Das Wichtigste für den Yandex.Zen-Dienst ist die Entwicklung und Pflege einer Plattform, die das Publikum mit den Autoren verbindet. Um eine attraktive Plattform für gute Autoren zu sein, muss Zen in der Lage sein, ein relevantes Publikum für Kanäle zu finden, die zu jedem Thema schreiben, einschließlich des engsten. Der Leiter der Autorenglücksgruppe Boris Sharchilev sprach über das autozentrische Ranking, das die relevantesten Benutzer für die Autoren auswählt. Aus dem Bericht können Sie herausfinden, wie sich dieser Ansatz von der Auswahl relevanter Elemente unterscheidet - was in Empfehlungssystemen beliebter ist.
Durch die Balance zwischen benutzerzentriertem und autozentrischem Ranking können wir das richtige Gleichgewicht zwischen Benutzerglück und Autorenglück erreichen.
- Kollegen, hallo alle zusammen. Ich heiße Borya. Ich beschäftige mich mit der Qualität des Rankings im Zen. Ich bin mir sicher, dass dies einer der interessantesten Yandex-Dienste ist. Wir haben sehr cooles maschinelles Lernen und in den nächsten 17 Minuten werde ich versuchen, Sie davon zu überzeugen.
Was ist Zen? Wenn ganz einfach, ist Zen ein persönlicher Empfehlungsservice. Wir versuchen, den Benutzern relevante Inhalte zu empfehlen, basierend auf dem, was wir über die Interessen dieser Benutzer wissen. Unser übergeordnetes Ziel ist es, dass Benutzer Zeit im Zen verbringen. Und was sehr wichtig ist, ist, dass sie diesmal nicht bereuen.
Unsere Grundform des Inhaltskonsums sieht ungefähr so aus. Dies ist ein endloser Strom von Empfehlungen. Und hier ist klar, dass wir im Prinzip versuchen, sehr Materialien zu sehr unterschiedlichen Themen zu empfehlen. Es gibt verschiedene Themen: etwas über das Geschäft, etwas über Humor, sogar etwas über Fantasie. Das heißt, auf dem Band finden Sie sowohl pädagogische als auch pädagogische Artikel sowie unterhaltsamere. Und natürlich Personalisierung. Der Zen-Feed für alle sieht anders aus - je nachdem, woran der Benutzer interessiert ist. Dazu natürlich ein bisschen Werbung.

Ein sehr wichtiger Punkt. Ganz am Anfang, als wir zum ersten Mal auftauchten, waren wir tatsächlich ein Aggregator von Inhalten aus dem Internet. Das heißt, wir haben vorhandene Websites durchsucht, Inhalte von ihnen übernommen und sie dem Benutzer je nach Interesse gezeigt. Jetzt ist die Situation anders. Jetzt ist Zen eine ganze Blogging-Plattform, auf der jeder seinen eigenen Kanal erstellen kann, egal ob es sich um einen berühmten Blogger oder einen Anfänger handelt, der etwas zu erzählen hat. Neue Autoren sehen einen so schönen Begrüßungsbildschirm, auf dem wir über den Service sprechen - dass Zen selbst ein Publikum auswählt und nur gute Materialien schreiben muss.
Jetzt macht die Plattform mehr als die Hälfte des gesamten Datenverkehrs in Zen aus. Und diese Zahl wird nur wachsen. Wir verstehen, dass jeder vorhandene Inhalte bewerten kann. Natürlich werden wir es am besten machen. Aber nicht jeder hat einzigartige Inhalte, und wir glauben, dass dies unser Wettbewerbsvorteil sein wird.

Es ist wichtig zu verstehen, dass Zen bereits sehr groß ist. Laut Yandex.Radar hatten wir Ende letzten Jahres ungefähr 10-12 Millionen tägliche Leser pro Tag, ungefähr 35 Millionen tägliche Leser, und sogar nach einigen Daten von Yandex.Radar hatten wir letztes Jahr Zum ersten Mal gingen sie um das Publikum von Yandex.News herum. Dies bedeutet, dass wir das Internet in aller Ernsthaftigkeit machen, wir haben sehr ernste Aufgaben, es gibt viele davon und wir freuen uns sehr auf Ihre Hilfe.
Lassen Sie uns über die Details der Funktionsweise sprechen und besprechen, was wir mit einem Praktikanten tun können und wie wir unseren Service unterstützen können.
