
Teil 1/3 hier
Teil 3/3 hier
Hallo und willkommen zurück! Dies ist der zweite Teil des Artikels zum Einrichten eines Kubernetes-Clusters auf Bare-Metal. Zuvor haben wir den Kubernetes HA-Cluster mithilfe von externem etcd, Master-Master und Lastausgleich konfiguriert. Nun ist es an der Zeit, eine zusätzliche Umgebung und Dienstprogramme einzurichten, um den Cluster nützlicher und so nah wie möglich am Arbeitszustand zu machen.
In diesem Teil des Artikels konzentrieren wir uns auf die Konfiguration des internen Load Balancers von Clusterdiensten - dies ist MetalLB. Wir werden auch den verteilten Dateispeicher zwischen unseren Arbeitsknoten installieren und konfigurieren. Wir werden GlusterFS für persistente Volumes verwenden, die in Kubernetes verfügbar sind.
Nachdem Sie alle Schritte ausgeführt haben, sieht unser Clusterdiagramm folgendermaßen aus:
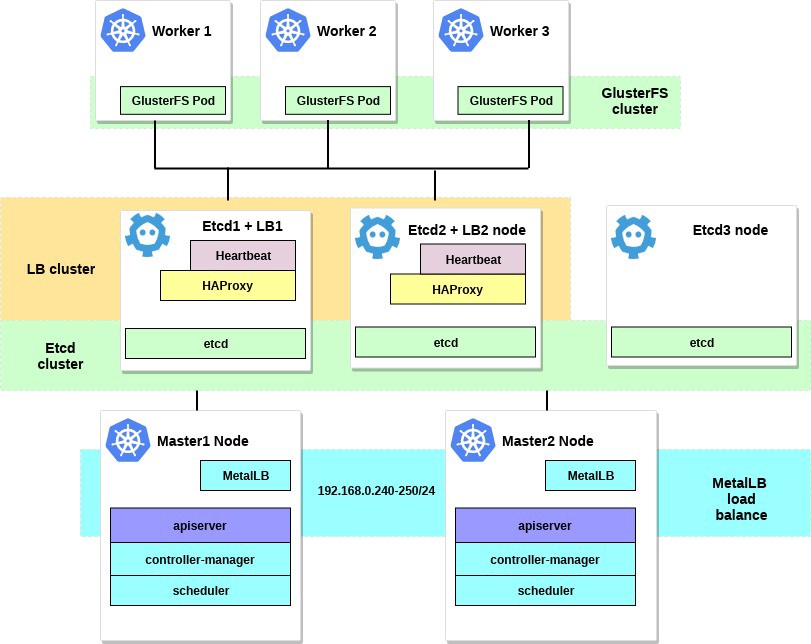
Ein paar Worte zu MetalLB direkt von der Dokumentseite:
MetalLB ist eine Load-Balancer-Implementierung für Kubernetes Bare-Metal-Cluster mit Standard-Routing-Protokollen.
Kubernetes bietet keine Implementierung von Netzwerklastenausgleichern ( Diensttyp LoadBalancer ) für Bare Metal an. Alle Implementierungsoptionen von Network LB, mit denen Kubernetes geliefert wird, sind Middleware und greifen auf verschiedene IaaS-Plattformen (GCP, AWS, Azure usw.) zu. Wenn Sie nicht auf einer von IaaS unterstützten Plattform (GCP, AWS, Azure usw.) arbeiten, bleibt der LoadBalancer bei der Erstellung auf unbestimmte Zeit im Standby-Status.
BM-Serverbetreiber verfügen über zwei weniger effektive Tools zum Eingeben des Benutzerverkehrs in ihre Cluster: NodePort- und externalIPs-Dienste. Beide Optionen weisen erhebliche Produktionsmängel auf, wodurch BM-Cluster zu Bürgern zweiter Klasse im Kubernetes-Ökosystem werden.
MetalLB versucht, dieses Ungleichgewicht zu korrigieren, indem es eine Network LB-Implementierung anbietet, die in Standard-Netzwerkgeräte integriert ist, sodass externe Dienste in BM-Clustern auch „nur mit maximaler Geschwindigkeit funktionieren“.
Mit diesem Tool starten wir daher Dienste im Kubernetes-Cluster mithilfe eines Load Balancers, wofür wir uns beim MetalLB-Team bedanken. Der Einrichtungsprozess ist sehr einfach und unkompliziert.
Zu Beginn des Beispiels haben wir das Subnetz 192.168.0.0/24 für die Anforderungen unseres Clusters ausgewählt. Nehmen Sie nun einen Teil dieses Subnetzes für den zukünftigen Load Balancer.
Wir betreten das Maschinensystem mit dem konfigurierten kubectl- Dienstprogramm und führen Folgendes aus:
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yaml
Dadurch wird MetalLB im Cluster im metallb-system . Stellen Sie sicher, dass alle MetalLB-Komponenten ordnungsgemäß funktionieren:
control# kubectl get pod --namespace=metallb-system NAME READY STATUS RESTARTS AGE controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h speaker-82qb5 1/1 Running 0 5d3h speaker-h5jw7 1/1 Running 0 5d3h speaker-r2fcg 1/1 Running 0 5d3h
Konfigurieren Sie nun MetalLB mit configmap. In diesem Beispiel verwenden wir die Layer 2-Anpassung. Informationen zu anderen Anpassungsoptionen finden Sie in der MetalLB-Dokumentation.
Erstellen Sie die Datei metallb-config.yaml in einem beliebigen Verzeichnis innerhalb des ausgewählten IP-Bereichs des Subnetzes unseres Clusters:
control# vi metallb-config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.0.240-192.168.0.250
Und wenden Sie diese Einstellung an:
control# kubectl apply -f metallb-config.yaml
Überprüfen und ändern Sie die Konfigurationskarte später, falls erforderlich:
control# kubectl describe configmaps -n metallb-system control# kubectl edit configmap config -n metallb-system
Jetzt haben wir unseren eigenen konfigurierten lokalen Load Balancer. Lassen Sie uns am Beispiel des Nginx-Dienstes sehen, wie es funktioniert.
control# vi nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 control# vi nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx spec: type: LoadBalancer selector: app: nginx ports: - port: 80 name: http
Erstellen Sie dann eine Testbereitstellung und einen Nginx-Dienst:
control# kubectl apply -f nginx-deployment.yaml control# kubectl apply -f nginx-service.yaml
Und jetzt - überprüfen Sie das Ergebnis:
control# kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107s
Es wurden 3 Nginx-Pods erstellt, wie in der vorherigen Bereitstellung angegeben. Der Nginx-Dienst leitet den Verkehr gemäß dem zyklischen Ausgleichsschema zu all diesen Pods. Sie können auch die externe IP sehen, die von unserem MetalLB-Load-Balancer empfangen wurde.
Versuchen Sie nun, auf die IP-Adresse 192.168.0.240 aufzurollen, und Sie sehen die Seite Nginx index.html. Denken Sie daran, die Testbereitstellung und den Nginx-Dienst zu entfernen.
control# kubectl delete svc nginx service "nginx" deleted control# kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted
Nun, das ist alles mit MetalLB. Fahren wir fort. Wir konfigurieren GlusterFS für Kubernetes-Volumes.
2. Konfigurieren von GlusterFS mit Heketi auf Arbeitsknoten.
Tatsächlich kann der Kubernetes-Cluster nicht ohne darin enthaltene Volumes verwendet werden. Wie Sie wissen, sind Herde kurzlebig, d.h. Sie können jederzeit erstellt und gelöscht werden. Alle darin enthaltenen Daten gehen verloren. In einem realen Cluster ist daher verteilter Speicher erforderlich, um den Austausch von Einstellungen und Daten zwischen Knoten und Anwendungen in diesem Cluster sicherzustellen.
In Kubernetes stehen Volumes auf verschiedene Arten zur Verfügung. Wählen Sie die gewünschten aus. In diesem Beispiel werde ich zeigen, wie GlusterFS-Speicher für interne Anwendungen erstellt wird. Dies ähnelt persistenten Volumes. Früher habe ich dafür die Systeminstallation von GlusterFS auf allen Kubernetes-Arbeitsknoten verwendet und dann einfach Volumes wie hostPath in GlusterFS-Verzeichnissen erstellt.
Jetzt haben wir ein neues handliches Heketi- Tool.
Ein paar Worte aus der Heketi-Dokumentation:
RESTful Volume Management-Infrastruktur für GlusterFS.
Heketi bietet eine RESTful-Verwaltungsschnittstelle, mit der der Lebenszyklus von GlusterFS-Volumes verwaltet werden kann. Dank Heketi können Cloud-Dienste wie OpenStack Manila, Kubernetes und OpenShift GlusterFS-Volumes dynamisch mit jeder unterstützten Zuverlässigkeit bereitstellen. Heketi ermittelt automatisch die Position von Blöcken in einem Cluster und gibt die Position von Blöcken und deren Replikaten in verschiedenen Fehlerbereichen an. Heketi unterstützt auch eine beliebige Anzahl von GlusterFS-Clustern, sodass Cloud-Dienste Online-Dateispeicherung anbieten können, nicht nur einen einzelnen GlusterFS-Cluster.
Es hört sich gut an und außerdem wird dieses Tool unseren VM-Cluster näher an die großen Cloud-Cluster von Kubernetes bringen. Am Ende können Sie PersistentVolumeClaims erstellen, die automatisch generiert werden, und vieles mehr.
Sie können zusätzliche Systemfestplatten verwenden, um GlusterFS zu konfigurieren, oder einfach einige Dummy-Block-Geräte erstellen. In diesem Beispiel werde ich die zweite Methode verwenden.
Erstellen Sie Dummy-Block-Geräte auf allen drei Arbeitsknoten:
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000
Sie erhalten eine Datei mit einer Größe von ca. 10 GB. Verwenden Sie dann losetup , um es diesen Knoten als Loopback-Gerät hinzuzufügen:
worker1-3# losetup /dev/loop0 /home/gluster/image
Bitte beachten Sie: Wenn Sie bereits eine Art Loopback-Gerät 0 haben, müssen Sie eine andere Nummer auswählen.
Ich nahm mir Zeit und fand heraus, warum Heketi nicht richtig arbeiten will. Um Probleme in zukünftigen Konfigurationen zu vermeiden, stellen Sie zunächst sicher, dass wir das Kernelmodul dm_thin_pool geladen und das Paket glusterfs-client auf allen Arbeitsknoten installiert haben.
worker1-3# modprobe dm_thin_pool worker1-3# apt-get update && apt-get -y install glusterfs-client
Nun müssen Sie die Datei / home / gluster / image und das Gerät / dev / loop0 auf allen Arbeitsknoten haben. Denken Sie daran, einen systemd-Dienst zu erstellen, der bei jedem Start dieser Server automatisch losetup und modprobe startet .
worker1-3# vi /etc/systemd/system/loop_gluster.service [Unit] Description=Create the loopback device for GlusterFS DefaultDependencies=false Before=local-fs.target After=systemd-udev-settle.service Requires=systemd-udev-settle.service [Service] Type=oneshot ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image" [Install] WantedBy=local-fs.target
Und schalten Sie es ein:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.
Die Vorbereitungsarbeiten sind abgeschlossen und wir sind bereit, GlusterFS und Heketi in unserem Cluster bereitzustellen. Dafür werde ich diese coole Anleitung verwenden . Die meisten Befehle werden von einem externen Steuercomputer gestartet, und sehr kleine Befehle werden von jedem Masterknoten innerhalb des Clusters gestartet.
Kopieren Sie zunächst das Repository und erstellen Sie DaemonSet GlusterFS:
control# git clone https://github.com/heketi/heketi control# cd heketi/extras/kubernetes control# kubectl create -f glusterfs-daemonset.json
Markieren wir nun unsere drei Arbeitsknoten für GlusterFS. Nach dem Beschriften werden GlusterFS-Pods erstellt:
control# kubectl label node worker1 storagenode=glusterfs control# kubectl label node worker2 storagenode=glusterfs control# kubectl label node worker3 storagenode=glusterfs control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 1m6s glusterfs-hzdll 1/1 Running 0 1m9s glusterfs-p8r59 1/1 Running 0 2m1s
Erstellen Sie jetzt ein Heketi-Dienstkonto:
control# kubectl create -f heketi-service-account.json
Wir bieten für dieses Servicekonto die Möglichkeit, Gluster-Pods zu verwalten. Erstellen Sie dazu eine Clusterfunktion, die für unser neu erstelltes Dienstkonto erforderlich ist:
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
Erstellen wir nun einen geheimen Kubernetes-Schlüssel, der die Konfiguration unserer Heketi-Instanz blockiert:
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.json
Erstellen Sie unter Heketi die erste Quelle, die wir für die ersten Setup-Vorgänge verwenden, und löschen Sie anschließend:
control# kubectl create -f heketi-bootstrap.json service "deploy-heketi" created deployment "deploy-heketi" created control# kubectl get pod NAME READY STATUS RESTARTS AGE deploy-heketi-1211581626-2jotm 1/1 Running 0 2m glusterfs-5dtdj 1/1 Running 0 6m6s glusterfs-hzdll 1/1 Running 0 6m9s glusterfs-p8r59 1/1 Running 0 7m1s
Nach dem Erstellen und Starten des Bootstrap Heketi-Dienstes müssen wir zu einem unserer Hauptknoten wechseln. Dort werden mehrere Befehle ausgeführt, da sich unser externer Steuerknoten nicht in unserem Cluster befindet und wir nicht auf die Arbeits-Pods und das interne Netzwerk des Clusters zugreifen können.
Laden Sie zunächst das Dienstprogramm heketi-client herunter und kopieren Sie es in den Ordner bin system:
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/ master1# heketi-cli heketi-cli v8.0.0
Suchen Sie nun die IP-Adresse des Heketi-Pods und exportieren Sie sie als Systemvariable:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm For me this pod have a 10.42.0.1 ip master1# curl http://10.42.0.1:57598/hello Handling connection for 57598 Hello from Heketi master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598
Lassen Sie uns nun Heketi Informationen über den GlusterFS-Cluster bereitstellen, den es verwalten soll. Wir stellen es über eine Topologiedatei zur Verfügung. Eine Topologie ist ein JSON-Manifest mit einer Liste aller von GlusterFS verwendeten Knoten, Festplatten und Cluster.
HINWEIS kubectl get node Sie sicher, dass hostnames/manage den genauen Namen angibt, wie im Abschnitt kubectl get node , und dass hostnames/storage die IP-Adresse der Speicherknoten ist.
master1:~/heketi-client# vi topology.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "worker1" ], "storage": [ "192.168.0.7" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker2" ], "storage": [ "192.168.0.8" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker3" ], "storage": [ "192.168.0.9" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] } ] } ] }
Dann laden Sie diese Datei herunter:
master1:~/heketi-client# heketi-cli topology load --json=topology.json Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c Adding device /dev/loop0 ... OK Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234 Adding device /dev/loop0 ... OK Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061 Adding device /dev/loop0 ... OK
Als Nächstes verwenden wir Heketi, um Volumes zum Speichern der Datenbank bereitzustellen. Der Teamname ist etwas seltsam, aber alles ist in Ordnung. Erstellen Sie auch ein Heketi-Repository:
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json secret/heketi-storage-secret created endpoints/heketi-storage-endpoints created service/heketi-storage-endpoints created job.batch/heketi-storage-copy-job created
Dies sind alle Befehle, die Sie vom Masterknoten ausführen müssen. Kehren wir zum Steuerknoten zurück und fahren von dort fort. Stellen Sie zunächst sicher, dass der zuletzt ausgeführte Befehl erfolgreich ausgeführt wurde:
control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-storage-copy-job-txkql 0/1 Completed 0 69s
Und der Heketi-Storage-Copy-Job-Job ist erledigt.
Wenn auf Ihren Arbeitsknoten derzeit kein glusterfs-client- Paket installiert ist, tritt ein Fehler auf.
Es ist Zeit, die Heketi Bootstrap-Installationsdatei zu entfernen und eine kleine Bereinigung durchzuführen:
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
In der letzten Phase müssen wir eine langfristige Kopie von Heketi erstellen:
control# cd ./heketi/extras/kubernetes control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json secret/heketi-db-backup created service/heketi created deployment.extensions/heketi created control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-b8c5f6554-knp7t 1/1 Running 0 22m
Wenn auf Ihren Arbeitsknoten derzeit kein glusterfs-client-Paket installiert ist, tritt ein Fehler auf. Und wir sind fast fertig, jetzt ist die Heketi-Datenbank im GlusterFS-Volume gespeichert und wird nicht jedes Mal zurückgesetzt, wenn der Heketi-Herd neu gestartet wird.
Um den GlusterFS-Cluster mit dynamischer Ressourcenzuweisung verwenden zu können, müssen Sie eine StorageClass erstellen.
Lassen Sie uns zunächst den Gluster-Speicherendpunkt suchen, der als Parameter an die StorageClass übergeben wird (heketi-storage-endpoints):
control# kubectl get endpoints NAME ENDPOINTS AGE heketi 10.42.0.2:8080 2d16h ....... ... ..
Erstellen Sie nun einige Dateien:
control# vi storage-class.yml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.2:8080" control# vi test-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: gluster1 annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
Verwenden Sie diese Dateien, um Klasse und PVC zu erstellen:
control# kubectl create -f storage-class.yaml storageclass "slow" created control# kubectl get storageclass NAME PROVISIONER AGE slow kubernetes.io/glusterfs 2d8h control# kubectl create -f test-pvc.yaml persistentvolumeclaim "gluster1" created control# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8h
Wir können auch das PV-Volumen anzeigen:
control# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8h
Wir haben jetzt ein dynamisch erstelltes GlusterFS-Volume, das PersistentVolumeClaim zugeordnet ist , und wir können diese Anweisung in jedem Unterplot verwenden.
Erstellen Sie eine einfache unter Nginx und testen Sie sie:
control# vi nginx-test.yml apiVersion: v1 kind: Pod metadata: name: nginx-pod1 labels: name: nginx-pod1 spec: containers: - name: nginx-pod1 image: gcr.io/google_containers/nginx-slim:0.8 ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster1 control# kubectl create -f nginx-test.yaml pod "nginx-pod1" created
Durchsuchen Sie unter (warten Sie einige Minuten, möglicherweise müssen Sie das Bild herunterladen, falls es noch nicht vorhanden ist):
control# kubectl get pods NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 4d10h glusterfs-hzdll 1/1 Running 0 4d10h glusterfs-p8r59 1/1 Running 0 4d10h heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h nginx-pod1 1/1 Running 0 47h
Gehen Sie nun in den Container und erstellen Sie die Datei index.html:
control# kubectl exec -ti nginx-pod1 /bin/sh # cd /usr/share/nginx/html # echo 'Hello there from GlusterFS pod !!!' > index.html # ls index.html # exit
Sie müssen die interne IP-Adresse des Herdes finden und sich von jedem Masterknoten aus darin einrollen:
master1# curl 10.40.0.1 Hello there from GlusterFS pod !!!
Dabei testen wir einfach unser neues beständiges Volume.
Einige nützliche Befehle zum Auschecken des neuen GlusterFS-Clusters sind: heketi-cli cluster list heketi-cli volume list und heketi-cli volume list . Sie können auf Ihrem Computer ausgeführt werden, wenn heketi-cli installiert ist . In diesem Beispiel ist dies der Knoten master1 .
master1# heketi-cli cluster list Clusters: Id:e83467d0074414e3f59d3350a93901ef [file][block] master1# heketi-cli volume list Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorage
Zu diesem Zeitpunkt haben wir erfolgreich einen internen Load Balancer mit Dateispeicher eingerichtet, und unser Cluster befindet sich jetzt näher am Betriebszustand.
Im nächsten Teil des Artikels konzentrieren wir uns auf die Erstellung eines Clusterüberwachungssystems und starten darin ein Testprojekt, um alle von uns konfigurierten Ressourcen zu nutzen.
Bleiben Sie in Kontakt und alles Gute!