Hallo Habr!
Mein Name ist Anton Markelov, ich bin Ops-Ingenieur bei United Traders. Wir sind auf die eine oder andere Weise an Projekten beteiligt, die mit Investitionen, Börsen und anderen finanziellen Angelegenheiten verbunden sind. Wir sind kein sehr großes Unternehmen, etwa 30 Entwicklungsingenieure, die Waage ist angemessen - etwas weniger als hundert Server. Während des quantitativen und qualitativen Wachstums unserer Infrastruktur hat die klassische Lösung „Wir halten sowohl die Anwendung als auch ihre Datenbank auf demselben Server“ in Bezug auf Zuverlässigkeit und Geschwindigkeit nicht mehr zu uns passen. Seitens der Analysten mussten datenbankübergreifende Abfragen erstellt werden. Die Betriebsabteilung hatte es satt, mit der Sicherung und Überwachung einer großen Anzahl von Datenbankservern herumzuspielen. Darüber hinaus hat das Speichern des Status auf demselben Computer wie die Anwendung selbst die Flexibilität der Ressourcenplanung und die Ausfallsicherheit der Infrastruktur erheblich verringert.
Der Übergang zur aktuellen Architektur war evolutionär. Verschiedene Lösungen wurden getestet, um Entwicklern und Analysten eine bequeme Schnittstelle zu bieten und die Zuverlässigkeit und Verwaltbarkeit dieser gesamten Wirtschaft zu erhöhen. Ich möchte über die Hauptphasen der Modernisierung unseres DBMS sprechen, zu welchem Rechen wir gekommen sind und zu welchen Entscheidungen wir als Ergebnis einer fehlertoleranten unabhängigen Umgebung gekommen sind, die Betriebsingenieuren, Entwicklern und Analysten bequeme Interaktionsmöglichkeiten bietet. Ich hoffe, dass unsere Erfahrung Ingenieuren aus Unternehmen unserer Größenordnung von Nutzen sein wird.
Dieser Artikel ist eine Zusammenfassung meines
Berichts auf der UPTIMEDAY-Konferenz. Vielleicht ist das Videoformat für jemanden angenehmer, obwohl der Autor mit meinen Händen etwas besser ist als ein Mundsprecher.
Der „Schneeflockenmann“ mit KDPV wurde schamlos von Maxim Dorofeev
entlehnt .
Wachstumskrankheiten
Wir haben eine Microservice-Architektur, Services werden hauptsächlich in Java oder Kotlin unter Verwendung des Spring-Frameworks geschrieben. Neben jedem Microservice befindet sich eine PostgreSQL-Basis. Alles wird von Nginx abgedeckt, um den Zugriff zu ermöglichen. Ein typischer Mikroservice ist eine Anwendung in Spring Boot, die ihre Daten in PostgreSQL (gleichzeitig Teil der Anwendungen und in ClickHouse) schreibt, über Kafka mit Nachbarn kommuniziert und über einige REST- oder GraphQL-Endpunkte für die Kommunikation mit der Außenwelt verfügt.
