Kann man anhand eines Zitats feststellen, welcher der Politiker der Autor ist? Die ukrainische NGO
Vox Ukraine führt das
VoxCheck- Projekt durch, in dessen Rahmen sie die Aussagen der am besten bewerteten Politiker überprüft. Kürzlich haben sie die gesamte
Datenbank verifizierter Angebote veröffentlicht . Ich höre gerade NLP-Kurse und habe mich entschlossen zu prüfen, wie genau der Autor anhand des Zitattextes identifiziert werden kann.
Haftungsausschluss . Dieser Artikel wurde aus dem Interesse an dem Thema und dem Wunsch heraus geschrieben, das in der Praxis untersuchte Material auszuprobieren, ohne die genaueste und detaillierteste Analyse zu beanspruchen.
Für die Analyse wurde Python verwendet, der Code ist auf
Github verfügbar.
Daten
Die Datenbank enthält jetzt 1952 Anführungszeichen mit der folgenden Verteilung nach Richtlinien:
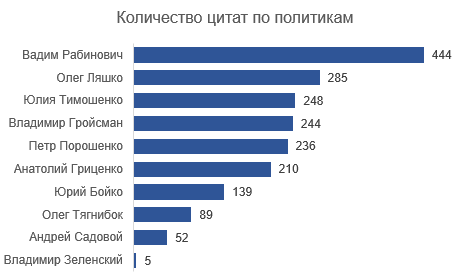
Zu Analysezwecken habe ich Personen mit> 200 Zitaten ausgewählt. Dementsprechend fielen Yuri Boyko, Oleg Tyagnibok, Andrey Sadovoy und Vladimir Zelensky aus der Analyse heraus. Das Array enthält noch 1.667 Zitate. Von den sechs verbleibenden Rednern sind vier (außer Groysman und Rabinovich) registrierte Kandidaten für die nächsten Präsidentschaftswahlen.
Die Zitate variieren von kurzen, ungefähr 30 Zeichen (
„Ich habe bereits 112 Rechnungen eingereicht.“ ) Bis zu langen, ungefähr 1.200 Zeichen. Die durchschnittliche Länge eines Zitats beträgt etwa 200 Zeichen (zum Beispiel:
„Bald müssen wir einer Kuh etwas weniger für ein Museum und einen Dinosaurier für Kinder in der Naturwissenschaft geben - als Ergebnis der politischen Politik, damit Yak einen Anfängeraufenthalt durchführt. Vieh weniger als 2 Monate . " )
TF-IDF
Lassen Sie uns zunächst sehen, welche Wörter für bestimmte Sprecher charakteristischer sind. Hier sind die Top 10 Wörter mit der höchsten TF-IDF für jeden Kandidaten:

Kurz über TF-IDFTF-IDF (Termhäufigkeit - inverse Dokumenthäufigkeit) ist ein Indikator, der die Bedeutung eines Wortes im Kontext eines Dokuments bewertet. TF-IDF-Wörter sind proportional zur Häufigkeit der Verwendung dieses Wortes im Dokument und umgekehrt proportional zur Häufigkeit der Verwendung des Wortes in allen Dokumenten der Sammlung. Im Kontext unserer Daten bedeutet eine hohe TF-IDF, dass ein Politiker dieses Wort häufig verwendet, während andere Politiker es relativ selten verwenden.
Um TF-IDF zu zählen, wurde Stemming verwendet, um das Wort zur Basis zu bringen.
Die Wörter, die ich für jeden Redner kommentieren möchte, um einen kleinen Kontext zu geben, sind grün hervorgehoben.
Oleg Lyashko:- Polen: Lyashko erwähnt Polen häufig im Zusammenhang mit der Arbeitsmigration der Ukrainer und vergleicht auch die Einkommen in Polen und der Ukraine
- Getreide: Laut Lyashko exportiert die Ukraine Getreide und verliert daran, weil der Export von Mehl teurer sein könnte
- Onkologie, Medikamente: Lyashko ist ein leidenschaftlicher Gegner der aktuellen medizinischen Reform und sagt oft, dass die Kosten für die Onkologie fast nicht vom Staat übernommen werden
Poroschenko und
Gritsenko sprechen viel über den militärischen Konflikt, was ziemlich logisch ist: Poroschenko ist der Präsident und dementsprechend der Oberbefehlshaber, und Gritsenko ist Militär und war der Verteidigungsminister.
Groisman ist der Premierminister und spricht hauptsächlich über die Wirtschaft, einschließlich der Staatsverschuldung.
Vadim Rabinovichs Zitate zeigen keine spezifischen Themen, vielleicht weil er viel spricht (444 von 1952, alle anderen haben weniger als 300 Zitate).
Julia Timoschenko spricht viel über das Gasfernleitungsnetz der Ukraine, über die Liquidation von Banken sowie über die niedrigen Wirtschaftsindikatoren des Landes.
Zitat Klassifizierung
Wir bekommen also 6 Klassen (Sprecher). Für die Klassifizierung habe ich den naiven Bayes'schen Klassifikator verwendet. Stoppwörter in russischer und ukrainischer Sprache werden aus dem Text ausgeschlossen (mithilfe des Stoppwortpakets). N-Gramm bis zu 2 sind enthalten (Optionen mit einer Länge von bis zu 3 wurden ebenfalls getestet, zeigten jedoch eine Überanpassung). Die Testprobe wird zu 20% entnommen.
Die Gesamtgenauigkeit des Modells (der Anteil korrekt klassifizierter Zitate) in der Trainingsstichprobe betrug
74,8% , in der Teststichprobe
75,7%Kreuzergebnisse von Autoren:

Die höchste Genauigkeit für Vadim Rabinovich (97%) - höchstwahrscheinlich, weil er der einzige von sechs russischen Sprechern ist. Hohe Klassifizierungsgenauigkeit von Groisman und Lyashko (78% und 77%).
Etwas höher als 60% sind die Genauigkeitsindikatoren für die Angabe von Poroschenko und Timoschenko. Das Modell definiert beide häufiger als Groysman. Groysman spricht als Premierminister häufig in Form eines „Fortschrittsberichts“ über das Thema Wirtschaft, und auch falsch klassifizierte Zitate von Poroschenko und Timoschenko befassen sich damit (nur Poroschenko als Vertreter der Regierung ist positiv, und Timoschenko hat das Gegenteil).
Hier ist zum Beispiel ein Zitat von Poroschenko, das vom Modell als Zitat von Groisman definiert wird:
5 Milliarden UAH, (tobto) 4 Milliarden UAH dieses Gesteins und 1 Milliarde UAH des gesamten Gesteins direkt für die MedizinUnd auch ein Zitat von Timoschenko, definiert als ein Zitat von Groisman:
Im offensiven Budget für die Nutzung von Gefängnissen sahen sie doppelt so wenig, nicht weniger als die Wissenschaft, um an der Akademie der Wissenschaften der Ukraine zu arbeiten.Die niedrigste Genauigkeit (57%) in Zitaten von Anatoly Gritsenko. Sein Modell wird oft als Poroschenko (was angesichts der militärischen Themen ihrer Zitate logisch ist) sowie als Lyaschko definiert. Im Fall von Lyashko ist die falsche Klassifizierung ein Zitat, das die Behörden kritisiert, einschließlich beispielsweise der Migration:
Ich spreche nicht über dasselbe Mitglied Ihres Ordens, Volodimir Borisovich, pan Klimkin, der sagt, dass Millionen das Land verlassen haben.Im Allgemeinen scheint mir das Ergebnis für solche kurzen Zitate eines ähnlichen Formats (mündliche Erklärungen von Politikern) und Themen (ukrainische Politik) nicht schlecht zu sein. Übrigens habe ich mit denselben Daten versucht, ein Modell zu erstellen, das die Kategorie des Zitats definiert (wahr / falsch / Manipulation), aber die Genauigkeit war sehr gering. Was im Prinzip logisch ist: Wenn man sich ein Zitat wie "So viel Geld wurde dafür ausgegeben, aber in einem solchen Land geben sie so viel aus" ansieht, ist es schwierig, die Richtigkeit der darin enthaltenen Daten zu bestimmen :)