Faltungs-Neuronale Netze klassifizieren verzerrte Bilder im Gegensatz zu Menschen hervorragend.

In diesem Artikel werde ich zeigen, warum fortgeschrittene tiefe neuronale Netze verzerrte Bilder perfekt erkennen können und wie dies dazu beiträgt, die überraschend einfache Strategie aufzuzeigen, die neuronale Netze zur Klassifizierung natürlicher Fotografien verwenden. Diese im ICLR 2019
veröffentlichten Entdeckungen haben viele Konsequenzen: Erstens zeigen sie, dass es viel einfacher ist, eine „
ImageNet “ -Lösung zu finden, als gedacht. Zweitens helfen sie uns, interpretierbarere und verständlichere Bildklassifizierungssysteme zu schaffen. Drittens erklären sie verschiedene Phänomene, die in modernen Faltungs-Neuronalen Netzen (SNA) beobachtet werden, beispielsweise ihre Tendenz, nach Texturen zu suchen (siehe unsere andere
Arbeit in ICLR 2019 und den entsprechenden
Blogeintrag ) und die räumliche Anordnung von Teilen des Objekts zu ignorieren.
Gute alte Modelle "Wortsack"
In den guten alten Zeiten, vor dem Aufkommen des tiefen Lernens, war das Erkennen natürlicher Bilder recht einfach: Wir definieren eine Reihe wichtiger visueller Merkmale („Wörter“), bestimmen, wie oft jedes visuelle Merkmal in einem Bild („Tasche“) vorkommt, und klassifizieren das Bild anhand dieser Zahlen. Daher werden solche Modelle in der Bildverarbeitung als "Wortsack" (Wortsack oder BoW) bezeichnet. Angenommen, wir haben zwei visuelle Merkmale, das menschliche Auge und den Stift, und wir möchten die Bilder in zwei Klassen einteilen: "Menschen" und "Vögel". Das einfachste BoW-Modell wäre das Folgende: Für jedes im Bild gefundene Auge erhöhen wir das Zeugnis zugunsten der „Person“ um 1. Und umgekehrt erhöhen wir für jeden Stift das Zeugnis zugunsten des „Vogels“ um 1. Welche Klasse mehr Beweise erhält, das wird es sein.
Eine bequeme Eigenschaft eines solch einfachen BoW-Modells ist die Interpretierbarkeit und Klarheit des Entscheidungsprozesses: Wir können genau prüfen, welche besonderen Merkmale des Bildes für eine bestimmte Klasse sprechen, die räumliche Integration von Merkmalen ist sehr einfach (im Vergleich zur nichtlinearen Integration von Merkmalen in tiefen neuronalen Netzen) Verstehe einfach, wie das Modell seine Entscheidungen trifft.
Traditionelle BoW-Modelle waren äußerst beliebt und funktionierten vor dem Einbruch des Deep Learning hervorragend, gerieten jedoch aufgrund der relativ geringen Effizienz schnell aus der Mode. Aber sind wir sicher, dass die neuronalen Netze eine grundlegend andere Entscheidungsstrategie als die BoW verwenden?
Tiefeninterpretiertes Netzwerk mit Taschenfunktionen (BagNet)
Um diese Annahme zu testen, kombinieren wir die Interpretierbarkeit und Klarheit von BoW-Modellen mit der Effizienz neuronaler Netze. Die Strategie sieht folgendermaßen aus:
- Teilen Sie das Bild in kleine Stücke qx q.
- Wir leiten die Teile durch das neuronale Netzwerk, um für jedes Teil einen Nachweis der Klassenzugehörigkeit (Logs) zu erhalten.
- Fassen Sie die Beweise in allen Teilen zusammen, um eine Lösung auf der Ebene des gesamten Bildes zu erhalten.
