In Reaktion auf eine Zunahme der Anzahl laufender Anwendungen und der Anzahl von Netzwerkgeräten nimmt die Netzwerkbandbreite zu und die Anforderungen an die Paketzustellung werden verschärft. In einer Reihe von Cloud-kritischen Rechenzentren, die für Unternehmen von entscheidender Bedeutung sind, ermöglicht der traditionelle Ansatz zur Wartung der Infrastruktur keine typischen Aufgaben mehr. Daher wurde das Konzept von AIOps (Algorithmic IT Operations) geboren.
Laut Gartner werden bis zum nächsten Jahr etwa 50% der Unternehmen AIOps einsetzen. Am Beispiel von Huawei FabricInsight, einem Netzwerkanalysator, der Teil einer umfassenden Lösung für Huawei CloudFabric-Rechenzentren ist, können wir darüber sprechen, was ähnliche Tools heute leisten können.
Die digitale Transformation von Unternehmen bietet neue Möglichkeiten - die Einführung der Big-Data-Analyse, die Entwicklung von Algorithmen für maschinelles Lernen - ist nicht mehr nur eine Modeerscheinung, sondern ein bewusstes Bedürfnis, dessen Schließung echten Gewinn bringt. Neue Implementierungen führen jedoch zu einer mehrfachen Erhöhung der Komplexität der Infrastruktur, was gleichzeitig neue Herausforderungen hinsichtlich ihrer Wartung mit sich bringt.
Das Hauptproblem bei der Aufrechterhaltung einer großen Infrastruktur besteht heute in der Datenmenge, die gesammelt und verarbeitet werden muss, um Informationen über den Status des Rechenzentrums zu erhalten, sowie in der Geschwindigkeit, mit der eine relevante Antwort auf die Fehlerursachen gegeben werden sollte. Einerseits nimmt die Anzahl der überwachten Parameter ständig zu, andererseits spielt die Zeit gegen Organisationen, da das Ziel eines Unternehmens darin besteht, die Verfügbarkeit seiner Dienste so schnell wie möglich wiederherzustellen, wenn etwas schief geht (insbesondere angesichts der strengen SLA-Anforderungen). Die Geschwindigkeit des "Anstiegs" des Dienstes nach dem Zusammenbruch wird weitgehend von der Geschwindigkeit der Untersuchung des Vorfalls bestimmt. Und dies hängt wiederum von der Vollständigkeit der Informationen darüber ab, was passiert. Wenn jedoch mindestens 50 bis 100 Server-Racks im Rechenzentrum installiert sind, können Standardüberwachungsmechanismen die hohen Bandbreitenanforderungen und die rechtzeitige Paketzustellung nicht bewältigen.
Warum schlägt SNMP fehl?
Standardmechanismen - SNMP und xFlow - erfassen Daten nur alle 5 bis 15 Minuten und erfassen Informationen. Sie wurden ursprünglich mit Blick auf die Einschränkungen der Nachbearbeitung gesammelter Daten entwickelt, ohne Probleme in Echtzeit identifizieren zu müssen. Und selbst eine derart begrenzte Datenerfassung wirkt sich auf den Betrieb von Netzwerkgeräten aus.
Wenn man bedenkt, dass der problematische Datenverkehr nur 3,65% beträgt, zeigt der traditionelle Ansatz, basierend auf den Analyseergebnissen, nur 30% der Netzwerkprobleme, 70% sind für Überwachungssysteme nicht sichtbar.
Erfahrene Administratoren, die wissen, was und wo sie suchen müssen, müssen die Ursache des Problems anhand der von SNMP und xFlow gesammelten Daten ermitteln. Probleme müssen identifiziert werden, indem große Protokolle und mehrere Fehlermeldungen analysiert und dann manuell Konfigurationsänderungen vorgenommen werden. Mit der Entwicklung von SDN und der Virtualisierung physischer Ressourcen gehört die manuelle Konfiguration der Vergangenheit an. Selbst eine ganze Reihe von Systemadministratoren kann heute nicht mehr sicherstellen, dass die Infrastrukturparameter den Geschäftsanforderungen kontinuierlich entsprechen.
