Vorwort
Es gibt ein so einfaches und sehr nützliches Dienstprogramm auf der Welt -
BDelta , und es kam vor, dass es lange Zeit in unserem Produktionsprozess Wurzeln schlug (obwohl seine Version nicht installiert werden konnte, aber es war sicherlich nicht die letzte verfügbare). Wir verwenden es für den beabsichtigten Zweck - die Konstruktion von binären Patches. Wenn Sie sich ansehen, was sich im Repository befindet, wird es ein wenig traurig: Tatsächlich wurde es vor langer Zeit aufgegeben und vieles war dort sehr veraltet (nachdem mein ehemaliger Kollege dort mehrere Korrekturen vorgenommen hatte, aber es war vor langer Zeit). Im Allgemeinen habe ich mich entschlossen, dieses Geschäft wiederzubeleben: Ich gabelte, warf heraus, was ich nicht verwenden wollte, überholte das Projekt auf
cmake , inline die "heißen" Mikrofunktionen, entfernte große Arrays vom Stapel (und Arrays variabler Länge, von denen ich offen "bombardierte"). , fuhr noch einmal den Profiler - und fand heraus, dass etwa 40% der Zeit für das
Schreiben aufgewendet wird ...
Also, was ist los mit fwrite?
In diesem Code wird fwrite (in meinem speziellen Testfall: Erstellen eines Patches zwischen knapp 300 MB großen Dateien, die Eingabedaten befinden sich vollständig im Speicher) millionenfach mit einem kleinen Puffer aufgerufen. Offensichtlich wird sich diese Sache verlangsamen, und deshalb möchte ich diese Schande irgendwie beeinflussen. Es besteht kein Wunsch, irgendeine Art von Datenquellen zu implementieren, asynchrone Eingabe-Ausgabe, ich wollte eine einfachere Lösung finden. Das erste, was mir in den Sinn kam, war, den Puffer zu vergrößern
setvbuf(file, nullptr, _IOFBF, 64* 1024)
Aber ich habe keine signifikante Verbesserung des Ergebnisses erzielt (jetzt macht fwrite ungefähr 37% der Zeit aus) - es bedeutet, dass die Angelegenheit immer noch nicht in der häufigen Datenaufzeichnung auf der Festplatte liegt. Wenn Sie „unter der Haube“ schreiben, können Sie sehen, dass die Struktur der Sperr- / Entsperrdatei im Inneren wie folgt abläuft (Pseudocode, alle Analysen wurden unter Visual Studio 2017 durchgeführt):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream) { size_t retval = 0; _lock_str(stream); __try { retval = _fwrite_nolock(buffer, size, count, stream); } __finally { _unlock_str(stream); } return retval; }
Laut dem Profiler macht _fwrite_nolock nur 6% der Zeit aus, der Rest ist Overhead. In meinem speziellen Fall ist die Thread-Sicherheit ein offensichtlicher Überschuss. Ich werde sie opfern, indem ich den fwrite-Aufruf durch
_fwrite_nolock ersetze - selbst bei Argumenten, bei denen ich nicht
klug sein muss . Insgesamt: Diese einfache Manipulation reduzierte zeitweise die Kosten für die Aufzeichnung des Ergebnisses, die in der Originalversion fast die Hälfte der Zeitkosten betrugen. Übrigens gibt es in der POSIX-Welt eine ähnliche Funktion -
fwrite_unlocked . Im Allgemeinen gilt das Gleiche für Fread. So können Sie mit Hilfe des Paares #define eine plattformübergreifende Lösung ohne unnötige Sperren erhalten, wenn diese nicht erforderlich sind (und dies passiert häufig).
fwrite, _fwrite_nolock, setvbuf
Lassen Sie uns vom ursprünglichen Projekt abstrahieren und einen bestimmten Fall testen: Aufzeichnen einer großen Datei (512 MB) in extrem kleinen Portionen - 1 Byte. Testsystem: AMD Ryzen 7 1700, 16 GB RAM, Festplatte 3,5 "7200 U / min 64 MB Cache, Windows 10 1809, das Binar wurde 32-Bit erstellt, Optimierungen sind enthalten, die Bibliothek ist statisch verknüpft.
Probe für das Experiment:
#include <chrono> #include <cstdio> #include <inttypes.h> #include <memory> #ifdef _MSC_VER #define fwrite_unlocked _fwrite_nolock #endif using namespace std::chrono; int main() { std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose); if (!file) return 1; constexpr size_t TEST_BUFFER_SIZE = 256 * 1024; if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0) return 2; auto start = steady_clock::now(); const uint8_t b = 77; constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024; for (size_t i = 0; i < TEST_FILE_SIZE; ++i) fwrite_unlocked(&b, sizeof(b), 1, file.get()); auto end = steady_clock::now(); auto interval = duration_cast<microseconds>(end - start); printf("Time: %lld\n", interval.count()); return 0; }
Die Variablen sind TEST_BUFFER_SIZE. In einigen Fällen ersetzen wir fwrite_unlocked durch fwrite. Beginnen wir mit dem Fall von fwrite, ohne die Puffergröße explizit festzulegen (setvbuf und den zugehörigen Code auskommentieren): Zeit 27048906 μs, Schreibgeschwindigkeit - 18,93 Mb / s. Stellen Sie nun die Puffergröße auf 64 Kb ein: Zeit - 25037111 μs, Geschwindigkeit - 20,44 Mb / s. Jetzt testen wir den Betrieb von _fwrite_nolock, ohne setvbuf aufzurufen: 7262221 ms, die Geschwindigkeit beträgt 70,5 Mb / s!
Als nächstes experimentieren Sie mit der Größe des Puffers (setvbuf):
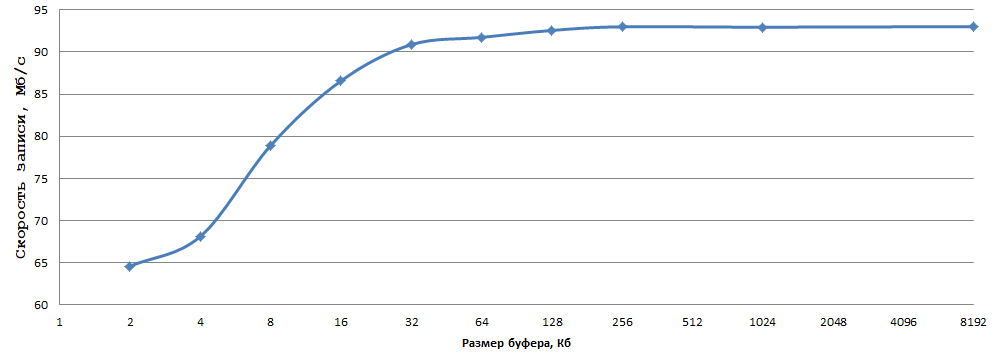
Die Daten wurden durch Mittelung von 5 Experimenten erhalten, ich war zu faul, um die Fehler zu berücksichtigen. Für mich sind 93 MB / s beim Schreiben von 1 Byte auf eine normale Festplatte ein sehr gutes Ergebnis. Wählen Sie einfach die optimale Puffergröße (in meinem Fall 256 KB - genau richtig) und ersetzen Sie fwrite durch _fwrite_nolock / fwrite_unlocked (in wenn keine Gewindesicherheit erforderlich ist, natürlich).
Ähnliches gilt für Fread unter ähnlichen Bedingungen. Nun wollen wir sehen, wie die Dinge unter Linux sind. Die Testkonfiguration ist wie folgt: AMD Ryzen 7 1700X, 16 GB RAM, Festplatte 3,5 "7200 U / min 64 MB Cache, OpenSUSE 15 OS, GCC 8.3.1, wir werden x86-64 Binar, Dateisystem auf testen ext4-Testabschnitt Das Ergebnis von fwrite ohne explizite Einstellung der Puffergröße in diesem Test ist 67,6 Mb / s. Wenn der Puffer auf 256 Kb eingestellt wird, erhöht sich die Geschwindigkeit auf 69,7 Mb / s. Jetzt werden wir ähnliche Messungen für fwrite_unlocked durchführen - die Ergebnisse sind 93,5 bzw. 94,6 Mb / s. Das Variieren der Puffergröße von 1 KB auf 8 MB führte mich zu folgenden Schlussfolgerungen: Durch Erhöhen des Puffers wird die Schreibgeschwindigkeit erhöht. In meinem Fall betrug der Unterschied jedoch nur 3 Mbit / s. Ich bemerkte überhaupt keinen Geschwindigkeitsunterschied zwischen dem 64-Kbit- und dem 8-Mbit-Puffer. Aus den auf diesem Linux-Computer empfangenen Daten können wir die folgenden Schlussfolgerungen ziehen:
- fwrite_unlocked ist schneller als fwrite, aber der Unterschied in der Schreibgeschwindigkeit ist nicht so groß wie unter Windows
- Die Puffergröße unter Linux hat keinen so großen Einfluss auf die Schreibgeschwindigkeit über fwrite / fwrite_unlocked wie unter Windows
Insgesamt ist die vorgeschlagene Methode sowohl unter Windows als auch unter Linux wirksam (wenn auch in viel geringerem Umfang).
Nachwort
Der Zweck dieses Artikels war es, in vielen Fällen eine einfache und effektive Technik zu beschreiben (ich bin früher nicht auf die Funktionen _fwrite_nolock / fwrite_unlocked gestoßen, sie sind nicht sehr beliebt - aber vergebens). Ich gebe nicht vor, neu im Material zu sein, aber ich hoffe, dass der Artikel für die Community nützlich sein wird.