In diesem Artikel werde ich über Minen sprechen, die unter der Aufführung liegen, sowie über ihre Entdeckung (vorzugsweise sogar vor der Explosion) und ihre Räumung.
Ein Bild, um Aufmerksamkeit zu erregen Was ist eine Mine?
Beginnen wir mit dem, was den Ursprüngen eines Wissens zugrunde liegt - mit der Definition. Die Alten sagten, richtig zu benennen bedeutet richtig zu verstehen. Ich denke, dass die Definition einer Mine unter Leistung am besten ausgedrückt wird, indem man sie einem offensichtlichen Fehler gegenüberstellt, zum Beispiel:
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
Selbst unerfahrene Entwickler wissen, dass die Linien unveränderlich sind. Wenn Sie sie in einer Schleife zusammenkleben, bedeutet dies nicht, dass Sie dem Ende einer vorhandenen Linie Daten hinzufügen, sondern mit jedem Durchgang eine neue Linie erstellen. Wenn Sie sich irren, lassen Sie sich nicht entmutigen - die „Idee“ warnt Sie sofort vor der Gefahr, und das „Sonar“ wird Ihre Versammlung mit Sicherheit überfluten.
Dieser Code wird jedoch viel weniger Aufmerksamkeit erregen und die Idee ( vor Version 2018.2 ) wird still sein:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
Das Problem ist hier dasselbe: Die Wrapper für einfache Typen sind unveränderlich, was bedeutet, dass das Hinzufügen von 5 Einheiten zur Objektnummer das Erstellen eines neuen Wrappers und das Schreiben der Nummer 6 bedeutet.
Der Witz hier ist das Vorhandensein von zwei Darstellungen bestimmter Arten von Daten in Java - einfach und objektiv - sowie deren automatische Transformation mittels der Sprache selbst. Aus diesem Grund denken viele unerfahrene Entwickler ungefähr so: "Nun, die Ausführung transformiert sie dort irgendwie von selbst, es ist nur eine Zahl."
In der Tat ist nicht alles so einfach. Nehmen Sie den Benchmark und versuchen Sie, die Zahlen auf die angegebene Weise hinzuzufügen:
Plötzlich kam es sehr, sehr billig heraus (im Folgenden JDK 11, sofern nicht ausdrücklich anders angegeben) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
Vergleichen Sie mit einem einfachen Typ:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
Von hier leiten wir eine der Definitionen von Minen unter Leistung ab - dies ist Code, der nicht ins Auge fällt, von statischen Analysegeräten nicht erkannt wird (zumindest zu dem Zeitpunkt, als Sie darauf gestoßen sind), aber bei einigen Anwendungen langsamer werden kann. In unserem Fall werden, während die Summe 127 nicht überschreitet, Objekte aus dem Cache entnommen und Long nur viermal langsamer als long . Bei einem Array der Größe 100 ist die Geschwindigkeit jedoch fast zehnmal niedriger.
Große kleine Dinge
Manchmal wird eine kleine Änderung, die die Bedeutung der Ausführung fast nicht ändert, unter bestimmten Umständen zu einer starken Bremse.
Angenommen, wir haben einen Code:
Wie sieht die Methodenlogik aus?
Beeilen Sie sich nicht, um zu guckenDies ist ConcurrentHashMap::computeIfAbsent !
Wir haben die "Acht" und können den Code kühl verbessern: Ersetzen Sie 6 Zeilen durch eine, wodurch der Code kürzer und verständlicher wird. Übrigens werden Kenner des Multithreading wahrscheinlich auf eine weitere Verbesserung hinweisen, die ConcurrentHashMap::computeIfAbsent bringt, aber etwas später;)
Lassen Sie uns einen großen Gedanken wahr werden lassen:
Versammelt, angefangen, geweintUm die volle Größe zu sehen, klicken Sie mit der rechten Maustaste auf das Bild und wählen Sie "Bild in neuem Tab öffnen".
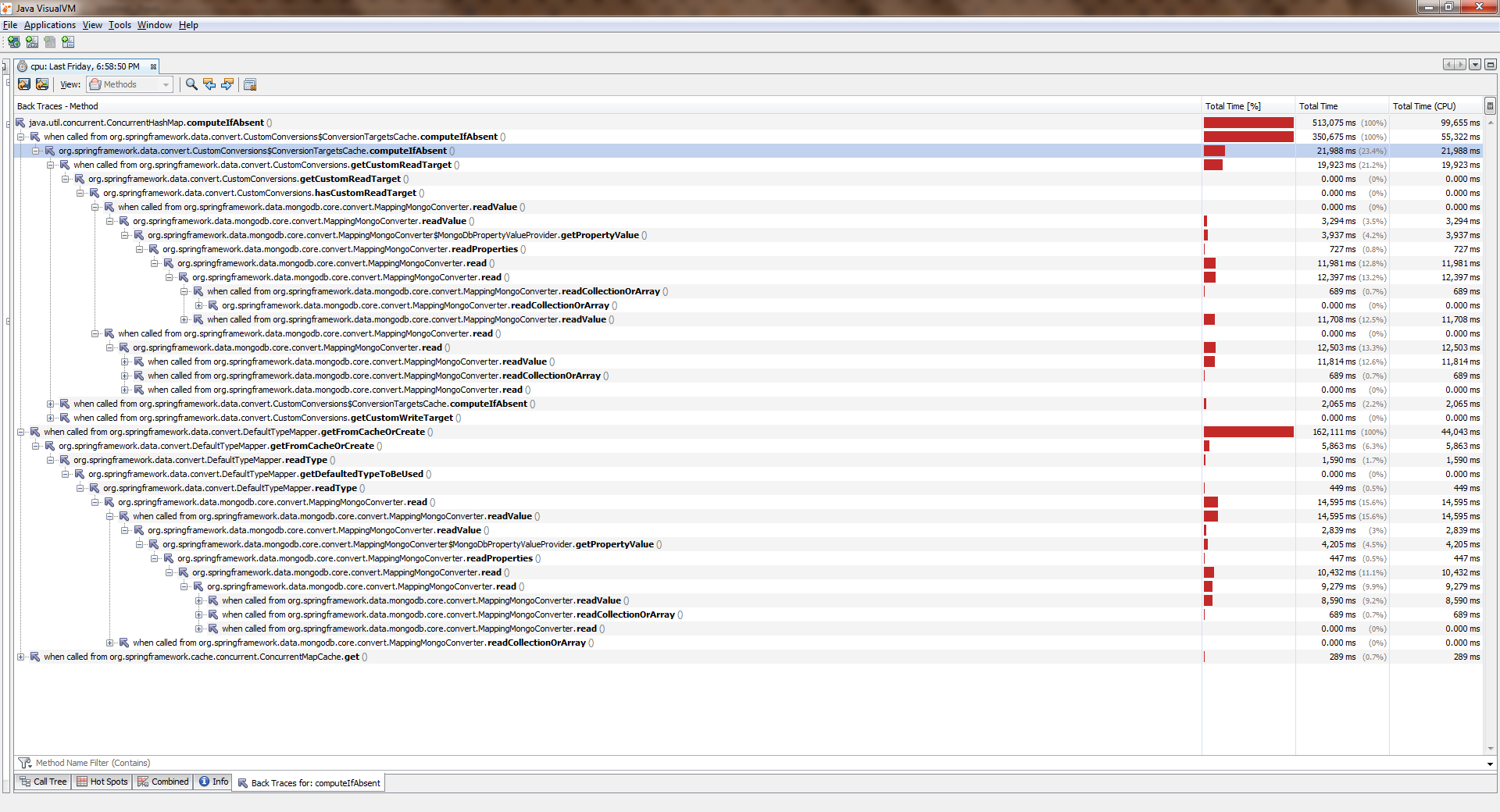
Während die Anwendung mit einem Thread arbeitete, war alles mehr oder weniger gut. Streams wurden mehr und deutlich schlechter. Es ConcurrentHashMap::computeIfAbsent heraus, dass ConcurrentHashMap::computeIfAbsent blockiert ist, auch wenn der Schlüssel bereits zum Wörterbuch hinzugefügt wurde . Und dies wurde der Grund für einen ziemlichen Fehler in Spring Date Mongo.
Sie können dies mit einer einfachen Messung ("acht") überprüfen. Hier ist seine Schlussfolgerung:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
Kann dies von den Entwicklern eindeutig als Fehler angesehen werden? Meiner bescheidenen Meinung nach nein, nein. Die Dokumentation sagt:
Einige versuchte Aktualisierungsvorgänge auf dieser Karte durch andere Threads werden möglicherweise blockiert, während die Berechnung ausgeführt wird. Daher sollte die Berechnung kurz und einfach sein und darf nicht versuchen, andere Zuordnungen dieser Karte zu aktualisieren
Mit anderen Worten, ConcurrentHashMap::computeIfAbsent schließt die Zelle mit dem Schlüssel von außen (im Gegensatz zu ConcurrentHashMap::get ), was im Allgemeinen der Fall ist, da Sie dem Rennen ausweichen können, während Sie eine Methode aus verschiedenen Threads aufrufen, wenn der Schlüssel noch nicht hinzugefügt wurde.
Andererseits erfolgt in der gebräuchlichsten Betriebsart die Berechnung des Wertes und seine Bindung mit dem Schlüssel nur beim ersten Aufruf, und alle nachfolgenden Aufrufe geben nur den zuvor berechneten Wert zurück. Daher ist es sinnvoll, die Logik so zu ändern, dass die Sperre nur beim Ändern gesetzt wird. Es wurde hier gemacht .
In neueren Editionen (> 8) ist ConcurrentHashMap::computeIfAbsent geworden:
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
Achten Sie auf die Hinterlist dieses Beispiels: Der semantische Inhalt hat sich nicht wesentlich geändert, da wir auf den ersten Blick nur eine erweiterte Syntax verwendet haben. Während die Anwendung in einem Thread ausgeführt wird, spürt der Benutzer den Unterschied fast nicht! So scheinbar harmlos verändert sich das Schwein meins unter unserer Leistung.
Warum ich "fast unverändert" schriebConcurrentHashMap::computeIfAbsent nicht immer mit dem Ausdruck getAndPut austauschbar, da ConcurrentHashMap::computeIfAbsent eine atomare Operation ist. Im gleichen Code
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
Aufgrund der fehlenden externen Synchronisation erscheint ein Rennen . Wenn die an ConcurrentHashMap::computeIfAbsent für den angegebenen Schlüssel übergebene Funktion immer denselben Wert zurückgibt, handelt es sich um ein "sicheres" Rennen. Wir müssen höchstens ConcurrentHashMap::computeIfAbsent oder mehrmals denselben Wert berechnen. Wenn es keine solchen Garantien gibt, ist ein mechanischer Ersatz mit einer Aufschlüsselung der Anwendung behaftet. Seid vorsichtig!
Diese Hände haben nichts verändert
Es kommt auch vor, dass sich der Code überhaupt nicht ändert, aber plötzlich langsamer wird.
Stellen Sie sich vor, wir stehen vor der Aufgabe, die Elemente eines Arrays in eine Sammlung zu verschieben. Am logischsten wäre es, die vorgefertigte Collection::addAll , aber hier ist das Pech - sie akzeptiert die Sammlung:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
Am einfachsten ist es, das Array in Arrays::asList . Es wird sich so etwas herausstellen
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
Während des Korrekturlesens werden uns leistungsbewusste Kollegen wahrscheinlich mitteilen, dass dieser Code gleichzeitig zwei Probleme aufweist:
- Einschließen eines Arrays in eine Liste (zusätzliches Objekt)
- Erstellen eines Iterators (ein weiteres zusätzliches Objekt) und Durchlaufen
In der Referenzimplementierung von Collection::addAll wir Collection::addAll :
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
Hier wird also ein Iterator erstellt und die Elemente damit sortiert. Erfahrene Genossen bieten daher ihre Lösung an:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Im Code zu Recht produktiver:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
Erstens wird kein Iterator erstellt. Zweitens verläuft der Durchlauf im üblichen Zählzyklus. Außerdem passen die Arrays gut in die Caches, ihre Elemente befinden sich nacheinander im Speicher (was bedeutet, dass nur wenige Cache-Fehler auftreten), und der Zugriff per Index ist sehr schnell. Nun, eine Wrapper-Liste wird auch nicht erstellt. Es klingt gut und klingt.
Schließlich zitieren Kollegen Ultima Ratio Regum: Dokumentation. Und dort sagt Grau auf Weiß (oder Grün auf Schwarz):
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
Das heißt, die Entwickler selbst (und wem sollten sie glauben, wenn nicht ihnen?) Schreiben Sie, dass die Dienstprogrammmethode für die meisten Implementierungen viel schneller funktioniert. Und er ist wirklich schneller. Manchmal.
Der Benchmark , den wir für das HashSet auf dem G8 starten werden, wird dazu beitragen, HashSet zu HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
Es scheint, dass die erfahreneren Kameraden Recht hatten. Fast.
In späteren Ausgaben (zum Beispiel in 11) wird die Brillanz der Utility-Methode etwas nachlassen:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
Es ist zu sehen, dass es sich nicht um eine "viel schnellere" handelt. Und wenn wir das Experiment für ArrayList -a wiederholen, stellt sich heraus, dass die Utility-Methode viel verliert (je weiter desto stärker):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
Hier gibt es nichts Unerwartetes. ArrayList auf einem Array. Collection::addAll haben die Entwickler die Collection::addAll weitsichtig neu definiert:
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
Nun zurück zu unseren Minen. Angenommen, wir haben die beim Korrekturlesen vorgeschlagene Lösung dennoch akzeptiert und diesen Code belassen:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Im Moment ist alles in Ordnung, aber nach dem Hinzufügen neuer Funktionen wird die Methode manchmal heiß und verlangsamt sich. Wir öffnen Quellcodes - der Code hat sich nicht geändert. Die Datenmenge ist gleich. Und die Leistung sank sehr. Dies ist eine andere Art von mir.
Entdecken Sie den Debugger und finden Sie das Schöne:

Bitte beachten Sie: Wir haben den Algorithmus nicht geändert, die Menge der verarbeiteten Daten hat sich nicht geändert, aber ihre Art hat sich geändert und ein Leistungsproblem ist in unserem Code aufgetreten:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
Bei großen Arrays Collections::addAll der Unterschied zwischen Collections::addAll und Collection::addAll 500-mal bescheidene Collection::addAll . Tatsache ist, dass COWList nicht nur das vorhandene Array erweitert, sondern jedes Mal, wenn Elemente hinzugefügt werden, ein neues erstellt:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
Wer ist schuld?
Das Hauptproblem hierbei ist, dass die Collections::addAll eine Schnittstelle akzeptiert, während die addAll Methode keinen Body hat. Kein Körper - kein Geschäft, daher basiert die Dokumentation auf der Implementierung in AbstractCollection::addAll , einem verallgemeinerten Algorithmus, der für alle Sammlungen gilt. Dies bedeutet, dass spezifischere Implementierungen von Datenstrukturen, die sich auf einer niedrigeren Abstraktionsebene befinden, dieses Verhalten ändern können.
Jetzt menschlich Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
Mehr über Abstraktionen
Da wir über die Abstraktionsebenen sprechen, erzähle ich Ihnen ein Beispiel aus dem Leben.
Vergleichen wir diese beiden Möglichkeiten zum Speichern der n-ten Anzahl von Entitäten in der Datenbank:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
Auf den ersten Blick sollte die Leistung beider Methoden nicht sehr unterschiedlich sein, weil
- In beiden Fällen wird die gleiche Anzahl von Entitäten in der Datenbank gespeichert
- Wenn die Taste aus der Sequenz entnommen wird, ist die Anzahl der Anrufe gleich
- Die übertragene Datenmenge ist gleich
SimpleJpaRepository::saveAndFlush an die SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
Der dunkle Fleck hier ist die flush() -Methode. Warum dumm? Es scheint mir, dass die Offenlegung in der JpaRepository Oberfläche ein Entwicklerfehler war. Ich werde versuchen, meinen Gedanken zu rechtfertigen. In der Regel wird diese Methode vom Entwickler überhaupt nicht verwendet, da der Aufruf von EntityManager::flush an den Abschluss einer von Spring kontrollierten Transaktion gebunden EntityManager::flush :
Bitte beachten Sie: EntityManager ist Teil der JPA Spezifikation, die in Hibernate als Sitzung implementiert ist (Sitzungsschnittstelle bzw. SessionImpl-Klasse). Spring Date ist ein Framework, das auf einem ORM ausgeführt wird, in diesem Fall auf Hibernate. Es stellt sich heraus, dass die JpaRepository::saveAndFlush uns Zugriff auf die unteren Ebenen der API gewährt, obwohl das Framework die Aufgabe hat, die Details auf niedriger Ebene auszublenden (die Situation ähnelt in gewisser Weise der unsicheren Story im JDK).
In unserem Fall gelangen wir bei Verwendung von JpaRepository::saveAndFlush in die unteren Ebenen der Anwendung und brechen dadurch etwas.
Nehmen Sie sich Zeit für einen Blick, denken Sie selbstDie Fähigkeit von Hibernate, Daten jdbc.batch_size zu senden, ist jdbc.batch_size ist ein Vielfaches der Einstellung jdbc.batch_size , die in application.yml :
spring: jpa: properties: hibernate: jdbc.batch_size: 500
Die Arbeit von Hibernate basiert auf Ereignissen. Wenn Sie also 1000 Entitäten wie diese speichern
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
Das Aufrufen von repository.save(e) wird nicht sofort repository.save(e) . Stattdessen wird ein Ereignis erstellt, das sich in der Warteschlange befindet. Nach Abschluss der Transaktion werden die Daten mit EntityManager::flush , wodurch die Einfügungen / Aktualisierungen in mehrere Bündel von jdbc.batch_size und Anforderungen daraus erstellt werden. In unserem Fall bedeutet jdbc.batch_size: 500 , dass das Speichern von 1000 Entitäten in der Realität nur 2 Anforderungen bedeutet.
Aber mit einer manuellen Entladung der Sitzung bei jedem Durchgang des Zyklus
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
Die Warteschlange wird gelöscht und das Speichern von 1000 Entitäten bedeutet 1000 Abfragen.
Eine Störung der unteren Schichten der Anwendung kann daher leicht zu einer Mine und nicht nur zu einer Produktivitätsmine werden (siehe Unsicher und ihre unkontrollierte Verwendung).
Wie viel verlangsamt es sich? Nehmen Sie den besten Fall (für uns) - die Datenbank befindet sich auf demselben Host wie die Anwendung. Meine Messung zeigt folgendes Bild:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
Wenn sich die Datenbank auf einem Remote-Host befindet, werden die Kosten für die Datenübertragung mit zunehmendem Datenvolumen offensichtlich immer schlechter.
Wenn Sie also auf der falschen Abstraktionsebene arbeiten, kann dies leicht zu einer Zeitbombe führen. Übrigens habe ich in einem meiner vorherigen Artikel über einen merkwürdigen Versuch gesprochen, StringBuilder -a zu verbessern: Dort war ich nur erfolglos, als ich versuchte, in eine abstraktere Codeebene zu gelangen.
Minenfeldgrenzen
Lass uns einen Pionier spielen? Finde meine:
Gefunden? Überprüfen Sie die richtige Antwort. "Willst du mich veräppeln?", Ruft der Kritiker aus. "Aber gibt es nur ein Kleben von zwei Linien? Was bedeutet das in blutigem E.?" Lassen Sie mich Ihre Aufmerksamkeit auf die Tatsache lenken, dass ich nicht nur das Verkleben von Zeichenfolgen hervorgehoben habe, sondern auch den Namen der Klasse und den Namen der Methode. In der Tat besteht die Gefahr des Klebens von Zeichenfolgen nicht darin, sich selbst zu kleben, sondern in dem, was in der Methode geschieht, die die Schlüssel für den Cache erstellt, d. H. In bestimmten Szenarien haben wir viele Zugriffe auf diese Methode, was viele Müllzeilen bedeutet.
Daher sollte eine Fehlermeldung nur erstellt werden, wenn dieser Fehler tatsächlich ausgelöst wird:
Minenfelder haben also Grenzen - dies ist die Datenmenge, die Häufigkeit des Zugriffs auf die Methode usw. Quantitative Indikatoren bei Erreichen und Überschreiten, bei denen ein geringfügiger Nachteil statistisch signifikant wird.
Auf der anderen Seite ist dies das Merkmal, an dessen Schnittpunkt die Komplikation des Codes keine signifikante (messbare) Verbesserung ergibt.
Dies ist eine weitere Schlussfolgerung für den Entwickler: In den meisten Fällen ist Täuschung böse, was zu einer bedeutungslosen Komplikation des Codes führt. In 99 von 100 Fällen gewinnen wir nichts.
Es sollte daran erinnert werden, dass es immer gibt
Der einhundertste Fall
Hier ist der Code, den Nitzan Wakart in seinem Artikel The volatile read überraschend gibt :
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
Wenn wir die Erfahrung einrichten, werden wir einen erstaunlichen Unterschied zwischen den beiden Möglichkeiten entdecken, über ein Array zu iterieren:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Hier kann ein unerfahrener Entwickler eine so offensichtliche und Benchmark-Schlussfolgerung ziehen: Das Durchlaufen eines Arrays mit der neuen Syntax funktioniert schneller als ein Zählzyklus. Dies ist die falsche Schlussfolgerung, da es sich lohnt, die goodOldLoop Methode ein goodOldLoop zu ändern:
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
und seine Leistung ist vergleichbar mit der der "schnelleren" sweetLoop Methode:
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? Richtig? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .