
Teil 1/3 hier .
Teil 2/3 hier .
Hallo allerseits! Und hier ist der dritte Teil der Kubernetes auf Bare-Metal-Führung! Ich werde auf die Überwachung des Clusters und das Sammeln von Protokollen achten. Außerdem werden wir eine Testanwendung starten, um die vorkonfigurierten Clusterkomponenten zu verwenden. Anschließend werden wir mehrere Stresstests durchführen und die Stabilität dieses Clusterschemas überprüfen.
Das beliebteste Tool, das die Kubernetes-Community zur Bereitstellung einer webbasierten Oberfläche und zum Abrufen von Cluster-Statistiken anbietet, ist das Kubernetes-Dashboard . Tatsächlich befindet es sich noch in der Entwicklung, aber selbst jetzt kann es einige zusätzliche Daten zur Fehlerbehebung bei Anwendungsproblemen und zur Verwaltung von Clusterressourcen bereitstellen.
Das Thema ist teilweise umstritten. Stimmt es, dass Sie eine Art Webinterface benötigen, um den Cluster zu verwalten, oder reicht es aus, das kubectl- Konsolentool zu verwenden? Nun, manchmal ergänzen sich diese Optionen.
Lassen Sie uns unser Kubernetes Dashboard erweitern und sehen. Bei einer Standardbereitstellung wird dieses Dashboard nur an der lokalen Hostadresse gestartet. Daher müssen Sie den Befehl kubectl proxy für die Erweiterung verwenden , er ist jedoch weiterhin nur auf Ihrem lokalen kubectl-Steuergerät verfügbar. Aus Sicherheitsgründen nicht schlecht, aber ich möchte Zugriff im Browser außerhalb des Clusters haben und bin bereit, einige Risiken einzugehen (schließlich wird SSL mit einem effektiven Token verwendet).
Um meine Methode anzuwenden, müssen Sie die Standardbereitstellungsdatei im Serviceabschnitt geringfügig ändern. Um dieses Dashboard unter einer offenen Adresse zu öffnen, verwenden wir unseren Load Balancer.
Wir betreten das Maschinensystem mit dem konfigurierten kubectl- Dienstprogramm und erstellen:
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
Führen Sie dann Folgendes aus:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
Wie Sie sehen, hat unser BN für diesen Service die IP 192.168.0.240 hinzugefügt. Öffnen Sie nun https://192.168.0.240 , um das Kubernetes-Dashboard anzuzeigen.
Es gibt zwei Möglichkeiten, um Zugriff zu erhalten: Verwenden Sie die Datei admin.conf von unserem admin.conf , die wir zuvor beim Einrichten von kubectl verwendet haben, oder erstellen Sie ein spezielles Dienstkonto mit einem Sicherheitstoken.
Erstellen wir einen Administrator:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
Jetzt benötigen Sie einen Token, um in das System einzutreten:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
Kopieren Sie das Token und fügen Sie es in das Token-Feld auf dem Anmeldebildschirm ein.
Nach dem Betreten des Systems können Sie den Cluster etwas genauer untersuchen - ich mag dieses Tool.
Der nächste Schritt zur Vertiefung des Überwachungssystems unseres Clusters ist die Installation von Heapster .
Mit Heapster können Sie den Containercluster überwachen und die Leistung für Kubernetes (Version v1.0.6 und höher) analysieren. Es bietet entsprechende Plattformen.
Dieses Tool bietet Statistiken zur Cluster-Nutzung über die Konsole und fügt dem Kubernetes-Dashboard weitere Informationen zu Knoten- und Herdressourcen hinzu.
Es gibt kaum Schwierigkeiten, es auf blankem Metall zu installieren, und ich musste einige Nachforschungen anstellen: Warum funktioniert das Tool in der Originalversion nicht, aber ich habe eine Lösung gefunden.
Fahren wir also fort und unterstützen dieses Add-On:
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
Dies ist die am häufigsten verwendete Standardbereitstellungsdatei aus der Heapster-Community, mit nur einem kleinen Unterschied: Damit sie in unserem Cluster funktioniert, wird die Zeile " source = " in der Heapster-Bereitstellung wie folgt geändert:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
In dieser Beschreibung finden Sie alle diese Optionen. Ich habe den Kubelet-Port auf 10250 geändert und die Überprüfung des SSL-Zertifikats deaktiviert (es gab ein kleines Problem damit).
Wir müssen auch Berechtigungen hinzufügen, um Knotenstatistiken in der Heapster-RBAC-Rolle abzurufen. Fügen Sie diese wenigen Zeilen am Ende der Rolle hinzu:
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
Zusammenfassend sollte Ihre RBAC-Rolle folgendermaßen aussehen:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
Ok, jetzt führen wir den Befehl aus, um sicherzustellen, dass die Heapster-Bereitstellung erfolgreich gestartet wurde.
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
Wenn Sie Daten zur Ausgabe erhalten haben, ist alles korrekt. Kehren wir zu unserer Dashboard-Seite zurück und sehen uns die neuen Grafiken an, die jetzt verfügbar sind.
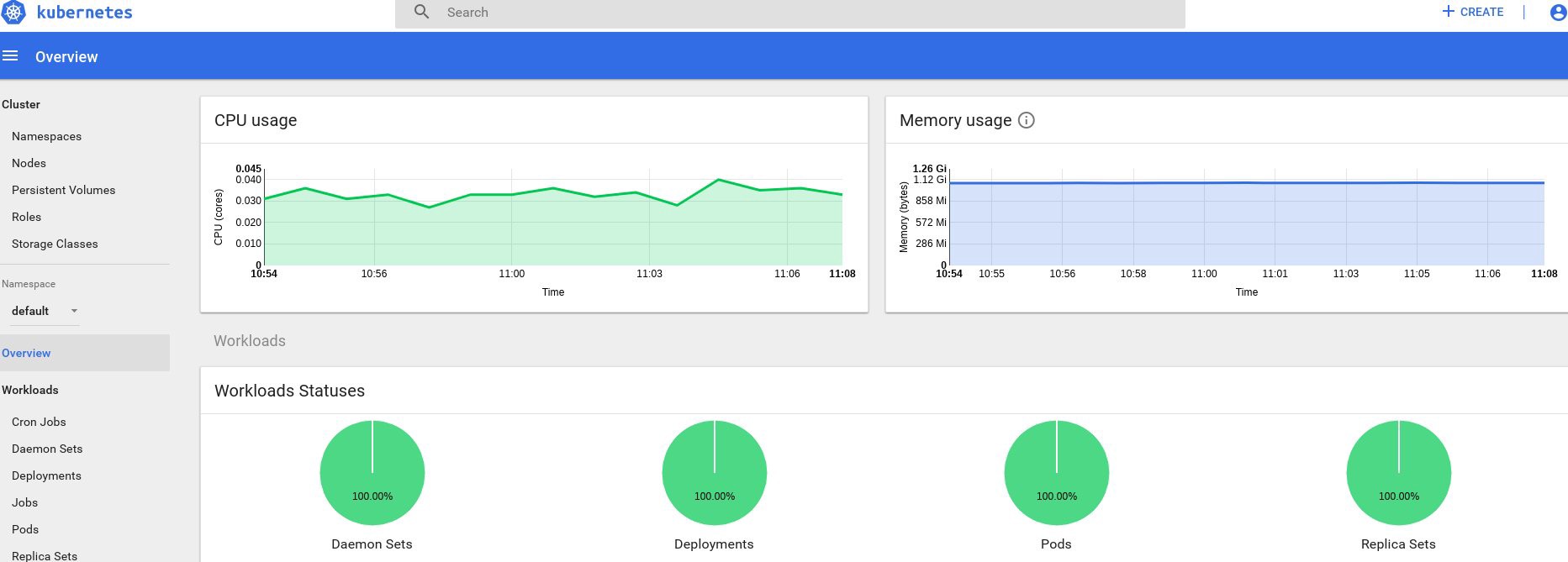

Von nun an können wir auch den tatsächlichen Ressourcenverbrauch für Clusterknoten, Herde usw. verfolgen.
Wenn dies nicht ausreicht, können Sie die Statistik durch Hinzufügen von InfluxDB + Grafana weiter verbessern. Dadurch können Sie Ihre eigenen Grafana-Panels zeichnen.
Wir werden diese Version der InfluxDB + Grafana-Installation von der Heapster Git-Seite verwenden, aber wie üblich werden wir Korrekturen vornehmen. Da wir die Heapster-Bereitstellung bereits konfiguriert hatten, müssen wir nur Grafana und InfluxDB hinzufügen und dann die vorhandene Heapster-Bereitstellung so ändern, dass auch Metriken in Influx eingefügt werden.
Ok, erstellen wir die InfluxDB- und Grafana-Bereitstellungen:
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
Als nächstes kommt Grafana. Vergessen Sie nicht, die Diensteinstellungen zu ändern, um den MetaLB-Load-Balancer zu aktivieren und die externe IP-Adresse für den Grafana-Dienst abzurufen.
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
Und erschaffe sie:
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
Es ist Zeit, die Heapster-Bereitstellung zu ändern und die InfluxDB-Verbindung hinzuzufügen. Sie müssen nur eine Zeile hinzufügen:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
Bearbeiten Sie die Heapster-Bereitstellung:
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
Suchen Sie nun die externe IP-Adresse des Grafana-Dienstes und melden Sie sich beim darin enthaltenen System an:
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
Öffnen Sie http://192.168.0.241 in einem Browser und verwenden Sie zum ersten Mal die Anmeldeinformationen admin / admin:

Als ich mich einloggte, war mein Grafana leer, aber zum Glück können wir alle erforderlichen Dashboards von grafana.com erhalten . Sie müssen die Panels Nr. 3649 und 3646 importieren. Wählen Sie beim Importieren die richtige Datenquelle aus.
Überwachen Sie anschließend die Nutzung der Ressourcen von Knoten und Herden und erstellen Sie natürlich Ihre eigenen einzigartigen Dashboards.
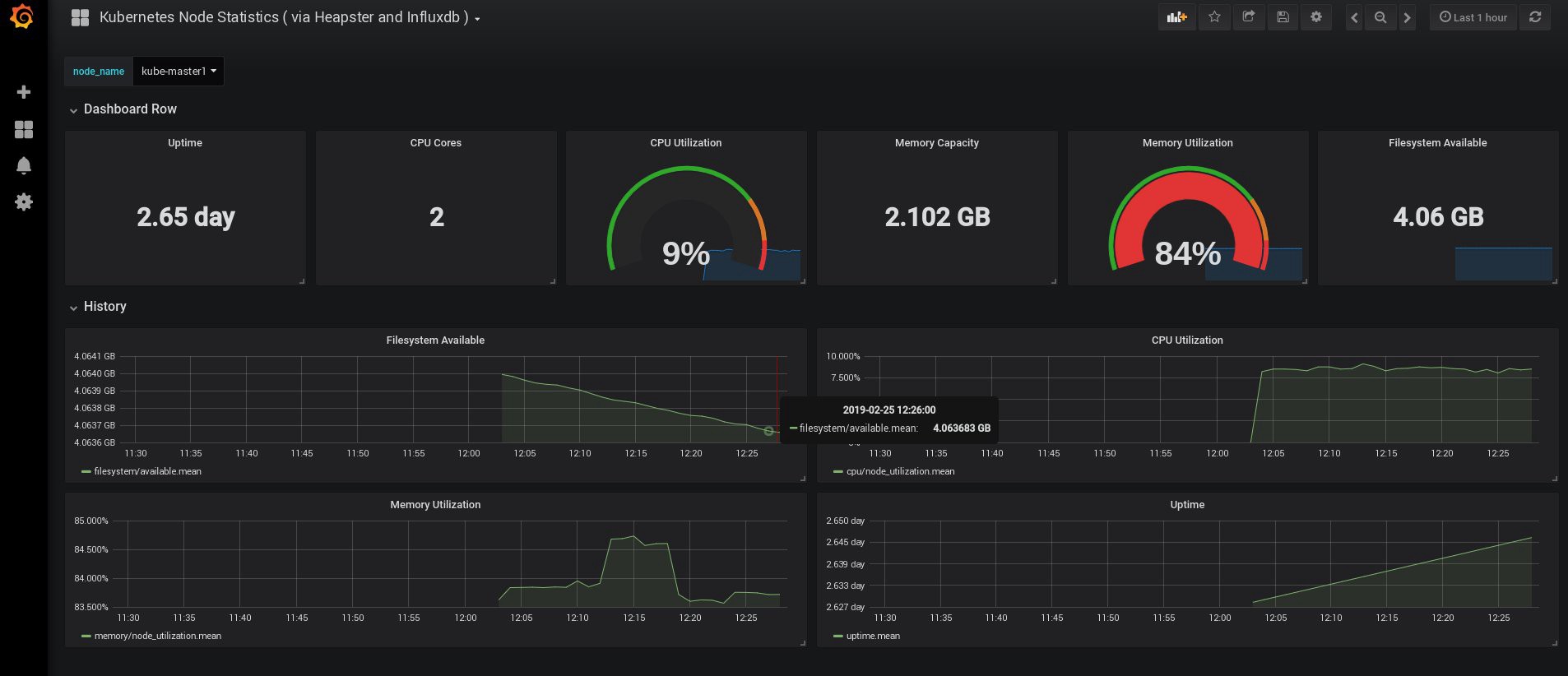
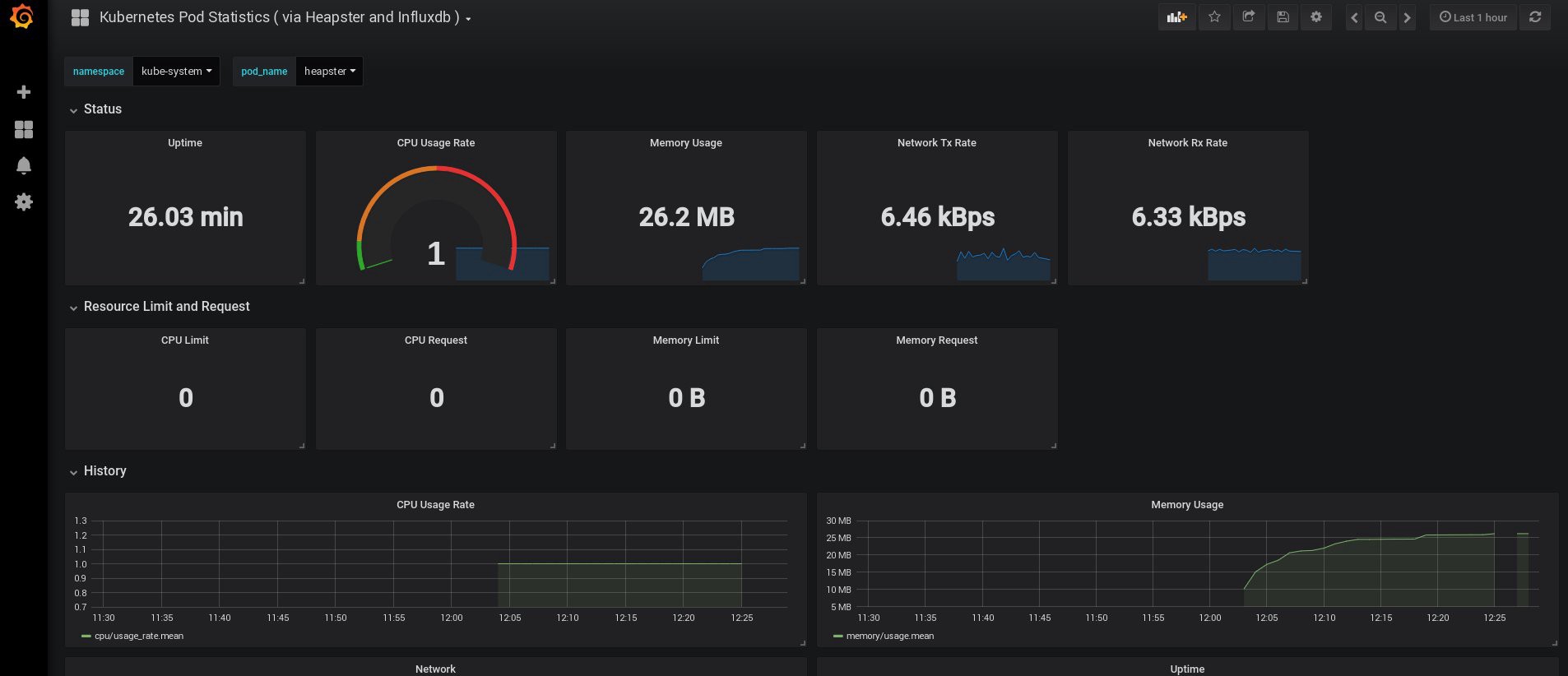
Lassen Sie uns zunächst mit der Überwachung enden. Die folgenden Elemente, die wir möglicherweise benötigen, sind die Protokolle zum Speichern unserer Anwendungen und des Clusters. Es gibt verschiedene Möglichkeiten, dies zu implementieren, und alle sind in der Kubernetes- Dokumentation beschrieben . Aufgrund meiner eigenen Erfahrung bevorzuge ich die externen Einstellungen der Elasticsearch- und Kibana-Dienste sowie nur die Registrierungsagenten, die auf jedem Kubernetes-Arbeitsknoten ausgeführt werden. Dies schützt den Cluster vor Überlastungen, die mit einer großen Anzahl von Protokollen und anderen Problemen verbunden sind, und ermöglicht den Empfang von Protokollen, selbst wenn der Cluster vollständig funktionsunfähig wird.
Der beliebteste Protokollsammlungsstapel für Kubernetes-Fans ist Elasticsearch, Fluentd und Kibana (EFK-Stapel). In diesem Beispiel führen wir Elasticsearch und Kibana auf einem externen Knoten aus (Sie können den vorhandenen ELK-Stack verwenden) sowie Fluentd in unserem Cluster als Daemonset für jeden Knoten als Protokollsammlungsagent.
Ich werde den Teil über das Erstellen einer VM mit Elasticsearch- und Kibana-Installationen überspringen. Dies ist ein ziemlich beliebtes Thema, daher finden Sie viel Material darüber, wie es am besten geht. Zum Beispiel in meinem Artikel . Entfernen Sie einfach das logstash- Konfigurationsfragment aus der Datei docker-compose.yml und 127.0.0.1 aus dem Abschnitt elasticsearch- Ports.
Danach sollte eine funktionierende Elasticsearch mit dem VM-IP-Port 9200 verbunden sein. Konfigurieren Sie für zusätzliche Sicherheit login: pass oder Sicherheitsschlüssel zwischen fluentd und elasticsearch. Ich schütze sie jedoch oft einfach mit iptables-Regeln.
Sie müssen lediglich ein fließendes Daemonset in Kubernetes erstellen und in der Konfiguration den externen Knoten elasticsearch node: port angeben.
Wir verwenden das offizielle Kubernetes-Add-On mit der Yaml-Konfiguration von hier aus , mit geringfügigen Änderungen:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
Dann werden wir eine spezifische Konfiguration von fluentd vornehmen:
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
Die Konfiguration ist elementar, reicht aber für einen schnellen Start aus. Es werden System- und Anwendungsprotokolle gesammelt. Wenn Sie etwas Komplizierteres benötigen, können Sie die offizielle Dokumentation zu fließenden Plugins und Kubernetes-Konfigurationen lesen.
Erstellen wir nun ein fließendes Daemonset in unserem Cluster:
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
Stellen Sie sicher, dass alle fließenden Pods und anderen Ressourcen erfolgreich ausgeführt werden, und öffnen Sie dann Kibana. Suchen und fügen Sie in Kibana einen neuen Index von fluentd hinzu. Wenn Sie etwas finden, ist alles korrekt. Wenn nicht, überprüfen Sie die vorherigen Schritte und erstellen Sie das Daemonset neu oder bearbeiten Sie die Konfigurationskarte:

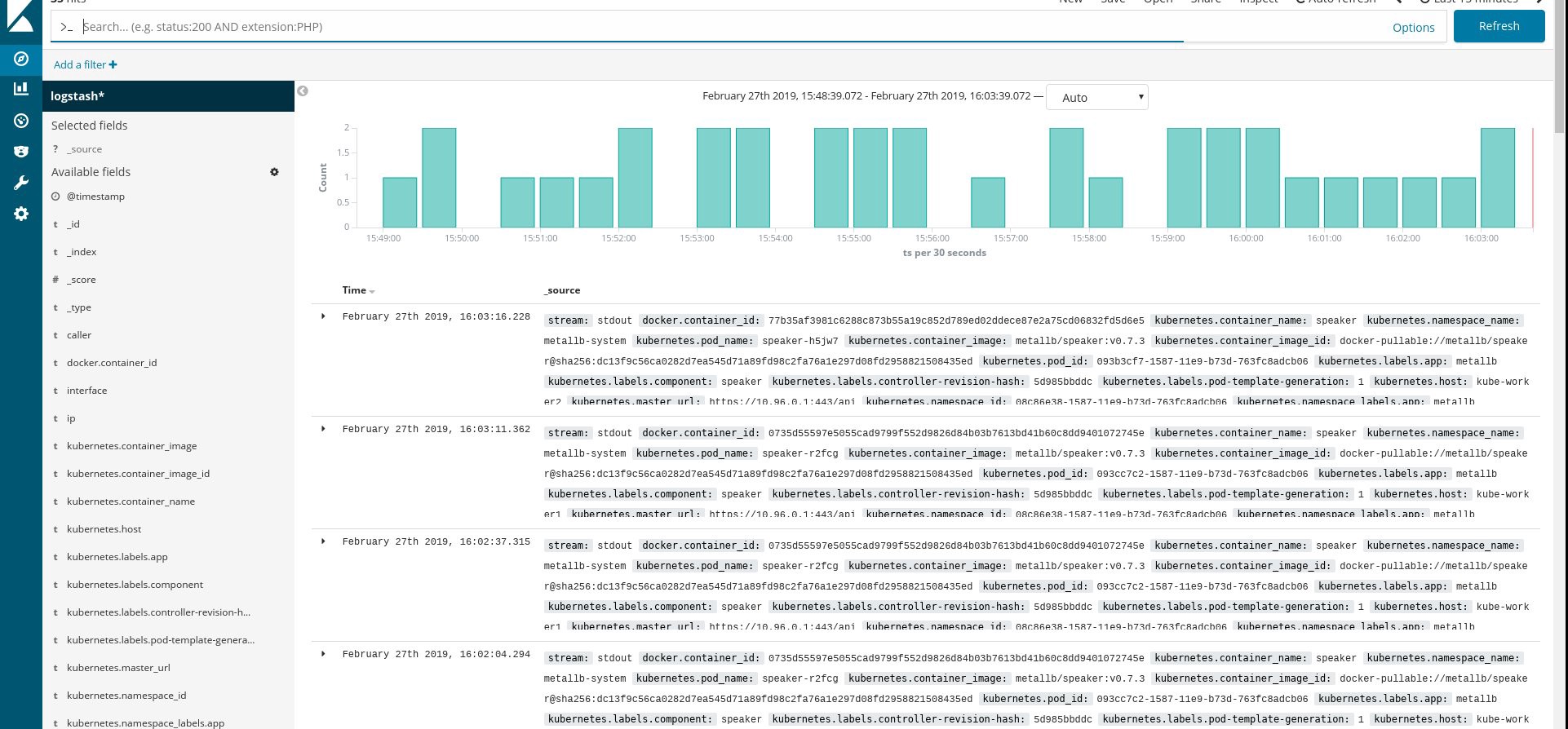
Nun, da wir die Protokolle vom Cluster erhalten, können Sie beliebige Dashboards erstellen. Natürlich ist die Konfiguration die einfachste, daher müssen Sie sie wahrscheinlich selbst ändern. Das Hauptziel war zu zeigen, wie dies gemacht wird.
Nachdem wir alle vorherigen Schritte ausgeführt haben, haben wir einen wirklich guten, gebrauchsfertigen Kubernetes-Cluster erhalten. Es ist Zeit, eine Testanwendung einzubetten und zu sehen, was passiert.
Nehmen Sie für dieses Beispiel meine kleine Python / Flask Kubyk-Anwendung, die bereits einen Docker-Container enthält. Nehmen Sie sie also aus der offenen Docker-Registrierung. Jetzt fügen wir dieser Anwendung eine externe Datenbankdatei hinzu - dafür verwenden wir den konfigurierten GlusterFS-Speicher.
Zunächst erstellen wir ein neues PVC- Volume für diese Anwendung (permanente Volume-Anforderung), in dem die SQLite- Datenbank mit Benutzeranmeldeinformationen gespeichert wird. Sie können die vorab erstellte Speicherklasse aus Teil 2 dieses Handbuchs verwenden.
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
Nachdem wir ein neues PVC für die Anwendung erstellt haben, sind wir bereit für die Bereitstellung.
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
Jetzt erstellen wir eine Bereitstellung und einen Service:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
Überprüfen Sie die neue IP-Adresse, die dem Dienst zugewiesen wurde, sowie den Status des Sub:
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
Es sieht also so aus, als hätten wir eine neue Anwendung erfolgreich gestartet. Wenn wir die IP-Adresse http://192.168.0.242 im Browser öffnen, sollte die Anmeldeseite dieser Anwendung angezeigt werden. Sie können die Anmeldeinformationen admin / admin verwenden, um sich anzumelden. Wenn wir jedoch versuchen, uns zu diesem Zeitpunkt anzumelden, wird eine Fehlermeldung angezeigt, da noch keine Datenbank verfügbar ist.
Hier ist ein Beispiel für eine Protokollfehlermeldung vom Herd im Kubernetes-Dashboard:
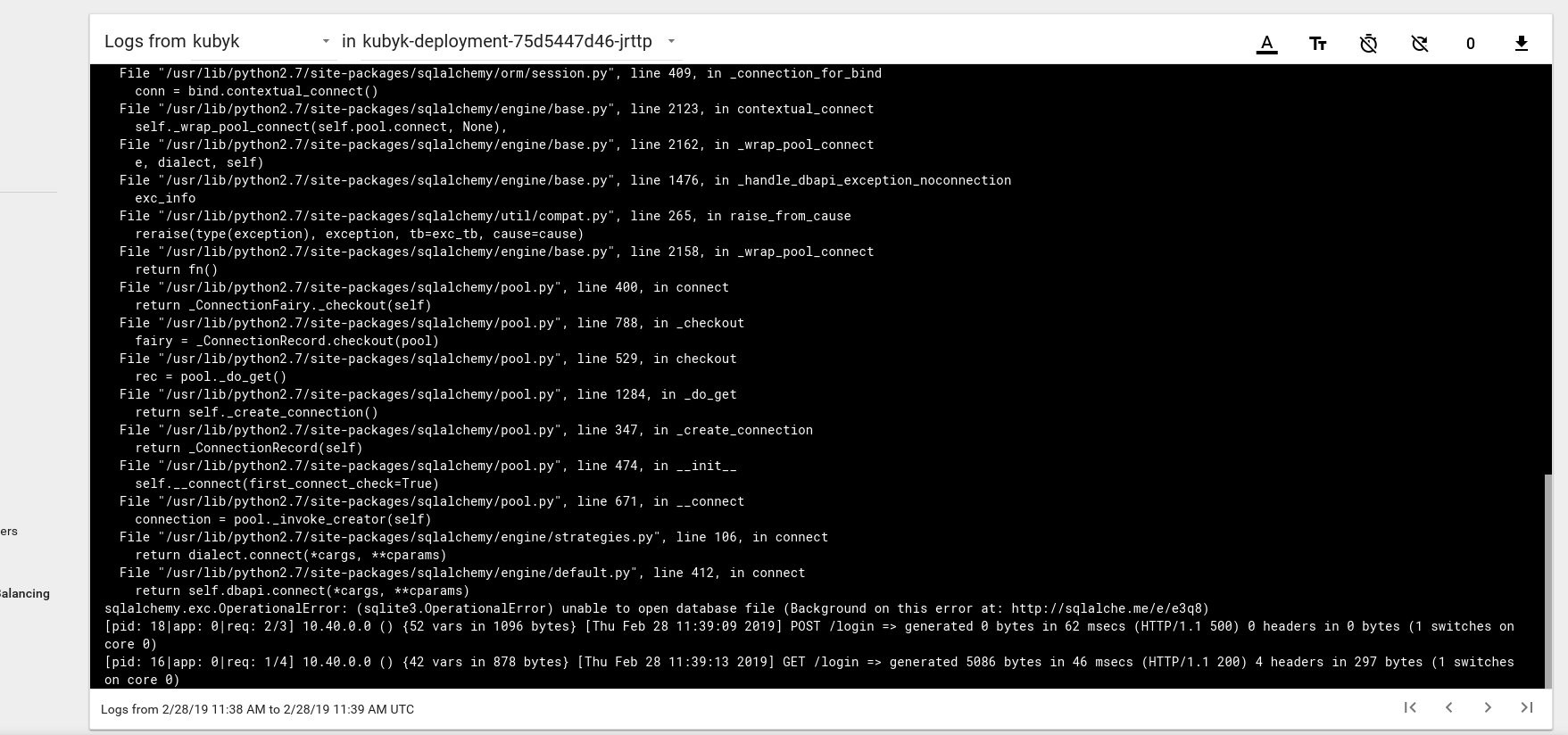
Um dies zu beheben, müssen Sie die SQlite DB-Datei aus meinem Git-Repository auf das zuvor erstellte PVC-Volume kopieren. Die Anwendung beginnt mit der Verwendung dieser Datenbank.
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
Wir verwenden das Unter aus der Anwendung und den Befehl kubectl cp, um diese Datei auf das Volume zu kopieren.
Sie müssen dem nginx-Benutzer auch Schreibzugriff auf dieses Verzeichnis gewähren. Meine Anwendung wird über den Nginx-Benutzer mit Supervisord gestartet.
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
Versuchen wir erneut, uns anzumelden:
Großartig, jetzt funktioniert unsere Anwendung ordnungsgemäß und wir können die Kubyk- Bereitstellung auf 3 Replikate skalieren, um beispielsweise eine Kopie der Anwendung in einem Arbeitsknoten abzulegen. Da wir zuvor das PVC-Volume erstellt haben, verwenden alle unsere Pods mit Anwendungsreplikaten dieselbe Datenbank, und der Dienst verteilt den Datenverkehr zirkulär zwischen den Replikaten.
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
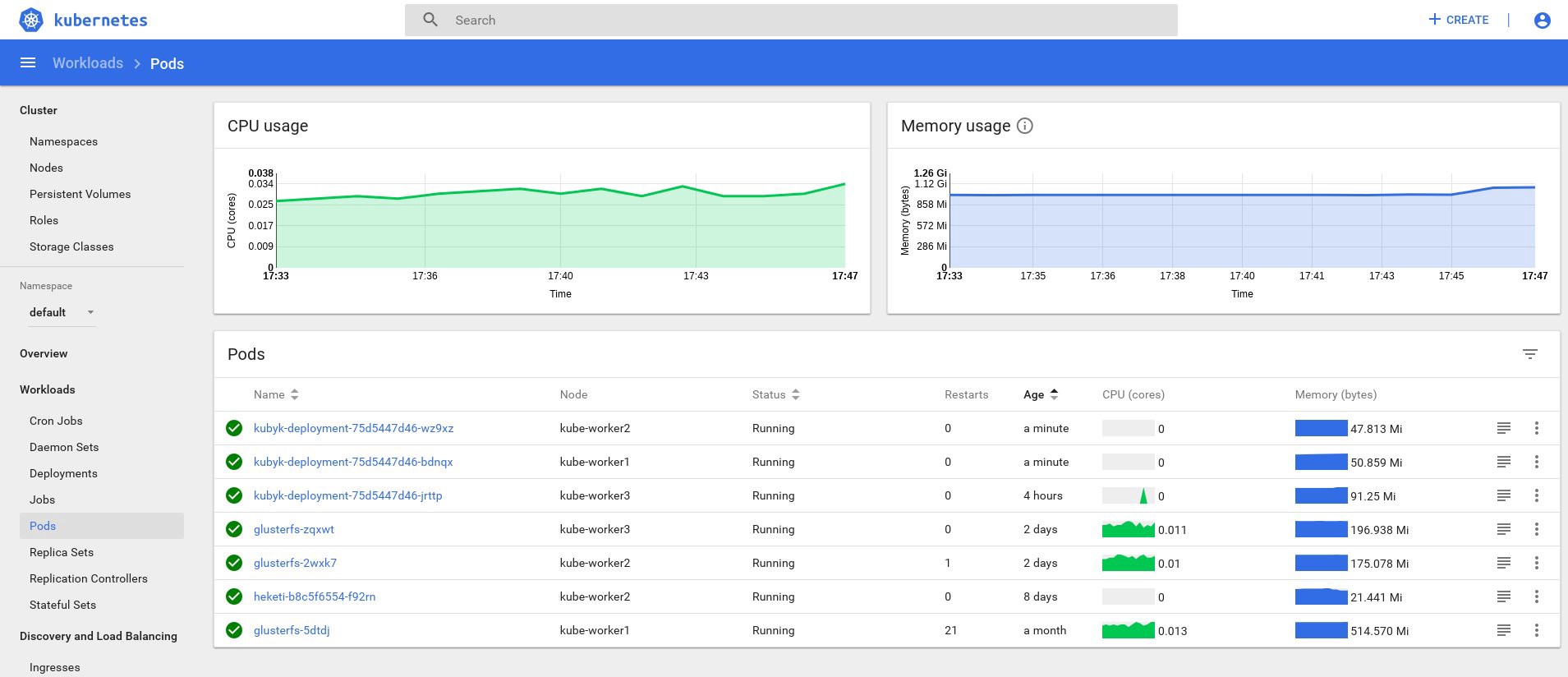
Jetzt haben wir Anwendungsreplikate für jeden Arbeitsknoten, sodass die Anwendung nicht aufhört zu arbeiten, wenn sie Knoten verliert. Außerdem erhalten wir eine einfache Möglichkeit, die Last auszugleichen, wie ich bereits sagte. Kein schlechter Anfang.
Erstellen wir einen neuen Benutzer in unserer Anwendung:
Alle neuen Anfragen werden vom nächsten Herd in der Liste bearbeitet. Dies kann anhand der Protokolle der Herde überprüft werden. Beispielsweise wird von der Anwendung in einem Sub ein neuer Benutzer erstellt, der nächste Sub beantwortet die nächste Anfrage und so weiter. Da diese Anwendung ein einziges beständiges Volume zum Speichern der Datenbank verwendet, sind alle Daten sicher, auch wenn alle Replikate verloren gehen.
In großen und komplexen Anwendungen benötigen Sie nicht nur ein bestimmtes Volume für die Datenbank, sondern verschiedene Volumes, um persistente Informationen und viele andere Elemente aufzunehmen.
Nun, wir sind fast fertig. Sie können noch viele weitere Aspekte hinzufügen, da Kubernetes ein umfangreiches und dynamisches Thema ist, aber wir werden hier aufhören. Das Hauptziel dieser Artikelserie war es, zu zeigen, wie Sie Ihren eigenen Kubernetes-Cluster erstellen. Ich hoffe, diese Informationen waren für Sie hilfreich.
PS
Natürlich Stabilitäts- und Stresstests.
Das Clusterdiagramm aus unserem Beispiel funktioniert ohne 2 Arbeitsknoten, 1 Hauptknoten und 1 etcd-Knoten. Wenn Sie möchten, deaktivieren Sie sie und prüfen Sie, ob die Testanwendung funktioniert.
Beim Zusammenstellen dieser Handbücher habe ich einen Produktionscluster für ein fast ähnliches Schema vorbereitet. Nachdem ich einen Cluster erstellt und eine Anwendung darin bereitgestellt hatte, kam es einmal zu einem schwerwiegenden Stromausfall. Absolut alle Server des Clusters wurden abgeschnitten - ein lebhafter Albtraum des Systemadministrators. Einige Server wurden für eine lange Zeit heruntergefahren, und dann traten bei ihnen Dateisystemfehler auf. Der Neustart hat mich jedoch sehr überrascht: Der Kubernetes-Cluster wurde vollständig wiederhergestellt. Alle GlusterFS-Volumes und -Bereitstellungen wurden gestartet. Für mich ist dies eine Demonstration des großen Potenzials dieser Technologie.
Alles Gute und hoffentlich bis bald!