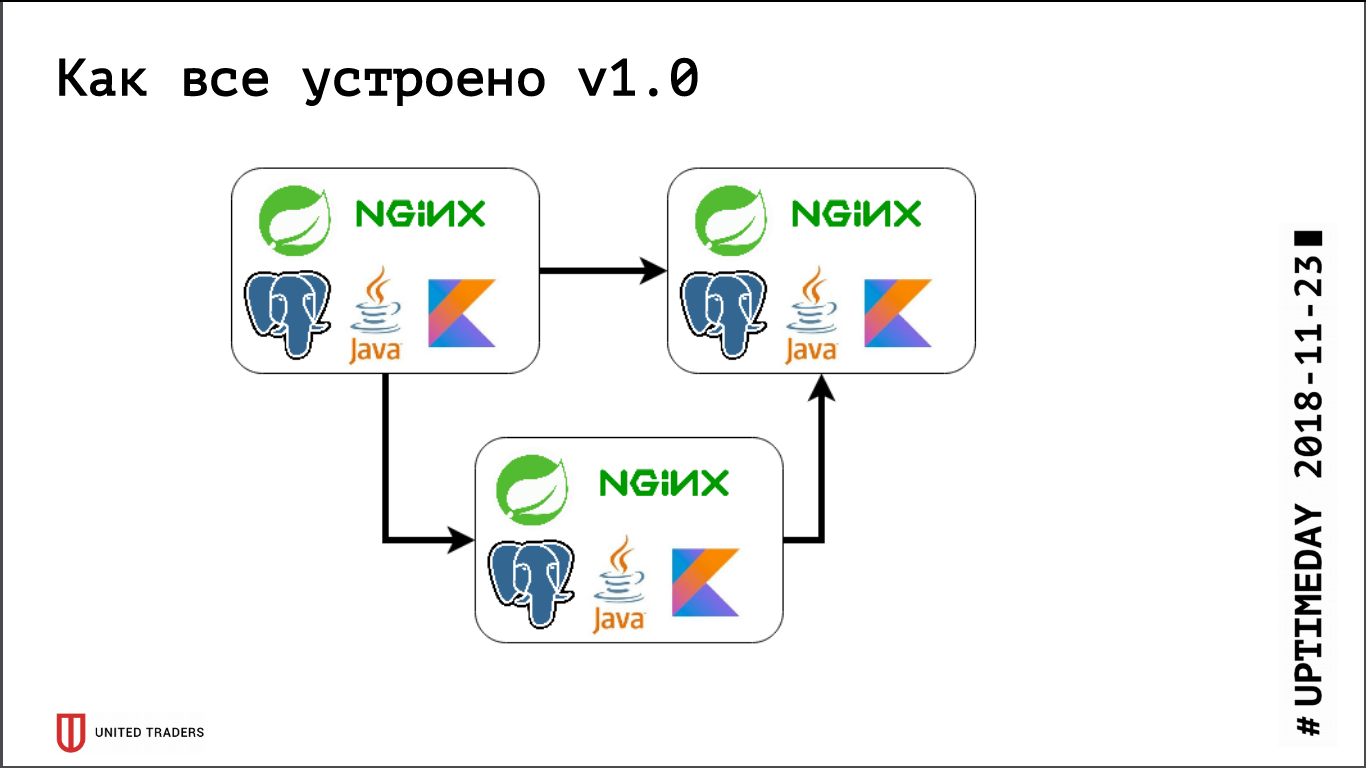
Früher, als wir noch sehr klein waren, hatten wir nur mehrere Server in DigitalOcean, Kafka war noch nicht da, die gesamte Kommunikation erfolgte über REST. Das heißt, wir haben ein Droplet genommen, dort Java, PostgreSQL und Nginx installiert und dort Zabbix gestartet, um die Serverressourcen und die Verfügbarkeit von Service-Endpunkten zu überwachen. Sie stellten alles mit Hilfe von Ansible bereit, wir hatten standardisierte Playbooks, vier bis fünf Rollen rollten den gesamten Service aus. Solange wir relativ gesehen 6 Server in der Produktion und 3 im Test hatten, konnte man irgendwie damit leben.
Dann begann die aktive Entwicklungsphase, die Anzahl der Anwendungen wuchs, zehn Microservices wurden zu vierzig, ihre Funktionalität begann sich zu ändern, und die Integration mit externen Systemen wie CRM, Kundenstandorten und dergleichen erschien. Wir haben den ersten Schmerz. Einige Anwendungen verbrauchten mehr Ressourcen, drangen nicht mehr in vorhandene Server ein, wir bekamen Tröpfchen, zogen Anwendungen hin und her und wählten viele Hände. Es tat ziemlich weh - niemand mag dumme mechanische Arbeit - ich wollte mich schnell entscheiden. Also haben wir uns auf den Weg gemacht - wir haben nur 3 große dedizierte Server anstelle von 10 Cloud-Tröpfchen genommen. Dies schloss das Problem für eine Weile, aber es wurde offensichtlich, dass es Zeit war, Optionen für eine Art Orchestrierung und Server-Rebalancing auszuarbeiten. Wir haben begonnen, Lösungen wie DC / OS und Kubernetes genau zu untersuchen und unser Fachwissen in diesem Bereich schrittweise zu erweitern.
Etwa zur gleichen Zeit hatten wir eine analytische Abteilung, die regelmäßig schwierige Anfragen stellen, Berichte erstellen und schöne Dashboards erstellen musste, was uns einen zweiten Schmerz bereitete. Erstens haben Analysten die Basis stark belastet, und zweitens benötigten sie datenbankübergreifende Abfragen, weil Jeder Mikroservice behielt eine ziemlich enge Datenscheibe. Wir haben mehrere Systeme getestet. Zuerst haben wir versucht, alles durch Replikation auf Tabellenebene zu lösen (es war wieder im neunten PostgreSQL, es gab keine sofort einsatzbereite logische Replikation), aber die daraus resultierenden Handwerke, die auf pglogical, Presto, Slony-I und Bucardo basierten, haben dies nicht vollständig getan arrangiert. Zum Beispiel hat pglogical die Migration nicht unterstützt - eine neue Version des Microservices wurde eingeführt, die Struktur der Datenbank wurde geändert, Java selbst hat die Struktur mithilfe von Flyway geändert, und bei Replikaten in pglogical muss alles manuell geändert werden. Ansonsten fehlte entweder etwas oder es war zu schwierig.
Super Sklave
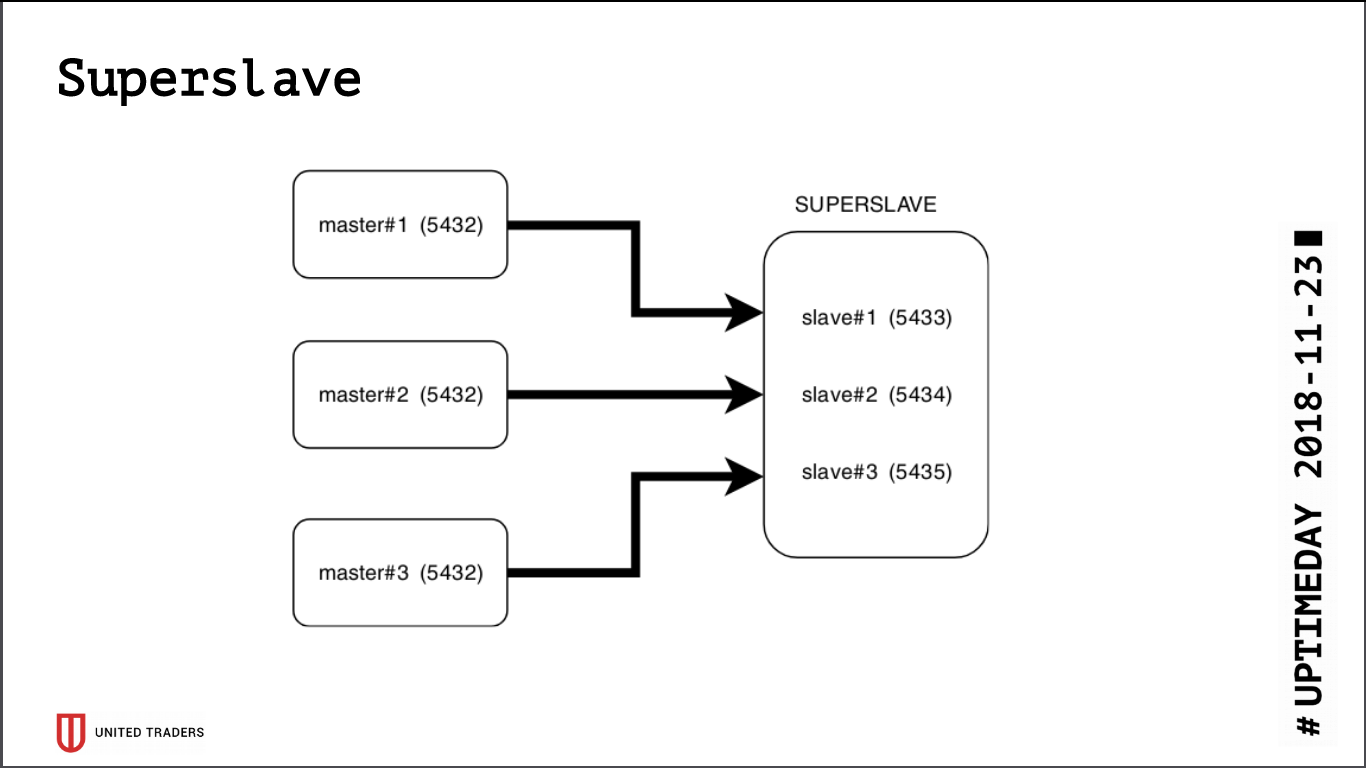
Als Ergebnis der Forschung wurde eine einfache und brutale Lösung namens Superslave geboren: Wir nahmen einen separaten Server, konfigurierten darauf einen Slave für jeden Produktionsserver an verschiedenen Ports und erstellten eine virtuelle Datenbank, die die Datenbanken der Slaves über postgres_fdw (Foreign Data Wrapper) kombiniert. Das heißt, all dies wurde einfach und zuverlässig mit Standard-Postgres implementiert, ohne dass zusätzliche Entitäten eingeführt wurden: Mit einer einzigen Anfrage konnten Daten aus mehreren Datenbanken abgerufen werden. Wir haben diese virtuelle Basis an Analysten weitergegeben. Ein zusätzliches Plus ist, dass das schreibgeschützte Replikat selbst bei einem Fehler mit Zugriffsrechten dort nichts schreiben konnte.
Wir haben
Redash zur Visualisierung verwendet, es weiß, wie man Diagramme zeichnet, Anforderungen nach einem Zeitplan ausführt, zum Beispiel einmal am Tag, und verfügt über ein gewichtiges System von Rechten, sodass wir Analysten und Entwickler dorthin gehen lassen.

Parallel dazu setzte sich das Wachstum fort, Kafka erschien in der Infrastruktur als Bus und ClickHouse für Analytics-Speicher. Sie sind leicht aus der Schachtel zu gruppieren, unser Supersklave vor ihrem Hintergrund sah aus wie ein ungeschicktes Fossil. Außerdem blieb PostgreSQL der einzige Status, der nach der Anwendung gezogen werden musste (wenn er noch auf einen anderen Server übertragen werden musste), und wir wollten unbedingt eine zustandslose Anwendung, um eng mit Kubernetes und ihm zu experimentieren ähnliche Plattformen.
Wir haben nach einer Lösung gesucht, die die folgenden Anforderungen erfüllt:
- Fehlertoleranz: Wenn N Server ausfallen, funktioniert der Cluster weiter.
- Für Anwendungen sollte alles wie zuvor bleiben, keine Änderungen im Code;
- einfache Bereitstellung und Verwaltung;
- weniger Abstraktionsebenen gegenüber regulärem PostgreSQL;
- Im Idealfall sollte der Lastenausgleich so erfolgen, dass nicht alle Anforderungen an einen Server gesendet werden.
- Idealerweise ist es in einer vertrauten Sprache geschrieben.
Es gab nicht viele Kandidaten:
- Standard-Streaming-Replikation (repmgr, Patroni, Stolon);
- Trigger-basierte Replikation (Londiste, Slony);
- Abfrage-Replikation der mittleren Schicht (pgpool-II);
- synchrone Replikation mit mehreren Kernservern (Bucardo).
Zum großen Teil hatten wir bereits schlechte Erfahrungen beim Bau der Querbasis, so dass Patroni und Stolon blieben. Patroni ist in Python geschrieben, Stolon in Go, wir haben genug Erfahrung in beiden Sprachen. Darüber hinaus haben sie eine ähnliche Architektur und Funktionalität, sodass die Wahl aus subjektiven Gründen getroffen wurde: Patroni wurde von Zalando entwickelt, und wir haben einmal versucht, mit ihrem Nakadi-Projekt (REST-API für Kafka) zu arbeiten, bei dem wir auf einen schwerwiegenden Mangel an Dokumentation stießen.