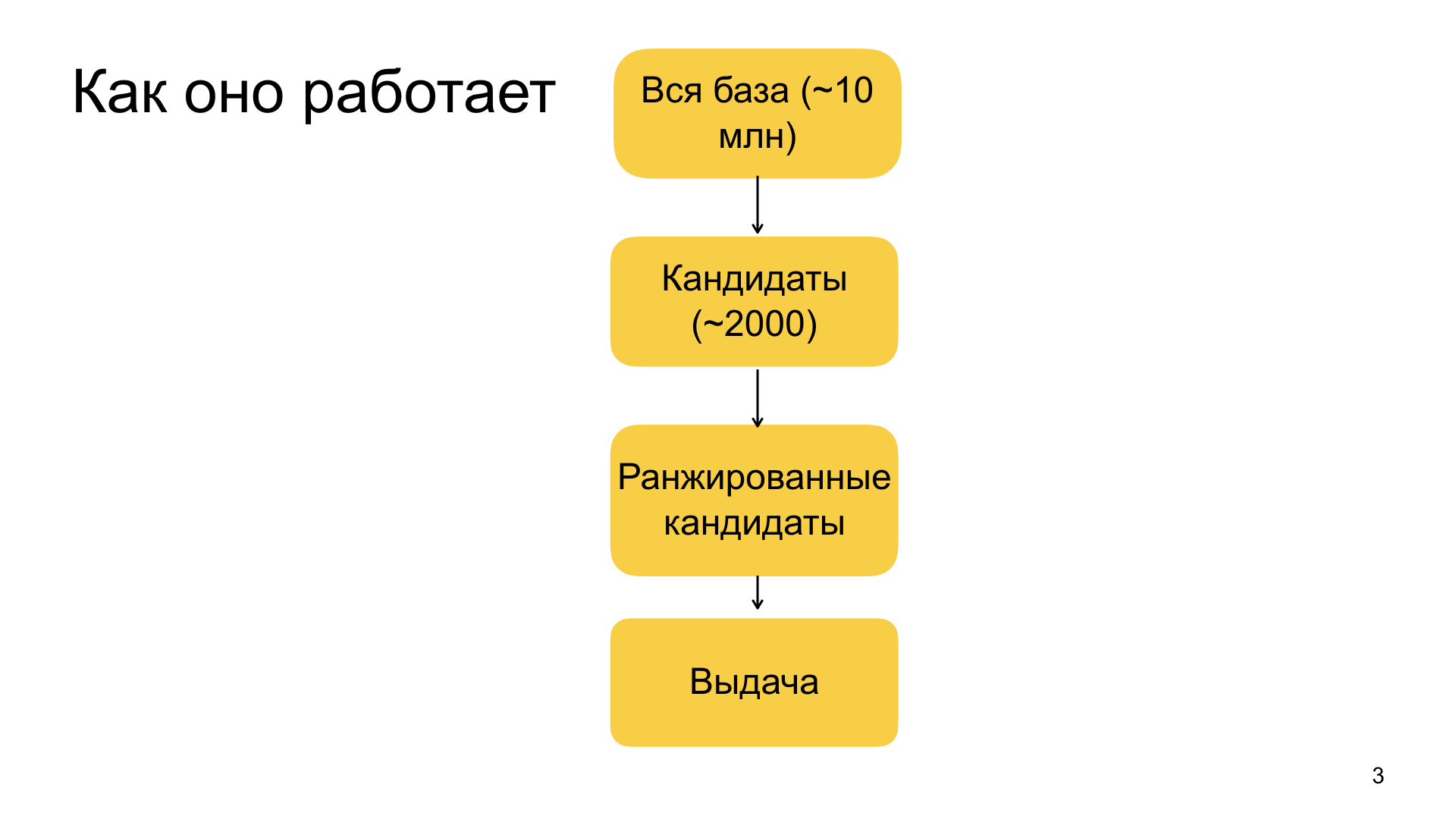
Der allgemeine Überblick über die Empfehlungen, die wir haben, ist so angeordnet. Alles beginnt mit unserer großen Datenbank von Dokumenten, aus denen wir Materialien für Empfehlungen auswählen. Es besteht aus zig Millionen Dokumenten. Darüber hinaus wird diese Datenbank ständig aufgefüllt - täglich kommen etwa eine Million neue Dokumente darin an. Im Idealfall möchten wir unsere gesamte maschinelle Lernmaschine für jeden Benutzer persönlich auf all diese zig Millionen Dokumente anwenden und das für ihn relevanteste auswählen. Leider funktioniert dies in der Praxis nicht, da Zen ein Dienst ist, der in Echtzeit funktioniert. Wir haben sehr strenge Garantien dafür, wie schnell wir bereit sind zu reagieren. Aus praktischen Gründen sind wir daher gezwungen, die Basis von zig Millionen Dokumenten in der ersten Phase auf Tausende potenzieller Empfehlungen zu beschränken, die wir bereits vollständig mit unserem Modell in Einklang bringen und die relevantesten auswählen können. Diese Phase der Verengung der Basis von zig Millionen auf etwa Tausende wird als Auswahl von Kandidaten oder einfaches Ranking bezeichnet.
Wenn wir dieses Kit haben, wenden wir darauf unser komplexes großes Modell für maschinelles Lernen an, das auf der obersten Ebene die Gradientensteigerung fördert. Dies alles ist ohne Überraschungen, aber wir haben sehr unterschiedliche Faktoren - von einigen einfachen, die beispielsweise charakterisieren, wie relevant die Domain für den Benutzer ist, die Quelle, wie oft sie besucht, klickt, Feedback hinterlässt, Vorlieben und Abneigungen. Dies gilt auch für komplexere Faktoren, die beispielsweise auf neuronalen Netzwerkfunktionen basieren. Wir verarbeiten den Text des Artikels, wir verarbeiten Bilder und andere Datenquellen und wir verwenden auch solche zusammengesetzten Funktionen. All dieses Schema ist ziemlich kompliziert, ich werde keine Zeit haben, es Ihnen im Detail zu erzählen.
Nachdem wir unsere zweitausend Kandidaten bewertet haben, wählen wir die Spitze aus ihnen aus. Die Größe des Oberteils hängt davon ab, wie viel Material wir empfehlen müssen. Es ist immer anders definiert. Und so bilden wir die letzte Ausgabe.
So sieht die Schaltung auf hohem Niveau aus. Lassen Sie uns nun darüber sprechen, welche Komponenten des gesamten Prozesses wir verbessern möchten.

Es stellt sich heraus, dass wir an fast allem interessiert sind. Es gibt viele Aufgaben. Wir möchten die Geschwindigkeit der Datenlieferung für das Ranking erhöhen: Je aktueller die Daten sind, desto relevanter sind unsere Empfehlungen. Ich möchte den Service beschleunigen: Je schneller wir arbeiten, desto besser ist die Benutzererfahrung. Wir wollen die Zuverlässigkeit des Dienstes erhöhen.
Es ist uns wichtig, das Ranking zu verbessern. Das heißt, wir müssen neue Modelle des maschinellen Lernens anwenden und unsere derzeitigen Modelle in anderen Ländern verbessern. Wir werden nicht nur in Russland, sondern auch in vielen anderen Ländern der Welt empfohlen.
Wir möchten auch die Regionalität berücksichtigen und den Menschen den Inhalt empfehlen, der sich auf ihre Region bezieht.
Und es ist sehr wichtig - wir müssen unsere Authoring-Plattform entwickeln. Dies ist unsere Zukunft, wir müssen in sie investieren. Es gibt auch viele Aufgaben. Insbesondere müssen wir in der Lage sein, qualitativ hochwertige Inhalte zu finden und zu starten. Es ist wichtig, dass wir gute Materialien zeigen, keinen Müll. Wir müssen in der Lage sein, neue Inhaltsformate zu bewerten. Wir haben nicht nur Artikel, sondern auch kurze Videos und Beiträge, die Benutzer direkt im Feed ansehen. Alle diese Formate müssen eingestuft werden können.
Und ein sehr wichtiger Punkt, über den ich ausführlicher und technischer sprechen möchte - es ist wichtig, dass jeder Autor ein für ihn relevantes Publikum findet, auch wenn es um hübsche Nischenautoren und -themen geht. Lassen Sie uns genauer sprechen, was hier das Problem ist und wie wir es lösen.
Schauen wir uns ein Beispiel an.
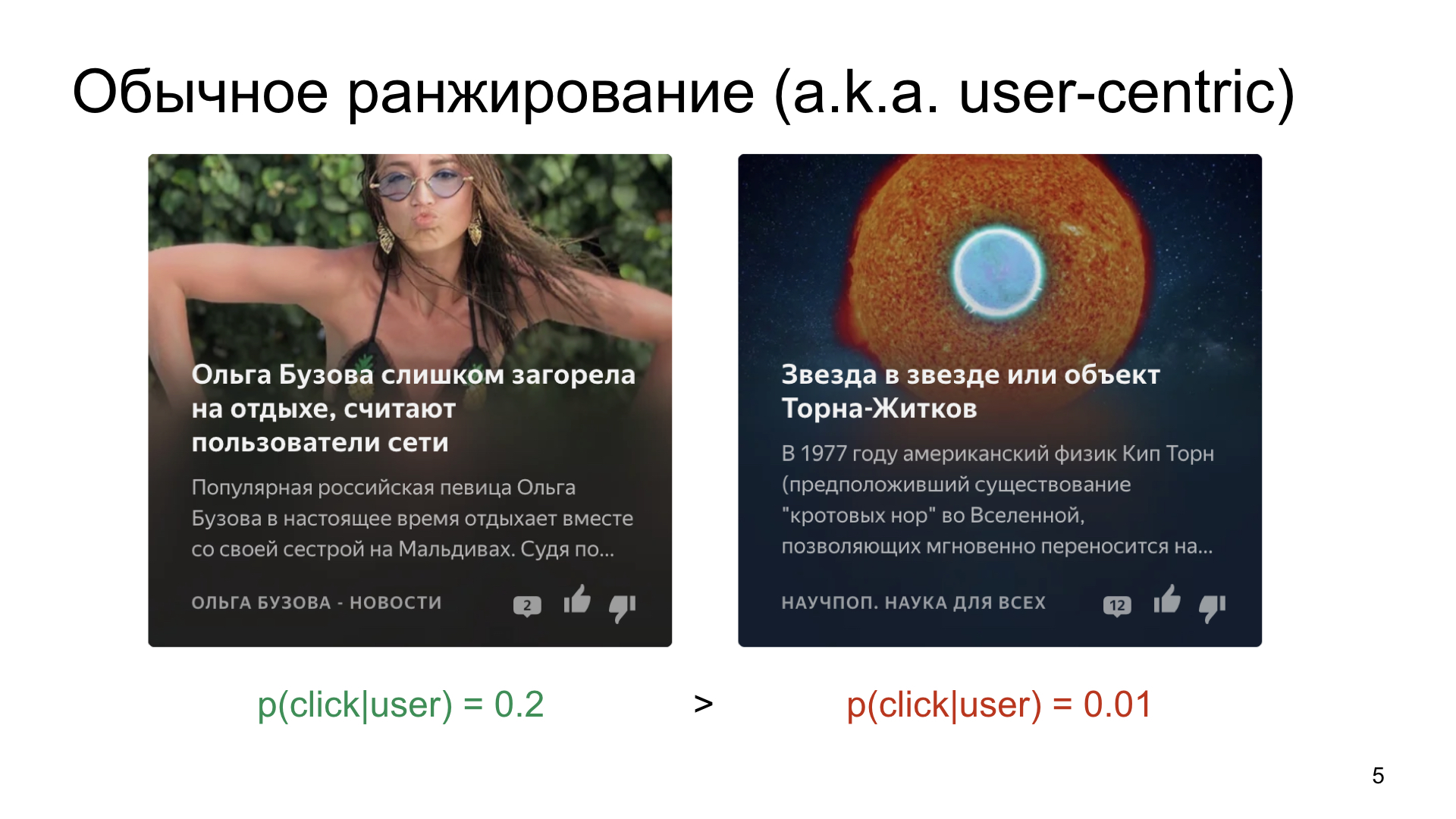
Wir wählen aus zwei Karten aus, die wir dem Benutzer zeigen möchten.
So funktioniert die Welt und die Art und Weise, wie Menschen arbeiten, dass es etwas Durchschnittlicheres gibt, bei dem die Wahrscheinlichkeit eines Klicks durchschnittlich 20 Prozent beträgt, und es gibt etwas Nischeres, zum Beispiel Artikel über Wissenschaft oder Raum.
Wenn wir Karten einfach nach der Wahrscheinlichkeit eines Klicks ordnen, werden natürlich klickbarere und einfachere Inhalte eine sehr große Anzahl von Impressionen sammeln, und selbst ein sehr guter Artikel über die Wissenschaft wird dies nicht tun. Das wollen wir natürlich nicht. Wir wollen auch für Nischenkanäle ein interessiertes Publikum finden.

Warum willst du das tun? In der Tat gibt es zwei Gründe. Der erste ist Lebensmittelgeschäft. Das heißt, wir wollen, dass Zen eine Art Schnitt des Internets ist. Damit alles, was der Benutzer im großen Internet finden kann und woran er interessiert ist, im Zen präsentiert wird. Und damit er erhält, was ihn interessiert.
Wissenschaftliche Kanäle haben ihr eigenes Publikum. Aber es gibt eine solche Nuance. Wenn Wissenschaftsliebhaber Wissenschaft und populäre Inhalte zeigen, klicken sie eher darauf als auf Wissenschaft. Wenn Sie ihnen jedoch nur Wissenschaft zeigen, klicken sie auch auf Wissenschaft und werden es nicht einmal bereuen. Die Frage ist, wie man solche Leute findet und wie man Inhalte anzeigt, wobei man sich nicht auf den Benutzer, sondern auf den Autor konzentriert.

Wie geht das? Die übliche Ranking-Formel, die die Wahrscheinlichkeit von Klicks vorhersagt, hilft uns hier nicht weiter, da im Durchschnitt mehr Nischenartikel verlieren. Sie können aber auch in die andere Richtung gehen: Um eine bestimmte Quote zuzuweisen und den Autoren mehr oder weniger gleichmäßig Eindrücke zu vermitteln, geben Sie ihnen eine Art minimale Garantie. Dies kann getan werden, und dies wird die Autoren ein wenig glücklicher machen, aber leider wird dies unsere Benutzer weniger glücklich machen. Benutzer werden weniger klicken, mehr verärgert sein und gehen. Das wollen wir natürlich nicht.
Wie kann man hier sein?
Wir haben lange nachgedacht und uns ein neues Konzept ausgedacht. Wir nannten es autozentrische Rankings oder Impressionen für den Autor.
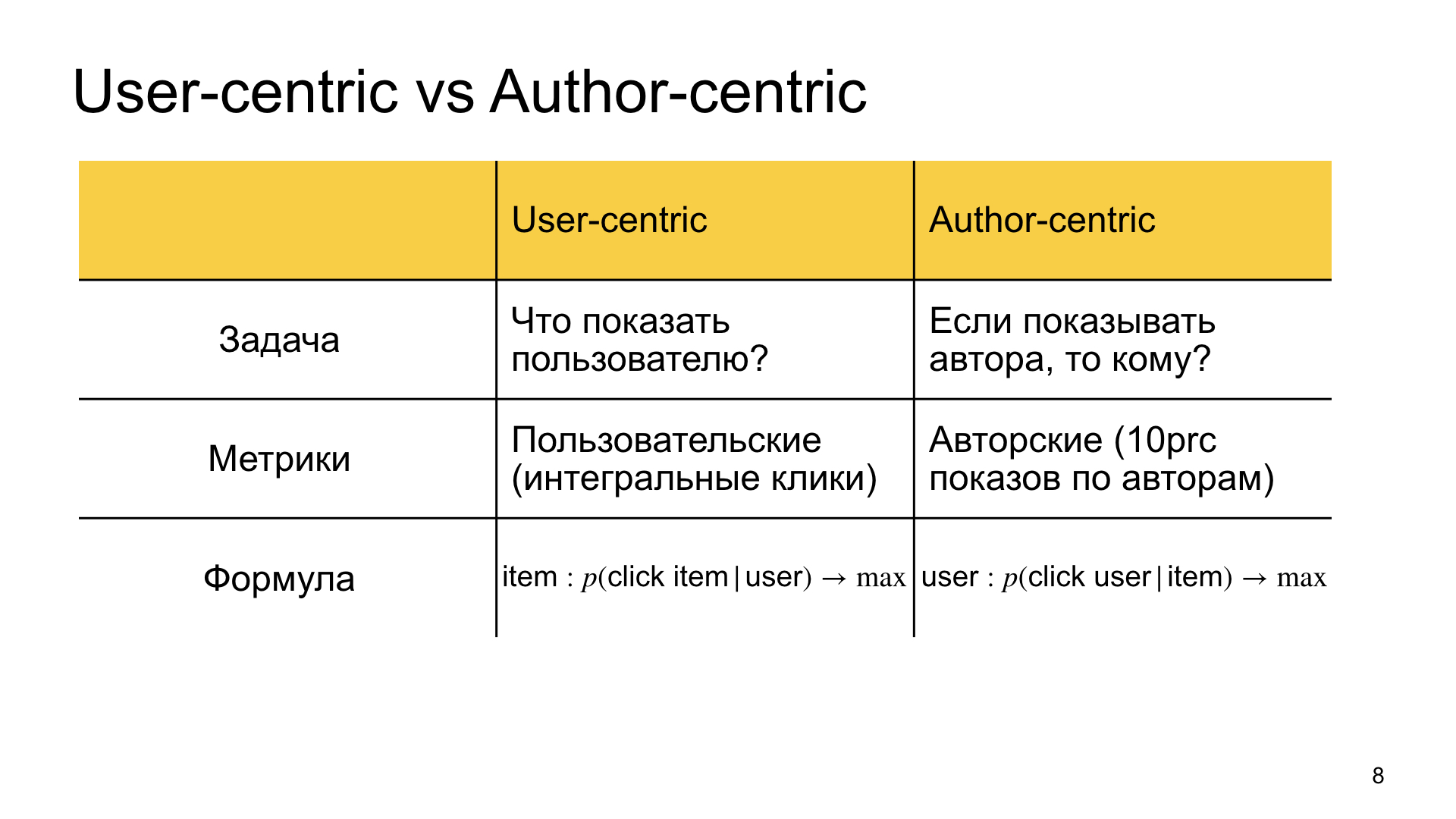
Was ist unser Ziel im regulären Ranking, das wir als usercentric bezeichnen? Finden Sie das Material, das für den Benutzer am relevantesten ist. Wir beantworten die Frage, was dem Benutzer gezeigt werden soll.
Im autozentrischen Ranking stürzen wir die Problemstellung irgendwie um und sagen, dass wir diesen Autor zeigen wollen, und die Frage ist, wem wir ihn zeigen sollen, für wen er am relevantesten ist. Daher der Unterschied in den Metriken. Im ersten Fall interessieren wir uns mehr für benutzerdefinierte Metriken, dh integrale Klicks, integrale Zeit im Zen und so weiter. Im zweiten Fall interessieren uns die sogenannten Autorenmetriken. Zum Beispiel messen wir, wie gut Zen lebt, zum Beispiel unter 10% der Autoren. Wenn sie gut genug leben, sind auch alle anderen glücklich.

Wie machen wir das? Angenommen, wir haben die übliche Rangfolgeformel. Nehmen wir zur Vereinfachung an, dass die Wahrscheinlichkeit vorhergesagt wird, dass ein Benutzer auf ein bestimmtes Objekt auf einer bestimmten Karte klickt. Was werden wir tun? Lassen Sie es uns nun für jeden Artikel beheben und unser Modell für diesen Artikel idealerweise - in der Praxis für alle Benutzer - auf eine Art Benutzerbeispiel anwenden. Und wir werden eine Verteilung unserer Punktzahlen erstellen, dh Schätzungen der Wahrscheinlichkeit, auf einen Artikel zu klicken, für jeden Artikel durch Benutzer. Jetzt haben wir für jeden Artikel eine Verteilung wie in der Tabelle (Folie oben - ca. Ed.). Danach ordnen wir die Artikel für den Benutzer und wählen die Spitze nicht nur nach der Wahrscheinlichkeit eines Klicks aus, sondern auch nach dem Perzentil, in das dieser Benutzer für diesen Artikel fällt. Das heißt, wir schätzen die Wahrscheinlichkeit eines Klicks, sehen, wo der Benutzer in diese Verteilung fällt, und ordnen nach diesem Wert.

Hier haben wir die gleichen zwei Karten, eine davon ist klickbarer, 20%, die andere - weniger als 1%. Wenn Sie nun einen bestimmten Benutzer nehmen, ist eine solche Situation möglich, dass er die Möglichkeit hat, auf eine beliebtere Karte zu klicken als auf eine weniger beliebte, z. B. 10% gegenüber 3%. Da die durchschnittliche Wahrscheinlichkeit eines Klicks auf eine beliebte Karte 20% beträgt und der Benutzer 10% hat, ist er für diese Veröffentlichung im Durchschnitt weniger relevant als der durchschnittliche Zen-Benutzer. Und in einer anderen Situation das Gegenteil: Er hat eine 3% ige Chance auf einen Klick, aber der durchschnittliche Artikel hat 1%. Daher ist es ein durchschnittliches Publikum, das für den Artikel relevanter ist als andere Zen-Benutzer. Daher ist die wichtigste Erkenntnis hier, dass wir mit Hilfe eines solchen Frameworks die Möglichkeit haben, einen weniger beliebten Artikel anzuzeigen, selbst wenn die Wahrscheinlichkeit eines Klicks auf einen Artikel geringer ist, wenn sich der Benutzer im vertrauenswürdigsten Kern dieser Veröffentlichung befindet.

Wenn Benutzer mehr oder weniger gleichmäßig zu uns kommen, wird die angegebene Punktzahl, nach der wir rangieren, dh das Perzentil, in das jeder Benutzer fällt, gleichmäßig auf die Benutzer verteilt. Das heißt, wenn alle Artikel auf diese Weise eingestuft werden, sammeln sie alle mehr oder weniger die gleiche Anzahl von Impressionen. Es werden keine Emissionen von zig Millionen Impressionen im Vergleich zu 10 Impressionen einiger weniger relevanter Karten ausgegeben. Durch das Abwägen von benutzerzentriertem und autozentrischem Ranking können wir das Verhältnis von Benutzerglück und Autorenglück erreichen, das wir für richtig halten.
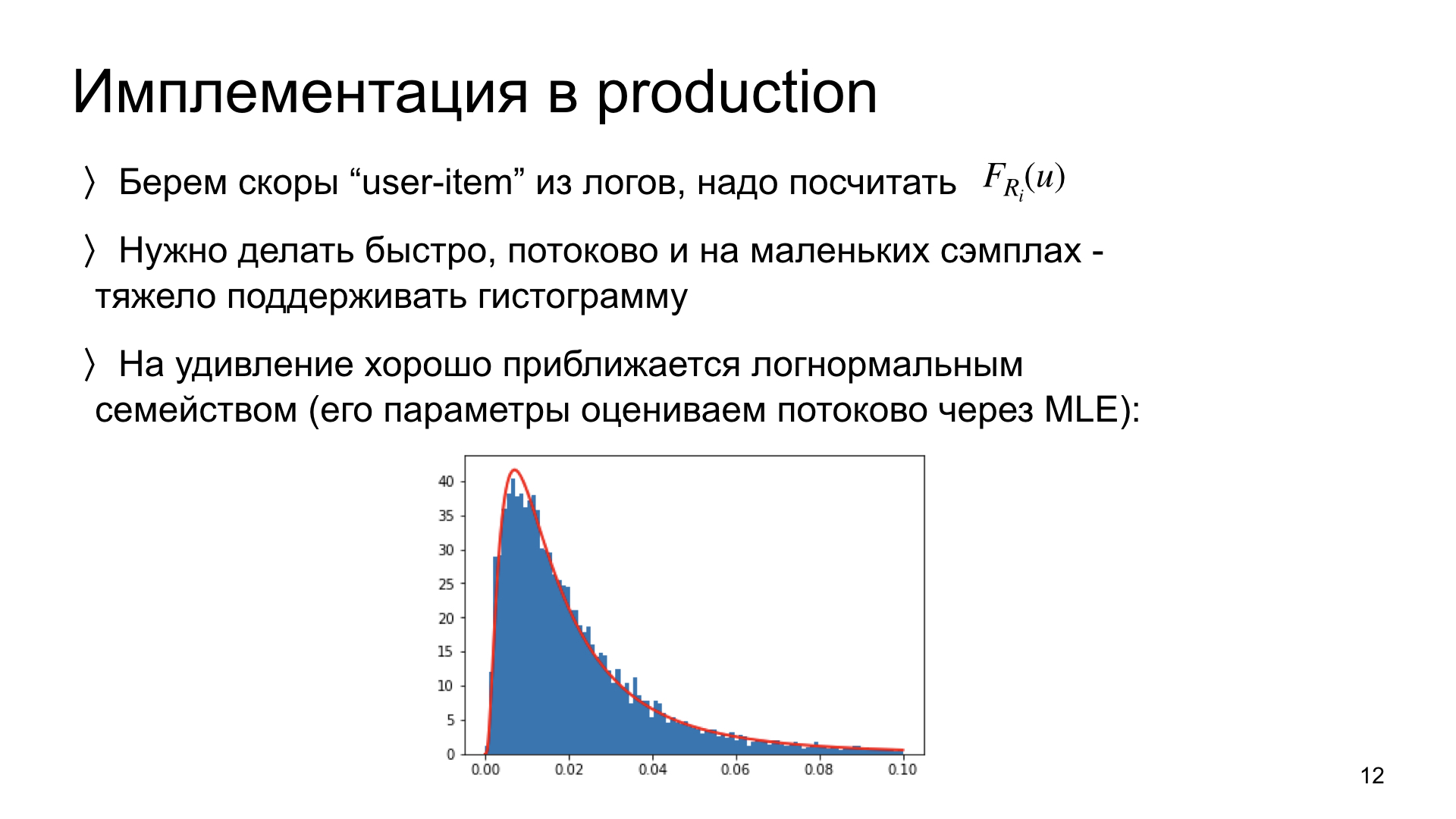
Ein paar Worte darüber, wie wir dies in der Produktion umsetzen. Wir müssen uns unsere Protokolle ansehen und die Verteilung für jeden Artikel daraus berechnen. Eine wichtige Einschränkung: Wir müssen dies erstens schnell und zweitens im Streaming-Modus tun können. Das heißt, um die Verteilungsschätzung für neue Daten zu aktualisieren, müssen im Idealfall nicht alle vorherigen Daten gespeichert werden, sondern nur die aktuelle Schätzung. Ein solches System ist skalierbar, ein solches Schema funktioniert. Idealerweise müssen wir dies für kleine Datenmengen tun können. Wenn ein Artikel nur 300 Impressionen enthält, müssen wir in der Lage sein, die Verteilung für eine solche Anzahl von Beobachtungen angemessen abzuschätzen.
Wir haben Experimente durchgeführt und festgestellt, dass solche Punkteverteilungen überraschend nahe an logarithmischen Normalverteilungen liegen. Das heißt, dies ist eine empirische Beobachtung. Und wenn ja, können wir, anstatt das gesamte Histogramm der Verteilung nicht parametrisch zu schätzen, nur zwei Parameter dieser Verteilung auswerten. Und wir können dies im Stream tun, indem wir nur die aktuelle Parameterschätzung und neue Beobachtungen verwenden. Ein solches Schema ist sehr schnell und funktioniert sehr gut. Jetzt ist sie bei uns in Produktion.
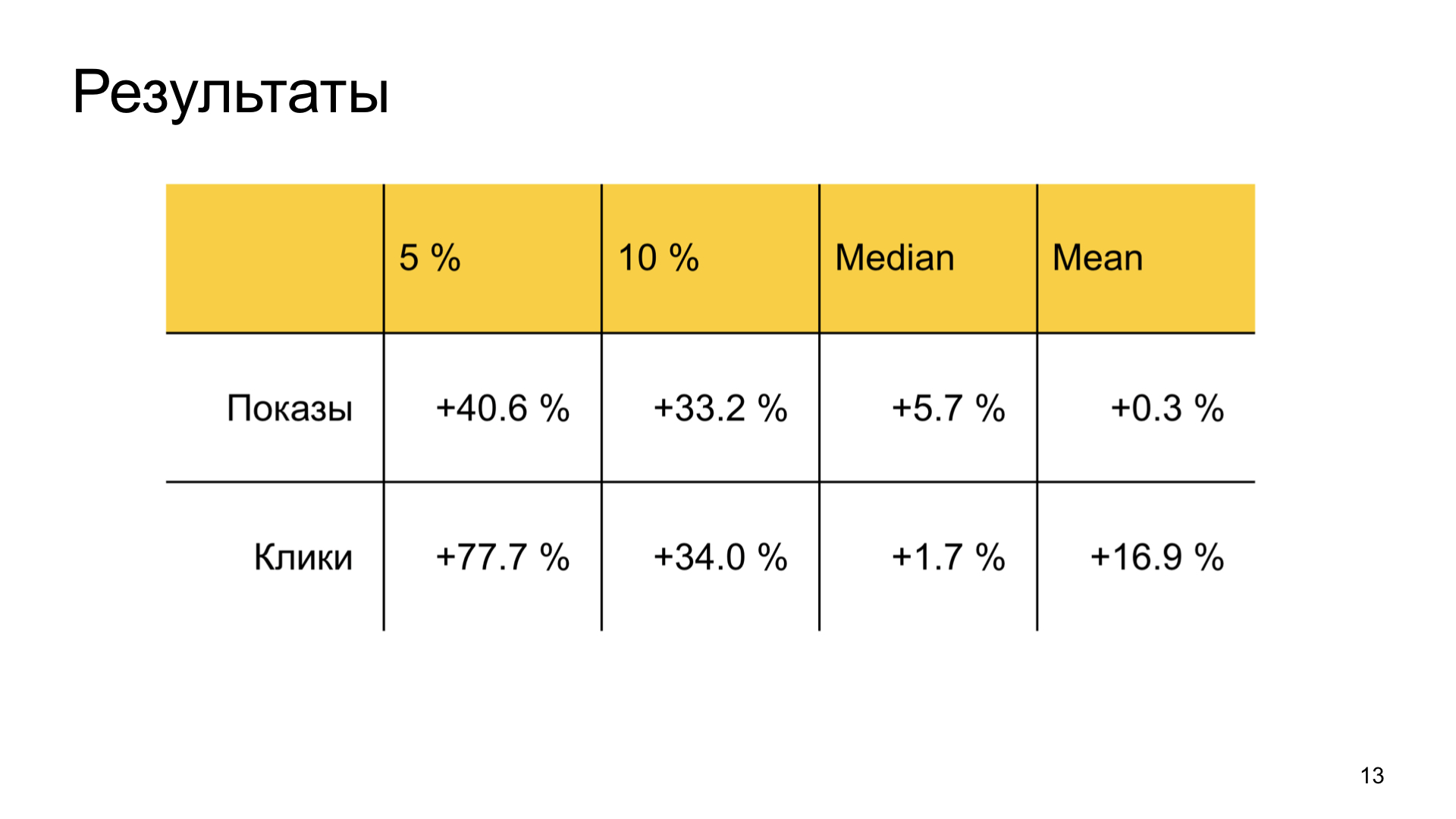
Die Ergebnisse sind auch gut. Wir steigern das Glück vernachlässigter guter Autoren im Zen erheblich und verschwenden keine gängigen Benutzerkennzahlen. Das heißt, die Geschäftsaufgabe ist vollständig erfüllt.
Ich habe jetzt eines der Beispiele für Aufgaben gezeigt, mit denen wir uns befassen können. Natürlich gibt es viele dieser Aufgaben, und bei jeder dieser Aufgaben benötigen wir Ihre Hilfe. Wir hoffen sehr, dass Sie
mit uns zusammenarbeiten möchten. Am Ende werde ich ein paar Worte darüber sagen, was wir von Praktikanten erwarten und was wir nicht von ihnen erwarten. Vom Auszubildenden erwarten wir das Wichtigste - die Fähigkeit, Code zu schreiben. Wir haben keine reinen Wissenschaftler im Dienst. Wir sind alle ML-Ingenieure, sie müssen in der Lage sein, den gesamten Zyklus der Aufgaben zu erledigen. Sie müssen in der Lage sein, ihre Lösung in der Produktion umzusetzen und ML anzuwenden. Das heißt, wir erwarten, dass Sie Code auf einer grundlegenden Ebene schreiben, die Ansätze verstehen, die Algorithmen, Datenstrukturen und die Grundlagen des maschinellen Lernens kennen.
Was erwarten wir nicht von Praktikanten? Erstens erwarten wir keine tiefen Kenntnisse von Sprachen oder Frameworks. Das heißt, wenn Sie nicht wissen, wie Coroutinen in Python funktionieren, ist es in Ordnung, wir bringen Ihnen alles bei. Und wir erwarten nicht viel Erfahrung von Ihnen. Wir erwarten Wissen von Ihnen, den Wunsch zu arbeiten. Wenn es keine Erfahrung gibt, ist es okay. Wir werden alles lehren und alles wird gut. Vielen Dank!