Ich bin ein großer Fan von allem, was
Fabien Sanglard tut, ich mag seinen Blog und ich lese
beide Bücher von vorne bis hinten (beschrieben in einem kürzlich erschienenen
Hansleminutes-Podcast ).
Fabien hat kürzlich einen großartigen Beitrag geschrieben, in dem er
einen winzigen Raytracer
entschlüsselt , den Code deobfusciert und die Mathematik fantastisch schön erklärt hat. Ich empfehle wirklich, sich die Zeit zu nehmen, um dies zu lesen!
Aber ich habe mich gefragt,
ob es möglich ist, diesen C ++ - Code nach C # zu portieren . Da ich in letzter Zeit in meinem
Hauptjob ziemlich viel C ++ geschrieben habe, dachte ich, ich könnte es versuchen.
Aber was noch wichtiger ist, ich wollte eine bessere Vorstellung davon bekommen,
ob C # eine einfache Sprache ist .
Eine etwas andere, aber verwandte Frage: Inwieweit ist C # für die "Systemprogrammierung" geeignet? Zu diesem Thema empfehle ich
Joe Duffys hervorragenden Beitrag aus dem Jahr 2013 .
Leitungsport
Ich begann damit,
deobfuscierten C ++ - Code einfach Zeile für Zeile nach C # zu
portieren . Es war ziemlich einfach: Es scheint, dass die Wahrheit immer noch gesagt wird, dass C # C ++++ ist !!!
Das Beispiel zeigt die Hauptdatenstruktur - 'Vektor', hier ein Vergleich, C ++ links, C # rechts:

Es gibt also einige syntaktische Unterschiede, aber da Sie mit .NET
Ihre eigenen Werttypen definieren
können , konnte ich dieselbe Funktionalität erhalten. Dies ist wichtig, da die Behandlung von "Vektor" als Struktur bedeutet, dass wir eine bessere "Datenlokalität" erzielen können und den .NET-Garbage Collector nicht einbeziehen müssen, da die Daten auf den Stapel übertragen werden (ja, ich weiß, dass dies ein Implementierungsdetail ist).
Weitere Informationen zu
structs oder „
structs “ in .NET finden Sie hier:
Insbesondere in Eric Lipperts letztem Beitrag finden wir ein so nützliches Zitat, dass deutlich wird, was „Werttypen“ wirklich sind:
Das Wichtigste an den Wertetypen sind natürlich nicht die Implementierungsdetails, wie sie zugeordnet werden , sondern die ursprüngliche semantische Bedeutung des „Wertetyps“, nämlich, dass er immer „nach Wert“ kopiert wird . Wenn Zuordnungsinformationen wichtig wären, würden wir sie "Heap-Typen" und "Stack-Typen" nennen. Aber in den meisten Fällen spielt es keine Rolle. Meistens ist die Semantik des Kopierens und Identifizierens relevant.