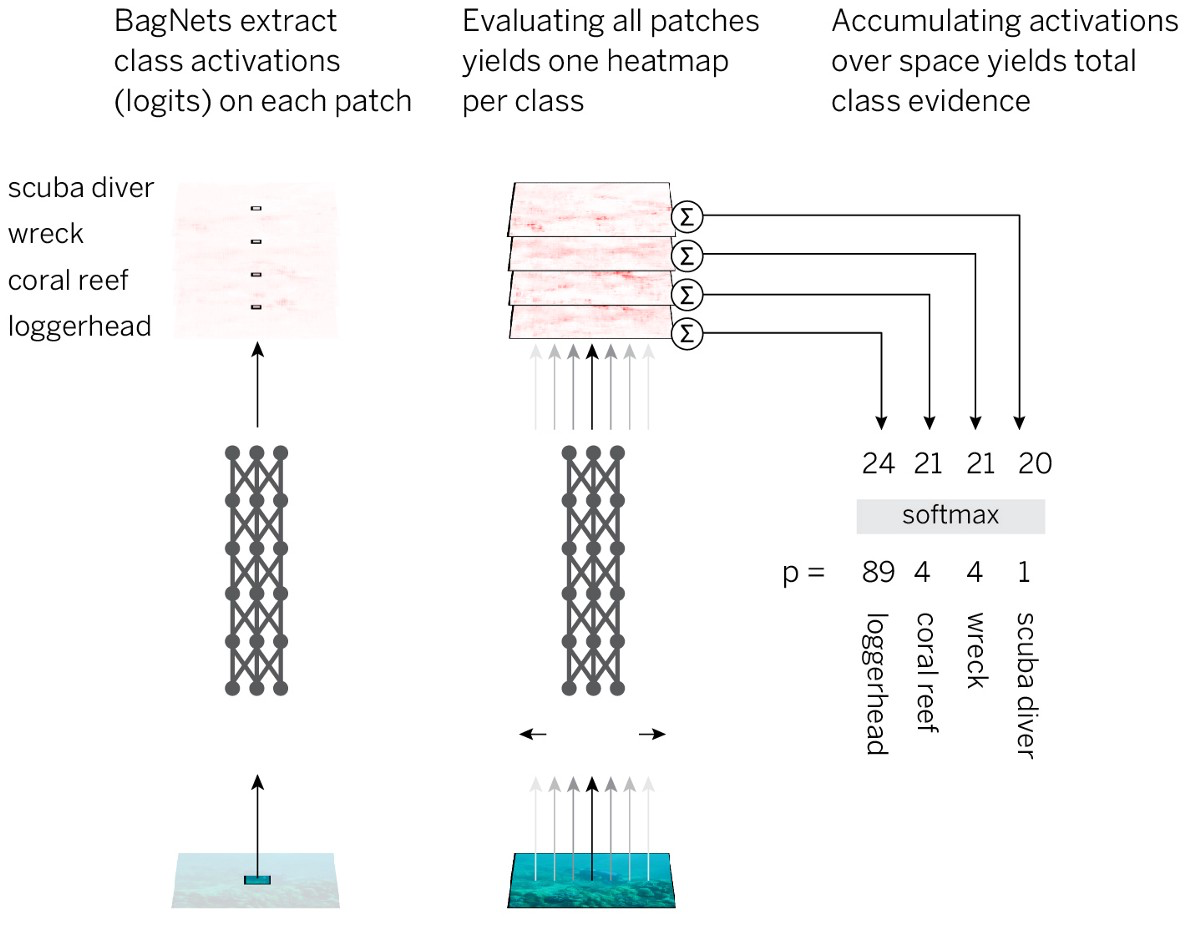
Um diese Strategie auf einfachste Weise umzusetzen, verwenden wir die Standard-ResNet-50-Architektur und ersetzen fast alle 3x3-Faltungen durch 1x1-Faltungen. Infolgedessen "sieht" jedes verborgene Element in der letzten Faltungsschicht nur einen kleinen Teil des Bildes (dh sein Wahrnehmungsfeld ist viel kleiner als die Bildgröße). So vermeiden wir das auferlegte Markup des Bildes und kommen dem Standard-SNA so nahe wie möglich, während wir eine vorgeplante Strategie anwenden. Wir nennen die resultierende Architektur BagNet-q, wobei q die Größe des Wahrnehmungsfeldes der obersten Schicht bezeichnet (wir haben das Modell mit q = 9, 17 und 33 getestet). BagNet-q läuft etwa 2,5 länger als das ResNet-50.
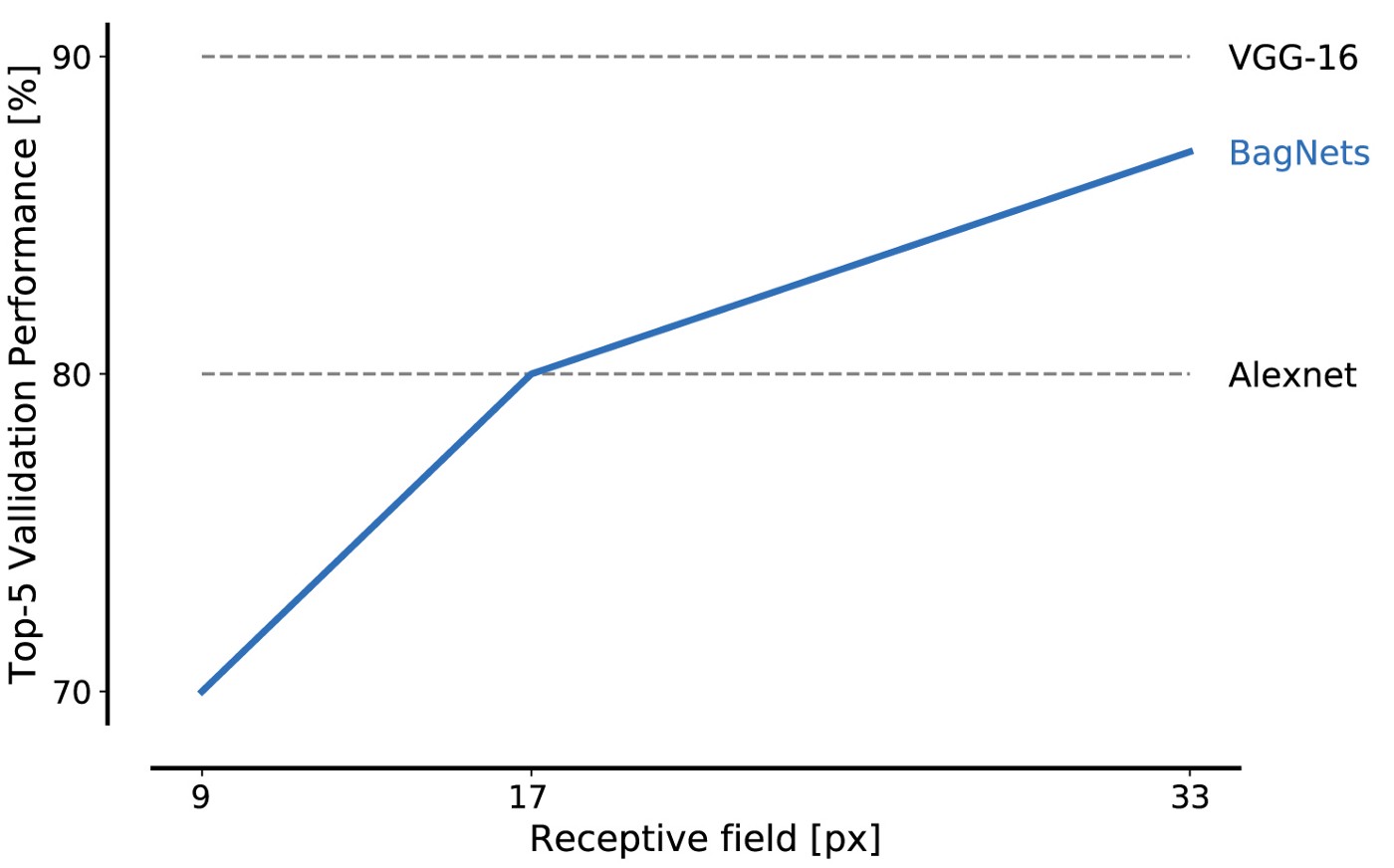
Die Leistung von BagNet bei Daten aus der ImageNet-Datenbank ist selbst bei Verwendung kleiner Teile beeindruckend: Fragmente mit 17 x 17 Pixel reichen aus, um die Effizienz des AlexNet-Levels zu erreichen, und Fragmente mit 33 x 33 Pixel reichen aus, um eine Genauigkeit von 87% zu erreichen und in die Top 5 zu gelangen. Sie können die Effizienz steigern, indem Sie die 3x3-Pakete sorgfältiger platzieren und die Hyperparameter anpassen.
Dies ist unser erstes großes Ergebnis: ImageNet kann nur mit einer Reihe kleiner Bildfunktionen gelöst werden. Die entfernten räumlichen Beziehungen der Teile der Komposition, wie die Form von Objekten oder die Interaktion zwischen Teilen des Objekts, können vollständig ignoriert werden. Sie werden absolut nicht benötigt, um das Problem zu lösen.
Ein bemerkenswertes Merkmal von BagNet'ov ist die Transparenz ihres Entscheidungssystems. Sie können beispielsweise herausfinden, welche Merkmale der Bilder für eine bestimmte Klasse am charakteristischsten sind. Zum Beispiel wird Schleie, ein großer Fisch, normalerweise durch das Bild von Fingern auf einem grünen Hintergrund erkannt. Warum? Denn auf den meisten Fotos in dieser Kategorie gibt es einen Fischer, der eine Schleie als Trophäe hält. Und wenn BagNet das Bild fälschlicherweise als Linie erkennt, geschieht dies normalerweise, weil sich irgendwo auf dem Foto Finger auf einem grünen Hintergrund befinden.
 Die charakteristischsten Teile von Bildern. Die obere Reihe in jeder Zelle entspricht der korrekten Erkennung und die untere Zeile den ablenkenden Fragmenten, die zu einer falschen Erkennung geführt haben
Die charakteristischsten Teile von Bildern. Die obere Reihe in jeder Zelle entspricht der korrekten Erkennung und die untere Zeile den ablenkenden Fragmenten, die zu einer falschen Erkennung geführt habenWir erhalten auch die genaue „Wärmekarte“, die zeigt, welche Teile des Bildes zur Entscheidung beigetragen haben.
 Heatmaps sind keine Annäherung, sie zeigen genau den Beitrag jedes Teils des Bildes.
Heatmaps sind keine Annäherung, sie zeigen genau den Beitrag jedes Teils des Bildes.BagNets zeigen, dass Sie mit ImageNet nur aufgrund schwacher statistischer Korrelationen zwischen lokalen Merkmalen von Bildern und der Kategorie von Objekten eine hohe Genauigkeit erzielen können. Wenn dies ausreicht, warum sollten Standard-Neuronale Netze von ResNet-50 dann etwas grundlegend anderes lernen? Warum sollte ResNet-50 komplexe Beziehungen in großem Maßstab wie die Form eines Objekts untersuchen, wenn die Fülle lokaler Merkmale des Bildes ausreicht, um das Problem zu lösen?
Um die Hypothese zu testen, dass moderne SNAs einer Strategie folgen, die dem Betrieb der einfachsten BoW-Netzwerke ähnelt, haben wir verschiedene Netzwerke - ResNet, DenseNet und VGG - auf die folgenden „Zeichen“ von BagNet getestet:
- Die Lösungen sind unabhängig vom räumlichen Mischen der Bildmerkmale (dies kann nur bei VGG-Modellen überprüft werden).
- Änderungen verschiedener Teile des Bildes sollten nicht voneinander abhängen (im Sinne ihres Einflusses auf die Klassenzugehörigkeit).
- Fehler, die von Standard-SNA und BagNet'ami gemacht wurden, sollten ähnlich sein.
- Standard-SNS und BagNet sollten für ähnliche Funktionen empfindlich sein.
In allen vier Experimenten fanden wir überraschend ähnliche Verhaltensweisen von SNS und BagNet. Im letzten Experiment haben wir beispielsweise gezeigt, dass BagNet für dieselben Stellen in den Bildern wie die SNA am empfindlichsten ist (wenn sie sich beispielsweise überlappen). Tatsächlich sagen BagNet-Wärmekarten (räumliche Empfindlichkeitskarten) die Empfindlichkeit von DenseNet-169 besser voraus als Wärmekarten, die mit Attributionsmethoden wie DeepLift (direkte Berechnung von Wärmekarten für DenseNet-169) erhalten wurden. Natürlich wiederholt der SNA das Verhalten von BagNet nicht genau, aber bestimmte Abweichungen zeigen dies. Insbesondere werden die Abhängigkeiten umso größer, je tiefer die Netzwerke werden, und desto größer werden die Abhängigkeiten. Daher sind tiefe neuronale Netze in der Tat eine Verbesserung gegenüber BagNet-Modellen, aber ich glaube nicht, dass sich die Grundlage ihrer Klassifizierung irgendwie ändert.
Über die BoW-Klassifizierung hinausgehen
Die Beobachtung der SNA-Entscheidungsfindung im Stil von BoW-Strategien kann einige der seltsamen Merkmale der SNA erklären. Dies erklärt zunächst, warum der SNA so
an Texturen gebunden ist . Zweitens, warum der SNA nicht empfindlich auf das
Mischen von Bildteilen reagiert. Dies kann sogar das Vorhandensein von gegnerischen Aufklebern und gegnerischen Störungen erklären: Verwirrende Signale können an einer beliebigen Stelle im Bild platziert werden, und der SNS fängt dieses Signal mit Sicherheit ab, unabhängig davon, ob es zum Rest des Bildes passt.
Tatsächlich zeigt unsere Arbeit, dass der SNA beim Erkennen von Bildern viele schwache statistische Gesetze verwendet und nicht wie Menschen Teile des Bildes auf Objektebene integriert. Gleiches gilt höchstwahrscheinlich für andere Aufgaben und sensorische Modalitäten.
Wir müssen unsere Architekturen, Aufgaben und Trainingsmethoden sorgfältig planen, um die Tendenz zu überwinden, schwache statistische Korrelationen zu verwenden. Ein Ansatz besteht darin, die Verzerrung des SNA-Trainings von kleinen lokalen Merkmalen auf globalere zu übertragen. Die andere besteht darin, die Merkmale zu entfernen oder zu ersetzen, auf die sich das neuronale Netzwerk nicht verlassen sollte, wie wir es in einer anderen
Veröffentlichung für ICLR 2019 getan haben, indem die Stilübertragungsvorverarbeitung verwendet wird, um die Textur eines natürlichen Objekts zu beseitigen.
Eines der größten Probleme bleibt jedoch die Klassifizierung von Bildern: Wenn lokale Merkmale ausreichen, gibt es keinen Anreiz, die reale "Physik" der natürlichen Welt zu studieren. Wir müssen die Aufgabe so umstrukturieren, dass Modelle verschoben werden, um die physikalische Natur von Objekten zu untersuchen. Um dies zu tun, müssen Sie höchstwahrscheinlich über die reine Beobachtungslehre hinaus zu den Korrelationen von Eingabe- und Ausgabedaten gehen, damit Modelle kausale Zusammenhänge extrahieren können.
Zusammengenommen legen unsere Ergebnisse nahe, dass die SNA einer äußerst einfachen Klassifizierungsstrategie folgen kann. Die Tatsache, dass eine solche Entdeckung im Jahr 2019 gemacht werden kann, unterstreicht, wie wenig wir die internen Merkmale der Arbeit tiefer neuronaler Netze noch verstehen. Der Mangel an Verständnis erlaubt es uns nicht, grundlegend verbesserte Modelle und Architekturen zu entwickeln, die die Lücke zwischen der Wahrnehmung von Mensch und Maschine schließen. Durch die Vertiefung unseres Verständnisses können wir Wege finden, um diese Lücke zu schließen. Dies kann äußerst nützlich sein: Beim Versuch, die SNA in Richtung der physikalischen Eigenschaften von Objekten zu verschieben, erreichten wir plötzlich eine
Widerstandsfähigkeit gegen Lärm auf menschlicher Ebene. Ich erwarte das Erscheinen einer Vielzahl anderer interessanter Ergebnisse auf unserem Weg zur Entwicklung der SNA, die die physische und kausale Natur unserer Welt wirklich verstehen.