
Im Laufe der Jahre, in denen Kubernetes in der Produktion betrieben wurde, haben wir viele interessante Geschichten gesammelt, da Fehler in verschiedenen Systemkomponenten zu unangenehmen und / oder unverständlichen Konsequenzen führten, die sich auf den Betrieb von Containern und Pods auswirken. In diesem Artikel haben wir einige der häufigsten oder interessantesten ausgewählt. Selbst wenn Sie nie das Glück haben, auf solche Situationen zu stoßen, ist das Lesen über so kurze Detektive - umso mehr aus erster Hand - immer unterhaltsam, nicht wahr?
Geschichte 1. Supercronic und eiskalter Docker
Auf einem der Cluster erhielten wir regelmäßig einen "eingefrorenen" Docker, der die normale Funktion des Clusters beeinträchtigte. Gleichzeitig wurde in den Docker-Protokollen Folgendes beobachtet
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
In diesem Fehler interessiert uns am meisten die Meldung:
pthread_create failed: No space left on device . Eine kurze Untersuchung der
Dokumentation erklärte, dass Docker den Prozess nicht verzweigen konnte, was dazu führte, dass er regelmäßig „einfrierte“.
Bei der Überwachung des Geschehens entspricht das folgende Bild:

Eine ähnliche Situation wird auf anderen Knoten beobachtet:


Auf denselben Knoten sehen wir:
root@kube-node-1 ~
Es stellte sich heraus, dass dieses Verhalten eine Folge der Arbeit des
Pods mit
Supercronic ist (dem Dienstprogramm auf Go, mit dem wir Cron-Aufgaben in Pods ausführen):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
Das Problem ist folgendes: Wenn eine Aufgabe in Supercronic gestartet wird, kann der von ihr erzeugte Prozess
nicht korrekt abgeschlossen werden und verwandelt sich in einen
Zombie .
Hinweis : Genauer gesagt werden Prozesse durch Cron-Tasks generiert. Supercronic ist jedoch kein Init-System und kann die Prozesse, die seine untergeordneten Elemente erzeugt haben, nicht „übernehmen“. Wenn SIGHUP- oder SIGTERM-Signale auftreten, werden sie nicht an die erzeugten Prozesse übertragen, wodurch die untergeordneten Prozesse nicht beendet werden und im Zombie-Status verbleiben. Mehr dazu können Sie beispielsweise in einem solchen Artikel lesen.Es gibt verschiedene Möglichkeiten, Probleme zu lösen:
- Als vorübergehende Problemumgehung: Erhöhen Sie die Anzahl der PIDs im System zu einem bestimmten Zeitpunkt:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- Oder starten Sie Aufgaben in Supercronic nicht direkt, sondern mit Hilfe derselben Tini , die Prozesse korrekt beenden und keinen Zombie generieren kann.
Verlauf 2. "Zombies" beim Entfernen von cgroup
Kubelet verbrauchte viel CPU:
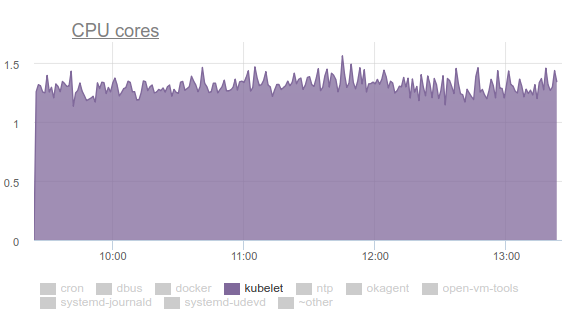
Niemand mag das, also haben wir uns mit
Perf bewaffnet und angefangen, uns mit dem Problem zu befassen. Die Ergebnisse der Untersuchung waren wie folgt:
- Kubelet verbringt mehr als ein Drittel der CPU-Zeit damit, Speicherdaten aus allen Gruppen abzurufen:

- In der Mailingliste der Kernelentwickler finden Sie eine Diskussion des Problems . Kurz gesagt, das Fazit ist, dass verschiedene tmpfs-Dateien und ähnliche Dinge nicht vollständig aus dem System entfernt werden, wenn cgroup gelöscht wird - der sogenannte memcg- Zombie bleibt bestehen. Früher oder später werden sie immer noch aus dem Seiten-Cache entfernt, aber der Speicher auf dem Server ist groß und der Kernel sieht keinen Grund, Zeit zu verschwenden. Daher sammeln sie sich weiter an. Warum passiert das überhaupt? Dies ist ein Server mit Cron-Jobs, der ständig neue Jobs und mit ihnen neue Pods erstellt. Daher werden neue cgroups für Container in ihnen erstellt, die bald gelöscht werden.
- Warum verbringt cAdvisor in kubelet so viel Zeit? Dies lässt sich leicht an der einfachsten Ausführung der
time cat /sys/fs/cgroup/memory/memory.stat . Wenn der Vorgang auf einer fehlerfreien Maschine 0,01 Sekunden dauert, auf einer problematischen cron02 1,2 Sekunden. Die Sache ist, dass cAdvisor, der Daten aus sysfs sehr langsam liest, versucht, den verwendeten Speicher auch in Zombie-Gruppen zu berücksichtigen. - Um Zombies gewaltsam zu entfernen, haben wir versucht, die Caches zu löschen, wie in LKML empfohlen:
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches , aber der Kernel erwies sich als komplizierter und ließ die Maschine hängen.
Was tun? Das Problem wird behoben (
Commit und Beschreibung siehe Versionsmeldung), indem der Linux-Kernel auf Version 4.16 aktualisiert wird.
Verlauf 3. Systemd und sein Mount
Auch hier verbraucht Kubelet auf einigen Knoten zu viele Ressourcen, aber diesmal ist es bereits Speicher:

Es stellte sich heraus, dass das in Ubuntu 16.04 verwendete Systemd ein Problem aufweist. Es tritt auf, wenn die Mounts gesteuert werden, die zum Verbinden von
subPath aus ConfigMaps oder Geheimnissen erstellt werden. Nach Abschluss des Pods
verbleiben der
systemd-Dienst und sein Service-Mount auf dem System. Im Laufe der Zeit sammeln sie eine große Menge an. Es gibt sogar Probleme zu diesem Thema:
- kops # 5916 ;
- kubernetes # 57345 .
... in letzterem wird auf PR in systemd verwiesen:
# 7811 (Problem in systemd ist
# 7798 ).
Das Problem liegt nicht mehr in Ubuntu 18.04, aber wenn Sie Ubuntu 16.04 weiterhin verwenden möchten, kann unsere Problemumgehung zu diesem Thema hilfreich sein.
Also haben wir das folgende DaemonSet erstellt:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
... und es verwendet das folgende Skript:
... und es beginnt alle 5 Minuten mit dem bereits erwähnten Supercronic. Sein Dockerfile sieht folgendermaßen aus:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
Geschichte 4. Wettbewerb bei der Planung von Pods
Es wurde Folgendes festgestellt: Wenn ein Pod auf unserem Knoten platziert wird und sein Bild für eine sehr lange Zeit abgepumpt wird,
beginnt der andere Pod, der zum selben Knoten "
gelangt " ist, einfach
nicht, das Bild des neuen Pods zu ziehen . Stattdessen wartet er darauf, dass das Bild des vorherigen Pods gezogen wird. Infolgedessen wird ein bereits geplanter Pod, dessen Bild in nur einer Minute heruntergeladen werden kann, für lange Zeit in den Status
containerCreating .
In Veranstaltungen wird es so etwas geben:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
Es stellt sich heraus, dass
ein einzelnes Image aus der langsamen Registrierung die Bereitstellung auf dem Knoten
blockieren kann .
Leider gibt es nicht so viele Auswege:
- Versuchen Sie, Ihre Docker-Registrierung direkt im Cluster oder direkt mit dem Cluster zu verwenden (z. B. GitLab-Registrierung, Nexus usw.).
- Verwenden Sie Dienstprogramme wie kraken .
Verlauf 5. Hängende Knoten mit nicht genügend Speicher
Während des Betriebs verschiedener Anwendungen haben wir auch eine Situation erhalten, in der der Knoten nicht mehr zugänglich ist: SSH reagiert nicht, alle Überwachungsdämonen fallen ab und dann ist nichts (oder fast nichts) in den Protokollen abnormal.
Ich werde Ihnen auf den Bildern am Beispiel eines Knotens sagen, auf dem MongoDB funktioniert hat.
So sieht atop
vor dem Absturz aus:

Und so -
nach dem Unfall:

Auch bei der Überwachung gibt es einen scharfen Sprung, bei dem der Knoten nicht mehr zugänglich ist:
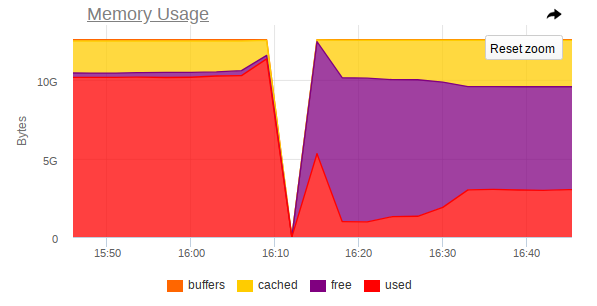
So zeigen die Screenshots, dass:
- Der Arbeitsspeicher des Computers ist fast zu Ende.
- Es wird ein starker Anstieg des RAM-Verbrauchs beobachtet, wonach der Zugriff auf die gesamte Maschine stark deaktiviert wird.
- Bei Mongo kommt eine große Aufgabe an, die den DBMS-Prozess dazu zwingt, mehr Speicher zu verwenden und aktiv von der Festplatte zu lesen.
Es stellt sich heraus, dass, wenn Linux keinen freien Speicher mehr hat (Speicherdruck tritt auf) und kein Swap stattfindet,
bevor der OOM-Killer eintrifft, ein Gleichgewicht zwischen dem Werfen von Seiten in den Seitencache und dem Zurückschreiben auf die Festplatte auftreten kann. Dies geschieht durch kswapd, das mutig so viele Seiten Speicher wie möglich für die spätere Verteilung freigibt.
Leider wird
kswapd bei einer großen E / A-Last in Verbindung mit einer geringen Menge an freiem Speicher
zum Engpass des gesamten Systems , da
alle Seitenfehler der Speicherseiten im System damit verbunden sind. Dies kann sehr lange dauern, wenn die Prozesse keinen Speicher mehr verwenden möchten, sondern am äußersten Rand des OOM-Killer-Abgrunds fixiert sind.
Die logische Frage ist: Warum kommt der OOM-Killer so spät? In der aktuellen OOM-Iteration ist Killer extrem dumm: Er beendet den Prozess nur, wenn der Versuch, eine Speicherseite zuzuweisen, fehlschlägt, d. H. wenn der Seitenfehler fehlschlägt. Dies geschieht lange Zeit nicht, da kswapd mutig Seiten des Speichers freigibt, indem der Seitencache (tatsächlich alle Festplatten-E / A im System) auf die Festplatte zurückgespült wird. Ausführlicher mit einer Beschreibung der Schritte, die erforderlich sind, um solche Probleme im Kernel zu beseitigen, können Sie
hier lesen.
Dieses Verhalten
sollte sich mit dem Linux 4.6+ Kernel
verbessern .
Story 6. Pods stehen noch aus
In einigen Clustern, in denen es wirklich viele Pods gibt, haben wir festgestellt, dass die meisten von ihnen im Status "
Pending sehr lange hängen bleiben, obwohl gleichzeitig die Docker-Container selbst bereits auf den Knoten ausgeführt werden und Sie manuell mit ihnen arbeiten können.
Es ist nichts Falsches daran zu
describe :
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
Nach dem Stöbern gingen wir davon aus, dass kubelet einfach keine Zeit hat, dem API-Server alle Informationen über den Status der Pods, Lebendigkeit / Bereitschaftsproben zu senden.
Nachdem wir die Hilfe studiert hatten, fanden wir die folgenden Parameter:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
Wie Sie sehen können, sind die
Standardwerte recht klein und decken in 90% alle Anforderungen ab ... In unserem Fall war dies jedoch nicht ausreichend. Deshalb setzen wir folgende Werte:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
... und startete die Kubelets neu, woraufhin sie das folgende Bild in den Diagrammen des Zugriffs auf den API-Server sahen:

... und ja, alles begann zu fliegen!
PS
Für die Hilfe beim Sammeln von Fehlern und bei der Vorbereitung des Artikels möchte ich den zahlreichen Ingenieuren unseres Unternehmens und insbesondere Andrei Klimentyev (Kollege aus unserem Forschungs- und Entwicklungsteam) (
zuzzas ) meinen tiefen Dank
aussprechen .
PPS
Lesen Sie auch in unserem Blog: