Hallo Habr! Ich mache Sie auf eine Übersetzung des Artikels
„Top 20 C ++ - Multithreading-Fehler und wie man sie vermeidet“ von Deb Haldar aufmerksam.
“") Szene aus dem Film „The Loop of Time“ (2012)
Szene aus dem Film „The Loop of Time“ (2012)Multithreading ist einer der schwierigsten Bereiche in der Programmierung, insbesondere in C ++. Im Laufe der Jahre der Entwicklung habe ich viele Fehler gemacht. Glücklicherweise wurden die meisten von ihnen durch Überprüfungscode und Tests identifiziert. Trotzdem sind einige irgendwie auf die Produktivität gerutscht, und wir mussten die Betriebssysteme bearbeiten, was immer teuer ist.
In diesem Artikel habe ich versucht, alle mir bekannten Fehler mit möglichen Lösungen zu kategorisieren. Wenn Sie andere Fallstricke kennen oder Vorschläge zur Behebung der beschriebenen Fehler haben, hinterlassen Sie bitte Ihre Kommentare unter dem Artikel.
Fehler Nr. 1: Verwenden Sie join () nicht, um auf Hintergrundthreads zu warten, bevor Sie die Anwendung beenden
Wenn Sie vergessen, dem Stream
beizutreten (
join () ) oder ihn zu trennen (trennen
() ) (nicht zu verbinden), bevor das Programm beendet wird, führt dies zum Absturz. (Die Übersetzung enthält die Wörter "join" im Kontext von "
join") und "
separ" im Kontext von "
attach ()" , obwohl dies nicht ganz korrekt ist. Tatsächlich ist "
join ()" der Punkt, an dem ein Ausführungsthread auf den Abschluss eines anderen wartet und kein Verbinden oder Zusammenführen von Threads erfolgt [Kommentarübersetzer]).
Im folgenden Beispiel haben wir vergessen,
join () von Thread t1 im Hauptthread auszuführen:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
//t1.join(); // join-
return 0 ;
}Warum ist das Programm abgestürzt ?! Da am Ende der Funktion
main () die Variable t1 den Gültigkeitsbereich verlassen hat und der Thread-Destruktor aufgerufen wurde. Der Destruktor prüft, ob der Thread t1
verbunden werden kann . Ein Thread kann
verbunden werden, wenn er nicht getrennt wurde. In diesem Fall wird
std :: terminate in seinem Destruktor aufgerufen. Folgendes macht beispielsweise der MSVC ++ - Compiler.
~thread ( ) _NOEXCEPT
{ // clean up
if ( joinable ( ) )
XSTD terminate ( ) ;
}
Je nach Aufgabe gibt es zwei Möglichkeiten, das Problem zu beheben:
1. Rufen Sie
join () von Thread t1 im Hauptthread auf:
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. join ( ) ; // join t1,
return 0 ;
}
2. Trennen Sie den Stream t1 vom Hauptstream und lassen Sie ihn weiterhin als "dämonisierten" Stream arbeiten:
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ; // t1
return 0 ;
}Fehler Nr. 2: Es wurde versucht, einen zuvor gelösten Thread anzuhängen
Wenn Sie irgendwann in der Arbeit des Programms einen getrennten Stream haben, können Sie ihn nicht wieder an den Haupt-Stream anhängen. Dies ist ein sehr offensichtlicher Fehler. Das Problem ist, dass Sie den Stream entfernen und dann einige hundert Codezeilen schreiben und versuchen können, ihn erneut anzuhängen. Wer erinnert sich denn daran, dass er 300 Zeilen zurückgeschrieben hat?
Das Problem ist, dass dies keinen Kompilierungsfehler verursacht, sondern das Programm beim Start abstürzt. Zum Beispiel:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
t1. join ( ) ; // CRASH !!!
return 0 ;
}
Die Lösung besteht darin, den Thread immer auf
joinable () zu überprüfen, bevor Sie versuchen, ihn an den aufrufenden Thread anzuhängen.
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
if ( t1. joinable ( ) )
{
t1. join ( ) ;
}
return 0 ;
}
Fehler Nr. 3: Missverständnis, dass std :: thread :: join () den aufrufenden Ausführungsthread blockiert
In realen Anwendungen müssen Sie häufig „langwierige“ Vorgänge bei der Verarbeitung von Netzwerk-E / A trennen oder darauf warten, dass ein Benutzer auf eine Schaltfläche usw. klickt. Ein Aufruf von
join () für solche Workflows (z. B. der UI-Rendering-Thread) kann dazu führen, dass die Benutzeroberfläche hängen bleibt. Es gibt geeignetere Implementierungsmethoden.
Beispielsweise kann in GUI-Anwendungen ein Arbeitsthread nach Abschluss eine Nachricht an den UI-Thread senden. Der UI-Stream verfügt über eine eigene Ereignisverarbeitungsschleife, z. B.: Bewegen der Maus, Drücken von Tasten usw. Diese Schleife kann auch Nachrichten von Arbeitsthreads empfangen und darauf antworten, ohne die blockierende
join () -Methode aufrufen zu müssen.
Aus diesem Grund werden fast alle Benutzerinteraktionen in der
WinRT- Plattform von Microsoft asynchronisiert, und synchrone Alternativen sind nicht verfügbar. Diese Entscheidungen wurden getroffen, um sicherzustellen, dass Entwickler die API verwenden, die die bestmögliche Endbenutzererfahrung bietet. Weitere Informationen zu diesem Thema finden Sie im Handbuch „
Moderne C ++ - und Windows Store-Apps “.
Fehler Nr. 4: Angenommen, Stream-Funktionsargumente werden standardmäßig als Referenz übergeben
Die Argumente an die Stream-Funktion werden standardmäßig als Wert übergeben. Wenn Sie Änderungen an den übergebenen Argumenten vornehmen müssen, müssen Sie diese mithilfe der Funktion
std :: ref () als Referenz übergeben.
Unter dem Spoiler finden Sie Beispiele aus einem anderen
C ++ 11-Artikel zum Multithreading-Tutorial über Fragen und Antworten - Grundlagen der Thread-Verwaltung (Deb Haldar) , in dem die Parameterübergabe [ca. Übersetzer].
Weitere Details:Bei der Ausführung des Codes:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, targetCity ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
Es wird im Terminal angezeigt:
Changing The Target City To Metropolis
Current Target City is Star City
Wie Sie sehen können, hat sich der Wert der targetCity- Variablen, die von der im Stream als Referenz aufgerufenen Funktion empfangen wurde, nicht geändert.
Schreiben Sie den Code mit std :: ref () neu , um das Argument zu übergeben:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, std :: ref ( targetCity ) ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
Es wird ausgegeben:
Changing The Target City To Metropolis
Current Target City is Metropolis
Im neuen Thread vorgenommene Änderungen wirken sich auf den Wert der in der Hauptfunktion deklarierten und initialisierten targetCity- Variablen aus.
Fehler Nr. 5: Schützen Sie gemeinsam genutzte Daten und Ressourcen nicht mit einem kritischen Abschnitt (z. B. einem Mutex).
In einer Umgebung mit mehreren Threads konkurrieren normalerweise mehr als ein Thread um Ressourcen und gemeinsam genutzte Daten. Dies führt häufig zu einem unsicheren Zustand für Ressourcen und Daten, es sei denn, der Zugriff auf diese Ressourcen ist durch einen Mechanismus geschützt, der es nur einem Ausführungsthread ermöglicht, Operationen an ihnen gleichzeitig auszuführen.
Im folgenden Beispiel ist
std :: cout eine gemeinsam genutzte Ressource, mit der 6 Threads arbeiten (t1-t5 + main).
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex mu ;
void CallHome ( string message )
{
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
}
int main ( )
{
thread t1 ( CallHome, "Hello from Jupiter" ) ;
thread t2 ( CallHome, "Hello from Pluto" ) ;
thread t3 ( CallHome, "Hello from Moon" ) ;
CallHome ( "Hello from Main/Earth" ) ;
thread t4 ( CallHome, "Hello from Uranus" ) ;
thread t5 ( CallHome, "Hello from Neptune" ) ;
t1. join ( ) ;
t2. join ( ) ;
t3. join ( ) ;
t4. join ( ) ;
t5. join ( ) ;
return 0 ;
}
Wenn wir dieses Programm ausführen, erhalten wir die Schlussfolgerung:
Thread 0x1000fb5c0 says Hello from Main/Earth
Thread Thread Thread 0x700005bd20000x700005b4f000 says says Thread Thread Hello from Pluto0x700005c55000Hello from Jupiter says 0x700005d5b000Hello from Moon
0x700005cd8000 says says Hello from Uranus
Hello from Neptune
Dies liegt daran, dass fünf Threads gleichzeitig in zufälliger Reihenfolge auf den Ausgabestream zugreifen. Um die Schlussfolgerung genauer zu formulieren, müssen Sie den Zugriff auf die gemeinsam genutzte Ressource mit
std :: mutex schützen. Ändern Sie einfach die
CallHome () -Funktion so, dass der Mutex vor der Verwendung von
std :: cout erfasst und anschließend freigegeben wird.
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
mu. unlock ( ) ;
}Fehler Nr. 6: Vergessen Sie, die Sperre nach dem Verlassen des kritischen Abschnitts aufzuheben
Im vorherigen Absatz haben Sie gesehen, wie Sie einen kritischen Abschnitt mit einem Mutex schützen. Das Aufrufen der Methoden
lock () und
entsperren () direkt im Mutex ist jedoch nicht die bevorzugte Option, da Sie möglicherweise vergessen haben, die gehaltene Sperre anzugeben. Was wird als nächstes passieren? Alle anderen Threads, die auf die Freigabe der Ressource warten, werden unendlich blockiert und das Programm kann hängen bleiben.
Wenn Sie in unserem synthetischen Beispiel vergessen haben, den Mutex im Funktionsaufruf
CallHome () zu entsperren, wird die erste Nachricht von Stream t1 an den Standard-Stream ausgegeben und das Programm stürzt ab. Dies liegt an der Tatsache, dass der Thread t1 eine Mutex-Sperre erhalten hat und die verbleibenden Threads darauf warten, dass diese Sperre aufgehoben wird.
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
//mu.unlock();
}Das Folgende ist die Ausgabe dieses Codes: Das Programm stürzte ab, zeigte die einzige Meldung im Terminal an und wurde nicht beendet:
Thread 0x700005986000 says Hello from Pluto
Solche Fehler treten häufig auf, weshalb es unerwünscht ist, die Methoden
lock () / entsperren () direkt aus dem Mutex heraus zu verwenden. Verwenden Sie
stattdessen die Vorlagenklasse
std :: lock_guard , die das
RAII- Idiom verwendet, um die Lebensdauer der Sperre zu steuern. Wenn das Objekt
lock_guard erstellt wird, versucht es, den Mutex zu übernehmen. Wenn das Programm den Bereich des Objekts
lock_guard verlässt, wird der Destruktor aufgerufen, wodurch der Mutex
freigegeben wird.
Wir schreiben die
CallHome () - Funktion mit dem Objekt
std :: lock_guard neu :
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; //
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guardFehler Nr. 7: Machen Sie den kritischen Abschnitt größer als nötig
Wenn ein Thread innerhalb eines kritischen Abschnitts ausgeführt wird, werden alle anderen, die versuchen, ihn einzugeben, im Wesentlichen blockiert. Wir sollten im kritischen Abschnitt so wenig Anweisungen wie möglich aufbewahren. Zur Veranschaulichung wird ein Beispiel für fehlerhaften Code mit einem großen kritischen Abschnitt angegeben:
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
ReadFifyThousandRecords ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muDie
ReadFifyThousandRecords () -Methode ändert keine Daten. Es gibt keinen Grund, es unter Verschluss auszuführen. Wenn diese Methode 10 Sekunden lang ausgeführt wird und 50.000 Zeilen aus der Datenbank gelesen werden, werden alle anderen Threads für diesen gesamten Zeitraum unnötig blockiert. Dies kann die Programmleistung ernsthaft beeinträchtigen.
Die richtige Lösung wäre, im kritischen Bereich nur mit
std :: cout zu arbeiten .
void CallHome ( string message )
{
ReadFifyThousandRecords ( ) ; // ..
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muFehler Nr. 8: Mehrere Sperren in einer anderen Reihenfolge
Dies ist eine der häufigsten Ursachen für
Deadlocks . In dieser Situation werden Threads unendlich blockiert, da auf den Zugriff auf Ressourcen gewartet wird, die von anderen Threads blockiert werden. Betrachten Sie ein Beispiel:
| Stream 1 | Stream 2 |
|---|
| Schloss A. | Schloss B. |
| // ... einige Operationen | // ... einige Operationen |
| Schloss B. | Schloss A. |
| // ... einige andere Operationen | // ... einige andere Operationen |
| entsperren B. | entsperren A. |
| entsperren A. | entsperren B. |
Es kann vorkommen, dass Thread 1 versucht, Sperre B zu erfassen und blockiert wird, weil Thread 2 sie bereits erfasst hat. Gleichzeitig versucht der zweite Thread, Sperre A zu erfassen, kann dies jedoch nicht, da er vom ersten Thread erfasst wurde. Thread 1 kann die Verriegelung A erst lösen, wenn sie B usw. verriegelt. Mit anderen Worten, das Programm friert ein.
Dieses Codebeispiel hilft Ihnen bei der Reproduktion von
Deadlocks :
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex muA ;
std :: mutex muB ;
void CallHome_Th1 ( string message )
{
muA. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muB. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muB. unlock ( ) ;
muA. unlock ( ) ;
}
void CallHome_Th2 ( string message )
{
muB. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muA. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muA. unlock ( ) ;
muB. unlock ( ) ;
}
int main ( )
{
thread t1 ( CallHome_Th1, "Hello from Jupiter" ) ;
thread t2 ( CallHome_Th2, "Hello from Pluto" ) ;
t1. join ( ) ;
t2. join ( ) ;
return 0 ;
}Wenn Sie diesen Code ausführen, stürzt er ab. Wenn Sie tiefer in den Debugger im Thread-Fenster einsteigen, werden Sie sehen, dass der erste Thread (aufgerufen von
CallHome_Th1 () ) versucht, Mutex B zu sperren, während Thread 2 (aufgerufen von
CallHome_Th2 () ) versucht, Mutex A zu blockieren. Keiner der Threads kann nicht erfolgreich sein, was zu einem Deadlock führt!
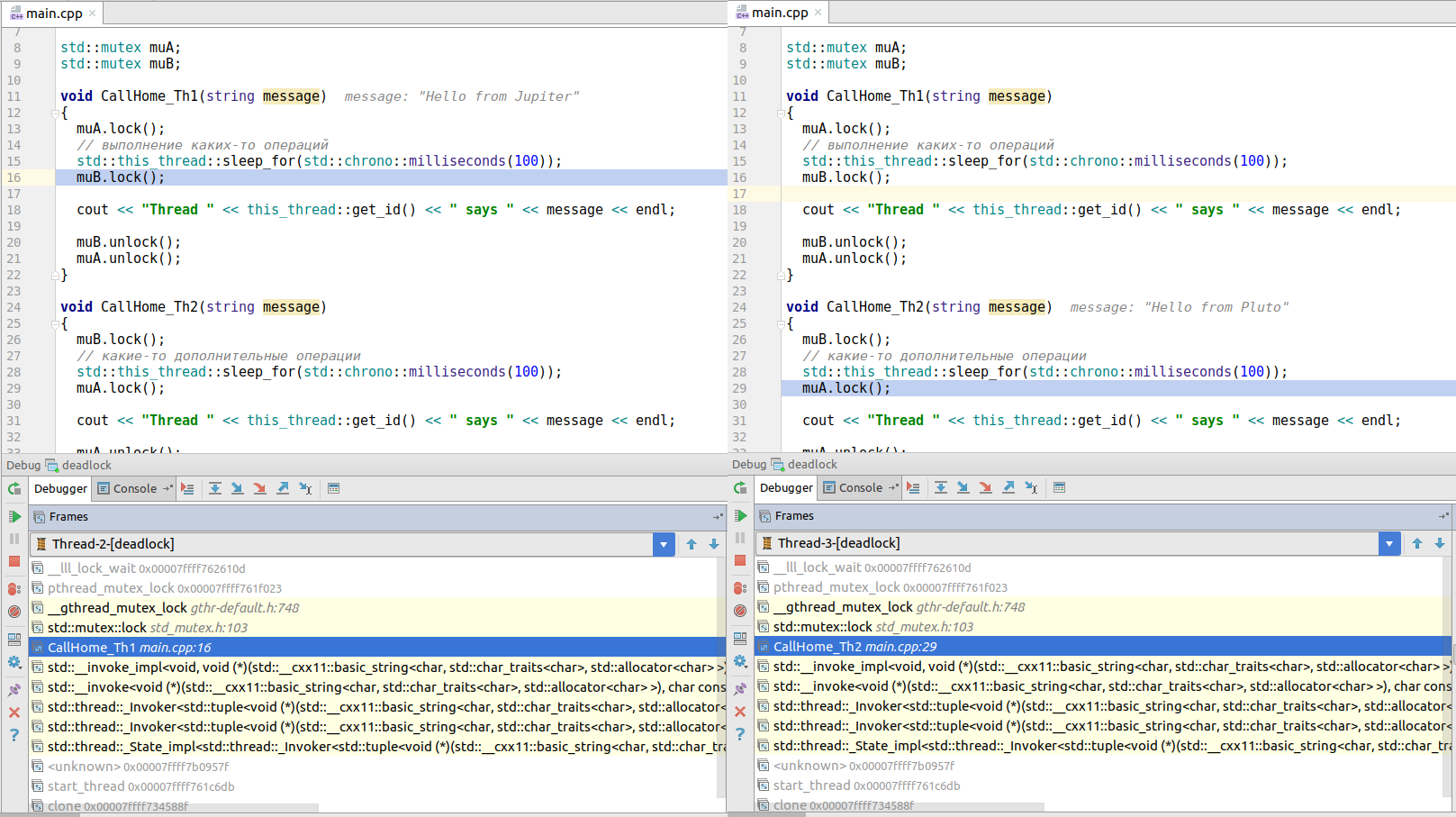
(das Bild ist anklickbar)
Was können Sie dagegen tun? Die beste Lösung wäre, den Code so umzustrukturieren, dass Sperren jedes Mal in derselben Reihenfolge auftreten.
Je nach Situation können Sie andere Strategien anwenden:
1. Verwenden Sie die Wrapper-
Klasse std :: scoped_lock , um mehrere Sperren gemeinsam zu erfassen:
std :: scoped_lock lock { muA, muB } ;2. Verwenden Sie die
Klasse std :: timed_mutex , in der Sie ein Zeitlimit angeben können.
Danach wird die Sperre
aufgehoben , wenn die Ressource nicht verfügbar ist.
std :: timed_mutex m ;
void DoSome ( ) {
std :: chrono :: milliseconds timeout ( 100 ) ;
while ( true ) {
if ( m. try_lock_for ( timeout ) ) {
std :: cout << std :: this_thread :: get_id ( ) << ": acquire mutex successfully" << std :: endl ;
m. unlock ( ) ;
} else {
std :: cout << std :: this_thread :: get_id ( ) << ": can't acquire mutex, do something else" << std :: endl ;
}
}
}Fehler Nr. 9: Ich habe zweimal versucht, eine std :: mutex-Sperre zu ergreifen
Der Versuch, die Sperre zweimal zu sperren, führt zu undefiniertem Verhalten. In den meisten Debug-Implementierungen stürzt dies ab. Im folgenden Code
sperrt LaunchRocket () beispielsweise den Mutex und ruft dann
StartThruster () auf . Was merkwürdig ist, im obigen Code wird dieses Problem während des normalen Betriebs des Programms nicht auftreten. Das Problem tritt nur auf, wenn eine Ausnahme ausgelöst wird, die von undefiniertem Verhalten begleitet wird oder das Programm abnormal beendet wird.
#include "stdafx.h"
#include <iostream>
#include <thread>
#include <mutex>
std :: mutex mu ;
static int counter = 0 ;
void StartThruster ( )
{
try
{
// -
}
catch ( ... )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
std :: cout << "Launching rocket" << std :: endl ;
}
}
void LaunchRocket ( )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
counter ++ ;
StartThruster ( ) ;
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
return 0 ;
}
Um dieses Problem zu beheben, müssen Sie den Code so korrigieren, dass das erneute Abrufen zuvor empfangener Sperren verhindert wird. Sie können
std :: recursive_mutex als Krückenlösung verwenden, aber eine solche Lösung weist fast immer auf eine schlechte Architektur des Programms hin.
Fehler Nr. 10: Verwenden Sie Mutexe, wenn std :: atomic-Typen ausreichen
Wenn Sie einfache Datentypen wie einen Booleschen Wert oder einen Ganzzahlzähler ändern müssen, bietet die Verwendung von
std: atomic im Allgemeinen eine bessere Leistung als die Verwendung von Mutexen.
Zum Beispiel, anstatt das folgende Konstrukt zu verwenden:
int counter ;
...
mu. lock ( ) ;
counter ++ ;
mu. unlock ( ) ;
Es ist besser, eine Variable als
std :: atomic zu deklarieren:
std :: atomic < int > counter ;
...
counter ++ ;Einen detaillierten Vergleich von Mutex und Atom finden Sie unter
Vergleich: Lockless-Programmierung mit Atomics in C ++ 11 vs. Mutex- und RW-Schlösser »Fehler Nr. 11: Erstellen und zerstören Sie eine große Anzahl von Threads direkt, anstatt einen Pool freier Threads zu verwenden
Das Erstellen und Zerstören von Threads ist in Bezug auf die Prozessorzeit ein teurer Vorgang. Stellen Sie sich einen Versuch vor, einen Stream zu erstellen, während das System rechenintensive Operationen ausführt, z. B. das Rendern von Grafiken oder das Berechnen von Spielphysik. Der häufig für solche Aufgaben verwendete Ansatz besteht darin, einen Pool vorab zugewiesener Threads zu erstellen, die Routineaufgaben wie das Schreiben auf die Festplatte oder das Senden von Daten über das Netzwerk während des gesamten Lebenszyklus des Prozesses ausführen können.
Ein weiterer Vorteil des Thread-Pools gegenüber dem Laichen und Zerstören von Threads selbst besteht darin, dass Sie sich keine Gedanken über eine
Überbelegung von Threads machen müssen (eine Situation, in der die Anzahl der Threads die Anzahl der verfügbaren Kerne überschreitet und ein erheblicher Teil der Prozessorzeit für das Wechseln von Kontexten aufgewendet wird [ca. Übersetzer]). Dies kann die Systemleistung beeinträchtigen.
Darüber hinaus erspart uns die Verwendung des Pools die Probleme bei der Verwaltung des Lebenszyklus von Threads, was sich letztendlich in kompakterem Code mit weniger Fehlern niederschlägt.
Die beiden beliebtesten Bibliotheken, die den Thread-Pool implementieren, sind
Intel Thread Building Blocks (TBB) und
Microsoft Parallel Patterns Library (PPL) .
Fehler Nr. 12: Behandeln Sie keine Ausnahmen, die in Hintergrundthreads auftreten
Ausnahmen, die in einem Thread ausgelöst werden, können nicht in einem anderen Thread behandelt werden. Stellen wir uns vor, wir haben eine Funktion, die eine Ausnahme auslöst. Wenn wir diese Funktion in einem separaten Thread ausführen, der vom Hauptthread der Ausführung abzweigt, und erwarten, dass wir eine vom zusätzlichen Thread ausgelöste Ausnahme abfangen, funktioniert dies nicht. Betrachten Sie ein Beispiel:
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr teptr = nullptr ;
void LaunchRocket ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
int main ( )
{
try
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
return 0 ;
}
Wenn dieses Programm ausgeführt wird, stürzt es ab. Der catch-Block in der Funktion main () wird jedoch nicht ausgeführt und behandelt die im Thread t1 ausgelöste Ausnahme nicht.
Die Lösung für dieses Problem besteht darin, die Funktionen von C ++ 11 zu verwenden:
std :: exception_ptr wird verwendet, um die im Hintergrundthread ausgelöste
Ausnahme zu behandeln. Hier sind die Schritte, die Sie unternehmen müssen:
- Erstellen Sie eine globale Instanz der Klasse std :: exception_ptr , die mit nullptr initialisiert wurde
- Behandeln Sie in einer Funktion, die in einem separaten Thread ausgeführt wird, alle Ausnahmen und legen Sie den Wert std :: current_exception () der im vorherigen Schritt deklarierten globalen Variablen std :: exception_ptr fest
- Überprüfen Sie den Wert einer globalen Variablen im Hauptthread
- Wenn der Wert festgelegt ist, rufen Sie mit der Funktion std :: rethrow_exception (exception_ptr p) die zuvor abgefangene Ausnahme wiederholt auf und übergeben Sie sie als Referenz als Parameter
Das Abrufen einer Ausnahme als Referenz tritt in dem Thread, in dem sie erstellt wurde, nicht auf. Daher eignet sich diese Funktion hervorragend zum Behandeln von Ausnahmen in verschiedenen Threads.
Im folgenden Code können Sie die im Hintergrund-Thread ausgelöste Ausnahme sicher behandeln.
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr globalExceptionPtr = nullptr ;
void LaunchRocket ( )
{
try
{
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
catch ( ... )
{
//
globalExceptionPtr = std :: current_exception ( ) ;
}
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
if ( globalExceptionPtr )
{
try
{
std :: rethrow_exception ( globalExceptionPtr ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
}
return 0 ;
}
Fehler Nr. 13: Verwenden Sie Threads, um den asynchronen Betrieb zu simulieren, anstatt std :: async zu verwenden
Wenn Sie den Code zur asynchronen Ausführung benötigen, d. H. Ohne den Hauptthread der Ausführung zu blockieren, wäre die beste Wahl die Verwendung von
std :: async () . Dies entspricht dem Erstellen eines Streams und dem Übergeben des erforderlichen Codes zur Ausführung in diesem Stream über einen Zeiger auf eine Funktion oder einen Parameter in Form einer Lambda-Funktion. Im letzteren Fall müssen Sie jedoch die Erstellung, das Anhängen / Entfernen dieses Threads sowie die Behandlung aller Ausnahmen überwachen, die in diesem Thread auftreten können. Wenn Sie
std :: async () verwenden , entlasten Sie sich von diesen Problemen und verringern die Wahrscheinlichkeit, in einen
Deadlock zu
geraten ,
erheblich .
Ein weiterer wesentlicher Vorteil der Verwendung von
std :: async ist die Möglichkeit, das Ergebnis einer asynchronen Operation mithilfe des
std :: future- Objekts an den aufrufenden Thread zurückzugeben. Stellen Sie sich vor, wir haben eine
ConjureMagic () -Funktion, die ein int zurückgibt. Wir können eine asynchrone Operation starten, die den Wert in Zukunft auf das
zukünftige Objekt setzt, wenn die Aufgabe abgeschlossen ist, und wir können das Ergebnis der Ausführung aus diesem Objekt in dem Ausführungsfluss extrahieren, aus dem die Operation aufgerufen wurde.
// future
std :: future asyncResult2 = std :: async ( & ConjureMagic ) ;
//... - future
// future
int v = asyncResult2. get ( ) ;Das Zurückholen des Ergebnisses vom laufenden Thread zum Aufrufer ist umständlicher. Zwei Möglichkeiten sind möglich:
- Übergeben eines Verweises auf die Ausgabevariable an den Stream, in dem das Ergebnis gespeichert wird.
- Speichern Sie das Ergebnis in der Feldvariablen des Workflow-Objekts, die gelesen werden kann, sobald der Thread die Ausführung abgeschlossen hat.
Kurt Guntheroth stellte fest, dass der Aufwand für die Erstellung eines Streams in Bezug auf die Leistung 14-mal so
hoch ist wie für die Verwendung von
Async .
Fazit: Verwenden Sie standardmäßig
std :: async (), bis Sie starke Argumente für die direkte Verwendung von
std :: thread finden .
Fehler Nr. 14: Verwenden Sie std :: launch :: async nicht, wenn Asynchronität erforderlich ist
Die Funktion
std :: async () ist nicht ganz der richtige Name, da sie standardmäßig möglicherweise nicht asynchron ausgeführt wird!
Es gibt zwei
std :: async- Laufzeitrichtlinien:
- std :: launch :: async : Die übergebene Funktion wird sofort in einem separaten Thread ausgeführt
- std :: launch :: deferred : Die übergebene Funktion wird nicht sofort gestartet. Der Start wird verzögert, bevor die Aufrufe get () oder wait () für das Objekt std :: future ausgeführt werden, das vom Aufruf std :: async zurückgegeben wird . Anstelle des Aufrufs dieser Methoden wird die Funktion synchron ausgeführt.
Wenn wir
std :: async () mit Standardparametern aufrufen, beginnt dies mit einer Kombination dieser beiden Parameter, was tatsächlich zu unvorhersehbarem Verhalten führt. Es gibt eine Reihe anderer Schwierigkeiten bei der Verwendung von
std: async () mit der Standardstartrichtlinie:
- Unfähigkeit, den korrekten Zugriff auf lokale Flussvariablen vorherzusagen
- Eine asynchrone Task wird möglicherweise überhaupt nicht gestartet, da während der Programmausführung möglicherweise keine Aufrufe der Methoden get () und wait () aufgerufen werden
- Bei Verwendung in Schleifen, in denen die Exit-Bedingung erwartet, dass das Objekt std :: future bereit ist, werden diese Schleifen möglicherweise nie beendet, da die vom Aufruf von std :: async zurückgegebene std :: future möglicherweise im verzögerten Zustand beginnt.
Um all diese Schwierigkeiten zu vermeiden, rufen Sie
std :: async immer mit der
Startrichtlinie std :: launch :: async auf.
Mach das nicht:
// myFunction std::async
auto myFuture = std :: async ( myFunction ) ;Tun Sie stattdessen Folgendes:
// myFunction
auto myFuture = std :: async ( std :: launch :: async , myFunction ) ;Dieser Punkt wird in dem Buch von Scott Meyers „Effective and Modern C ++“ ausführlicher behandelt.
Fehler Nr. 15: Aufruf der Methode get () eines std :: future-Objekts in einem Codeblock, dessen Ausführungszeit kritisch ist
Der folgende Code verarbeitet das Ergebnis, das vom
std :: future- Objekt einer asynchronen Operation erhalten wurde. Die
while-Schleife wird jedoch gesperrt, bis der asynchrone Vorgang abgeschlossen ist (in diesem Fall 10 Sekunden lang). Wenn Sie diese Schleife verwenden möchten, um Informationen auf dem Bildschirm anzuzeigen, kann dies zu unangenehmen Verzögerungen beim Rendern der Benutzeroberfläche führen.
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
int val = myFuture. get ( ) ; // 10
// - Val
}
return 0 ;
}
Hinweis : Ein weiteres Problem des obigen Codes besteht darin, dass versucht wird, ein zweites Mal auf das
std :: future- Objekt zuzugreifen, obwohl der Status des
std :: future- Objekts bei der ersten Iteration der Schleife abgerufen wurde und nicht abgerufen werden konnte.
Die richtige Lösung wäre, die Gültigkeit des
std :: future- Objekts zu überprüfen, bevor Sie die
get () -Methode aufrufen. Daher blockieren wir nicht den Abschluss der asynchronen Task und versuchen nicht, das bereits extrahierte
std :: future- Objekt
abzufragen .
Mit diesem Code-Snippet können Sie Folgendes erreichen:
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
if ( myFuture. valid ( ) )
{
int val = myFuture. get ( ) ; // 10
// - Val
}
}
return 0 ;
}
№16: , , , std::future::get()
Stellen Sie sich vor, wir haben das folgende Codefragment. Was ist Ihrer Meinung nach das Ergebnis des Aufrufs von std :: future :: get () ? Wenn Sie davon ausgehen, dass das Programm abstürzt, haben Sie absolut Recht! Die in der asynchronen Operation ausgelöste Ausnahme wird nur ausgelöst, wenn die Methode get () für das Objekt std :: future aufgerufen wird . Und wenn die Methode get () nicht aufgerufen wird, wird die Ausnahme ignoriert und ausgelöst, wenn das Objekt std :: future den Gültigkeitsbereich verlässt. Wenn Ihre asynchrone Operation eine Ausnahme auslösen kann, sollten Sie den Aufruf von std :: future :: get () immer in einen try / catch- Block einschließen. Ein Beispiel dafür, wie dies aussehen könnte:#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
int result = myFuture. get ( ) ;
}
return 0 ;
}
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
try
{
int result = myFuture. get ( ) ;
}
catch ( const std :: runtime_error & e )
{
std :: cout << "Async task threw exception: " << e. what ( ) << std :: endl ;
}
}
return 0 ;
}
№17: std::async,
Obwohl std :: async () in den meisten Fällen ausreicht, gibt es Situationen, in denen Sie möglicherweise eine sorgfältige Kontrolle über die Ausführung Ihres Codes in einem Stream benötigen. Zum Beispiel, wenn Sie einen bestimmten Thread an einen bestimmten Prozessorkern in einem Multiprozessorsystem (z. B. Xbox) binden möchten.Das angegebene Codefragment stellt die Bindung des Threads an den 5. Prozessorkern im System her. Dies ist möglich dank der native_handle () -Methode des std :: thread- Objekts und der Übergabe an die Win32-API- Stream-Funktion . Es gibt viele andere Funktionen, die über die Streaming-Win32-API bereitgestellt werden und in std :: thread oder std :: async () nicht verfügbar sind . Beim Durcharbeiten#include "stdafx.h"
#include <windows.h>
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
DWORD result = :: SetThreadIdealProcessor ( t1. native_handle ( ) , 5 ) ;
t1. join ( ) ;
return 0 ;
}
std :: async () sind diese grundlegenden Plattformfunktionen nicht verfügbar, weshalb diese Methode für komplexere Aufgaben ungeeignet ist.Eine Alternative besteht darin, std :: packaged_task zu erstellen und nach dem Festlegen der Eigenschaften des Threads in den gewünschten Ausführungsthread zu verschieben.Fehler Nr. 18: Es sind viel mehr "laufende" Threads als Kerne verfügbar
Aus architektonischer Sicht können Flüsse in zwei Gruppen eingeteilt werden: "Laufen" und "Warten".Das Ausführen von Threads nutzt 100% der Prozessorzeit des Kernels, auf dem sie ausgeführt werden. Wenn einem Kern mehr als ein laufender Thread zugeordnet ist, sinkt die Effizienz der CPU-Auslastung. Wir erzielen keinen Leistungsgewinn, wenn wir mehr als einen laufenden Thread auf einem Prozessorkern ausführen. In Wirklichkeit sinkt die Leistung aufgrund zusätzlicher Kontextwechsel.Wartende Threads verwenden nur wenige Taktzyklen, in denen sie ausgeführt werden, während sie auf Systemereignisse oder Netzwerk-E / A usw. warten. In diesem Fall bleibt der größte Teil der verfügbaren Prozessorzeit des Kernels ungenutzt. Ein wartender Thread kann Daten verarbeiten, während die anderen auf das Auslösen von Ereignissen warten. Aus diesem Grund ist es vorteilhaft, mehrere wartende Threads auf einen einzelnen Kern zu verteilen. Durch das Planen mehrerer ausstehender Threads pro Kern kann die Programmleistung erheblich gesteigert werden.Wie kann man also verstehen, wie viele laufende Threads das System unterstützt? Verwenden Sie die Methode std :: thread :: hardware_concurrency () . Diese Funktion gibt normalerweise die Anzahl der Prozessorkerne zurück, berücksichtigt jedoch Kerne, die sich aufgrund von zwei oder mehr logischen Kernen verhaltenHypertreading .Sie müssen den erhaltenen Wert der Zielplattform verwenden, um die maximale Anzahl gleichzeitig laufender Threads Ihres Programms zu planen. Sie können auch einen Kern für alle ausstehenden Threads zuweisen und die verbleibende Anzahl von Kernen zum Ausführen von Threads verwenden. Verwenden Sie in einem Quad-Core-System beispielsweise einen Kern für ALLE ausstehenden Threads und für die verbleibenden drei Kerne drei laufende Threads. Abhängig von der Effizienz Ihres Thread-Schedulers können einige Ihrer ausführbaren Threads den Kontext wechseln (aufgrund von Fehlern beim Seitenzugriff usw.), wodurch der Kernel für einige Zeit inaktiv bleibt. Wenn Sie diese Situation während der Profilerstellung beobachten, sollten Sie eine etwas größere Anzahl von auszuführenden Threads als die Anzahl der Kerne erstellen und diesen Wert für Ihr System konfigurieren.Fehler Nr. 19: Verwenden des flüchtigen Schlüsselworts für die Synchronisation
Das Schlüsselwort flüchtig , bevor der Typ einer Variablen angegeben wird, macht Operationen für diese Variable nicht atomar oder threadsicher. Was Sie wahrscheinlich wollen, ist std :: atomic . Weitere Informationen findenSie in der Diskussion zum Stackoverflow .Fehler Nr. 20: Verwenden der sperrenfreien Architektur, sofern dies nicht unbedingt erforderlich ist
Es gibt etwas in der Komplexität, das jeder Ingenieur mag. Das Erstellen sperrfreier Programme klingt im Vergleich zu regulären Synchronisationsmechanismen wie Mutex, bedingten Variablen, Asynchronität usw. sehr verlockend. Allerdings hatte jeder erfahrene C ++ - Entwickler, mit dem ich gesprochen habe, eine Meinung dass die Verwendung der nicht sperrenden Programmierung als anfängliche Option eine Art vorzeitige Optimierung ist, die im ungünstigsten Moment seitwärts gehen kann (denken Sie an einen Fehler in einem Betriebssystem, wenn Sie keinen vollständigen Heap-Dump haben!).In meiner Karriere in C ++ gab es nur eine Situation, in der Code ohne Sperren ausgeführt werden musste, da wir in einem System mit begrenzten Ressourcen arbeiteten, in dem jede Transaktion in unserer Komponente nicht länger als 10 Mikrosekunden dauern sollte.Bevor Sie über die Anwendung eines Entwicklungsansatzes ohne Blockierung nachdenken, beantworten Sie bitte drei Fragen:- Haben Sie versucht, die Architektur Ihres Systems so zu gestalten, dass kein Synchronisationsmechanismus erforderlich ist? Die beste Synchronisation ist in der Regel das Fehlen einer Synchronisation.
- Wenn Sie eine Synchronisierung benötigen, haben Sie Ihren Code profiliert, um die Leistungsmerkmale zu verstehen? Wenn ja, haben Sie versucht, Engpässe zu optimieren?
- Können Sie horizontal statt vertikal skalieren?
Zusammenfassend lässt sich sagen, dass Sie für eine normale Anwendungsentwicklung eine nicht sperrende Programmierung nur in Betracht ziehen sollten, wenn Sie alle anderen Alternativen ausgeschöpft haben. Eine andere Möglichkeit, dies zu betrachten, besteht darin, dass Sie sich wahrscheinlich von der Programmierung fernhalten sollten, ohne zu blockieren, wenn Sie immer noch einige der oben genannten 19 Fehler machen.[Von. Übersetzer: Vielen Dank an vovo4K für die Unterstützung bei der Vorbereitung dieses Artikels.]