Stolon
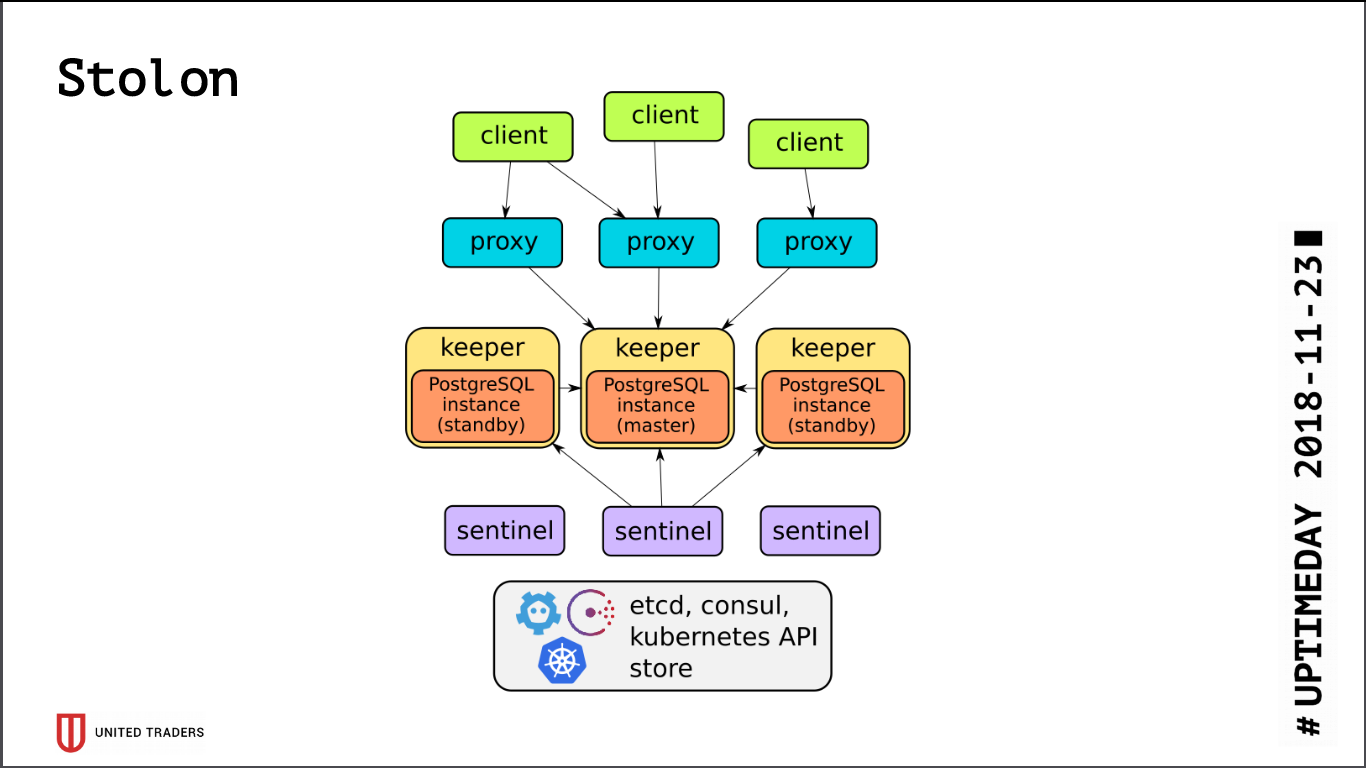
Die Architektur von
Stolon ist recht einfach: Es gibt N Server, mit Hilfe von etcd / consul wird ein Leader ausgewählt, PostgreSQL wird darin im Assistentenmodus gestartet und auf andere Server repliziert. Dann gehen Stolon-Proxys zu diesem PostgreSQL-Master und geben vor, Anwendungen mit gewöhnlichen Postgres zu sein, und Clients gehen zu diesen Proxys. Im Falle des Verschwindens eines Meisters finden Wiederwahlen statt, jemand anderes wird Meister, der Rest wird bereit. Es gibt nur wenige Abstraktionsebenen. PostgreSQL wird wie gewohnt installiert. Die einzige Einschränkung besteht darin, dass die PostgreSQL-Konfiguration in etcd gespeichert ist und etwas anders konfiguriert ist.
