Alexander Rubin arbeitet bei Percona und hat
mehr als einmal bei
HighLoad ++ gespielt , was den Teilnehmern als Experte für MySQL bekannt ist. Es ist logisch anzunehmen, dass wir heute über etwas im Zusammenhang mit MySQL sprechen werden. Dies ist so, aber nur teilweise, weil wir auch über das
Internet der Dinge sprechen werden. Die Geschichte wird halb unterhaltsam sein, insbesondere der erste Teil, in dem wir uns das Gerät ansehen, das Alexander für die Ernte von Aprikosen entwickelt hat. Das ist die Natur eines echten Ingenieurs - wenn Sie Obst wollen, kaufen Sie eine Gebühr.

Hintergrund
Alles begann mit dem einfachen Wunsch, einen Obstbaum in seiner Gegend zu pflanzen. Es scheint sehr einfach zu sein, dies zu tun - Sie kommen in den Laden und kaufen einen Sämling. Aber in Amerika ist die erste Frage, die Verkäufer stellen, wie viel Sonnenlicht der Baum erhalten wird. Für Alexander stellte sich heraus, dass dies ein riesiges Rätsel war - es ist völlig unbekannt, wie viel Sonnenlicht auf dem Gelände ist.
Um das herauszufinden, konnte ein Schüler jeden Tag auf den Hof gehen, sehen, wie viel Sonnenschein es gibt, und es in ein Notizbuch schreiben. Dies ist jedoch nicht der Fall - es ist notwendig, alles auszurüsten und zu automatisieren.
Während der Präsentation wurden viele Beispiele live aufgeführt und gespielt. Wenn Sie ein vollständigeres Bild als im Text wünschen, wechseln Sie zum Ansehen des Videos.Um Wetterbeobachtungen nicht in einem Notebook aufzuzeichnen, gibt es eine große Anzahl von Geräten für Internet-Dinge - Raspberry Pi, den neuen Raspberry Pi, Arduino - Tausende verschiedener Plattformen. Aber ich habe für dieses Projekt ein Gerät namens
Particle Photon ausgewählt. Es ist sehr einfach zu bedienen und kostet auf der offiziellen Website 19 US-Dollar.
Das Gute an Particle Photon ist:
- 100% Cloud-Lösung;
- Alle Sensoren eignen sich beispielsweise für Arduino. Sie kosten alle weniger als einen Dollar.
Ich habe ein solches Gerät hergestellt und es auf der Baustelle ins Gras gelegt. Es hat eine Partikelwolke und eine Konsole. Dieses Gerät stellt eine Verbindung über einen WLAN-Hotspot her und sendet Daten: Licht, Temperatur und Luftfeuchtigkeit. Der Tester hat 24 Stunden mit einer kleinen Batterie gedauert, was ziemlich gut ist.
Außerdem muss ich nicht nur die Beleuchtung usw. messen und auf das Telefon übertragen (was wirklich gut ist - ich kann in Echtzeit sehen, welche Art von Beleuchtung ich habe), sondern auch
Daten speichern . Dafür habe ich mich natürlich als MySQL-Veteran für MySQL entschieden.
Wie schreiben wir Daten in MySQL?
Ich habe ein ziemlich kompliziertes Schema gewählt:
- Ich erhalte Daten von der Partikelkonsole.
- Ich benutze Node.js, um sie in MySQL zu schreiben.
Ich verwende die Partikel-JS-API, die von der Partikel-Website heruntergeladen werden kann. Ich stelle eine Verbindung mit MySQL her und schreibe, das heißt, ich mache nur INSERT INTO-Werte. Eine solche Pipeline.
Somit liegt das Gerät auf dem Hof, stellt über WLAN eine Verbindung zum Heimrouter her und überträgt mithilfe des MQTT-Protokolls Daten an Partikel. Dann genau das Schema: Das Programm auf Node.js läuft auf der virtuellen Maschine, die Daten von Particle empfängt und in MySQL schreibt.
Zu Beginn habe ich die Diagramme aus den Rohdaten in R erstellt. Die Diagramme zeigen, dass die Temperatur und die Beleuchtung tagsüber steigen, nachts fallen und die Luftfeuchtigkeit steigt - das ist natürlich. Es gibt aber auch Rauschen in der Grafik, was typisch für Internet of Things-Geräte ist. Wenn beispielsweise ein Fehler auf ein Gerät kriecht und es schließt, kann der Sensor völlig irrelevante Daten übertragen. Dies wird für weitere Überlegungen wichtig sein.
Lassen Sie uns nun über MySQL und JSON sprechen, die sich in der Arbeit mit JSON von MySQL 5.7 auf MySQL 8 geändert haben. Dann werde ich eine Demo zeigen, für die ich MySQL 8 verwende (zum Zeitpunkt des Berichts war diese Version noch nicht produktionsbereit, eine stabile Version wurde bereits veröffentlicht).
MySQL-Datenspeicherung
Wenn wir versuchen, von Sensoren empfangene Daten zu speichern, besteht unser erster Gedanke
darin, eine Tabelle in MySQL zu erstellen :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
Hier gibt es für jeden Sensor und für jeden Datentyp eine Spalte: Licht, Temperatur, Luftfeuchtigkeit.
Das ist logisch genug, aber
es gibt ein Problem - es ist nicht flexibel . Angenommen, wir möchten einen weiteren Sensor hinzufügen und etwas anderes messen. Zum Beispiel messen einige Leute das restliche Bier in einem Fass. Was ist in diesem Fall zu tun?
alter table sensor_wide add water level double ...;
Wie pervers, um etwas zur Tabelle hinzuzufügen? Sie müssen eine Änderungstabelle erstellen, aber wenn Sie eine Änderungstabelle in MySQL erstellt haben, wissen Sie, wovon ich spreche - das ist völlig schwierig. Das Ändern der Tabelle in MySQL 8 und MariaDB ist viel einfacher, aber historisch gesehen ist dies ein großes Problem. Wenn wir also beispielsweise eine Spalte mit dem Namen des Bieres hinzufügen müssen, ist dies nicht so einfach.
Wieder erscheinen die Sensoren, verschwinden, was sollen wir mit den alten Daten machen? Zum Beispiel erhalten wir keine Informationen mehr über Beleuchtung. Oder erstellen wir eine neue Spalte - wie speichert man, was vorher nicht da war? Der Standardansatz ist null, aber für die Analyse ist er nicht sehr praktisch.
Eine weitere Option ist ein Schlüssel- / Wertspeicher.
MySQL-Datenspeicherung: Schlüssel / Wert
Dies wird
flexibler : In Schlüssel / Wert gibt es einen Namen, zum Beispiel Temperatur und dementsprechend Daten.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
In diesem Fall tritt ein
anderes Problem auf
- es gibt keine Typen . Wir wissen nicht, was wir im Feld "Daten" speichern. Wir müssen es als Textfeld deklarieren. Wenn ich mein Internet-of-Things-Gerät erstelle, weiß ich, welche Art von Sensor es gibt und welchen Typ es hat. Wenn Sie jedoch die Daten einer anderen Person in derselben Tabelle speichern müssen, weiß ich nicht, welche Daten erfasst werden.
Sie können viele Tabellen speichern, aber das Erstellen einer neuen Tabelle für jeden Sensor ist nicht sehr gut.
Was kann getan werden? - Verwenden Sie JSON.
MySQL-Datenspeicher: JSON
Die gute Nachricht ist, dass Sie in MySQL 5.7 JSON als Feld speichern können.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
Bevor MySQL 5.7 erschien, wurde JSON ebenfalls gespeichert, jedoch als Textfeld. Mit dem JSON-Feld in MySQL können Sie JSON selbst am effizientesten speichern. Darüber hinaus können Sie basierend auf JSON virtuelle Spalten und Indizes erstellen, die darauf basieren.
Das einzige kleine Problem ist,
dass die Tabelle während der Lagerung größer wird . Aber dann bekommen wir viel mehr Flexibilität.
Das JSON-Feld eignet sich besser zum Speichern von JSON als das Textfeld, weil:
- Bietet automatische Dokumentenüberprüfung . Das heißt, wenn wir versuchen, etwas zu schreiben, das dort nicht gültig ist, tritt ein Fehler auf.
- Dies ist ein optimiertes Speicherformat . JSON wird im Binärformat gespeichert, sodass Sie von einem JSON-Dokument zu einem anderen wechseln können - das sogenannte Überspringen.
Um Daten in JSON zu speichern, können wir einfach SQL verwenden: Einfügen einfügen, dort 'Daten' einfügen und Daten vom Gerät abrufen.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
Demo
Um zu demonstrieren (
hier der Anfang im Video), verwendet das Beispiel eine virtuelle Maschine, in der sich SQL befindet.

Unten ist ein Fragment des Programms.
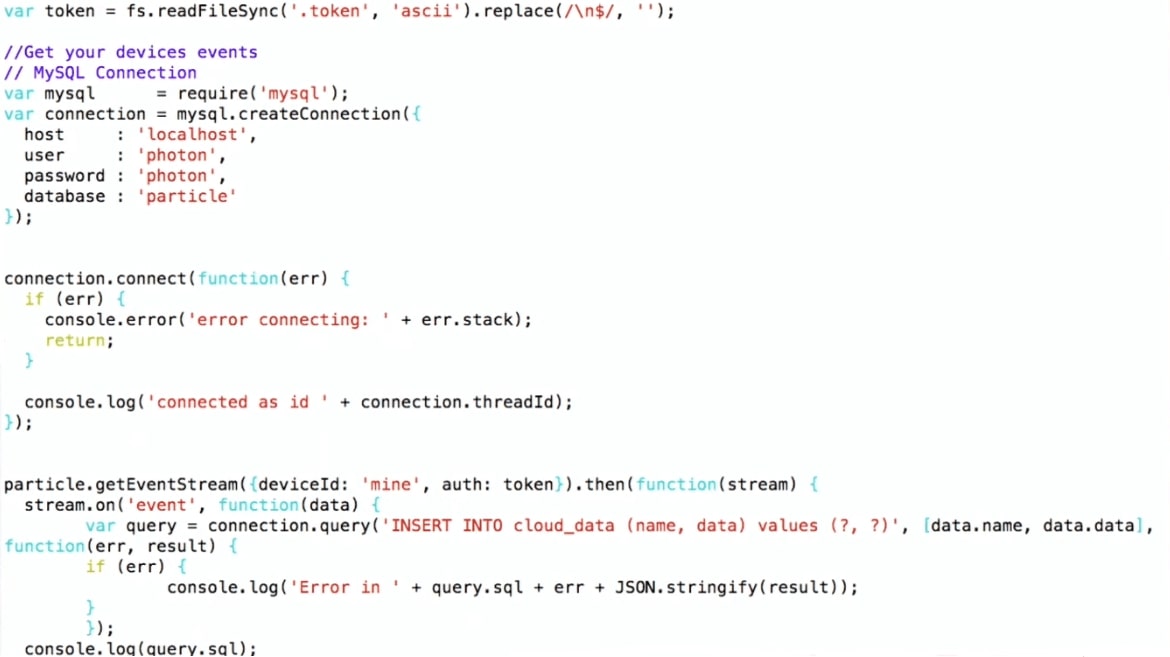
Ich mache
INSERT INTO cloud_data (name, data) , bekomme die Daten bereits im JSON-Format und kann sie direkt in MySQL schreiben, ohne darüber nachzudenken, was sich darin befindet.
Wie sich herausstellte, können Sie mit dieser Cloud nicht nur auf die Daten meines Geräts zugreifen, sondern im Allgemeinen auf
alle Daten , die dieses Partikel verwendet. Es scheint soweit zu funktionieren. Menschen, die auf der ganzen Welt Teilchenphoton verwenden, senden einige Daten: Die Tür zur Garage ist offen, oder der Rest des Bieres ist so und so oder etwas anderes. Es ist nicht bekannt, wo sich diese Geräte befinden, aber solche Daten können erhalten werden. Der einzige Unterschied besteht darin, dass ich beim
deviceId: 'mine' meiner Daten
deviceId: 'mine' schreibe:
deviceId: 'mine' .
Wenn wir den Code ausführen, erhalten wir einen Datenstrom von Geräten anderer Personen, die etwas tun.
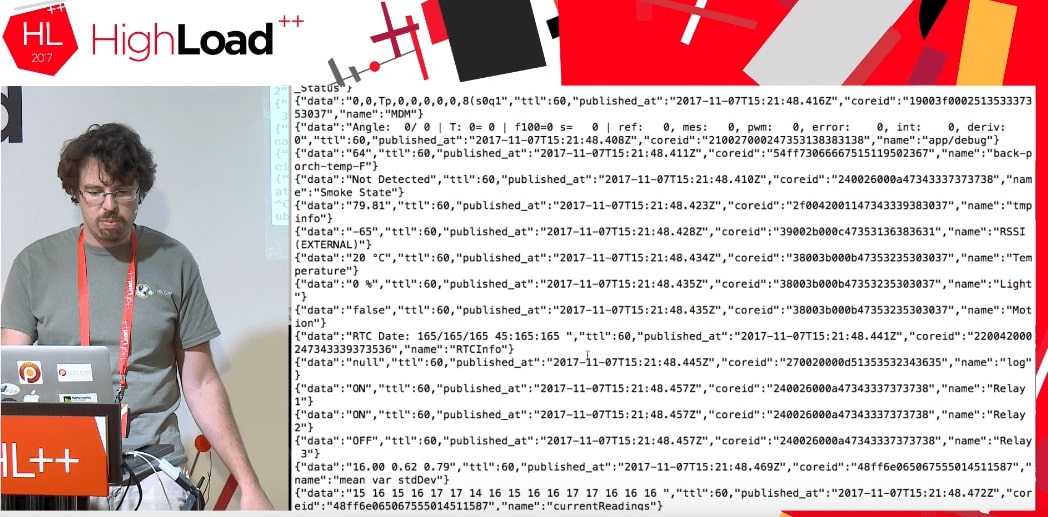
Wir wissen absolut nicht, was diese Daten sind: TTL, Published_at, Coreid, Türstatus (Tür offen), Relais ein.
Dies ist ein großartiges Beispiel. Angenommen, ich versuche, dies in MySQL in eine normale Datenstruktur zu integrieren. Ich sollte wissen, was die Tür dort ist, warum sie offen ist und welche allgemeinen Parameter sie annehmen kann. Wenn ich JSON habe, schreibe ich es als JSON-Feld direkt in MySQL.
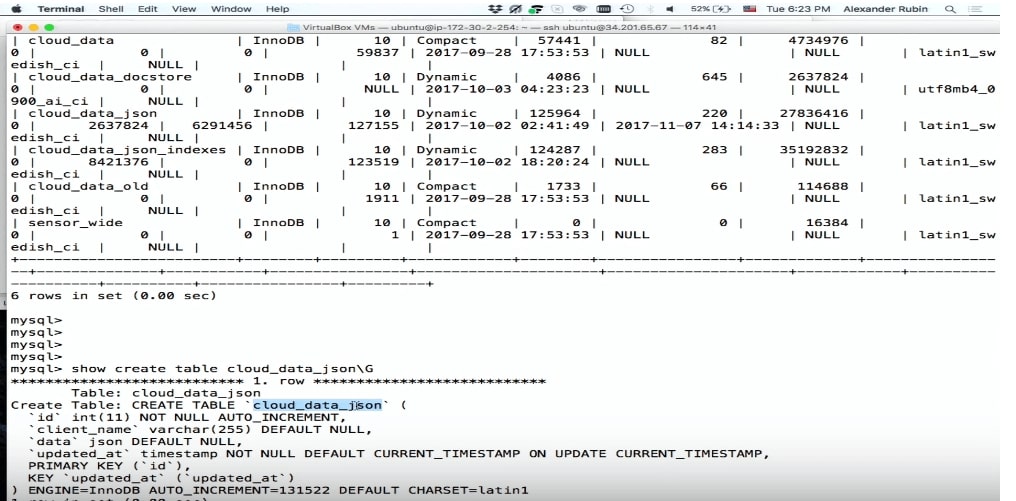
Bitte, alles wurde aufgezeichnet.
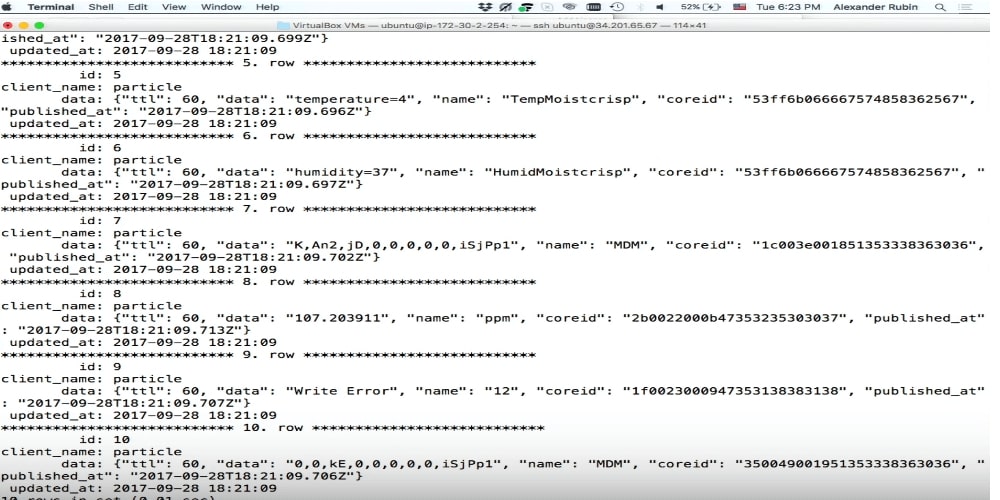
Dokumentenspeicher
Der Dokumentenspeicher ist ein Versuch in MySQL, Speicher für JSON zu erstellen. Ich liebe SQL wirklich, bin gut damit vertraut, kann jede SQL-Abfrage machen usw. Aber viele Leute mögen SQL aus verschiedenen Gründen nicht, und der Document Store kann eine Lösung für sie sein, da Sie damit von SQL abstrahieren, eine Verbindung zu MySQL herstellen und JSON direkt dort schreiben können.

In MySQL 5.7 ist eine weitere Möglichkeit aufgetreten: Verwenden Sie ein anderes Protokoll, einen anderen Port, und es wird auch ein anderer Treiber benötigt. Für Node.js (in der Tat für jede Programmiersprache - PHP, Java usw.) stellen wir über ein anderes Protokoll eine Verbindung zu MySQL her und können Daten im JSON-Format übertragen. Auch hier weiß ich nicht, was ich in diesem JSON habe - Informationen über Türen oder etwas anderes. Ich speichere die Daten einfach in MySQL und dann werden wir es herausfinden.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
Wenn Sie damit experimentieren möchten, können Sie MySQL 5.7 so konfigurieren, dass es den entsprechenden Port Document Store oder X DevAPI versteht und überwacht. Ich habe Connector-Nodejs verwendet.
Dies ist ein Beispiel für das, was ich dort aufschreibe: Bier usw. Ich weiß absolut nicht, was da ist. Jetzt schreiben wir es einfach auf und analysieren es später.

Der nächste Punkt unseres Programms ist, wie man sieht, was da ist.
MySQL-Datenspeicherung: JSON + -Indizes
In JSON und MySQL 5.7 gibt es eine großartige Funktion, mit der Felder aus JSON gezogen werden können. Dies ist ein solcher syntaktischer Zucker in der Funktion JSON_EXTRACT. Ich finde das sehr praktisch.
Daten sind in unserem Fall der Name der Spalte, in der JSON gespeichert ist, und Name ist unser Feld. Name, Daten, Published_at - das ist alles, was wir auf diese Weise herausholen können.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
In diesem Beispiel möchte ich sehen, was ich in die MySQL-Tabelle und die letzten 10 Datensätze geschrieben habe. Ich mache eine solche Anfrage und versuche sie auszuführen. Leider wird
dies sehr lange funktionieren .
In logischer Weise verwendet MySQL in diesem Fall keine Indizes. Wir ziehen die Daten aus JSON heraus und versuchen, eine Art Filter und Sortierung anzuwenden. In diesem Fall erhalten wir Using filesort.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
Die Verwendung von filesort ist sehr schlecht, es handelt sich um eine externe Sortierung.
Die gute Nachricht ist, dass Sie zwei Schritte unternehmen können, um dies zu beschleunigen.
Schritt 1. Erstellen Sie eine virtuelle Spalte
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Ich mache EXTRACT, das heißt, ich ziehe Daten aus JSON und erstelle darauf basierend eine virtuelle Spalte. Die virtuelle Spalte wird nicht in MySQL 5.7 und in MySQL 8 gespeichert - es ist lediglich die Möglichkeit, eine separate Spalte zu erstellen.
Sie fragen, wie es ist, Sie sagten, dass ALTER TABLE eine so lange Operation ist. Aber hier ist es nicht so schlimm.
Das Erstellen einer virtuellen Spalte ist schnell . Dort gibt es eine Sperre, aber tatsächlich gibt es in MySQL eine Sperre für alle DDL-Operationen. ALTER TABLE ist eine ziemlich schnelle Operation und erstellt nicht die gesamte Tabelle neu.
Wir haben hier eine virtuelle Spalte erstellt. Ich musste das Datum konvertieren, da es in JSON im ISO-Format gespeichert ist, aber hier verwendet MySQL ein völlig anderes Format. Um eine Spalte zu erstellen, habe ich sie benannt, ihr einen Typ gegeben und gesagt, dass ich dort aufnehmen würde.
Um die ursprüngliche Abfrage zu optimieren, müssen Sie "public_at" und "name" herausziehen. Published_at existiert bereits, der Name ist einfacher - erstellen Sie einfach eine virtuelle Spalte.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Schritt 2. Erstellen eines Index
Im folgenden Code erstelle ich einen Index für shared_at und führe die Abfrage aus:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
Sie können sehen, dass MySQL den Index tatsächlich verwendet. Dies ist eine Optimierung auf Bestellung. In diesem Beispiel werden Daten und Name nicht indiziert. MySQL verwendet die Reihenfolge nach Daten, und da wir einen Index für Publish_at haben, wird dieser verwendet.
Außerdem könnte ich die gleiche Syntax Zucker
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") anstelle von "Published_at" in der angegebenen Reihenfolge verwenden. MySQL würde immer noch verstehen, dass es einen Index für diese Spalte gibt, und ihn verwenden.
Es gibt tatsächlich ein kleines Problem damit. Angenommen, ich möchte Daten nicht nur nach publiziertem_at, sondern auch nach Namen sortieren.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
Wenn Ihr Gerät Zehntausende von Ereignissen pro Sekunde verarbeitet, gibt publiziert_at keine gute Sortierung aus, da es Duplikate gibt. Daher fügen wir eine weitere Sortierung nach Datenname hinzu. Dies ist eine typische Abfrage nicht nur für das Internet der Dinge: Geben Sie mir die letzten 10 Ereignisse, sondern sortieren Sie sie nach Datum und dann beispielsweise nach dem Nachnamen der Person in aufsteigender Reihenfolge. Zu diesem Zweck gibt es im obigen Beispiel zwei Felder und zwei Sortierschlüssel: absteigend und aufsteigend.
In diesem Fall verwendet MySQL zunächst keine Indizes. In diesem speziellen Fall entscheidet MySQL, dass ein vollständiger Tabellenscan rentabler ist als die Verwendung eines Index, und wiederum wird die sehr langsame Dateisortierungsoperation verwendet.
Neu in MySQL 8.0
absteigend / aufsteigend
In MySQL 5.7 kann eine solche Abfrage nicht optimiert werden, wenn auch nur auf Kosten anderer Dinge. In MySQL 8 gab es eine echte Möglichkeit, die Sortierung für jedes Feld festzulegen.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
Das Interessanteste ist, dass der absteigende / aufsteigende Schlüssel nach dem Indexnamen schon lange in SQL ist. Bereits in der allerersten Version von MySQL 3.23 können Sie "publiziert_absteigend" oder "veröffentlicht_at aufsteigend" angeben. MySQL akzeptierte dies,
tat aber nichts , das heißt, es wurde immer in eine Richtung sortiert.
In MySQL 8 wurde dies behoben und jetzt gibt es eine solche Funktion. Sie können ein Feld in absteigender Reihenfolge und mit Standardsortierung erstellen.
Lassen Sie uns eine Sekunde zurückgehen und das Beispiel aus Schritt 2 noch einmal betrachten.
Warum funktioniert es, sonst nicht? Dies funktioniert, weil es sich bei MySQL-Indizes um einen B-Baum handelt und B-Baum-Indizes sowohl vom Anfang als auch vom Ende gelesen werden können. In diesem Fall liest MySQL den Index vom Ende und alles ist gut. Aber wenn wir absteigen und aufsteigen, können Sie nicht lesen. Sie können in derselben Reihenfolge lesen, aber
Sie können nicht zwei Sortierungen kombinieren - Sie müssen neu sortieren.
Da wir einen ganz bestimmten Fall optimieren, können wir einen Index dafür erstellen und eine bestimmte Sortierung angeben: Hier ist "public_at" absteigend, "data_name" aufsteigend. MySQL verwendet diesen Index und alles wird gut und schnell.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
Dies ist eine Funktion von MySQL 8, das zum Zeitpunkt der Veröffentlichung bereits verfügbar und für die Produktion bereit ist.
Ausgabeergebnisse
Es gibt zwei weitere interessante Dinge, die ich zeigen möchte:
1. Hübscher Druck, dh eine schöne Ausgabe von Daten auf dem Bildschirm. Mit normalem SELECT wird JSON nicht formatiert.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2. Wir können sagen, dass MySQL das Ergebnis in Form eines JSON-Arrays oder eines JSON-Objekts ausgibt, die Felder angibt und die Ausgabe dann als JSON formatiert wird.
Volltextsuche in JSON-Dokumenten
Wenn wir ein flexibles Speichersystem verwenden und nicht wissen, was sich in unserem JSON befindet, wäre es logisch, die Volltextsuche zu verwenden.
Leider hat die
Volltextsuche ihre Grenzen . Das erste, was ich versuchte, war, einen Volltextschlüssel zu erstellen. Ich habe versucht so etwas zu tun:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
Leider funktioniert das nicht. Selbst in MySQL 8 ist es leider unmöglich, einen Volltextindex einfach über das JSON-Feld zu erstellen. Natürlich hätte ich gerne eine solche Funktion - die Möglichkeit, zumindest nach JSON-Schlüsseln zu suchen, wäre sehr nützlich.
Wenn dies jedoch noch nicht möglich ist, erstellen wir eine virtuelle Spalte. In unserem Fall gibt es ein Datenfeld, und es wäre interessant für uns zu sehen, was sich darin befindet.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
Leider funktioniert dies auch nicht -
Sie können keinen Volltextindex für eine virtuelle Spalte erstellen .
Wenn ja, erstellen wir eine gespeicherte Spalte. Mit MySQL 5.7 können Sie eine Spalte als gespeichertes Feld deklarieren.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
In den vorherigen Beispielen haben wir virtuelle Spalten erstellt, die nicht gespeichert werden, aber Indizes werden erstellt und gespeichert. In diesem Fall musste ich MySQL mitteilen, dass dies eine STORED-Spalte ist, dh, sie wird erstellt und die Daten werden darauf kopiert. Danach hat MySQL einen Volltextindex erstellt, dafür mussten wir die Tabelle neu erstellen. Diese Einschränkung gilt jedoch für die InnoDB- und InnoDB-Volltextsuche: Sie müssen die Tabelle neu erstellen, um eine spezielle Volltextsuchkennung hinzuzufügen.
Interessanterweise gab es in MySQL 8 eine
neue UTF8 MB4- Codierung für Emoticons . Natürlich nicht ganz für sie, aber weil es in UTF8MB3 einige Probleme mit Russisch, Chinesisch, Japanisch und anderen Sprachen gibt.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
Dementsprechend sollte MySQL 8 JSON-Daten in UTF8MB4 speichern. Aber ob aufgrund der Tatsache, dass Node.js eine Verbindung zur Device Cloud herstellt und dort etwas falsch geschrieben ist oder es sich um einen Beta-Versionsfehler handelt, ist dies nicht geschehen. Daher musste ich die Daten konvertieren, bevor ich sie in eine gespeicherte Spalte schrieb.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
Danach konnte ich eine Volltextsuche für zwei Felder erstellen: für den JSON-Namen und für die JSON-Daten.
Nicht nur IoT
JSON ist nicht nur das Internet der Dinge. Es kann für andere interessante Dinge verwendet werden:
- Benutzerdefinierte Felder (CMS);
- Komplexe Strukturen usw.;
Einige Dinge können mit einem flexiblen Datenspeicherungsschema viel bequemer implementiert werden. Ein hervorragendes Beispiel lieferte Oracle OpenWorld: Kinoreservierungen. Es ist sehr schwierig, dies im relationalen Modell zu implementieren - Sie erhalten viele abhängige Tabellen, Verknüpfungen usw. Auf der anderen Seite können wir den gesamten Raum als JSON-Struktur speichern, in andere Tabellen in MySQL schreiben und auf die übliche Weise verwenden: Indizes basierend auf JSON erstellen usw.
Komplexe Strukturen werden bequem im JSON-Format gespeichert.
Dies ist ein Baum, der erfolgreich gepflanzt wurde. Leider aßen es einige Jahre später Hirsche, aber das ist eine ganz andere Geschichte.
Dieser Bericht ist ein hervorragendes Beispiel dafür, wie ein ganzer Abschnitt bei einer großen Konferenz aus einem Thema und dann aus einer separaten Veranstaltung hervorgeht. Im Fall des Internet der Dinge haben wir InoThings ++ - eine Konferenz für Fachleute auf dem Internet der Dinge, die am 4. April zum zweiten Mal stattfinden wird.
Das zentrale Ereignis der Konferenz wird anscheinend der Runde Tisch „Brauchen wir nationale Standards im Internet der Dinge?“ Sein, der organisch durch umfassende angewandte Berichte ergänzt wird. Kommen Sie, wenn Ihre stark ausgelasteten Systeme korrekt auf IIoT umgestellt werden.