Nun wollen wir sehen, wie einige andere Methoden im Vergleich aussehen (wieder C ++ links, C # rechts), zuerst
RayTracing(..) :
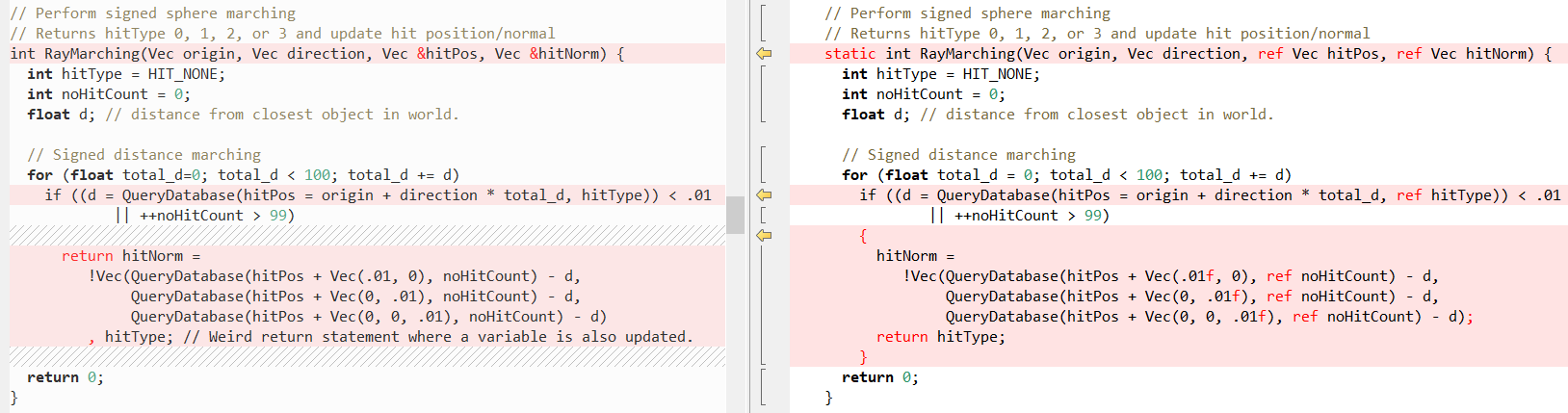
Dann
QueryDatabase (..) :
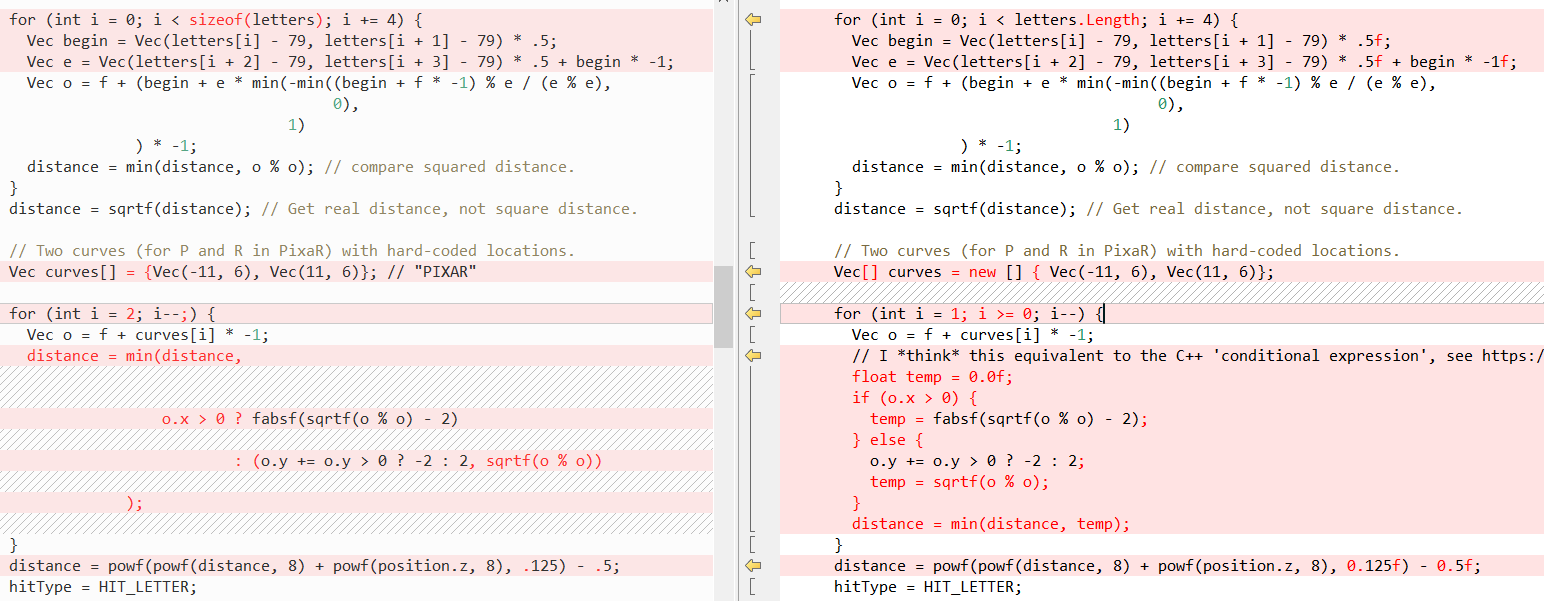
(In
Fabians Beitrag finden Sie eine Erklärung, was diese beiden Funktionen bewirken.)
Tatsache ist jedoch, dass C # das Schreiben von C ++ - Code sehr einfach macht! In diesem Fall hilft uns das Schlüsselwort
ref am meisten, wodurch wir einen
Wert als Referenz übergeben können . Wir haben
ref seit einiger Zeit in Methodenaufrufen verwendet, aber in letzter Zeit wurden Anstrengungen unternommen, um
ref anderer Stelle aufzulösen:
Manchmal verbessert die Verwendung von
ref manchmal die Leistung, da die Struktur dann nicht kopiert werden muss. Weitere Informationen finden Sie in den Benchmarks im
Beitrag von Adam Stinix und unter
„Leistung fängt Ref-Einheimische und Ref-Rückgaben in C # ein“ .
Das Wichtigste ist jedoch, dass ein solches Skript unserem C # -Port das gleiche Verhalten wie der C ++ - Quellcode verleiht. Obwohl ich darauf hinweisen möchte, dass die sogenannten "verwalteten Links" nicht ganz mit "Zeigern" identisch sind, können Sie mit ihnen keine Arithmetik durchführen. Weitere Informationen hierzu finden Sie hier:
Leistung
Somit war der Code gut portiert, aber auch die Leistung ist wichtig. Besonders im Ray Tracer, der den Frame für mehrere Minuten berechnen kann. C ++ - Code enthält die Variable
sampleCount , die die endgültige Bildqualität steuert, mit
sampleCount = 2 wie folgt:

Offensichtlich nicht sehr realistisch!
Aber wenn Sie auf
sampleCount = 2048 , sieht alles
viel besser aus:

Das Starten mit
sampleCount = 2048 ist jedoch
sehr zeitaufwändig, sodass alle anderen Läufe mit einem Wert von
2 werden, um mindestens eine Minute zu erreichen. Das Ändern von
sampleCount wirkt sich nur auf die Anzahl der Iterationen der äußersten
Codeschleife aus. Eine Erläuterung finden Sie in
dieser Übersicht .
Ergebnisse nach einem "naiven" Leitungsport
Um C ++ und C # inhaltlich zu vergleichen, habe ich das
Zeitfenster- Tool verwendet. Dies ist der Port des Befehls
time unix. Die ersten Ergebnisse sahen folgendermaßen aus:
| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) |
|---|
| Zeit (Sek.) | 47,40 | 80.14 | 78.02 |
| Im Kern (Sek.) | 0,14 (0,3%) | 0,72 (0,9%) | 0,63 (0,8%) |
| Im User-Space (Sek.) | 43,86 (92,5%) | 73,06 (91,2%) | 70,66 (90,6%) |
| Anzahl der Seitenfehlerfehler | 1143 | 4818 | 5945 |
| Arbeitssatz (KB) | 4232 | 13 624 | 17 052 |
| Extrudierter Speicher (KB) | 95 | 172 | 154 |
| Nicht präventives Gedächtnis | 7 | 14 | 16 |
| Datei tauschen (KB) | 1460 | 10 936 | 11 024 |
Zunächst sehen wir, dass C # -Code etwas langsamer als die C ++ - Version ist, aber besser wird (siehe unten).
Aber lassen Sie uns zuerst sehen, was die .NET-JIT auch mit diesem „naiven“ zeilenweisen Port mit uns macht. Erstens gelingt es gut, kleinere Hilfsmethoden einzubetten. Dies zeigt sich in der Ausgabe des hervorragenden
Inlining Analyzer- Tools (grün = integriert):
Es werden jedoch nicht alle Methoden eingebettet. Beispielsweise wird
QueryDatabase(..) aufgrund der Komplexität übersprungen:
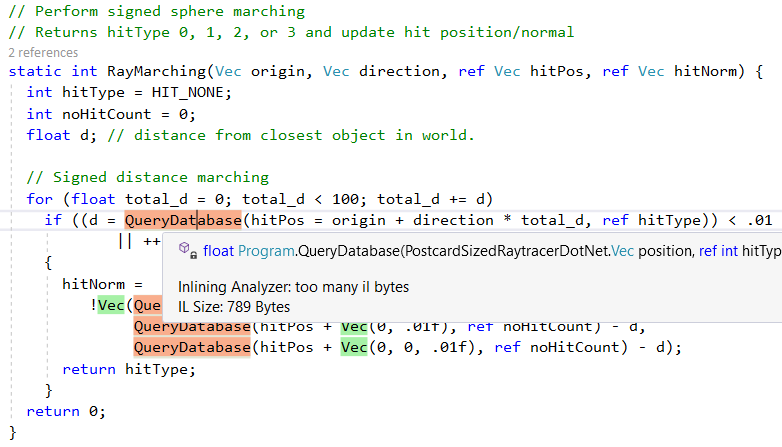
Eine weitere JIT-Compilerfunktion (.NET Just-In-Time) ist die Konvertierung bestimmter Methodenaufrufe in die entsprechenden CPU-Anweisungen. Wir können dies in Aktion mit der
sqrt Shell-Funktion sehen. Hier ist der C #
Math.Sqrt (beachten Sie den Aufruf von
Math.Sqrt ):
Und hier ist der Assembler-Code, den die .NET-JIT generiert: Es gibt keinen Aufruf von
Math.Sqrt und die Prozessoranweisung
vsqrtsd wird verwendet :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(Um dieses Problem zu
beheben , befolgen Sie
diese Anweisungen , verwenden Sie das
VS2019-Add-On "Disasmo" oder schauen Sie sich
SharpLab.io an. )
Diese Ersetzungen werden auch als
Intrinsics bezeichnet . Im folgenden Code können wir sehen, wie die JIT sie generiert. Dieses Snippet zeigt die Zuordnung nur für
AMD64 , aber die JIT zielt auch auf
X86 ,
ARM und
ARM64 , die vollständige Methode
hier .
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
Wie Sie sehen können, sind einige Methoden wie
Sqrt und
Abs implementiert, während andere C ++ - Laufzeitfunktionen verwenden, z. B.
powf .
Dieser gesamte Prozess wird im Artikel
„Wie wird Math.Pow () in .NET Framework implementiert?“ Sehr gut erläutert. kann es auch in der CoreCLR-Quelle gesehen werden:
Ergebnisse nach einfachen Leistungsverbesserungen
Ich frage mich, ob Sie den naiven Line-by-Port-Port sofort verbessern können. Nach einigen Profilen habe ich zwei wichtige Änderungen vorgenommen:
- Inline-Array-Initialisierung entfernen
- Ersetzen der Funktionen von
Math.XXX(..) durch Analoga von MathF.()
Diese Änderungen werden nachstehend ausführlicher erläutert.
Inline-Array-Initialisierung entfernen
Weitere Informationen dazu, warum dies erforderlich ist, finden Sie in
dieser hervorragenden Antwort zum
Stapelüberlauf von
Andrei Akinshin sowie in Benchmarks und Assembler-Code. Er kommt zu folgendem Schluss:
Fazit
- Zwischenspeichert .NET fest codierte lokale Arrays? Wie diejenigen, die den Roslyn-Compiler in Metadaten einfügen.
- In diesem Fall wird es Overhead geben? Leider ja: Bei jedem Aufruf kopiert JIT den Inhalt des Arrays aus den Metadaten, was im Vergleich zu einem statischen Array zusätzliche Zeit in Anspruch nimmt. Die Laufzeit wählt auch Objekte aus und erzeugt Datenverkehr im Speicher.
- Muss man sich darüber Sorgen machen? Möglicherweise. Wenn dies eine heiße Methode ist und Sie ein gutes Leistungsniveau erreichen möchten, müssen Sie ein statisches Array verwenden. Wenn dies eine kalte Methode ist, die die Anwendungsleistung nicht beeinträchtigt, müssen Sie wahrscheinlich „guten“ Quellcode schreiben und das Array im Methodenbereich platzieren.
Sie können die in
diesem Diff vorgenommenen Änderungen sehen.
Verwenden von MathF-Funktionen anstelle von Math
Zweitens und vor allem habe ich die Leistung erheblich verbessert, indem ich die folgenden Änderungen vorgenommen habe:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
Ab .NET Standard 2.1 gibt es konkrete Implementierungen gängiger mathematischer
float Funktionen. Sie befinden sich in der
System.MathF- Klasse. Weitere Informationen zu dieser API und ihrer Implementierung finden Sie hier:
Nach diesen Änderungen wurde der Unterschied in der C # - und C ++ - Codeleistung auf etwa 10% reduziert:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC AUS | .NET Core (2.2) TC ON |
|---|
| Zeit (Sek.) | 41,38 | 58,89 | 46.04 | 44.33 |
| Im Kern (Sek.) | 0,05 (0,1%) | 0,06 (0,1%) | 0,14 (0,3%) | 0,13 (0,3%) |
| Im User-Space (Sek.) | 41,19 (99,5%) | 58,34 (99,1%) | 44,72 (97,1%) | 44,03 (99,3%) |
| Anzahl der Seitenfehlerfehler | 1119 | 4749 | 5776 | 5661 |
| Arbeitssatz (KB) | 4136 | 13.440 | 16.788 | 16.652 |
| Extrudierter Speicher (KB) | 89 | 172 | 150 | 150 |
| Nicht präventives Gedächtnis | 7 | 13 | 16 | 16 |
| Datei tauschen (KB) | 1428 | 10 904 | 10 960 | 11 044 |
TC - Multilevel-Kompilierung,
Tiered Compilation (
ich nehme an ,
dass sie in .NET Core 3.0 standardmäßig aktiviert ist)
Der Vollständigkeit halber sind hier die Ergebnisse mehrerer Läufe:
| Ausführen | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC AUS | .NET Core (2.2) TC ON |
|---|
| TestRun-01 | 41,38 | 58,89 | 46.04 | 44.33 |
| TestRun-02 | 41.19 | 57,65 | 46.23 | 45,96 |
| TestRun-03 | 42.17 | 62,64 | 46,22 | 48,73 |
Hinweis : Der Unterschied zwischen .NET Core und .NET Framework ist auf das Fehlen der MathF-API in .NET Framework 4.7.2 zurückzuführen. Weitere Informationen finden Sie
im Support-Ticket .Net Framework (4.8?). Netstandard 2.1 .
Weitere Steigerung der Produktivität
Ich bin sicher, dass der Code noch verbessert werden kann!
Wenn Sie den Leistungsunterschied beheben möchten, finden Sie
hier den C # -Code . Zum Vergleich können Sie C ++ - Assembler-Code über den hervorragenden
Compiler Explorer- Dienst
anzeigen .
Wenn dies hilfreich ist, finden Sie hier die Visual Studio-Profilerausgabe mit einer Anzeige "Hot Path" (nach den oben beschriebenen Leistungsverbesserungen):
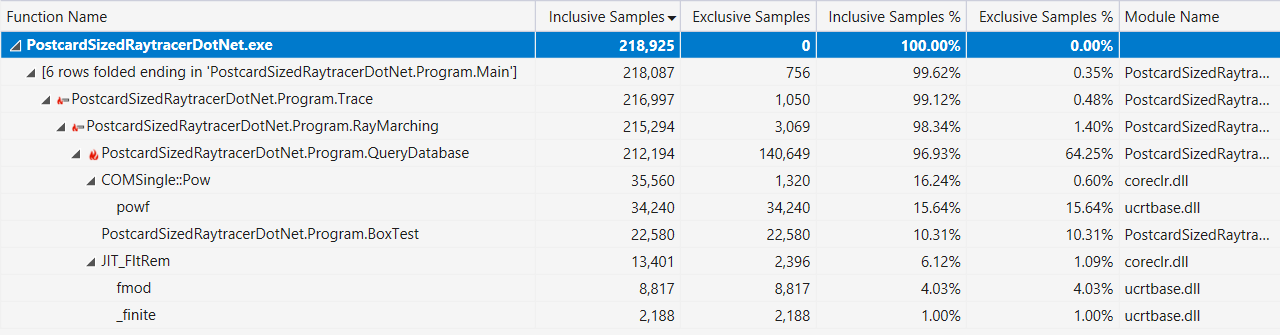
Ist C # eine einfache Sprache?
Oder genauer:
Welche Sprachfunktionen der C # / F # / VB.NET- oder BCL / Runtime-Funktionalität bedeuten "Low Level" * -Programmierung?
* Ja, ich verstehe, dass "niedriges Niveau" ein subjektiver Begriff ist.
Hinweis: Jeder C # -Entwickler hat seine eigene Vorstellung von der „niedrigen Ebene“. Diese Funktionen werden von C ++ - oder Rust-Programmierern als selbstverständlich angesehen.
Hier ist die Liste, die ich gemacht habe:
- ref kehrt zurück und ref Einheimische
- „Übergeben und Zurückgeben als Referenz, um das Kopieren großer Strukturen zu vermeiden. Sichere Typen und Speicher können sogar schneller als unsicher sein! “
- Unsicherer Code in .NET
- „Die in den vorherigen Kapiteln definierte C # -Sprachsprache unterscheidet sich stark von C und C ++, da ihr Zeiger als Datentyp fehlen. Stattdessen bietet C # Links und die Möglichkeit, Objekte zu erstellen, die vom Garbage Collector verwaltet werden. Dieses Design in Kombination mit anderen Funktionen macht C # zu einer viel sichereren Sprache als C oder C ++. “
- Verwaltete Zeiger in .NET
- „In der CLR gibt es einen anderen Zeigertyp - einen verwalteten Zeiger. Es kann als allgemeinere Art von Verknüpfung definiert werden, die auf andere Orte und nicht nur auf den Anfang des Objekts verweisen kann. “
- C # 7-Serie, Teil 10: Span <T> und Universal Memory Management
- „System.Span <T> ist nur ein Stapeltyp (
ref struct ), der alle Speicherzugriffsmuster umschließt. Es ist ein Typ für den universellen kontinuierlichen Speicherzugriff. Wir können uns eine Span-Implementierung mit einer Dummy-Referenz und einer Länge vorstellen, die alle drei Arten des Speicherzugriffs akzeptiert. "
- Kompatibilität („C # -Programmierhandbuch“)
- "Das .NET Framework bietet Interoperabilität mit nicht verwaltetem Code über Plattformaufrufdienste, den
System.Runtime.InteropServices , die C ++ - Kompatibilität und die COM-Kompatibilität (COM-Interoperabilität)."
Ich habe auch auf Twitter geweint und viel mehr Optionen für die Aufnahme in die Liste erhalten:
- Ben Adams : „Integrierte Tools für Plattformen (CPU-Anweisungen)“
- Mark Gravell : „SIMD via Vector (was gut zu Span passt ) ist * ziemlich * niedrig; .NET Core sollte (bald?) Direkte CPU-Embedded-Tools für die explizitere Verwendung spezifischer CPU-Anweisungen anbieten. “
- Mark Gravell : „Leistungsstarke JIT: Dinge wie die Entfernungsentfernung für Arrays / Intervalle sowie die Verwendung von Per-Struct-T-Regeln zum Entfernen großer Codeteile, von denen JIT sicher weiß, dass sie für dieses T oder für Ihr spezifisches T nicht verfügbar sind CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated usw.) "
- Kevin Jones : „Ich würde besonders die Klassen
MemoryMarshal und Unsafe sowie einige andere Dinge in den System.Runtime.CompilerServices “
- Theodoros Chatsigiannakis : „Sie können auch
__makeref und den Rest __makeref “
- Damageboy : "Die Fähigkeit, dynamisch Code zu generieren, der genau der erwarteten Eingabe entspricht, da letztere nur zur Laufzeit bekannt ist und sich regelmäßig ändern kann?"
- Robert Hacken : "Dynamische Emission von IL"
- Victor Baybekov : „Stackalloc wurde nicht erwähnt. Es ist auch möglich, reines IL zu schreiben (nicht dynamisch, daher wird es bei einem Funktionsaufruf gespeichert), z. B. zwischengespeicherte
ldftn und sie über calli aufzurufen. In VS2017 gibt es eine Projektvorlage, die dies trivial macht, indem die Methoden extern + MethodImplOptions.ForwardRef + ilasm.ex »neu geschrieben werden.»
- Victor Baybekov : „MethodImplOptions.AggressiveInlining aktiviert auch die Low-Level-Programmierung in dem Sinne, dass Sie High-Level-Code mit vielen kleinen Methoden schreiben und dennoch das Verhalten von JIT steuern können, um ein optimiertes Ergebnis zu erzielen. Andernfalls Kopieren und Einfügen von Hunderten von LOC-Methoden ... "
- Ben Adams : "Verwenden Sie die gleichen Aufrufkonventionen (ABI) wie auf der Basisplattform und p / ruft zur Interaktion auf?"
- Victor Baibekov : „Da Sie #fsharp erwähnt haben, hat es ein
inline , das auf IL-Ebene für JIT funktioniert. Daher wurde es auf Sprachebene als wichtig angesehen. C # Dies ist (bisher) nicht genug für Lambdas, bei denen es sich immer um virtuelle Anrufe handelt, und Problemumgehungen sind oft seltsam (begrenzte Generika). "
- Alexandre Mutel : „Neue eingebettete SIMD, Nachbearbeitung der unsicheren Dienstprogrammklasse / IL (z. B. benutzerdefiniert, Fody usw.). Für C # 8.0 kommende Funktionszeiger ... "
- Alexandre Mutel : „In Bezug auf IL unterstützt F # IL direkt in einer Sprache, zum Beispiel.“
- OmariO : „ BinaryPrimitives . Niedriges Niveau, aber sicher "
- Koji Matsui : „Wie wäre es mit Ihrem eigenen eingebauten Assembler? Es ist sowohl für das Toolkit als auch für die Laufzeit schwierig, kann jedoch die aktuelle p / invoke-Lösung ersetzen und gegebenenfalls den eingebetteten Code implementieren. “
- Frank A. Kruger : "Ldobj, stobj, initobj, initblk, cpyblk"
- Conrad Coconut : „Vielleicht lokalen Speicher streamen? Puffer mit fester Größe? Sie sollten wahrscheinlich nicht verwaltete Einschränkungen und blittable Typen erwähnen :) ”
- Sebastiano Mandala : „Nur eine kleine Ergänzung zu allem, was gesagt wurde: Wie wäre es mit etwas Einfachem wie dem Anordnen von Strukturen und wie das Füllen und Ausrichten von Speicher- und Ordnungsfeldern die Cache-Leistung beeinflussen kann? Das muss ich selbst erforschen. “
- Nino Floris : "Konstanten, die über Readonlyspan, Stackalloc, Finalizer, WeakReference, offene Delegaten, MethodImplOptions, MemoryBarriers, TypedReference, Varargs, SIMD und Unsafe.AsRef eingebettet sind, können die Strukturtypen genau nach dem Layout festlegen (das für TaskAwaiter und seine Version verwendet wird)."
Am Ende würde ich also sagen, dass C # es Ihnen sicherlich ermöglicht, Code zu schreiben, der wie C ++ aussieht, und in Kombination mit den Laufzeit- und Basisklassenbibliotheken viele Funktionen auf niedriger Ebene bietet.Weiterführende Literatur
Unity Burst Compiler: