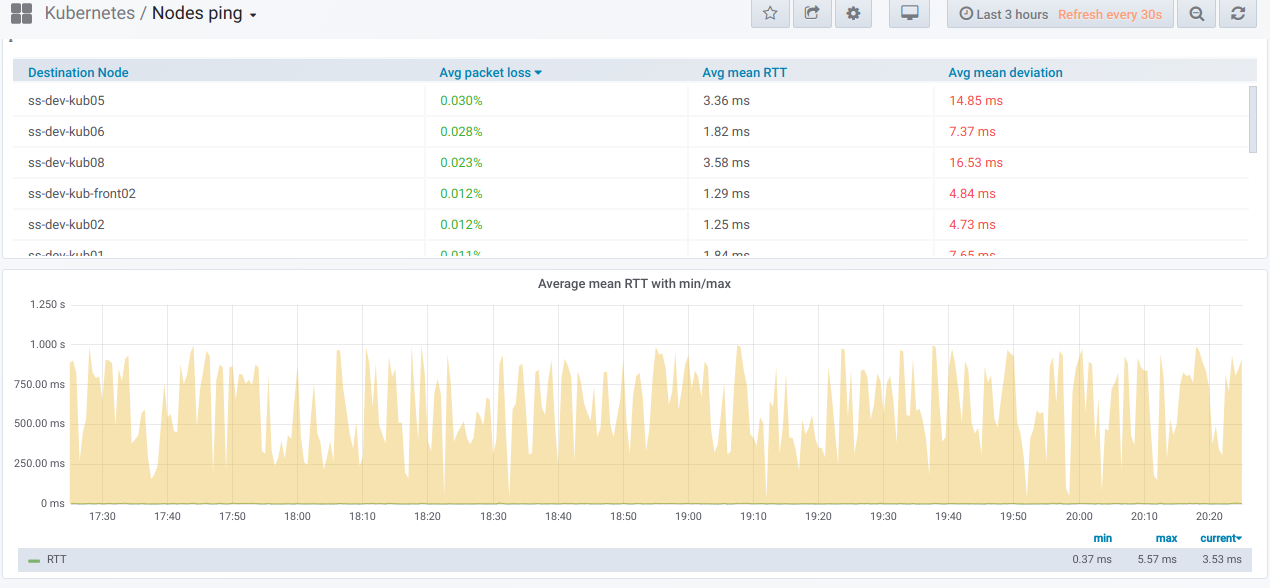
Übersichtstabelle für den Ping zwischen den ausgewählten Knoten für den im Grafana-Dashboard angegebenen Zeitraum:
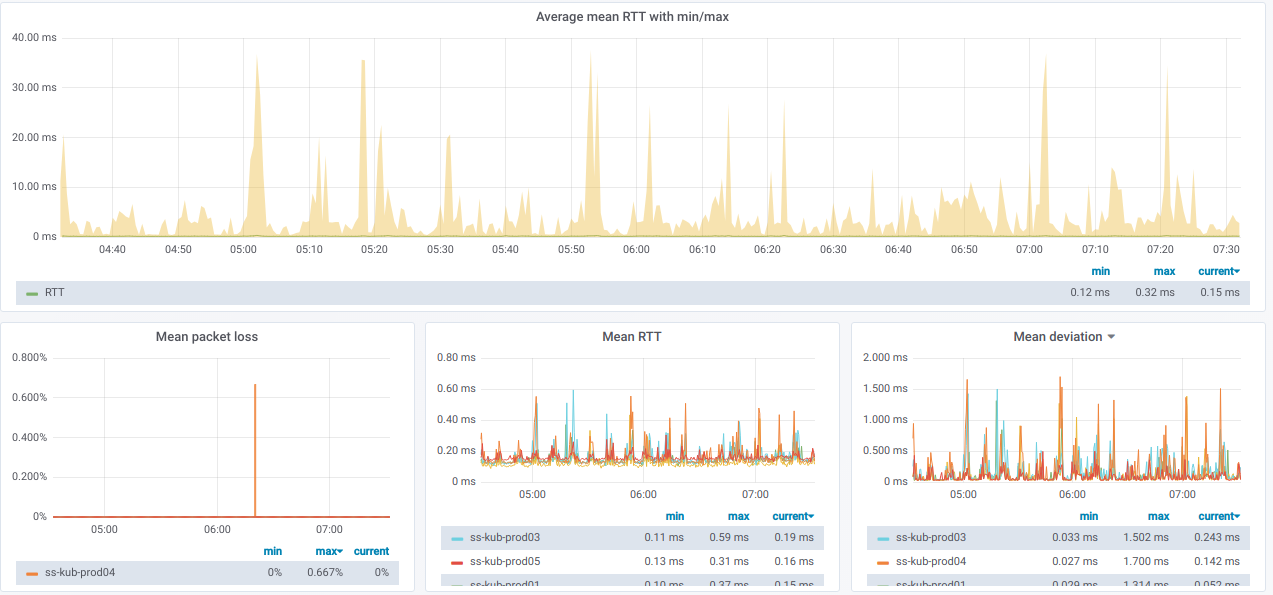
Und hier sind die Grafiken mit allgemeinen Informationen
zu den ausgewählten Knoten :
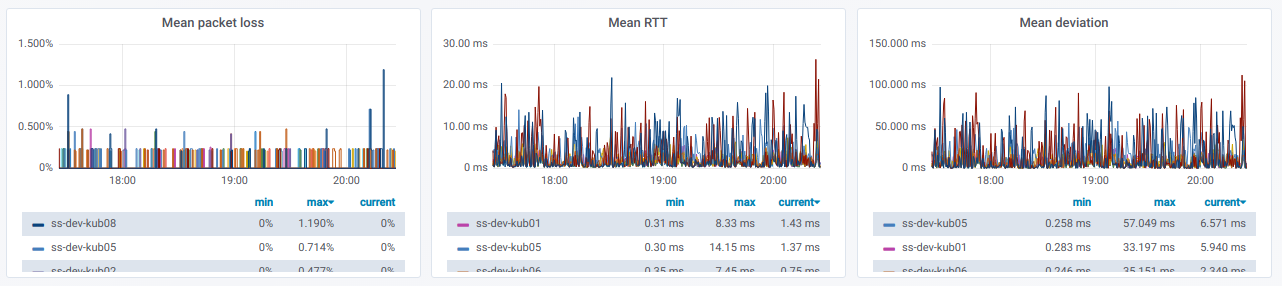
Wir haben auch eine Liste von Linien, von denen jede ein Diagramm
für einen separaten Knoten aus der
Auswahl des Quellknotens ist:

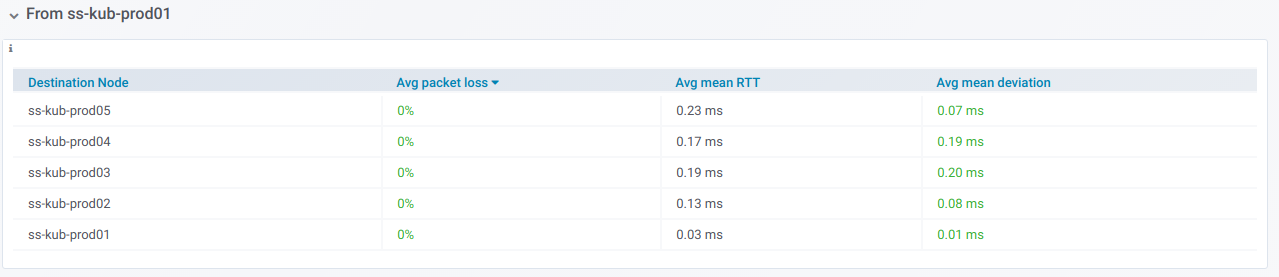
Wenn Sie eine solche Zeile erweitern, sehen Sie Informationen zu Pings
von einem bestimmten Knoten zu allen anderen , die in der Auswahl der
Zielknoten ausgewählt wurden:
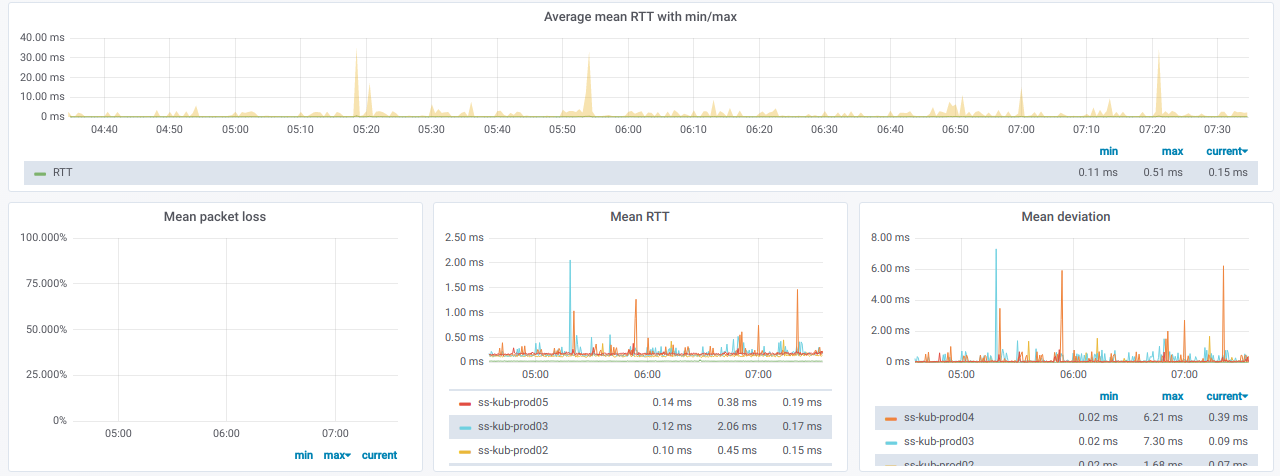
Diese Informationen sind in Grafiken dargestellt:
Wie sehen die geschätzten Grafiken schließlich mit schlechtem Ping zwischen den Knoten aus?
Wenn Sie dies in einer realen Umgebung beobachten, ist es Zeit, die Gründe herauszufinden.
PS
Lesen Sie auch in unserem Blog: