Dies ist der zweite Teil einer Artikelserie über Analysesysteme (
Link zu Teil 1 ).

Heute besteht kein Zweifel daran, dass eine genaue Datenverarbeitung und Interpretation der Ergebnisse nahezu jeder Art von Geschäft helfen kann. In dieser Hinsicht werden Analysesysteme zunehmend mit Parametern belastet, die Anzahl der Trigger und Benutzerereignisse in Anwendungen nimmt zu.
Aus diesem Grund geben Unternehmen ihren Analysten immer mehr „Rohdaten“ zur Analyse und verwandeln sie in die richtigen Entscheidungen. Die Bedeutung eines Analysesystems für ein Unternehmen sollte nicht unterschätzt werden, und das System selbst muss zuverlässig und nachhaltig sein.
Kundenanalyse
Client Analytics ist ein Dienst, den ein Unternehmen über das offizielle SDK mit seiner Website oder Anwendung verbindet, in seine eigene Codebasis integriert und Ereignisauslöser auswählt. Dieser Ansatz hat einen offensichtlichen Nachteil: Alle gesammelten Daten können aufgrund der Einschränkungen eines ausgewählten Dienstes nicht vollständig wie gewünscht verarbeitet werden. In einem System ist es beispielsweise nicht einfach, MapReduce-Aufgaben auszuführen, in einem anderen System können Sie Ihr Modell nicht ausführen. Ein weiterer Nachteil wird eine regelmäßige (beeindruckende) Rechnung für Dienstleistungen sein.
Es gibt viele Client-Analytics-Lösungen auf dem Markt, aber früher oder später sehen sich Analysten mit der Tatsache konfrontiert, dass es keinen universellen Service gibt, der für eine Aufgabe geeignet ist (während die Preise für all diese Services ständig steigen). In dieser Situation entscheiden sich Unternehmen häufig dafür, ein eigenes Analysesystem mit allen erforderlichen benutzerdefinierten Einstellungen und Funktionen zu erstellen.
Serveranalyse
Server Analytics ist ein Dienst, der intern in einem Unternehmen auf eigenen Servern und (normalerweise) aus eigener Kraft bereitgestellt werden kann. In diesem Modell werden alle Benutzerereignisse auf internen Servern gespeichert, sodass Entwickler verschiedene Datenbanken zum Speichern ausprobieren und die bequemste Architektur auswählen können. Und selbst wenn Sie für einige Aufgaben weiterhin Client-Analysen von Drittanbietern verwenden möchten, ist dies weiterhin möglich.
Serveranalysen können auf zwei Arten bereitgestellt werden. Erstens: Wählen Sie einige Open Source-Dienstprogramme aus, stellen Sie sie auf Ihren Computern bereit und entwickeln Sie Geschäftslogik.
| Vorteile | Nachteile |
| Sie können alles anpassen | Oft ist es sehr schwierig und es werden einzelne Entwickler benötigt. |
Zweitens: Nehmen Sie SaaS-Dienste (Amazon, Google, Azure), anstatt sie selbst bereitzustellen. Weitere Informationen zu SaaS finden Sie im dritten Teil.
| Vorteile | Nachteile |
| Bei mittleren Mengen mag es billiger sein, aber bei großem Wachstum wird es immer noch zu teuer | Kann nicht alle Parameter steuern |
| Die Verwaltung wird vollständig auf die Schultern des Dienstleisters übertragen | Es ist nicht immer bekannt, was sich im Service befindet (möglicherweise wird es nicht benötigt). |
So sammeln Sie Serveranalysen
Wenn wir keine Client-Analysen mehr verwenden und keine eigenen zusammenstellen möchten, müssen wir zunächst über die Architektur des neuen Systems nachdenken. Im Folgenden werde ich Ihnen Schritt für Schritt erklären, was zu beachten ist, warum die einzelnen Schritte erforderlich sind und welche Tools Sie verwenden können.
1. Datenerfassung
Genau wie bei der Kundenanalyse wählen Unternehmensanalysten zunächst die Arten von Ereignissen aus, die sie in Zukunft untersuchen möchten, und sammeln sie in einer Liste. Normalerweise finden diese Ereignisse in einer bestimmten Reihenfolge statt, die als „Ereignismuster“ bezeichnet wird.
Stellen Sie sich als nächstes vor, dass eine mobile Anwendung (Website) reguläre Benutzer (Geräte) und viele Server hat. Um Ereignisse sicher von Geräten auf Server zu übertragen, wird eine Zwischenschicht benötigt. Abhängig von der Architektur können mehrere unterschiedliche Ereigniswarteschlangen auftreten.
Apache Kafka ist eine
Pub / Sub-Warteschlange , die als Warteschlange zum Sammeln von Ereignissen verwendet wird.
Laut einem Beitrag über Kvor aus dem Jahr 2014 hat der Schöpfer von Apache Kafka beschlossen, die Software nach Franz Kafka zu benennen, weil „es sich um ein für die Aufnahme optimiertes System handelt“ und weil er Kafkas Werke liebte. - Wikipedia
In unserem Beispiel gibt es viele Datenproduzenten und deren Verbraucher (Geräte und Server), und Kafka hilft dabei, sie miteinander zu verbinden. Die Verbraucher werden in den nächsten Schritten ausführlicher beschrieben, wo sie die Hauptakteure sein werden. Jetzt betrachten wir nur Datenproduzenten (Ereignisse).
Kafka kapselt die Konzepte von Warteschlange und Partition. Insbesondere ist es besser, an anderer Stelle darüber zu lesen (z. B. in der
Dokumentation ). Stellen Sie sich vor, eine mobile Anwendung wird für zwei verschiedene Betriebssysteme gestartet, ohne auf Details einzugehen. Anschließend erstellt jede Version einen eigenen Ereignisstrom. Produzenten senden Events an Kafka, sie werden in einer geeigneten Warteschlange aufgezeichnet.
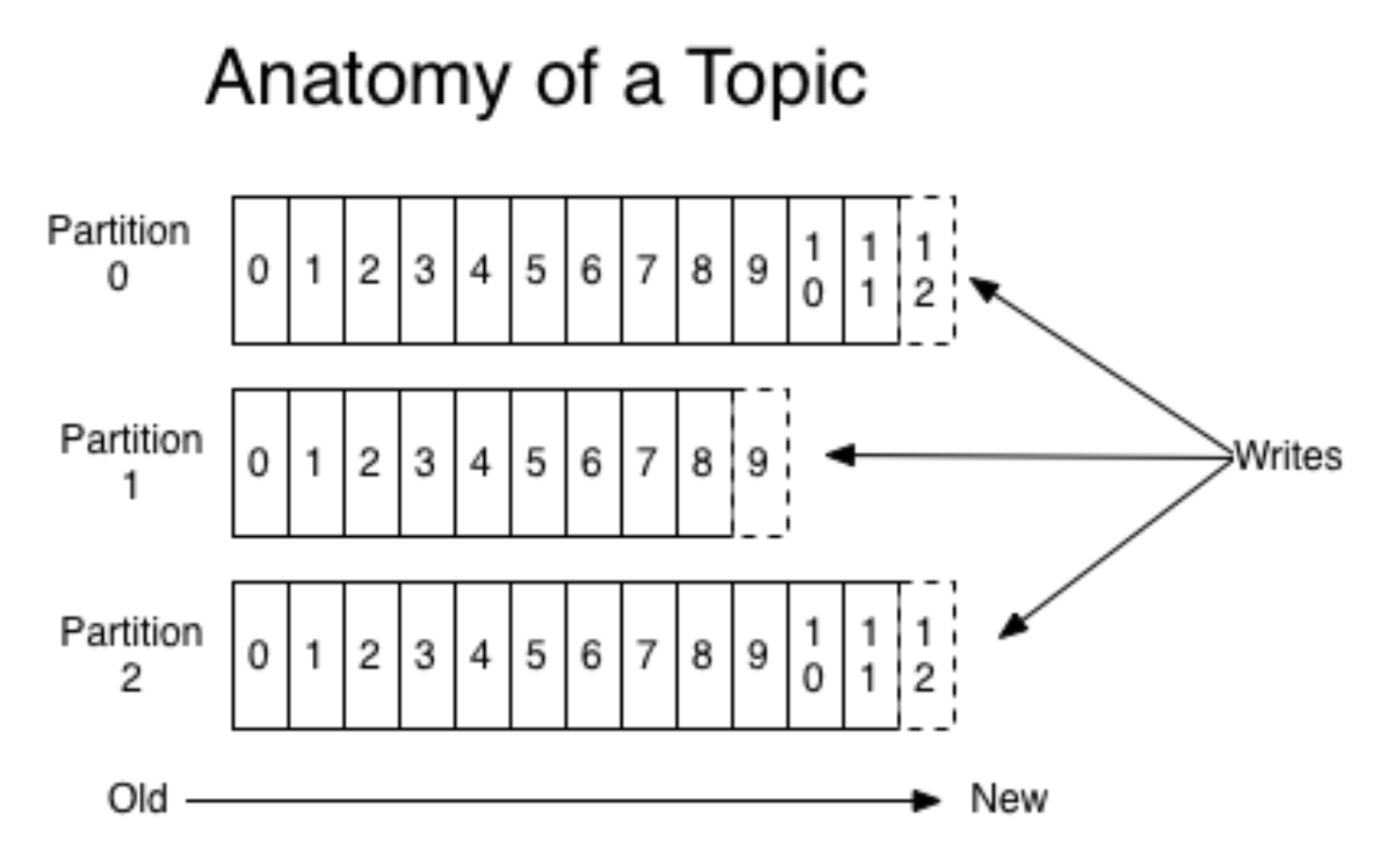
(Bild
von hier )
Gleichzeitig können Sie mit Kafka Teile lesen und den Ablauf von Ereignissen mit Mini-Fledermäusen verarbeiten. Kafka ist ein sehr praktisches Tool, das sich gut an wachsende Anforderungen anpassen lässt (z. B. durch Geolokalisierung von Ereignissen).
Normalerweise reicht eine Scherbe aus, aber aufgrund der Skalierung wird es (wie immer) schwieriger. Wahrscheinlich wird niemand nur einen physischen Shard in der Produktion verwenden wollen, da die Architektur fehlertolerant sein muss. Neben Kafka gibt es noch eine weitere bekannte Lösung - RabbitMQ. Wir haben es in der Produktion nicht als Warteschlange für Ereignisanalysen verwendet (wenn Sie eine solche Erfahrung haben, teilen Sie uns dies in den Kommentaren mit!). Sie verwendeten jedoch AWS Kinesis.
Bevor wir mit dem nächsten Schritt fortfahren, müssen wir eine weitere zusätzliche Ebene des Systems erwähnen - die Speicherung von Rohprotokollen. Dies ist keine erforderliche Ebene, aber es ist nützlich, wenn etwas schief geht und die Warteschlangen der Ereignisse in Kafka zurückgesetzt werden. Die Speicherung von Rohprotokollen erfordert keine komplizierte und teure Lösung. Sie können sie einfach irgendwo in der richtigen Reihenfolge (auch auf einer Festplatte) aufzeichnen.

2. Verarbeitung von Ereignisströmen
Nachdem wir alle Ereignisse vorbereitet und in geeignete Warteschlangen gestellt haben, fahren wir mit dem Verarbeitungsschritt fort. Hier werde ich über die beiden häufigsten Verarbeitungsoptionen sprechen.
Die erste Option besteht darin, Spark Streaming auf einem Apache-System zu aktivieren. Alle Apache-Produkte leben in HDFS, einem sicheren Dateireplikations-Dateisystem. Spark Streaming ist ein benutzerfreundliches Tool, das Streaming-Daten verarbeitet und gut skaliert. Die Wartung kann jedoch etwas schwierig sein.
Eine andere Möglichkeit besteht darin, einen eigenen Ereignishandler zu erstellen. Dazu müssen Sie beispielsweise eine Python-Anwendung schreiben, im Docker erstellen und die Kafka-Warteschlange abonnieren. Wenn Trigger auf den Handlern im Docker eintreffen, wird die Verarbeitung gestartet. Bei dieser Methode müssen Sie ständig Anwendungen ausführen.
Angenommen, wir haben eine der oben beschriebenen Optionen ausgewählt und fahren mit der Verarbeitung selbst fort. Prozessoren sollten zunächst die Gültigkeit der Daten überprüfen, Müll und "defekte" Ereignisse filtern. Zur Validierung verwenden wir normalerweise
Cerberus . Danach können Sie eine Datenzuordnung vornehmen: Daten aus verschiedenen Quellen werden normalisiert und standardisiert, um dem allgemeinen Etikett hinzugefügt zu werden.
3. Datenbank
Der dritte Schritt besteht darin, normalisierte Ereignisse aufrechtzuerhalten. Wenn wir mit einem vorgefertigten Analysesystem arbeiten, müssen wir uns häufig mit ihnen in Verbindung setzen. Daher ist es wichtig, eine geeignete Datenbank auszuwählen.
Wenn die Daten gut in ein festes Schema
passen , können Sie
Clickhouse oder eine andere
Spaltendatenbank auswählen. Aggregationen funktionieren also sehr schnell. Der Nachteil ist, dass das Schema starr festgelegt ist und daher das Falten beliebiger Objekte ohne Verfeinerung fehlschlägt (z. B. wenn ein nicht standardmäßiges Ereignis auftritt). Aber man kann sehr schnell zählen.
Für unstrukturierte Daten können Sie NoSQL verwenden, z. B.
Apache Cassandra . Es funktioniert auf HDFS, ist gut repliziert, Sie können viele Instanzen auslösen, fehlertolerant.
Sie können etwas Einfacheres aufnehmen, zum Beispiel
MongoDB . Es ist ziemlich langsam und für kleine Mengen. Das Plus ist aber, dass es sehr einfach und daher zum Starten geeignet ist.
4. Aggregationen
Nachdem wir alle Ereignisse sorgfältig gespeichert haben, möchten wir alle wichtigen Informationen aus dem Stapel sammeln und die Datenbank aktualisieren. Weltweit möchten wir relevante Dashboards und Metriken erhalten. Zum Beispiel von Ereignissen, um ein Benutzerprofil zu sammeln und das Verhalten irgendwie zu messen. Ereignisse werden aggregiert, gesammelt und erneut gespeichert (bereits in Benutzertabellen). Gleichzeitig können Sie das System so aufbauen, dass Sie auch einen Filter mit dem Aggregator-Koordinator verbinden: Sammeln Sie Benutzer nur von einem bestimmten Ereignistyp.
Wenn danach jemand im Team nur Analysen auf hoher Ebene benötigt, können Sie externe Analysesysteme anschließen. Sie können Mixpanel wieder einnehmen. Da es aber recht teuer ist, werden nicht alle Benutzerereignisse dorthin gesendet, sondern nur das, was benötigt wird. Dazu müssen Sie einen Koordinator erstellen, der einige Rohereignisse oder etwas, das wir zuvor selbst aggregiert haben, an externe Systeme, APIs oder Werbeplattformen überträgt.
5. Frontend
Sie müssen das Frontend mit dem erstellten System verbinden. Ein gutes Beispiel ist der
Redash- Service, eine GUI für Datenbanken, mit deren Hilfe Panels erstellt werden können. Wie die Interaktion funktioniert:
- Der Benutzer führt eine SQL-Abfrage durch.
- Als Antwort erhält eine Tablette.
- Für sie erstellt sie eine 'neue Visualisierung' und erhält einen schönen Zeitplan, der bereits für sich selbst gespeichert werden kann.
Visualisierungen im Dienst werden automatisch aktualisiert. Sie können Ihre Überwachung konfigurieren und verfolgen. Redash ist kostenlos, wenn Sie selbst gehostet werden und wie SaaS 50 US-Dollar pro Monat kostet.

Fazit
Nachdem Sie alle oben genannten Schritte ausgeführt haben, erstellen Sie Ihre Serveranalyse. Bitte beachten Sie, dass dies nicht so einfach ist wie das einfache Verbinden von Client-Analysen, da alles unabhängig konfiguriert werden muss. Bevor Sie Ihr eigenes System erstellen, sollten Sie daher die Notwendigkeit eines seriösen Analysesystems mit den Ressourcen vergleichen, die Sie bereit sind, diesem System zu widmen.
Wenn Sie alles berechnet haben und festgestellt haben, dass die Kosten zu hoch sind, werde ich im nächsten Teil darüber sprechen, wie Sie eine billigere Version der Serveranalyse erstellen können.
Danke fürs Lesen! Ich freue mich über Fragen in den Kommentaren.