Für diejenigen, die zu faul sind, um alles zu lesen: Es wird eine Widerlegung von sieben populären Mythen vorgeschlagen, die im Bereich der maschinellen Lernforschung ab Februar 2019 häufig als wahr angesehen wird. Dieser Artikel ist auf
der ArXiv-Website im PDF-Format [in englischer Sprache] verfügbar.
Mythos 1: TensorFlow ist eine Tensorbibliothek.
Mythos 2: Bilddatenbanken spiegeln echte Fotos wider, die in der Natur gefunden wurden.
Mythos 3: MO-Forscher verwenden keine Testkits zum Testen.
Mythos 4: Neuronales Netzwerktraining verwendet alle Eingabedaten.
Mythos 5: Eine Chargennormalisierung ist erforderlich, um sehr tiefe Restnetzwerke zu trainieren.
Mythos 6: Netzwerke mit Aufmerksamkeit sind besser als Faltung.
Mythos 7: Signifikanzkarten sind eine zuverlässige Methode zur Interpretation neuronaler Netze.
Und jetzt zu den Details.
Mythos 1: TensorFlow ist eine Tensorbibliothek
Tatsächlich ist dies eine Bibliothek für die Arbeit mit Matrizen, und dieser Unterschied ist sehr bedeutend.
Bei der
Berechnung von Derivaten höherer Ordnung von Matrix- und Tensorausdrücken. Laue et al. Die Autoren von
NeurIPS 2018 zeigen, dass ihre Bibliothek der automatischen Differenzierung, basierend auf der realen Tensorrechnung, viel kompaktere Expressionsbäume aufweist. Tatsache ist, dass die Tensorrechnung die Indexnotation verwendet, mit der Sie gleichermaßen mit dem direkten und dem umgekehrten Modus arbeiten können.
Die Matrixnummerierung verbirgt Indizes zur Vereinfachung der Notation, weshalb automatische Differenzierungsausdrucksbäume häufig zu komplex werden.
Betrachten Sie die Matrixmultiplikation C = AB. Wir haben
für direkten Modus und
für das Gegenteil. Um die Multiplikation korrekt durchzuführen, müssen Sie die Reihenfolge und Verwendung der Silbentrennung genau beachten. Aus Sicht der Aufzeichnung sieht dies für eine an MO beteiligte Person verwirrend aus, aus Sicht der Berechnungen ist dies jedoch eine zusätzliche Belastung für das Programm.
Ein anderes Beispiel, weniger trivial: c = det (A). Wir haben
für direkten Modus und
für das Gegenteil. In diesem Fall ist es offensichtlich unmöglich, den Ausdrucksbaum für beide Modi zu verwenden, da sie aus unterschiedlichen Operatoren bestehen.
Im Allgemeinen hat die Art und Weise, wie TensorFlow und andere Bibliotheken (z. B. Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS-Autograd) eine automatische Differenzierung implementiert, was dazu führt, dass für direkte und umgekehrte Im Modus werden verschiedene und ineffektive Ausdrucksbäume erstellt. Die Tensornummerierung umgeht diese Probleme aufgrund der Kommutativität der Multiplikation aufgrund der Indexnotation. Einzelheiten dazu finden Sie im wissenschaftlichen Artikel.
Die Autoren testeten ihre Methode, indem sie das umgekehrte Regime, auch als Rückausbreitung bekannt, in drei verschiedenen Aufgaben automatisch differenzierten und die Zeit maßen, die zur Berechnung der Hessen benötigt wurde.

Im ersten Problem wurde die quadratische Funktion x
T Ax optimiert. In der zweiten wurde die logistische Regression berechnet, in der dritten - Matrixfaktorisierung.
Auf der CPU erwies sich ihre Methode als zwei Größenordnungen schneller als beliebte Bibliotheken wie TensorFlow, Theano, PyTorch und HIPS autograd.
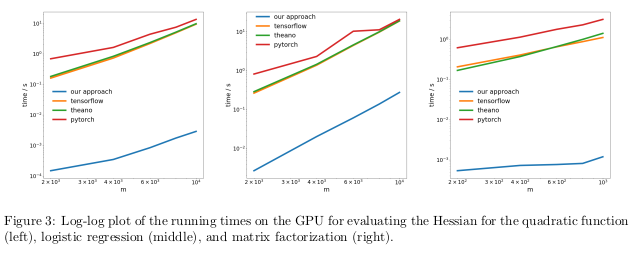
Auf der GPU beobachteten sie eine noch größere Beschleunigung um bis zu drei Größenordnungen.
Die Folgen:Das Berechnen von Ableitungen für Funktionen zweiter oder höherer Ordnung unter Verwendung aktueller Deep-Learning-Bibliotheken ist aus rechnerischer Sicht zu teuer. Dies schließt die Berechnung allgemeiner Tensoren vierter Ordnung wie Hessische ein (z. B. in MAML und Newtons Optimierung zweiter Ordnung). Glücklicherweise sind quadratische Formeln beim tiefen Lernen selten. Sie finden sich jedoch häufig im „klassischen“ maschinellen Lernen -
SVM , Methode der kleinsten Quadrate, LASSO, Gaußsche Prozesse usw.
Mythos 2: Bilddatenbanken spiegeln Fotos aus der realen Welt wider
Viele Menschen denken gerne, dass neuronale Netze gelernt haben, Objekte besser zu erkennen als Menschen. Es ist nicht so. Sie können aufgrund ausgewählter Bilder, z. B. ImageNet, den Menschen voraus sein, aber im Falle der Erkennung von Objekten aus realen Fotos aus dem normalen Leben können sie einen normalen Erwachsenen definitiv nicht überholen. Dies liegt daran, dass die Auswahl der Bilder in den aktuellen Datensätzen nicht mit der Auswahl aller möglichen Bilder übereinstimmt, die in der Realität natürlich vorkommen.
In einer ziemlich alten Arbeit,
Unbiased Look at Dataset Bias. Torralba und Efros. CVPR 2011. , Die Autoren schlugen vor, die mit einer Reihe von Bildern verbundenen Verzerrungen in zwölf gängigen Datenbanken zu untersuchen und herauszufinden, ob es möglich ist, den Klassifikator zu trainieren, um den Datensatz zu bestimmen, aus dem dieses Bild aufgenommen wurde.

Die Wahrscheinlichkeit, versehentlich den richtigen Datensatz zu erraten, liegt bei 1/12 ≈ 8%, während die Wissenschaftler selbst mit einer Erfolgsquote von> 75% die Aufgabe bewältigten.
Sie trainierten SVM anhand eines
Richtungsgradienten-Histogramms (HOG) und stellten fest, dass der Klassifikator die Aufgabe in 39% der Fälle erledigte, was die zufälligen Treffer deutlich übersteigt. Wenn wir dieses Experiment heute mit den fortschrittlichsten neuronalen Netzen wiederholen würden, würden wir sicherlich eine Erhöhung der Genauigkeit des Klassifikators sehen.
Wenn die Bilddatenbanken die wahren Bilder der realen Welt korrekt anzeigen würden, müssten wir nicht feststellen können, aus welchem Datensatz ein bestimmtes Bild stammt.

Es gibt jedoch Merkmale in den Daten, die jeden Bildsatz von den anderen unterscheiden. ImageNet hat viele Rennwagen, die das „theoretische“ Durchschnittsauto als Ganzes wahrscheinlich nicht beschreiben.

Die Autoren bestimmten auch den Wert jedes Datensatzes, indem sie maßen, wie gut ein auf einem Satz trainierter Klassifikator mit Bildern aus anderen Sätzen funktioniert. Nach dieser Metrik erwiesen sich die LabelMe- und ImageNet-Datenbanken als am wenigsten voreingenommen, da sie nach der Methode des „Währungskorbs“ ein Rating von 0,58 erhalten hatten. Es stellte sich heraus, dass alle Werte kleiner als eins sind, was bedeutet, dass das Training mit einem anderen Datensatz immer zu einer schlechten Leistung führt. In einer idealen Welt ohne voreingenommene Mengen sollten einige Zahlen eine überschritten haben.
Die Autoren folgerten pessimistisch:
Welchen Wert haben vorhandene Datensätze für Trainingsalgorithmen, die für die reale Welt entwickelt wurden? Die resultierende Antwort kann als "besser als nichts, aber nicht viel" beschrieben werden.
Mythos 3: MO-Forscher verwenden keine Testkits zum Testen
Im Lehrbuch über maschinelles Lernen lernen wir, den Datensatz in Training, Bewertung und Verifikation zu unterteilen. Die Effektivität des Modells, das anhand des Trainingssatzes trainiert und anhand der Bewertung bewertet wurde, hilft der am MO beteiligten Person, das Modell zu optimieren, um die Effizienz bei seiner tatsächlichen Verwendung zu maximieren. Der Testsatz muss erst berührt werden, wenn die Person die Anpassung abgeschlossen hat, um eine unvoreingenommene Bewertung der tatsächlichen Wirksamkeit des Modells in der realen Welt zu erhalten. Wenn eine Person in der Trainings- oder Bewertungsphase mit einem Testsatz betrügt, besteht die Gefahr, dass das Modell für einen bestimmten Datensatz zu angepasst wird.
In der hart umkämpften Welt der MO-Forschung werden neue Algorithmen und Modelle häufig anhand der Effektivität ihrer Arbeit mit Verifizierungsdaten beurteilt. Daher ist es für Forscher nicht sinnvoll, Artikel zu schreiben oder zu veröffentlichen, in denen Methoden beschrieben werden, die mit Testdatensätzen schlecht funktionieren. Dies bedeutet im Wesentlichen, dass die Gemeinde der gesamten Region Moskau einen Testsatz zur Bewertung verwendet.
Was sind die Folgen dieses Betrugs?

Autoren von
Verallgemeinern CIFAR-10-Klassifikatoren auf CIFAR-10? Recht et al. ArXiv 2018 untersuchte dieses Problem, indem es eine neue Testsuite für CIFAR-10 erstellte. Zu diesem Zweck haben sie eine Auswahl von Bildern aus Tiny Images getroffen.
Sie entschieden sich für CIFAR-10, weil es einer der am häufigsten verwendeten Datensätze im MO ist, dem zweitbeliebtesten Satz in NeurIPS 2017 (nach MNIST). Der Prozess zum Erstellen eines Datensatzes für CIFAR-10 ist ebenfalls gut beschrieben und transparent. In der großen Tiny Images-Datenbank befinden sich viele detaillierte Beschriftungen, sodass Sie einen neuen Testsatz reproduzieren und so die Verteilungsverschiebung minimieren können.

Sie fanden heraus, dass eine große Anzahl verschiedener Modelle neuronaler Netze im neuen Testsatz einen signifikanten Rückgang der Genauigkeit aufwies (4% - 15%). Der relative Leistungsrang jedes Modells blieb jedoch ziemlich stabil.
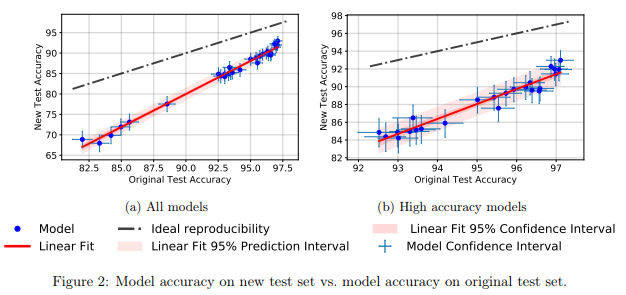
Im Allgemeinen zeigten Modelle mit besserer Leistung einen geringeren Genauigkeitsabfall als Modelle mit schlechterer Leistung. Dies ist schön, da sich daraus ergibt, dass der Verlust der Generalisierbarkeit des Modells aufgrund von Betrug, zumindest im Fall von CIFAR-10, abnimmt, wenn die Community verbesserte MO-Methoden und -Modelle erfindet.
Mythos 4: Neuronales Netzwerktraining verwendet alle Eingaben
Es ist allgemein anerkannt, dass
Daten ein neues Öl sind und dass je mehr Daten wir haben, desto besser können wir Deep-Learning-Modelle trainieren, die jetzt ineffizient und überparametrisiert sind.
In
einer empirischen Studie zum Beispiel des Vergessens während des Lernens in tiefen neuronalen Netzen. Toneva et al. Die Autoren des
ICLR 2019 zeigen eine signifikante Redundanz in mehreren gängigen Sätzen kleiner Bilder. Überraschenderweise können 30% der Daten aus CIFAR-10 einfach entfernt werden, ohne die Genauigkeit der Prüfung erheblich zu verändern.
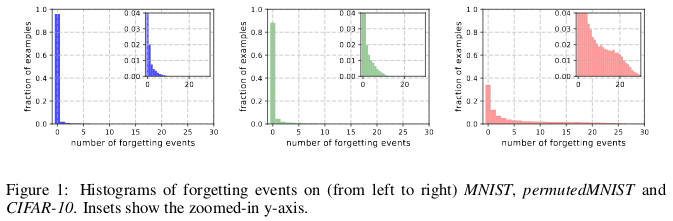 Geschichten des Vergessens von (von links nach rechts) MNIST, permutedMNIST und CIFAR-10.
Geschichten des Vergessens von (von links nach rechts) MNIST, permutedMNIST und CIFAR-10.Das Vergessen geschieht, wenn ein neuronales Netzwerk ein Bild zum Zeitpunkt t + 1 falsch klassifiziert, während es zum Zeitpunkt t ein Bild korrekt klassifizieren konnte. Der Zeitfluss wird durch SGD-Updates gemessen. Um das Vergessen zu verfolgen, starteten die Autoren ihr neuronales Netzwerk nach jedem SGD-Update mit einem kleinen Datensatz und nicht mit allen in der Datenbank verfügbaren Beispielen. Beispiele, die nicht vergessen werden müssen, werden als unvergessliche Beispiele bezeichnet.
Sie fanden heraus, dass 91,7% MNIST, 75,3% permutierter MNIST, 31,3% CIFAR-10 und 7,62% CIFAR-100 unvergessliche Beispiele sind. Dies ist intuitiv verständlich, da eine Erhöhung der Diversität und Komplexität des Datensatzes dazu führen sollte, dass das neuronale Netzwerk weitere Beispiele vergisst.

Unvergessliche Beispiele scheinen seltener und seltsamer zu sein als unvergessliche. Die Autoren vergleichen sie mit Unterstützungsvektoren in SVM, da sie den Umriss von Entscheidungsgrenzen zu zeichnen scheinen.
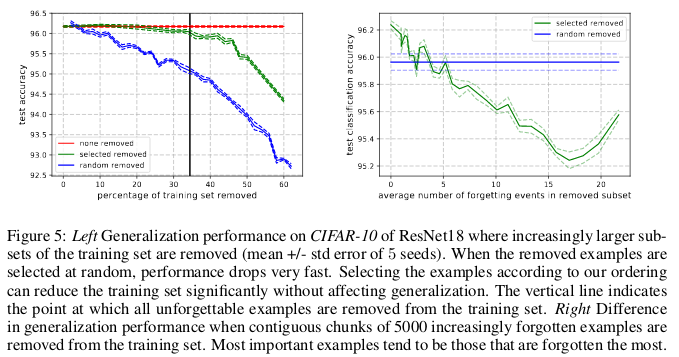
Unvergessliche Beispiele verschlüsseln wiederum meist redundante Informationen. Wenn wir die Beispiele nach dem Grad der Unvergesslichkeit sortieren, können wir den Datensatz komprimieren, indem wir die unvergesslichsten löschen.
30% der CIFAR-10-Daten können gelöscht werden, ohne die Genauigkeit der Prüfungen zu beeinträchtigen, und das Löschen von 35% der Daten führt zu einem leichten Rückgang der Genauigkeit der Prüfungen um 0,2%. Wenn Sie 30% der Daten zufällig auswählen, führt das Löschen zu einem erheblichen Verlust der Genauigkeit der Überprüfung von 1%.
In ähnlicher Weise können 8% der Daten aus dem CIFAR-100 entfernt werden, ohne dass die Validierungsgenauigkeit abnimmt.
Diese Ergebnisse zeigen, dass die Daten für das Training neuronaler Netze erheblich redundant sind, ähnlich wie beim SVM-Training, bei dem nicht unterstützende Vektoren entfernt werden können, ohne die Modellentscheidung zu beeinflussen.
Die Folgen:Wenn wir vor Beginn des Trainings feststellen können, welche Daten unvergesslich sind, können wir Platz sparen, indem wir sie und Zeit löschen, ohne sie beim Training eines neuronalen Netzwerks zu verwenden.
Mythos 5: Eine Chargennormalisierung ist erforderlich, um sehr tiefe Restnetzwerke zu trainieren.
Lange Zeit glaubte man, dass "das Trainieren eines tiefen neuronalen Netzwerks zur direkten Optimierung nur für einen kontrollierten Zweck (zum Beispiel die logarithmische Wahrscheinlichkeit einer korrekten Klassifizierung) unter Verwendung eines Gradientenabfalls, beginnend mit zufälligen Parametern, nicht gut funktioniert".
Der seitdem aufgetauchte Haufen genialer Methoden zur zufälligen Initialisierung, Aktivierungsfunktionen, Optimierungstechniken und andere Innovationen, wie z. B. Restverbindungen, erleichterten das Training tiefer neuronaler Netze mithilfe der Gradientenabstiegsmethode.
Nach der Einführung der Batch-Normalisierung (und anderer sequentieller Normalisierungstechniken) gelang jedoch ein echter Durchbruch, bei dem die Aktivierungsgröße für jede Schicht des Netzwerks begrenzt wurde, um das Problem des Verschwindens und der explosiven Gradienten zu beseitigen.
In einer kürzlich erschienenen Arbeit,
Fixup-Initialisierung: Restliches Lernen ohne Normalisierung. Zhang et al. ICLR 2019 hat gezeigt, dass es möglich ist, ein Netzwerk mit 10.000 Schichten mit reinem SGD zu trainieren, ohne eine Normalisierung anzuwenden.

Die Autoren verglichen das verbleibende neuronale Netzwerktraining für verschiedene Tiefen auf CIFAR-10 und stellten fest, dass Standardinitialisierungsmethoden für 100 Schichten nicht funktionierten, Fixup- und Batch-Normalisierungsmethoden jedoch mit 10.000 Schichten erfolgreich waren.

Sie führten eine theoretische Analyse durch und zeigten, dass „die Gradientennormalisierung bestimmter Schichten durch die unendlich zunehmende Anzahl aus einem tiefen Netzwerk begrenzt ist“, was ein Problem explosiver Gradienten darstellt. Um dies zu verhindern, wird Foxup verwendet, dessen Schlüsselidee darin besteht, die Gewichte in m Schichten für jeden der verbleibenden Zweige L um die Häufigkeit zu skalieren, die von m und L abhängt.

Fixup half dabei, ein tiefes Restnetzwerk mit 110 Schichten auf dem CIFAR-10 mit einer hohen Lerngeschwindigkeit zu trainieren, die mit dem Verhalten eines Netzwerks ähnlicher Architektur vergleichbar ist, das mithilfe der Batch-Normalisierung trainiert wurde.
Die Autoren zeigten weiterhin ähnliche Testergebnisse mit Fixup im Netzwerk ohne Normalisierung, wobei sie mit der ImageNet-Datenbank und mit Übersetzungen aus dem Englischen ins Deutsche arbeiteten.
Mythos 6: Netzwerke mit Aufmerksamkeit sind besser als Faltungsnetzwerke.
Die Idee, dass die Mechanismen der „Aufmerksamkeit“ den Faltungs-Neuronalen Netzen überlegen sind, gewinnt in der Gemeinschaft der MO-Forscher an Popularität. In der Arbeit von
Vaswani und Kollegen wurde festgestellt, dass „die Berechnungskosten abnehmbarer Windungen gleich der Kombination einer Selbstaufmerksamkeitsschicht und einer punktweisen Vorwärtskopplungsschicht sind“.
Selbst fortschrittliche generativ-wettbewerbsfähige Netzwerke zeigen den Vorteil der Selbstaufmerksamkeit gegenüber der Standardfaltung bei der Modellierung von Abhängigkeiten über große Entfernungen.
Mitwirkende
achten bei leichten und dynamischen Konvolutionen weniger auf sie. Wu et al. ICLR 2019 wirft Zweifel an der parametrischen Effizienz und Effektivität der Selbstaufmerksamkeit bei der Modellierung von Abhängigkeiten über große Entfernungen auf und bietet neue Faltungsoptionen, die teilweise von der Selbstaufmerksamkeit inspiriert sind und hinsichtlich der Parameter effektiver sind.
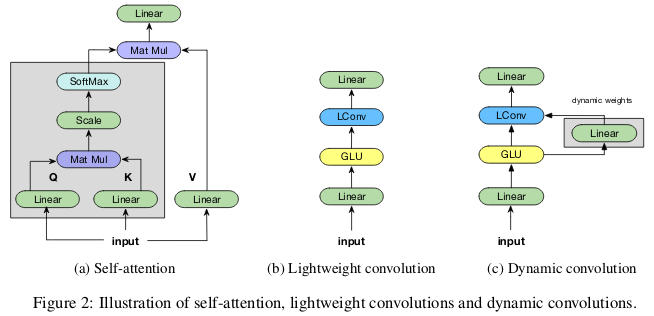
Die "leichten" Windungen sind in der Tiefe trennbar, in der Zeitdimension softmax-normalisiert, in der Kanaldimension durch das Gewicht getrennt und verwenden bei jedem Zeitschritt die gleichen Gewichte (als wiederkehrende neuronale Netze). Dynamische Windungen sind leichte Windungen, die bei jedem Zeitschritt unterschiedliche Gewichte verwenden.
Solche Tricks machen leichte und dynamische Windungen um mehrere Größenordnungen effektiver als unteilbare Standardwindungen.

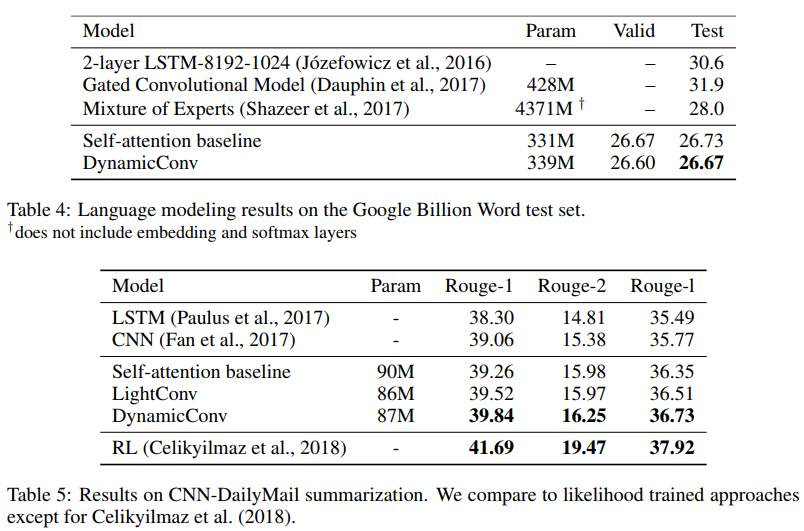
Die Autoren zeigen, dass diese neuen Faltungen selbstabsorbierenden Netzwerken bei maschineller Übersetzung, Sprachmodellierung und abstrakten Summierungsproblemen entsprechen oder diese übertreffen, wobei dieselben oder weniger Parameter verwendet werden.
Mythos 7: Signifikanzkarten - eine zuverlässige Methode zur Interpretation neuronaler Netze
Obwohl die Meinung besteht, dass neuronale Netze Black Boxes sind, gab es viele Versuche, sie zu interpretieren. Am beliebtesten sind Signifikanzkarten oder andere ähnliche Methoden, mit denen Features oder Trainingsbeispiele Wichtigkeitsbewertungen zugewiesen werden.
Es ist verlockend zu schließen, dass ein bestimmtes Bild aufgrund bestimmter Teile des Bildes, die für das neuronale Netzwerk von Bedeutung sind, auf eine bestimmte Weise klassifiziert wurde. Zur Berechnung von Signifikanzkarten gibt es verschiedene Methoden, bei denen häufig neuronale Netze in einem bestimmten Bild und die durch das Netz verlaufenden Gradienten aktiviert werden.
In der
Interpretation neuronaler Netze ist fragil. Ghorbani et al. Die Autoren von
AAAI 2019 zeigen, dass sie eine schwer fassbare Änderung im Bild einführen können, die jedoch die Signifikanzkarte verzerren wird.

Das neuronale Netzwerk bestimmt den Monarchenschmetterling nicht anhand des Musters auf seinen Flügeln, sondern aufgrund des Vorhandenseins unwichtiger grüner Blätter vor dem Hintergrund des Fotos.

Mehrdimensionale Bilder sind oft näher an Entscheidungsgrenzen, die durch tiefe neuronale Netze gebildet werden, daher ihre Empfindlichkeit gegenüber gegnerischen Angriffen. Und wenn Wettbewerbsangriffe Bilder über die Grenzen der Lösung hinaus verschieben, verschieben sie durch wettbewerbsorientierte interpretative Angriffe entlang der Grenze der Lösung, ohne das Gebiet derselben Lösung zu verlassen.
Die von den Autoren entwickelte Grundmethode ist eine Modifikation der Goodfello-Methode zur schnellen Gradientenmarkierung, die eine der ersten erfolgreichen Methoden für Wettbewerbsangriffe war. Es kann davon ausgegangen werden, dass auch andere, neuere und komplexere Angriffe für Angriffe auf die Interpretation neuronaler Netze verwendet werden können.
Die Folgen:Aufgrund der zunehmenden Verbreitung von Deep Learning in so kritischen Anwendungsbereichen wie der medizinischen Bildgebung ist es wichtig, die Interpretation von Entscheidungen, die von neuronalen Netzen getroffen werden, sorgfältig anzugehen. Obwohl es großartig wäre, wenn das Faltungsnetzwerk den Fleck auf dem MRT-Bild als bösartigen Tumor erkennen könnte, sollten diese Ergebnisse nicht als vertrauenswürdig eingestuft werden, wenn sie auf unzuverlässigen Interpretationsmethoden beruhen.