
Apache Spark ist heute vielleicht die beliebteste Plattform für die Analyse großer Datenmengen. Ein wesentlicher Beitrag zu seiner Popularität wird durch die Möglichkeit geleistet, es unter Python zu verwenden. Gleichzeitig sind sich alle einig, dass im Rahmen der Standard-API die Leistung von Python- und Scala / Java-Code vergleichbar ist, es jedoch keine einheitliche Sichtweise in Bezug auf benutzerdefinierte Funktionen (User Defined Function, UDF) gibt. Versuchen wir am Beispiel der Aufgabe, die SNA Hackathon 2019- Lösung zu überprüfen, herauszufinden, wie sich die Gemeinkosten in diesem Fall erhöhen.
Im Rahmen des Wettbewerbs lösen die Teilnehmer das Problem, den Newsfeed eines sozialen Netzwerks zu sortieren und Lösungen in Form einer Reihe sortierter Listen hochzuladen. Um die Qualität der erhaltenen Lösung zu überprüfen, wird zuerst für jede der geladenen Listen die ROC-AUC berechnet und dann der Durchschnittswert angezeigt. Bitte beachten Sie, dass Sie nicht eine gemeinsame ROC-AUC berechnen müssen, sondern eine persönliche für jeden Benutzer. Es gibt kein fertiges Design zur Lösung dieses Problems, daher müssen Sie eine spezielle Funktion schreiben. Ein guter Grund, die beiden Ansätze in der Praxis zu vergleichen.
Als Vergleichsplattform werden wir einen Cloud-Container mit vier Kernen und Spark verwenden, der im lokalen Modus gestartet wird, und wir werden über Apache Zeppelin damit arbeiten . Um die Funktionalität zu vergleichen, spiegeln wir denselben Code in PySpark und Scala Spark. [hier] Beginnen wir mit dem Laden der Daten.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
Bei Verwendung der Standard-API ist die fast vollständige Identität des Codes bis zum Schlüsselwort val bemerkenswert. Die Betriebszeit unterscheidet sich nicht wesentlich. Versuchen wir nun, die benötigte UDF zu ermitteln.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
Bei der Implementierung einer bestimmten Funktion ist klar, dass Python präziser ist, vor allem aufgrund der Möglichkeit, die integrierte Scikit-Lernfunktion zu verwenden. Es gibt jedoch unangenehme Momente - Sie müssen den Typ des Rückgabewerts explizit angeben, während er in Scala automatisch ermittelt wird. Lassen Sie uns die Operation ausführen:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
Der Code sieht fast identisch aus, aber die Ergebnisse sind entmutigend.

Die Implementierung in PySpark hat eineinhalb Minuten statt zwei Sekunden in Scala geklappt, dh Python war 45-mal langsamer . Während der Ausführung werden oben 4 aktive Python-Prozesse angezeigt, die mit voller Geschwindigkeit ausgeführt werden. Dies deutet darauf hin, dass die globale Interpreter-Sperre hier keine Probleme verursacht. Aber! Vielleicht liegt das Problem in der internen Implementierung von scikit-learn - versuchen wir, den Python-Code buchstäblich zu reproduzieren, ohne auf Standardbibliotheken zurückzugreifen.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

Das Experiment zeigt interessante Ergebnisse. Einerseits wurde mit diesem Ansatz die Produktivität gesteigert, andererseits verschwand der Lakonismus. Die erhaltenen Ergebnisse können darauf hinweisen, dass bei der Arbeit in Python mit zusätzlichen C ++ - Modulen ein erheblicher Aufwand für den Wechsel zwischen Kontexten auftritt. Natürlich gibt es einen ähnlichen Overhead bei der Verwendung von JNI in Java / Scala, aber ich musste mich bei der Verwendung nicht 45-mal mit Beispielen für eine Verschlechterung befassen.
Für eine detailliertere Analyse werden wir zwei zusätzliche Experimente durchführen: Verwenden von reinem Python ohne Spark, um den Beitrag des Paketaufrufs zu messen, und mit einer erhöhten Datengröße in Spark, um den Overhead zu amortisieren und einen genaueren Vergleich zu erhalten.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
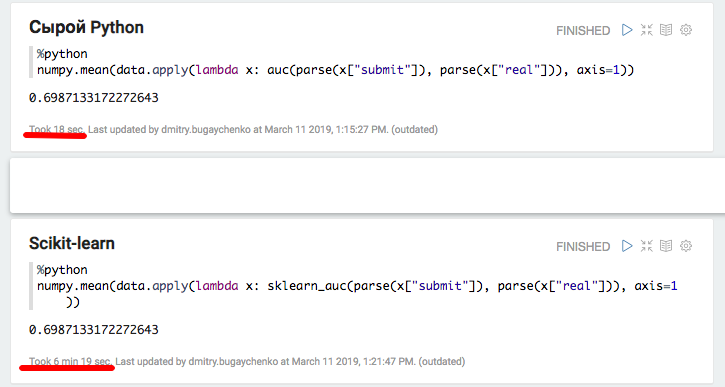
Das Experiment mit lokalem Python und Pandas bestätigte die Annahme eines erheblichen Overheads bei Verwendung zusätzlicher Pakete - bei Verwendung von Scikit-Learn verringert sich die Geschwindigkeit um mehr als das 20-fache. 20 ist jedoch nicht 45 - versuchen wir, die Daten aufzublasen und die Spark-Leistung erneut zu vergleichen.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

Der neue Vergleich zeigt den Geschwindigkeitsvorteil einer Scala-Implementierung gegenüber Python um das 7- bis 8-fache - 7 Sekunden gegenüber 55. Schließlich versuchen wir "die schnellste in Python" - numpy , um die Summe des Arrays zu berechnen:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
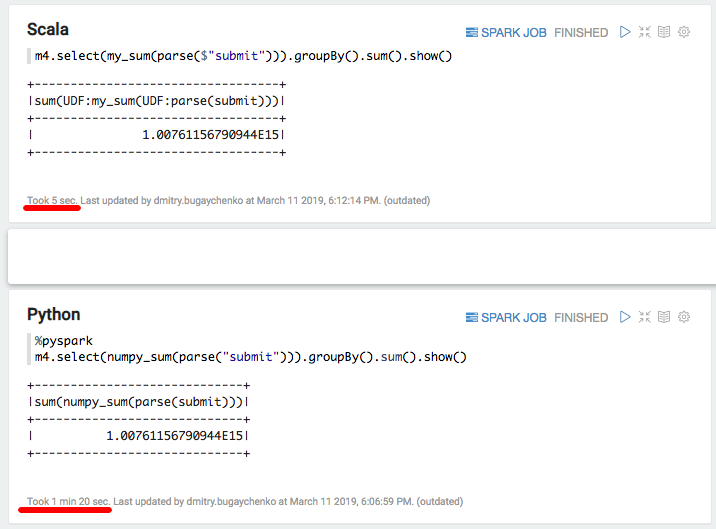
Wieder eine deutliche Verlangsamung - 5 Sekunden Scala gegenüber 80 Sekunden Python. Zusammenfassend können wir folgende Schlussfolgerungen ziehen:
- Während PySpark im Rahmen der Standard-API arbeitet, kann es in seiner Geschwindigkeit wirklich mit Scala vergleichbar sein.
- Wenn eine bestimmte Logik in Form von benutzerdefinierten Funktionen angezeigt wird, nimmt die PySpark-Leistung spürbar ab. Wenn bei ausreichenden Informationen die Verarbeitungszeit eines Datenblocks mehrere Sekunden überschreitet, ist die Python-Implementierung 5-10 langsamer, da bei der Interpretation von Python Daten zwischen Prozessen verschoben und Ressourcen verschwendet werden müssen.
- Wenn die Verwendung zusätzlicher Funktionen in C ++ - Modulen implementiert wird, entstehen zusätzliche Aufrufkosten, und der Unterschied zwischen Python und Scala erhöht sich um das 10- bis 50-fache.
Trotz des Charmes von Python erscheint die Verwendung in Verbindung mit Spark daher nicht immer gerechtfertigt. Wenn es nicht so viele Daten gibt, die den Python-Overhead signifikant machen, sollten Sie sich überlegen, ob hier Spark benötigt wird. Wenn viele Daten vorhanden sind, die Verarbeitung jedoch im Rahmen der Standard-Spark-SQL-API erfolgt, wird Python hier benötigt?
Wenn viele Daten vorhanden sind und häufig Aufgaben ausgeführt werden müssen, die über die Grenzen der SQL-API hinausgehen, müssen Sie den Cluster zeitweise vergrößern, um bei Verwendung von PySpark dieselbe Menge an Arbeit auszuführen. Für Odnoklassniki würden sich beispielsweise die Investitionskosten für den Spark-Cluster um viele hundert Millionen Rubel erhöhen. Wenn Sie versuchen, die erweiterten Funktionen der Python-Ökosystembibliotheken zu nutzen, besteht das Risiko einer Verlangsamung nicht nur zuweilen, sondern um eine Größenordnung.
Eine gewisse Beschleunigung kann unter Verwendung der relativ neuen Funktionalität von vektorisierten Funktionen erhalten werden. In diesem Fall wird nicht eine einzelne Zeile dem UDF-Eingang zugeführt, sondern ein Paket aus mehreren Zeilen in Form eines Pandas-Datenrahmens. Die Entwicklung dieser Funktionalität ist jedoch noch nicht abgeschlossen , und selbst in diesem Fall wird der Unterschied erheblich sein .
Eine Alternative wäre die Aufrechterhaltung eines umfangreichen Teams von Dateningenieuren, die in der Lage sind, die Anforderungen von Datenwissenschaftlern mit zusätzlichen Funktionen schnell zu erfüllen. Oder um in die Scala-Welt einzutauchen, da es nicht so schwierig ist: Viele der erforderlichen Tools sind bereits vorhanden. Es erscheinen Schulungsprogramme , die über PySpark hinausgehen.