Freunde, Ende März starten wir einen neuen Stream zum Kurs
„Data Scientist“ . Und im Moment beginnen wir, nützliches Material über den Kurs mit Ihnen zu teilen.
EinführungIch erinnere mich an die frühen Erfahrungen meiner Leidenschaft für maschinelles Lernen (ML) und kann sagen, dass viel Aufwand in den Aufbau eines wirklich guten Modells gesteckt wurde. Ich habe mich mit Experten auf diesem Gebiet beraten, um zu verstehen, wie ich mein Modell verbessern kann, über die erforderlichen Funktionen nachgedacht und versucht, sicherzustellen, dass alle von ihnen vorgeschlagenen Tipps berücksichtigt wurden. Trotzdem bin ich auf ein Problem gestoßen.
Wie implementiere ich das Modell in ein reales Projekt? Ich hatte diesbezüglich keine Ideen. Die gesamte Literatur, die ich bis zu diesem Punkt studiert habe, konzentrierte sich nur auf die Verbesserung von Modellen. Ich habe den nächsten Schritt in ihrer Entwicklung nicht gesehen.

Deshalb schreibe ich jetzt diesen Leitfaden. Ich möchte, dass Sie sich dem Problem stellen, auf das ich in meiner Zeit gestoßen bin, aber ich könnte es schnell lösen. Gegen Ende dieses Artikels werde ich Ihnen zeigen, wie Sie ein Modell für maschinelles Lernen mithilfe des Flask-Frameworks in Python implementieren.
Inhalt- Implementierungsoptionen für Modelle des maschinellen Lernens.
- Was ist eine API?
- Installieren der Python-Umgebung und grundlegende Informationen zu Flask.
- Erstellen eines maschinellen Lernmodells.
- Speichern von Modellen für maschinelles Lernen: Serialisierung und Deserialisierung.
- Erstellen einer API mit Flask.
Implementierungsoptionen für Modelle des maschinellen Lernens.
In den meisten Fällen ist die tatsächliche Verwendung von Modellen für maschinelles Lernen ein zentraler Bestandteil der Entwicklung, auch wenn es sich nur um eine kleine Komponente eines automatisierten E-Mail-Verteilungssystems oder Chatbots handelt. Manchmal scheinen die Hindernisse für die Umsetzung unüberwindbar.
Beispielsweise verwenden die meisten ML-Spezialisten R oder Python für ihre wissenschaftliche Forschung. Softwareentwickler, die einen völlig anderen Technologie-Stack verwenden, werden jedoch Verbraucher dieser Modelle sein. Es gibt zwei Möglichkeiten, um dieses Problem zu lösen:
Option 1: Schreiben Sie den gesamten Code in der Sprache neu, mit der die Entwicklungsingenieure arbeiten. Es klingt bis zu einem gewissen Grad logisch, aber es erfordert viel Zeit und Mühe, die entwickelten Modelle zu replizieren. Am Ende ist es nur Zeitverschwendung. Die meisten Sprachen wie JavaScript verfügen nicht über geeignete Bibliotheken für die Arbeit mit ML. Daher ist es eine rationale Lösung, diese Option nicht zu verwenden.
Option 2: Verwenden Sie die API. Netzwerk-APIs lösten das Problem der Arbeit mit Anwendungen in verschiedenen Sprachen. Wenn der Front-End-Entwickler Ihr Modell für maschinelles Lernen verwenden muss, um eine Webanwendung auf dieser Basis zu erstellen, muss er nur die URL des Zielservers abrufen, auf dem die API erläutert wird.
Was ist eine API?Mit einfachen Worten, die API (Application Programming Interface) ist eine Art Vertrag zwischen zwei Programmen. Wenn ein Benutzerprogramm Eingabedaten in einem bestimmten Format bereitstellt, leitet das Entwicklerprogramm (API) diese durch sich selbst und stellt dem Benutzer Ausgabedaten zur Verfügung.
Sie können einige Artikel selbst lesen, die gut beschreiben, warum die API bei Entwicklern sehr beliebt ist.
Die meisten großen Cloud-Dienstleister und kleinere Unternehmen mit Schwerpunkt auf maschinellem Lernen bieten gebrauchsfertige APIs an. Sie erfüllen die Anforderungen von Entwicklern, die maschinelles Lernen nicht verstehen, diese Technologie jedoch in ihre Lösungen integrieren möchten.
Einer dieser API-Anbieter ist beispielsweise Google mit seiner
Google Vision-API .
Der Entwickler muss lediglich die REST-API (Representational State Transfer) mit dem von Google bereitgestellten SDK aufrufen. Sehen Sie, was Sie mit der
Google Vision-API tun können.
Hört sich toll an, oder? In diesem Artikel erfahren Sie, wie Sie mit Flask, einem Python-Framework, eine eigene API erstellen.
Hinweis : Flask ist nicht das einzige Netzwerkframework für diesen Zweck. Es gibt auch Django, Falcon, Hug und viele andere, die in diesem Artikel nicht erwähnt werden. Für R gibt es beispielsweise ein Paket namens
KlempnerInstallieren der Python-Umgebung und grundlegende Informationen zu Flask.1) Erstellen einer virtuellen Umgebung mit Anaconda. Wenn Sie eine eigene virtuelle Umgebung für Python erstellen und den erforderlichen Abhängigkeitsstatus beibehalten müssen, bietet Anaconda hierfür gute Lösungen. Weiter wird mit der Kommandozeile arbeiten.
- Hier finden Sie das Miniconda- Installationsprogramm für Python.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.shbash Miniconda3-latest-Linux-x86_64.sh- Folgen Sie der Reihenfolge der Fragen.
source .bashrc- Wenn Sie
conda : conda , wird eine Liste der verfügbaren Befehle und Hilfen conda . conda create --name <environment-name> python=3.6 zum Erstellen einer neuen Umgebung conda create --name <environment-name> python=3.6 : conda create --name <environment-name> python=3.6- Befolgen Sie die Schritte, zu denen Sie aufgefordert werden, und geben Sie am Ende Folgendes ein:
source activate <environment-name> - Installieren Sie die erforderlichen Python-Pakete. Die wichtigsten sind Flasche und Gunicorn.
2) Wir werden versuchen, unsere einfache "Hello World" -Kolbenanwendung mit Gunicorn zu erstellen .- Öffnen Sie Ihren bevorzugten Texteditor und erstellen Sie die Datei
hello-world.py im Ordner - Schreiben Sie den folgenden Code:
"""Filename: hello-world.py """ from flask import Flask app = Flask(__name__) @app.route('/users/<string:username>') def hello_world(username=None): return("Hello {}!".format(username))
- Speichern Sie die Datei und kehren Sie zum Terminal zurück.
- Um die API zu starten, führen Sie sie im Terminal aus:
gunicorn --bind 0.0.0.0:8000 hello-world:app - Wenn Sie Folgendes erhalten, sind Sie auf dem richtigen Weg:

- Geben Sie im Browser Folgendes ein:
https://localhost:8000/users/any-name

Hurra! Du hast dein erstes Flask-Programm geschrieben! Da Sie bereits Erfahrung mit diesen einfachen Schritten haben, können wir Netzwerkendpunkte erstellen, auf die lokal zugegriffen werden kann.
Mit Flask können wir unsere Modelle verpacken und als Web-API verwenden. Wenn wir komplexere Netzwerkanwendungen erstellen möchten (z. B. in JavaScript), müssen wir einige Änderungen hinzufügen.
Erstellen eines maschinellen Lernmodells.- Schauen wir uns zunächst den Wettbewerb für maschinelles Lernen des Darlehensvorhersagewettbewerbs an . Das Hauptziel besteht darin, eine Vorverarbeitungspipeline einzurichten und ML-Modelle zu erstellen, um die Vorhersageaufgabe während der Bereitstellung zu erleichtern.
import os import json import numpy as np import pandas as pd from sklearn.externals import joblib from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.base import BaseEstimator, TransformerMixin from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import make_pipeline import warnings warnings.filterwarnings("ignore")
- Speichern Sie den Datensatz im Ordner:
!ls /home/pratos/Side-Project/av_articles/flask_api/data/
test.csv training.csv
data = pd.read_csv('../data/training.csv')
list(data.columns)
['Loan_ID', 'Gender', 'Married', 'Dependents', 'Education', 'Self_Employed', 'ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term', 'Credit_History', 'Property_Area', 'Loan_Status']
data.shape
(614, 13)
ul>
Finden Sie die Null / Nan-Werte in den Spalten:
for _ in data.columns: print("The number of null values in:{} == {}".format(_, data[_].isnull().sum()))
The number of null values in:Loan_ID == 0 The number of null values in:Gender == 13 The number of null values in:Married == 3 The number of null values in:Dependents == 15 The number of null values in:Education == 0 The number of null values in:Self_Employed == 32 The number of null values in:ApplicantIncome == 0 The number of null values in:CoapplicantIncome == 0 The number of null values in:LoanAmount == 22 The number of null values in:Loan_Amount_Term == 14 The number of null values in:Credit_History == 50 The number of null values in:Property_Area == 0 The number of null values in:Loan_Status == 0
- Der nächste Schritt besteht darin, Datensätze für Schulungen und Tests zu erstellen:
red_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome','CoapplicantIncome',\ 'LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'] X_train, X_test, y_train, y_test = train_test_split(data[pred_var], data['Loan_Status'], \ test_size=0.25, random_state=42)
- Um sicherzustellen, dass alle Vorverarbeitungsschritte auch nach dem Experimentieren korrekt ausgeführt werden und wir während der Vorhersage nichts verpasst haben, erstellen wir unseren eigenen Scikit-Lern-Evaluator für die Vorverarbeitung (Vorverarbeitungs-Scikit-Lernschätzer). .
Lesen Sie
Folgendes , um zu verstehen, wie wir es erstellt haben.
from sklearn.base import BaseEstimator, TransformerMixin class PreProcessing(BaseEstimator, TransformerMixin): """Custom Pre-Processing estimator for our use-case """ def __init__(self): pass def transform(self, df): """Regular transform() that is a help for training, validation & testing datasets (NOTE: The operations performed here are the ones that we did prior to this cell) """ pred_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome',\ 'CoapplicantIncome','LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'] df = df[pred_var] df['Dependents'] = df['Dependents'].fillna(0) df['Self_Employed'] = df['Self_Employed'].fillna('No') df['Loan_Amount_Term'] = df['Loan_Amount_Term'].fillna(self.term_mean_) df['Credit_History'] = df['Credit_History'].fillna(1) df['Married'] = df['Married'].fillna('No') df['Gender'] = df['Gender'].fillna('Male') df['LoanAmount'] = df['LoanAmount'].fillna(self.amt_mean_) gender_values = {'Female' : 0, 'Male' : 1} married_values = {'No' : 0, 'Yes' : 1} education_values = {'Graduate' : 0, 'Not Graduate' : 1} employed_values = {'No' : 0, 'Yes' : 1} property_values = {'Rural' : 0, 'Urban' : 1, 'Semiurban' : 2} dependent_values = {'3+': 3, '0': 0, '2': 2, '1': 1} df.replace({'Gender': gender_values, 'Married': married_values, 'Education': education_values, \ 'Self_Employed': employed_values, 'Property_Area': property_values, \ 'Dependents': dependent_values}, inplace=True) return df.as_matrix() def fit(self, df, y=None, **fit_params): """Fitting the Training dataset & calculating the required values from train eg: We will need the mean of X_train['Loan_Amount_Term'] that will be used in transformation of X_test """ self.term_mean_ = df['Loan_Amount_Term'].mean() self.amt_mean_ = df['LoanAmount'].mean() return self
- Konvertieren Sie
y_train und y_test in np.array :
y_train = y_train.replace({'Y':1, 'N':0}).as_matrix() y_test = y_test.replace({'Y':1, 'N':0}).as_matrix()
Erstellen wir eine Pipeline, um sicherzustellen, dass alle Vorverarbeitungsschritte, die wir ausführen, die Arbeit des Scikit-Learn-Evaluators sind.
pipe = make_pipeline(PreProcessing(), RandomForestClassifier())
pipe
Pipeline(memory=None, steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False))])
Um nach geeigneten Hyperparametern zu suchen (Grad für Polynomobjekte und Alpha für eine Kante), führen wir eine Rastersuche (Rastersuche) durch:
param_grid = {"randomforestclassifier__n_estimators" : [10, 20, 30], "randomforestclassifier__max_depth" : [None, 6, 8, 10], "randomforestclassifier__max_leaf_nodes": [None, 5, 10, 20], "randomforestclassifier__min_impurity_split": [0.1, 0.2, 0.3]}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3)
- Wir passen die Trainingsdaten für den Pipeline-Schätzer an:
grid.fit(X_train, y_train)
GridSearchCV(cv=3, error_score='raise', estimator=Pipeline(memory=None, steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impu..._jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False))]), fit_params=None, iid=True, n_jobs=1, param_grid={'randomforestclassifier__n_estimators': [10, 20, 30], 'randomforestclassifier__max_leaf_nodes': [None, 5, 10, 20], 'randomforestclassifier__min_impurity_split': [0.1, 0.2, 0.3], 'randomforestclassifier__max_depth': [None, 6, 8, 10]}, pre_dispatch='2*n_jobs', refit=True, return_train_score=True, scoring=None, verbose=0)
- Mal sehen, welchen Parameter die Suche im Raster gewählt hat:
print("Best parameters: {}".format(grid.best_params_))
Best parameters: {'randomforestclassifier__n_estimators': 30, 'randomforestclassifier__max_leaf_nodes': 20, 'randomforestclassifier__min_impurity_split': 0.2, 'randomforestclassifier__max_depth': 8}
print("Validation set score: {:.2f}".format(grid.score(X_test, y_test)))
Validation set score: 0.79
- Laden Sie die Testsuite herunter:
test_df = pd.read_csv('../data/test.csv', encoding="utf-8-sig") test_df = test_df.head()
grid.predict(test_df)
array([1, 1, 1, 1, 1])
Unsere Pipeline sieht gut genug aus, um mit dem nächsten wichtigen Schritt fortzufahren: der Serialisierung des maschinellen Lernmodells.
Speichern eines maschinellen Lernmodells: Serialisierung und Deserialisierung."In der Informatik bedeutet Serialisierung im Kontext der Datenspeicherung, Datenstrukturen oder Objektzustände in ein gespeichertes Format (z. B. eine Datei oder einen Speicherpuffer) zu übersetzen und später in derselben oder einer anderen Computerumgebung zu rekonstruieren."
In Python ist das Beizen die Standardmethode zum Speichern und Abrufen von Objekten in ihrem ursprünglichen Zustand. Um es klarer zu machen, werde ich ein einfaches Beispiel geben:
list_to_pickle = [1, 'here', 123, 'walker']
list_pickle
b'\x80\x03]q\x00(K\x01X\x04\x00\x00\x00hereq\x01K{X\x06\x00\x00\x00walkerq\x02e.'
Dann entladen wir das Dosenobjekt erneut:
loaded_pickle = pickle.loads(list_pickle)
loaded_pickle
[1, 'here', 123, 'walker']
Wir können vordefinierte Objekte in einer Datei speichern und verwenden. Diese Methode ähnelt dem Erstellen von
.rda Dateien, wie beispielsweise bei der R-Programmierung.
Hinweis: Einige mögen diese Aufbewahrungsmethode für die Serialisierung möglicherweise nicht. Eine Alternative könnte
h5py .
Wir haben eine benutzerdefinierte Klasse (Class), die wir während des Trainings importieren müssen. Daher verwenden wir das
dill Modul, um den Klassenauswerter mit dem
dill zu verpacken.
Es wird empfohlen, eine separate Datei
training.py erstellen, die den gesamten Code zum Trainieren des Modells enthält. (Ein Beispiel ist hier zu sehen).
- Installieren Sie den
dill
!pip install dill
Requirement already satisfied: dill in /home/pratos/miniconda3/envs/ordermanagement/lib/python3.5/site-packages
import dill as pickle filename = 'model_v1.pk'
with open('../flask_api/models/'+filename, 'wb') as file: pickle.dump(grid, file)
Das Modell wird in dem oben ausgewählten Verzeichnis gespeichert. Sobald ein Modell eingemottet ist, kann es in eine Flaschenverpackung eingewickelt werden. Zuvor müssen Sie jedoch sicherstellen, dass die vordefinierte Datei funktioniert. Laden wir es zurück und machen eine Vorhersage:
with open('../flask_api/models/'+filename ,'rb') as f: loaded_model = pickle.load(f)
loaded_model.predict(test_df)
array([1, 1, 1, 1, 1])
Da wir die Vorverarbeitungsschritte befolgt haben, damit die neu angekommenen Daten Teil der Pipeline sind, müssen wir nur Predict () ausführen. Mit der Scikit-Learn-Bibliothek ist es ganz einfach, mit Pipelines zu arbeiten. Gutachter und Pipelines kümmern sich um Ihre Zeit und Ihre Nerven, auch wenn die anfängliche Implementierung wild erscheint.
Erstellen einer API mit FlaskLassen Sie uns die Ordnerstruktur so einfach wie möglich halten:
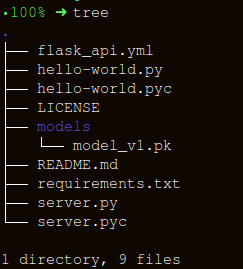
Das Erstellen eines Wrappers für die Funktion
apicall() besteht aus drei wichtigen Teilen:
- Empfangen von
request (für die eine Prognose erstellt wird); - Laden eines Dosengutachters;
- Übersetzung unserer Prognosen im JSON-Format und Erhalt eines Antwortstatuscodes
status code: 200 ;
HTTP-Nachrichten werden aus dem Header und dem Body erstellt. Im Allgemeinen wird der Hauptteilinhalt im JSON-Format übertragen. Wir senden (
POST url-endpoint/ ) eingehende Daten als Paket für den Empfang von Prognosen.
Hinweis: Sie können einfachen Text, XML, Lebensläufe oder ein Bild direkt senden, um das Format auszutauschen. In unserem Fall ist es jedoch vorzuziehen, JSON zu verwenden.
"""Filename: server.py """ import os import pandas as pd from sklearn.externals import joblib from flask import Flask, jsonify, request app = Flask(__name__) @app.route('/predict', methods=['POST']) def apicall(): """API Call Pandas dataframe (sent as a payload) from API Call """ try: test_json = request.get_json() test = pd.read_json(test_json, orient='records')
gunicorn --bind 0.0.0.0:8000 server:app nach der Ausführung
gunicorn --bind 0.0.0.0:8000 server:app ein:
gunicorn --bind 0.0.0.0:8000 server:appGenerieren wir Daten für die Prognose und eine Warteschlange für die
https:0.0.0.0:8000/predict Ausführung der API unter
https:0.0.0.0:8000/predict import json import requests
"""Setting the headers to send and accept json responses """ header = {'Content-Type': 'application/json', \ 'Accept': 'application/json'} """Reading test batch """ df = pd.read_csv('../data/test.csv', encoding="utf-8-sig") df = df.head() """Converting Pandas Dataframe to json """ data = df.to_json(orient='records')
data
'[{"Loan_ID":"LP001015","Gender":"Male","Married":"Yes","Dependents":"0","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5720,"CoapplicantIncome":0,"LoanAmount":110.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001022","Gender":"Male","Married":"Yes","Dependents":"1","Education":"Graduate","Self_Employed":"No","ApplicantIncome":3076,"CoapplicantIncome":1500,"LoanAmount":126.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001031","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5000,"CoapplicantIncome":1800,"LoanAmount":208.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001035","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":2340,"CoapplicantIncome":2546,"LoanAmount":100.0,"Loan_Amount_Term":360.0,"Credit_History":null,"Property_Area":"Urban"},{"Loan_ID":"LP001051","Gender":"Male","Married":"No","Dependents":"0","Education":"Not Graduate","Self_Employed":"No","ApplicantIncome":3276,"CoapplicantIncome":0,"LoanAmount":78.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"}]'
"""POST <url>/predict """ resp = requests.post("http://0.0.0.0:8000/predict", \ data = json.dumps(data),\ headers= header)
resp.status_code
200
"""The final response we get is as follows: """ resp.json()
{'predictions': '[{"0":"LP001015","1":1},{...
FazitIn diesem Artikel haben wir nur die Hälfte des Weges zurückgelegt und eine funktionierende API erstellt, die Prognosen liefert, und sind der direkten Integration von ML-Lösungen in entwickelte Anwendungen einen Schritt näher gekommen. Wir haben eine ziemlich einfache API erstellt, die beim Prototyping des Produkts hilft und es wirklich funktionsfähig macht. Um es jedoch an die Produktion zu senden, müssen Sie einige Anpassungen vornehmen, die nicht mehr im Bereich des maschinellen Lernens liegen.
Beim Erstellen der API sind einige Dinge zu beachten:
- Das Erstellen einer Qualitäts-API aus Spaghetti-Code ist nahezu unmöglich. Verwenden Sie daher Ihr Wissen im maschinellen Lernen, um eine nützliche und bequeme API zu erstellen.
- Versuchen Sie, die Versionskontrolle für Modelle und API-Code zu verwenden. Beachten Sie, dass Flask keine Unterstützung für Tools zur Versionskontrolle bietet. Das Speichern und Verfolgen von ML-Modellen ist eine schwierige Aufgabe. Finden Sie einen für Sie geeigneten Weg. Hier gibt es einen Artikel darüber, wie das geht.
- Aufgrund der Besonderheiten von Scikit-Lernmodellen müssen Sie sicherstellen, dass der Evaluator und der Trainingscode nebeneinander liegen (wenn Sie einen benutzerdefinierten Evaluator für die Vorverarbeitung oder ähnliche Aufgaben verwenden). Daher befindet sich neben dem vordefinierten Modell ein Klassenauswerter.
Der nächste logische Schritt besteht darin, Mechaniken für die Bereitstellung einer solchen API auf einer kleinen virtuellen Maschine zu erstellen. Es gibt verschiedene Möglichkeiten, dies zu tun, aber wir werden sie im nächsten Artikel behandeln.
Code und Erklärung für diesen ArtikelNützliche Quellen:[1]
Geben Sie Ihre Daten nicht ein.[2]
Scikit Learn-kompatible Transformatoren erstellen .
[3]
Verwenden von jsonify in Flask .
[4]
Flask-QuickStart.Hier ist so ein Material. Abonnieren Sie uns, wenn Ihnen die Veröffentlichung gefallen hat, und melden Sie sich für ein kostenloses
offenes Webinar zum Thema „Metrische Klassifizierungsalgorithmen“ an, das am 12. März vom Entwickler und Datenwissenschaftler mit 5 Jahren Erfahrung -
Alexander Nikitin - abgehalten wird.