Beim Testen des Clusters sind einige Probleme aufgetreten:
- Stolon weiß nicht, wie man auf ZooKeeper arbeitet, nur Konsul oder etcd;
- etcd ist sehr empfindlich gegenüber E / A. Wenn Sie PostgreSQL und etcd auf demselben Server behalten, benötigen Sie auf jeden Fall schnelle SSDs.
- Selbst auf SSDs müssen usw. Timeouts konfiguriert werden, da sonst unter Last alles kaputt geht. Der Cluster glaubt, dass der Master heruntergefallen ist, und unterbricht ständig die Verbindungen.
- Standardmäßig ist max_connections unter PostgreSQL klein (200). Sie müssen es an Ihre Anforderungen anpassen.
- Ein Cluster von drei etcd überlebt den Tod von nur einem Server. Idealerweise benötigen Sie eine Konfiguration, zum Beispiel 5 etcd + 3 Stolon.
- Nach dem Auspacken gehen alle Verbindungen zum Master, die Slaves sind für die Verbindung nicht zugänglich.
Da alle Verbindungen zu PostgreSQL zum Assistenten gehen, stoßen wir erneut auf ein Problem mit umfangreichen Analyseanforderungen. etcd reagierte manchmal schmerzhaft auf die hohe Belastung des Masters und schaltete ihn um. Durch das Umschalten des Assistenten werden immer die Verbindungen unterbrochen. Die Anfrage wurde neu gestartet, alles begann von vorne. Zur Umgehung dieses Problems wurde
ein Python-Skript geschrieben, das stolonctl-Adressen von Live-Slaves anforderte und eine Konfiguration für HAProxy generierte, um Anforderungen an diese umzuleiten.
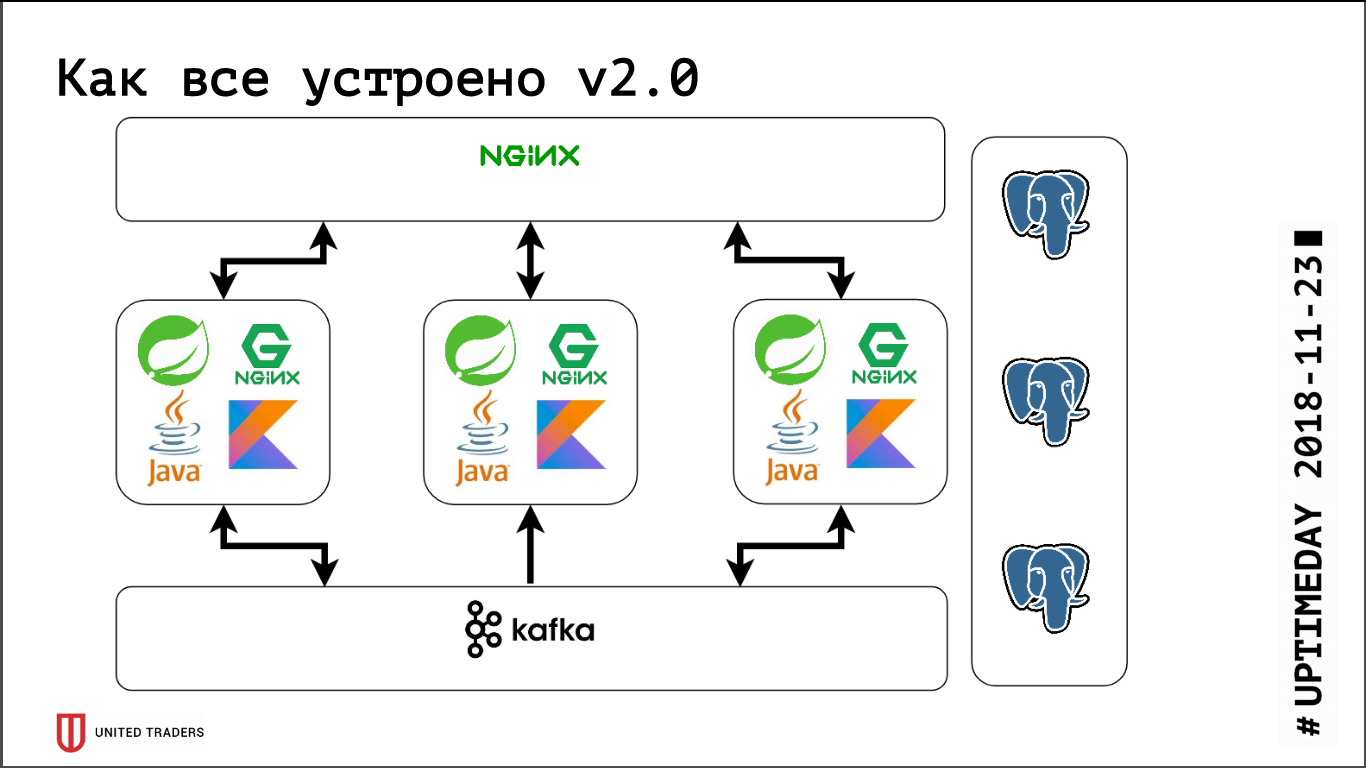
Das folgende Bild stellte sich heraus: Anforderungen von Anwendungen gehen an den Stolon-Proxy-Port, der sie an den Master weiterleitet, und Anforderungen von Analysten (sie sind immer schreibgeschützt) gehen an den HAProxy-Port, der sie an einen Slave weiterleitet.
Außerdem wurde heute buchstäblich eine PR bei Stolon verabschiedet, die es ermöglichte, Informationen über Stolon-Instanzen an eine Dienstentdeckung eines Drittanbieters zu senden.
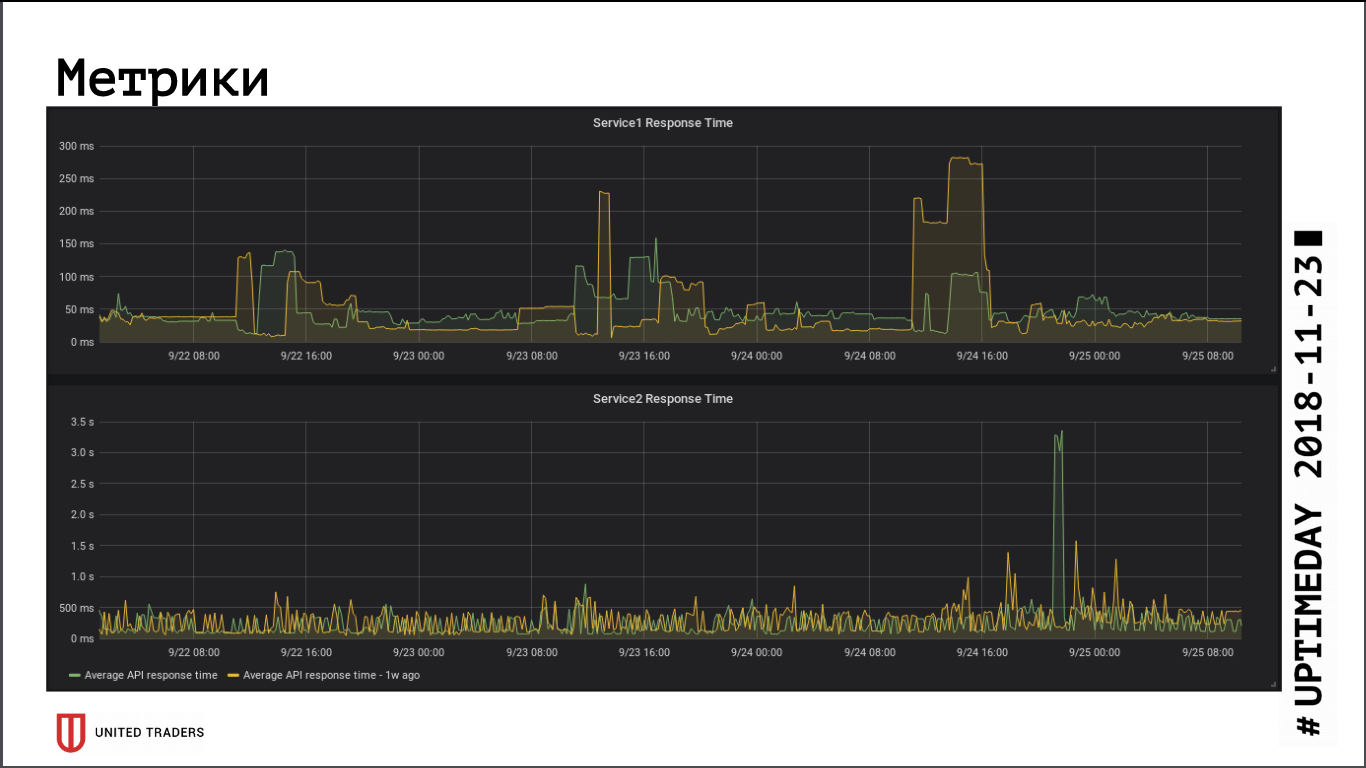
Gemessen an den Metriken für die Reaktionsgeschwindigkeit der Anwendung hatte der Übergang zu einem Remote-Cluster keinen wesentlichen Einfluss auf die Leistung. Die durchschnittliche Antwortzeit hat sich nicht geändert. Die daraus resultierende Netzwerklatenz wurde offenbar dadurch kompensiert, dass sich die Datenbank jetzt auf einem dedizierten Server befindet.
Stolon überlebt ohne Probleme einen Assistentenabsturz (Serververlust, Netzwerkverlust, Festplattenverlust), wenn der Server zum Leben erweckt wird - er setzt das Replikat automatisch zurück. Der schwächste Punkt in Stolon ist etcd, Fehler darin setzen den Cluster. Wir hatten einen typischen Unfall: Eine Gruppe von drei Knoten usw., zwei wurden abgeholzt. Alles, das Quorum war kaputt, etcd ging in einen ungesunden Zustand, der Stolon-Cluster akzeptiert keine Verbindungen, einschließlich Anfragen von stolonctl. Wiederherstellungsschema: Verwandeln Sie etcd auf dem überlebenden Server in einen Einzelknotencluster und fügen Sie die Mitglieder wieder hinzu. Fazit: Um den Tod von zwei Servern zu überleben, müssen mindestens 5 Instanzen usw. vorhanden sein.
Fehler überwachen und abfangen
Mit dem Wachstum der Infrastruktur und der Komplexität von Microservices wollte ich mehr Informationen darüber sammeln, was in der Anwendung und auf der Java-Maschine geschieht. Wir konnten Zabbix nicht an die neue Umgebung anpassen: Dies ist unter den Bedingungen einer sich ändernden Infrastruktur sehr unpraktisch. Ich musste entweder Krücken durch die API schleifen oder mit meinen Händen hineinklettern, was noch schlimmer ist. Die Datenbank ist schlecht an schwere Lasten angepasst, und im Allgemeinen ist es sehr unpraktisch, all dies in eine relationale Datenbank zu stellen.
Aus diesem Grund haben wir Prometheus für die Überwachung ausgewählt. Er hat einen sofort einsatzbereiten Aktuator für Spring-Anwendungen zur Bereitstellung von Metriken. Für Kafka haben sie JMX Exporter geschraubt, der auch Metriken auf komfortable Weise bereitstellt. Die Exporteure, die nicht "in der Box" gefunden wurden, haben wir uns in Python geschrieben, es gibt ungefähr zehn von ihnen. Wir visualisieren Grafana, sammeln die Protokolle mit Graylog (da er jetzt Beats unterstützt).
Wir verwenden
Sentry , um Fehler zu sammeln. Er schreibt alles in strukturierter Form, zeichnet Grafiken, zeigt, was öfter und seltener passiert ist. Normalerweise wenden sich Entwickler sofort nach der Bereitstellung an Sentry, um festzustellen, ob es Spitzenwerte gibt oder ob ein Rollback dringend erforderlich ist. Es stellt sich heraus, dass Fehler schnell erkannt werden, ohne dass die Protokolle ausgewählt werden müssen.
Das ist alles für den Moment, wenn das Format der Artikel den Lesern passt, werden wir weiter über unsere Infrastruktur sprechen, es macht immer noch viel Spaß: Kafka und Analyselösungen für Ereignisse, CI / CD-Kanal für Windows-Anwendungen und Abenteuer mit Openshift.