FabricInsight funktioniert anders
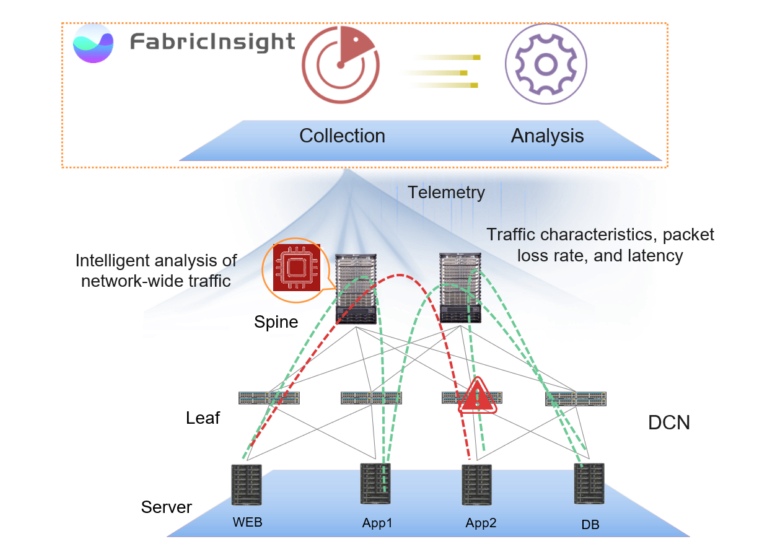
Die FabricInsight Network Analysis Platform bietet einen anderen Ansatz, der die Netzwerkwartung und die Fehlerpunkterkennung automatisiert. FabricInsight analysiert das Verhalten von Anwendungen, identifiziert die von ihnen verwendeten Netzwerkpfade und verfolgt den Status der Geräte auf ihnen.

Dieser Ansatz basiert auf zwei Schlüsselkomponenten - der Erfassung aller verfügbaren Daten und ihrer automatischen Analyse. Dieser Ansatz wird durch eine funktionale Visualisierung und eine Politik der Datenoffenheit ergänzt und ermöglicht es uns, viele der Probleme zu lösen, die zuvor Sackgassen waren.
Sammeln Sie alle verfügbaren Daten.
Der Schlüssel zu einer schnellen Reaktion auf die Situation ist das vollständige Bild dessen, was im Rechenzentrum auf Netzwerkebene geschieht. FabricInsight verwendet einen Push-Telemetrie-Abonnementmechanismus, um alle Servicedaten der zweiten Ebene zeitnah und ohne Stichproben zu erfassen. Um ein vollständiges Bild des Netzwerks zu erhalten, werden Daten zum Betrieb von Geräten, Anwendungen und zum Durchgang des Netzwerkverkehrs (TCP SYN-, FIN- und RST-Pakete) gesammelt. ERSPAN wird zum Spiegeln von Paketen unterstützt, ohne die CPU des Geräts und den GRPC von Google zum Melden der Leistung der Geräte selbst zu verwenden.
Die über das FabricInsight LEAF gesammelten Daten werden an den FabricInsight Collector übertragen, der die zeitlichen Parameter des durch das Netzwerk übertragenen Pakets überwacht. Collector stellt Netzwerkverkehrsdaten Zeitstempel zur Verfügung, codiert sie und sendet sie über HTTP an FabricInsight Analyzer. Mit diesem Ansatz können Sie maximale Informationen über das Netzwerk sammeln und sogar kurzfristige Verkehrsstöße erfassen, die von "klassischen" Lösungen nicht erkannt werden können.
Gleichzeitig untersucht FabricInsight IP-Pakete nicht (es erfasst nicht deren Inhalt) und verwendet bei seiner Arbeit nur Header. So kann es in geschäftskritischen Bereichen eingesetzt werden, beispielsweise in denen mit personenbezogenen Daten gearbeitet wird.
Echtzeitanalyse
Das zweite integrale Element des Systems ist der FabricInsight Analyzer. Durch den Empfang der gesammelten Daten werden Verkehrspfade identifiziert und Algorithmen ausgeführt, die die Situation nahezu in Echtzeit analysieren. Im Allgemeinen korreliert FabricInsight Analyzer den Netzwerkverkehr mit Anwendungen, sodass Sie Probleme schnell identifizieren und beheben können. Aufgrund des maschinellen Lernens werden die Algorithmen „trainiert“, um normales und abnormales Verhalten der Infrastruktur zu identifizieren.
NetworkInsight spiegelt die Ergebnisse der Netzwerkanalyse in seiner Benutzeroberfläche in Form von Karten des Netzwerkstatus, der Anwendungsinteraktionen, der Analyse für einzelne Anwendungen usw. wider, die in Echtzeit aktualisiert werden. Die Schnittstelle ist so implementiert, dass die Ebene der Anwendungen und spezifischen physischen Geräte, die für die Funktionsfähigkeit des Netzwerks verantwortlich sind, visuell in Beziehung gesetzt wird. Dies beschleunigt die Fehlerbehebung und die Methoden zu deren Lösung.
Wenn Anomalien festgestellt werden, werden die anfänglichen Informationen automatisch gespeichert. Je nachdem, welche Probleme festgestellt wurden (die Speicherdauer ist einstellbar), warnt FabricInsight den Benutzer bei Bedarf. Darüber hinaus werden die Verfahren zur Korrektur der Situation „mit einem Mausklick“ über die grafische Oberfläche initialisiert. Gleichzeitig werden verschiedene Fehlerkorrekturmuster analysiert, um den relevantesten Ansatz zu finden.
Fälle
Um Anomalien im Rechenzentrum zu identifizieren, wird eine Korrelationsanalyse des Betriebs von Anwendungen, Geräten und Verkehrspfaden verwendet, sodass verschiedene Arten von Anomalien aufgezeichnet werden - sowohl vorübergehend als auch langfristig.

Übrigens können die meisten der oben genannten temporären Anomalien mit dem klassischen Ansatz nicht behoben werden. Dies gilt auch für einige langfristige Anomalien. Ein ziemlich häufiges Beispiel ist ein "schiefes" Software-Update. Angenommen, eine bestimmte Anwendung wurde im Rechenzentrum ausgeführt, die bestimmten Datenverkehr generiert hat. Nach der Aktualisierung hat sich das Volumen dieses Datenverkehrs dramatisch geändert. Beispielsweise hat der Anwendungsdurchsatz abgenommen und die Verzögerungen haben zugenommen. Diese Anomalie wird von FabricInsight behoben.
Ein weiteres Beispiel ist die allmähliche Verschlechterung des optischen Kommunikationsmoduls (Leistungsverlust) vor dem Ausfall. Eine Verschlechterung bestimmt die Instabilität der Übertragung, was über lange Zeiträume auf die Notwendigkeit eines frühzeitigen Austauschs der Ausrüstung hinweisen kann. Es ist jedoch äußerst schwierig, dies mit einem Standardansatz zu identifizieren.

Als Antwort auf dieses Problem zeigt die FabricInsight-Schnittstelle den Status aller optischen Module im System zusammen mit einer Schätzung der Wahrscheinlichkeit ihres Ausfalls an.

Integration
Obwohl FabricInsight im Januar dieses Jahres auf dem russischen Markt erschien, wurde es bereits in ICBC, China UnionPay, der China Merchants Bank, PICC und anderen großen Rechenzentren auf Basis der Huawei-Infrastruktur eingesetzt.
Bisher unterstützt die Lösung nur unsere Switches (auf Broadcom-Chipsätzen), aber in Zukunft ist geplant, über das Ökosystem eines Herstellers hinauszugehen. Bei der Arbeit an FabricInsight haben wir uns zunächst auf offene Standards konzentriert, damit wir uns normalerweise mit Tools von Drittanbietern anfreunden können. Mit Druid können Sie beispielsweise Daten aus FabricInsight exportieren, über die Sie Informationen an Visualisierer von Drittanbietern senden können. FabricInsight ist auch bereits in das offene Rendering-Tool von Grafana integriert.
Im Allgemeinen sind AIOps-Tools wie unser FabricInsight eine logische Möglichkeit, Tools zur Überwachung und Wartung der Infrastruktur zu entwickeln. Es scheint uns, dass dies der einzige Weg ist, die SLA für Dienstleistungen weiterhin einzuhalten.