
Hallo allerseits! Mein Name ist Sergey Kostanbaev, an der Börse entwickle ich den Kern des Handelssystems.
Wenn die New Yorker Börse in Hollywood-Filmen gezeigt wird, sieht es immer so aus: Menschenmassen schreien etwas, winken Papier, es herrscht völliges Chaos. Wir hatten dies nie an der Moskauer Börse, da der Handel fast von Anfang an elektronisch abgewickelt wurde und auf zwei Hauptplattformen basiert - Spectra (Derivatemarkt) und ASTS (Währungs-, Aktien- und Geldmärkte). Und heute möchte ich über die Entwicklung der Architektur des ASTS-Handels- und Clearingsystems sprechen, über verschiedene Lösungen und Erkenntnisse. Die Geschichte wird lang sein, also musste ich sie in zwei Teile teilen.
Wir sind eine der wenigen Börsen der Welt, die mit Vermögenswerten aller Klassen handeln und eine umfassende Palette von Börsendiensten anbieten. Zum Beispiel haben wir im vergangenen Jahr den zweiten Platz in Bezug auf das Handelsvolumen von Anleihen weltweit belegt, den 25. Platz unter allen Börsen und den 13. Platz nach Kapitalisierung unter den öffentlichen Börsen.
Für professionelle Bieter sind Parameter wie Reaktionszeit, Stabilität der Zeitverteilung (Jitter) und Zuverlässigkeit des gesamten Komplexes von entscheidender Bedeutung. Derzeit verarbeiten wir zig Millionen Transaktionen pro Tag. Die Verarbeitung jeder Transaktion durch den Systemkern dauert mehrere zehn Sekunden. Natürlich ist bei Mobilfunkbetreibern zu Neujahr oder bei Suchmaschinen die Auslastung selbst höher als bei uns, aber in Bezug auf die Auslastung, gepaart mit den oben genannten Merkmalen, können nur wenige mit uns vergleichen, wie es mir scheint. Gleichzeitig ist es für uns wichtig, dass das System keine Sekunde langsamer wird, absolut stabil arbeitet und alle Benutzer unter gleichen Bedingungen sind.
Ein bisschen Geschichte
1994 wurde das australische ASTS-System an der Moskauer Interbank Currency Exchange (MICEX) eingeführt, und von diesem Moment an können Sie die russische Geschichte des elektronischen Handels zählen. 1998 wurde die Architektur der Börse für die Einführung des Internethandels modernisiert. Seitdem gewinnt die Geschwindigkeit der Einführung neuer Lösungen und architektonischer Änderungen in allen Systemen und Subsystemen nur noch an Dynamik.
In jenen Jahren arbeitete das Austauschsystem mit Hi-End-Hardware - den hochzuverlässigen HP Superdome 9000-Servern (basierend auf der
PA-RISC-Architektur ), die absolut alles duplizierten: die E / A-Subsysteme, das Netzwerk, den RAM (tatsächlich gab es ein RAID-Array aus dem RAM ), Prozessoren (Hot-Swapping unterstützt). Es war möglich, eine beliebige Komponente des Servers zu ändern, ohne den Computer anzuhalten. Wir haben uns auf diese Geräte verlassen und sie als nahezu störungsfrei angesehen. Das Betriebssystem war Unix-ähnliches HP UX.
Aber seit ungefähr 2010 ist ein Phänomen wie der Hochfrequenzhandel (HFT) oder der Hochfrequenzhandel, einfach ausgedrückt, Austauschroboter, aufgetreten. In nur 2,5 Jahren hat sich die Auslastung unserer Server um das 140-fache erhöht.
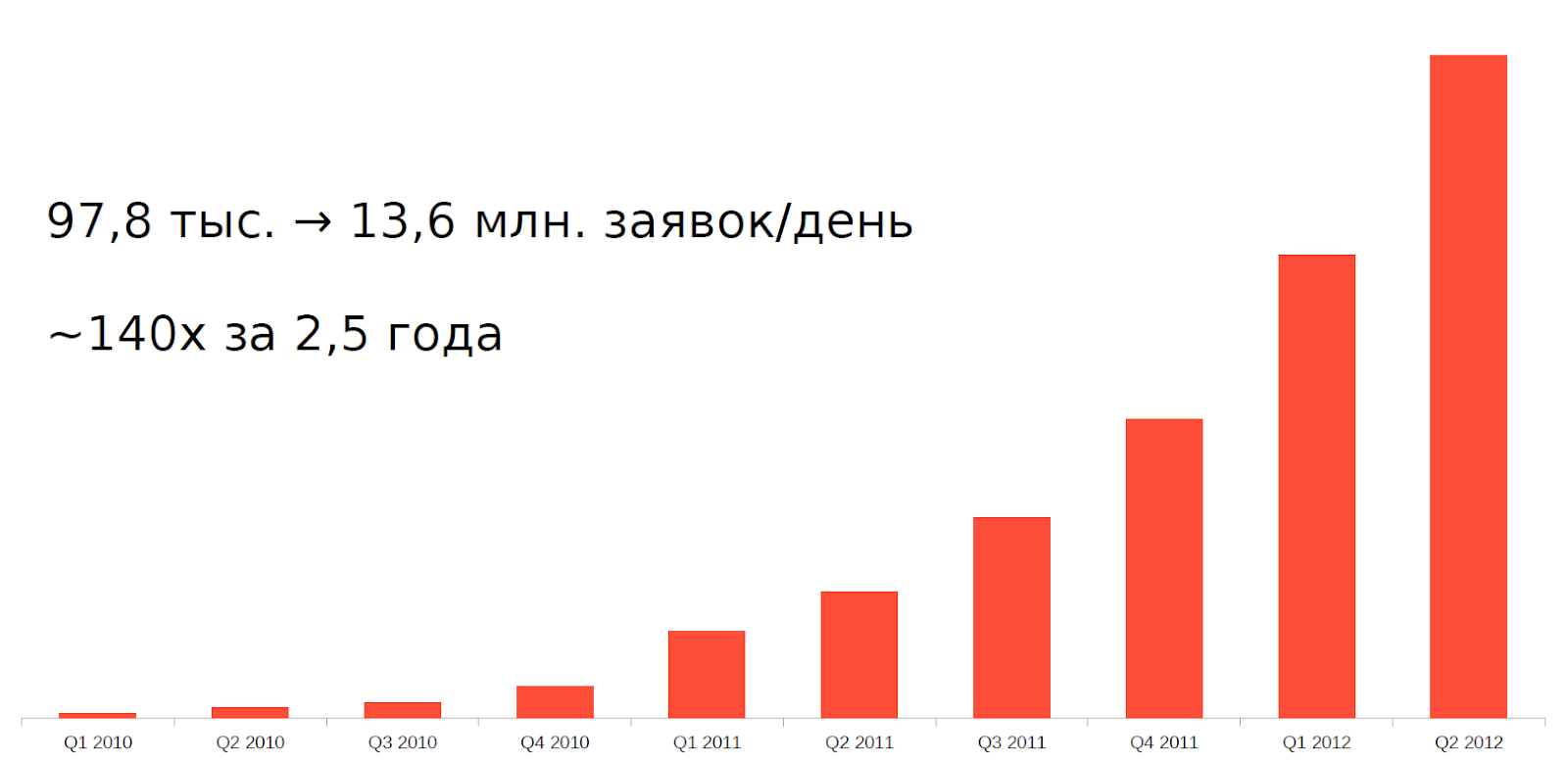
Es war unmöglich, einer solchen Belastung mit der alten Architektur und Ausrüstung standzuhalten. Es war notwendig, sich irgendwie anzupassen.
Starten Sie
Anfragen an das Austauschsystem können in zwei Typen unterteilt werden:
- Transaktionen Wenn Sie Dollar, Aktien oder etwas anderes kaufen möchten, senden Sie eine Transaktion an das Handelssystem und erhalten Sie eine Antwort über den Erfolg.
- Informationsanfragen. Wenn Sie den aktuellen Preis erfahren möchten, sehen Sie sich das Auftragsbuch oder die Indizes an und senden Sie dann Informationsanfragen.
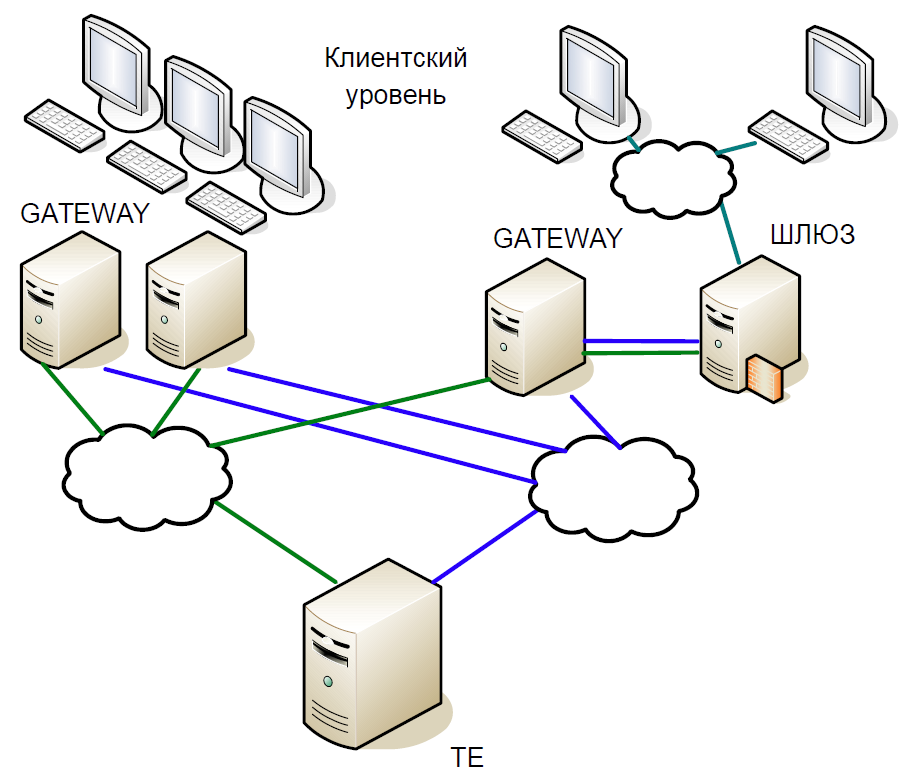
Schematisch kann der Kern des Systems in drei Ebenen unterteilt werden:
- Die Kundenebene, auf der Makler und Kunden arbeiten. Alle interagieren mit Zugriffsservern.
- Zugriffsserver (Gateways) sind Caching-Server, die alle Informationsanforderungen lokal verarbeiten. Möchten Sie wissen, zu welchem Preis Sberbank-Aktien jetzt gehandelt werden? Die Anfrage geht an den Zugriffsserver.
- Wenn Sie jedoch Aktien kaufen möchten, befindet sich die Anfrage bereits auf dem zentralen Server (Trade Engine). Für jeden Markttyp gibt es einen solchen Server, sie spielen eine entscheidende Rolle, und wir haben dieses System für sie entwickelt.
Der Kern des Handelssystems ist eine knifflige In-Memory-Datenbank, in der alle Transaktionen Börsentransaktionen sind. Die Basis wurde in C geschrieben, von den externen Abhängigkeiten gab es nur die libc-Bibliothek und es gab keine dynamische Speicherzuordnung. Um die Verarbeitungszeit zu verkürzen, beginnt das System mit einem statischen Satz von Arrays und einer statischen Verlagerung von Daten: Zuerst werden alle Daten für den aktuellen Tag in den Speicher geladen, und dann werden keine Festplattenzugriffe ausgeführt. Alle Arbeiten werden nur im Speicher ausgeführt. Beim Systemstart sind alle Referenzdaten bereits sortiert, sodass die Suche sehr effizient funktioniert und zur Laufzeit wenig Zeit in Anspruch nimmt. Alle Tabellen werden mit aufdringlichen Listen und Bäumen für dynamische Datenstrukturen erstellt, sodass zur Laufzeit keine Speicherzuweisung erforderlich ist.
Lassen Sie uns kurz auf die Geschichte der Entwicklung unseres Handels- und Clearingsystems eingehen.
Die erste Version der Architektur des Handels- und Clearingsystems basierte auf der sogenannten Unix-Interaktion: Shared Memory, Semaphoren und Warteschlangen wurden verwendet, und jeder Prozess bestand aus einem Thread. Dieser Ansatz war Anfang der neunziger Jahre weit verbreitet.
Die erste Version des Systems enthielt zwei Gateway-Ebenen und einen zentralen Server des Handelssystems. Das Arbeitsschema war wie folgt:
- Der Client sendet eine Anforderung, die das Gateway erreicht. Er überprüft die Gültigkeit des Formats (aber nicht der Daten selbst) und lehnt die falsche Transaktion ab.
- Wenn eine Informationsanforderung gesendet wurde, wird sie lokal ausgeführt. Wenn es sich um eine Transaktion handelt, wird sie an den zentralen Server umgeleitet.
- Dann verarbeitet die Handelsmaschine die Transaktion, ändert den lokalen Speicher und sendet eine Antwort auf die Transaktion und auf sich selbst - auf die Replikation unter Verwendung eines separaten Replikationsmechanismus.
- Das Gateway empfängt eine Antwort vom zentralen Knoten und leitet sie an den Client weiter.
- Nach einer Weile empfängt das Gateway die Transaktion mithilfe des Replikationsmechanismus und führt sie diesmal lokal aus. Dabei werden die Datenstrukturen so geändert, dass in den folgenden Informationsanforderungen die tatsächlichen Daten angezeigt werden.
Tatsächlich wird hier das Replikationsmodell beschrieben, bei dem Gateway die im Handelssystem ausgeführten Aktionen vollständig wiederholte. Ein separater Replikationskanal stellte dieselbe Transaktionsausführungsreihenfolge auf mehreren Zugriffsknoten bereit.
Da der Code Single-Threaded war, wurde ein klassisches Schema mit gegabelten Prozessen verwendet, um viele Clients zu bedienen. Das Erstellen eines Fork für die gesamte Datenbank war jedoch sehr teuer. Daher wurden einfache Serviceprozesse verwendet, die Pakete aus TCP-Sitzungen sammelten und in eine Warteschlange (SystemV Message Queue) überführten. Gateway und Trade Engine arbeiteten nur mit dieser Warteschlange und nahmen von dort Transaktionen zur Ausführung entgegen. Es war bereits unmöglich, eine Antwort darauf zu senden, da nicht klar ist, welcher Serviceprozess sie lesen soll. Wir haben also auf einen Trick zurückgegriffen: Jeder gegabelte Prozess hat eine Antwortwarteschlange für sich selbst erstellt, und als eine Anforderung in die eingehende Warteschlange einging, wurde ihr sofort ein Tag für die Antwortwarteschlange hinzugefügt.
Das ständige Kopieren großer Datenmengen aus der Warteschlange in die Warteschlange verursachte Probleme, insbesondere bei Informationsanforderungen. Daher haben wir einen anderen Trick ausgenutzt: Zusätzlich zur Antwortwarteschlange hat jeder Prozess auch einen gemeinsam genutzten Speicher (SystemV Shared Memory) erstellt. Die Pakete selbst wurden darin abgelegt, und nur das Tag wurde in der Warteschlange gespeichert, sodass Sie das Quellpaket finden können. Dies half, Daten im Prozessor-Cache zu speichern.
SystemV IPC enthält Dienstprogramme zum Anzeigen des Status von Warteschlangen-, Speicher- und Semaphorobjekten. Wir haben dies aktiv genutzt, um zu verstehen, was zu einem bestimmten Zeitpunkt im System geschieht, wo sich Pakete ansammeln, was blockiert wird usw.
Erste Modernisierung
Zunächst haben wir das Single-Process-Gateway losgeworden. Der wesentliche Nachteil bestand darin, dass entweder eine Replikationstransaktion oder eine Informationsanforderung von einem Client verarbeitet werden konnte. Und mit zunehmender Auslastung verarbeitet das Gateway Anforderungen länger und kann den Replikationsdatenstrom nicht verarbeiten. Wenn der Client eine Transaktion gesendet hat, müssen Sie außerdem nur deren Gültigkeit überprüfen und weiterleiten. Aus diesem Grund haben wir einen Gateway-Prozess durch viele Komponenten ersetzt, die parallel arbeiten können: Multithread-Informationen und Transaktionsprozesse, die unabhängig voneinander mit einem gemeinsamen Speicherbereich mithilfe der RW-Sperre arbeiten. Gleichzeitig haben wir Planungs- und Replikationsprozesse eingeführt.
Die Auswirkungen des Hochfrequenzhandels
Die obige Version der Architektur dauerte bis 2010. Inzwischen waren wir mit der Leistung der HP Superdome-Server nicht mehr zufrieden. Darüber hinaus ist die PA-RISC-Architektur tatsächlich gestorben, der Anbieter hat keine wesentlichen Aktualisierungen angeboten. Infolgedessen haben wir begonnen, von HP UX / PA RISC auf Linux / x86 umzusteigen. Der Übergang begann mit der Anpassung der Zugangsserver.
Warum mussten wir die Architektur erneut ändern? Tatsache ist, dass der Hochfrequenzhandel das Lastprofil des Systemkerns erheblich verändert hat.
Angenommen, wir haben eine kleine Transaktion, die zu einer erheblichen Preisänderung geführt hat - jemand hat eine halbe Milliarde Dollar gekauft. Nach einigen Millisekunden bemerken dies alle Marktteilnehmer und beginnen mit einer Korrektur. Natürlich stehen Anfragen in einer riesigen Warteschlange, die das System für lange Zeit harken wird.

In diesem Intervall von 50 ms beträgt die durchschnittliche Geschwindigkeit etwa 16.000 Transaktionen pro Sekunde. Wenn Sie das Fenster auf 20 ms reduzieren, erhalten wir eine durchschnittliche Geschwindigkeit von 90.000 Transaktionen pro Sekunde, und in der Spitze gibt es 200.000 Transaktionen. Mit anderen Worten, die Last ist instabil mit scharfen Stößen. Und die Anforderungswarteschlange sollte immer schnell verarbeitet werden.
Aber warum gibt es überhaupt eine Warteschlange? In unserem Beispiel haben viele Benutzer eine Preisänderung festgestellt und die entsprechenden Transaktionen gesendet. Diese kommen zu Gateway, er serialisiert sie, legt eine bestimmte Reihenfolge fest und sendet sie an das Netzwerk. Router mischen Pakete und leiten sie weiter. Wessen Paket früher kam, diese Transaktion "gewann". Infolgedessen stellten Börsenkunden fest, dass die Wahrscheinlichkeit einer schnellen Verarbeitung steigt, wenn dieselbe Transaktion von mehreren Gateways gesendet wurde. Bald begannen Austauschroboter, Gateway mit Anfragen zu bombardieren, und es kam zu einer Lawine von Transaktionen.

Eine neue Evolutionsrunde
Nach umfangreichen Tests und Recherchen haben wir auf den Echtzeitkern des Betriebssystems umgestellt. Zu diesem Zweck entschieden sie sich für RedHat Enterprise MRG Linux, wo MRG für Messaging Real-Time Grid steht. Der Vorteil von Echtzeit-Patches besteht darin, dass sie das System für die schnellstmögliche Ausführung optimieren: Alle Prozesse sind in einer FIFO-Warteschlange angeordnet, Sie können Kernel isolieren, keine Drops, alle Transaktionen werden in strikter Reihenfolge verarbeitet.
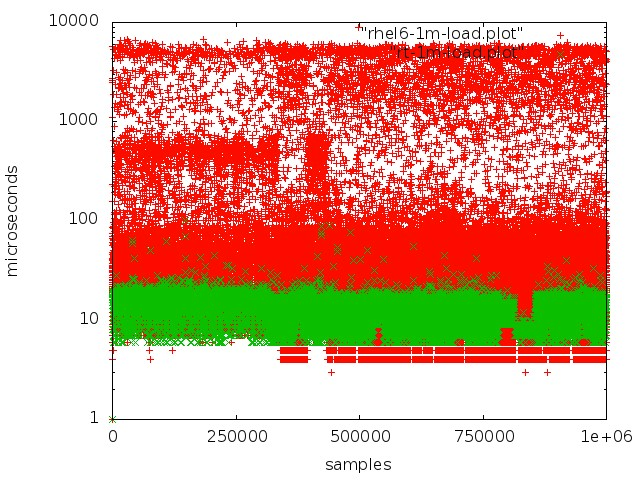 Rot - Arbeiten Sie mit einer Warteschlange in einem normalen Kernel, Grün - Arbeiten Sie in einem Echtzeitkernel.
Rot - Arbeiten Sie mit einer Warteschlange in einem normalen Kernel, Grün - Arbeiten Sie in einem Echtzeitkernel.Das Erreichen einer geringen Latenz auf normalen Servern ist jedoch nicht so einfach:
- Der SMI-Modus, der in der x86-Architektur im Mittelpunkt der Arbeit mit wichtigen Peripheriegeräten steht, stört stark. Die Verarbeitung verschiedener Hardwareereignisse und die Verwaltung von Komponenten und Geräten erfolgt durch die Firmware im sogenannten transparenten SMI-Modus, in dem das Betriebssystem überhaupt nicht sieht, was die Firmware tut. In der Regel bieten alle großen Anbieter spezielle Erweiterungen für Firmware-Server an, mit denen sich die SMI-Verarbeitung reduzieren lässt.
- Es sollte keine dynamische Steuerung der Prozessorfrequenz erfolgen, dies führt zu zusätzlichen Ausfallzeiten.
- Wenn das Dateisystemprotokoll zurückgesetzt wird, treten im Kernel bestimmte Prozesse auf, die zu unvorhersehbaren Verzögerungen führen.
- Sie müssen auf Dinge wie CPU-Affinität, Interrupt-Affinität, NUMA achten.
Ich muss sagen, dass das Thema der Konfiguration der Linux-Hardware und des Kernels für die Echtzeitverarbeitung einen separaten Artikel verdient. Wir haben viel Zeit mit Experimenten und Forschung verbracht, bevor wir ein gutes Ergebnis erzielt haben.
Beim Wechsel von PA-RISC-Servern zu x86 mussten wir den Systemcode praktisch nicht viel ändern, sondern nur anpassen und neu konfigurieren. Gleichzeitig wurden mehrere Fehler behoben. Zum Beispiel zeigten sich schnell die Konsequenzen, dass PA RISC ein Big-Endian-System und x86 ein Little-Endian-System war: Beispielsweise wurden Daten nicht korrekt gelesen. Ein schwierigerer Fehler war, dass PA RISC
sequentiellen konsistenten Speicherzugriff verwendet, während x86 Lesevorgänge neu anordnen kann, sodass Code, der auf einer Plattform absolut gültig ist, auf einer anderen Plattform nicht mehr funktioniert.
Nach dem Wechsel zu x86 stieg die Produktivität fast dreimal an, die durchschnittliche Transaktionsverarbeitungszeit verringerte sich auf 60 μs.
Schauen wir uns nun genauer an, welche wichtigen Änderungen an der Systemarchitektur vorgenommen wurden.
Heißes Standby-Epos
Bei Commodity-Servern war uns bewusst, dass diese weniger zuverlässig sind. Bei der Erstellung einer neuen Architektur haben wir daher a priori die Möglichkeit eines Ausfalls eines oder mehrerer Knoten angenommen. Daher brauchten wir ein Hot-Standby-System, das sehr schnell auf Backup-Maschinen umschalten kann.
Darüber hinaus gab es weitere Anforderungen:
- In keinem Fall sollten Sie verarbeitete Transaktionen verlieren.
- Das System muss für unsere Infrastruktur absolut transparent sein.
- Clients sollten keine Verbindungsunterbrechungen sehen.
- Die Reservierung sollte keine wesentliche Verzögerung mit sich bringen, da dies ein kritischer Faktor für den Umtausch ist.
Bei der Erstellung eines Hot-Standby-Systems wurden solche Szenarien nicht als doppelte Fehler betrachtet (z. B. funktionierte das Netzwerk auf einem Server nicht mehr und der Hauptserver blieb hängen). hat die Möglichkeit von Fehlern in der Software nicht berücksichtigt, da diese beim Testen erkannt werden; und berücksichtigte nicht die Fehlfunktion von Eisen.
Als Ergebnis kamen wir zu folgendem Schema:
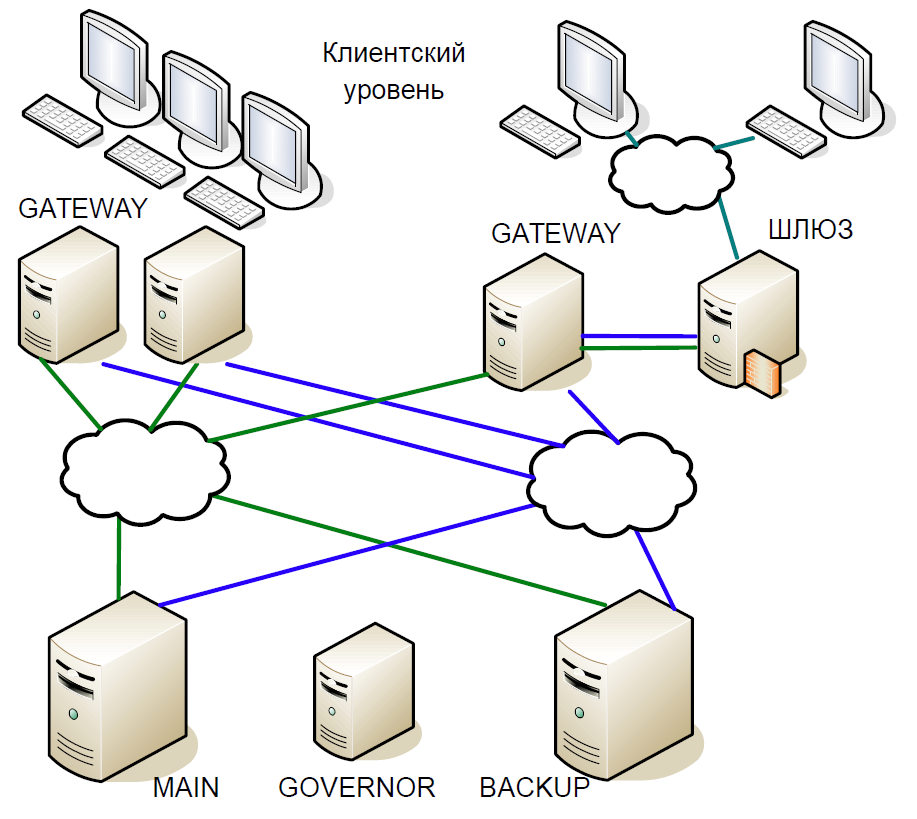
- Der Hauptserver interagierte direkt mit Gateway-Servern.
- Alle auf dem Hauptserver empfangenen Transaktionen wurden sofort über einen separaten Kanal auf den Sicherungsserver repliziert. Der Schiedsrichter (Gouverneur) koordinierte den Wechsel, wenn Probleme auftraten.
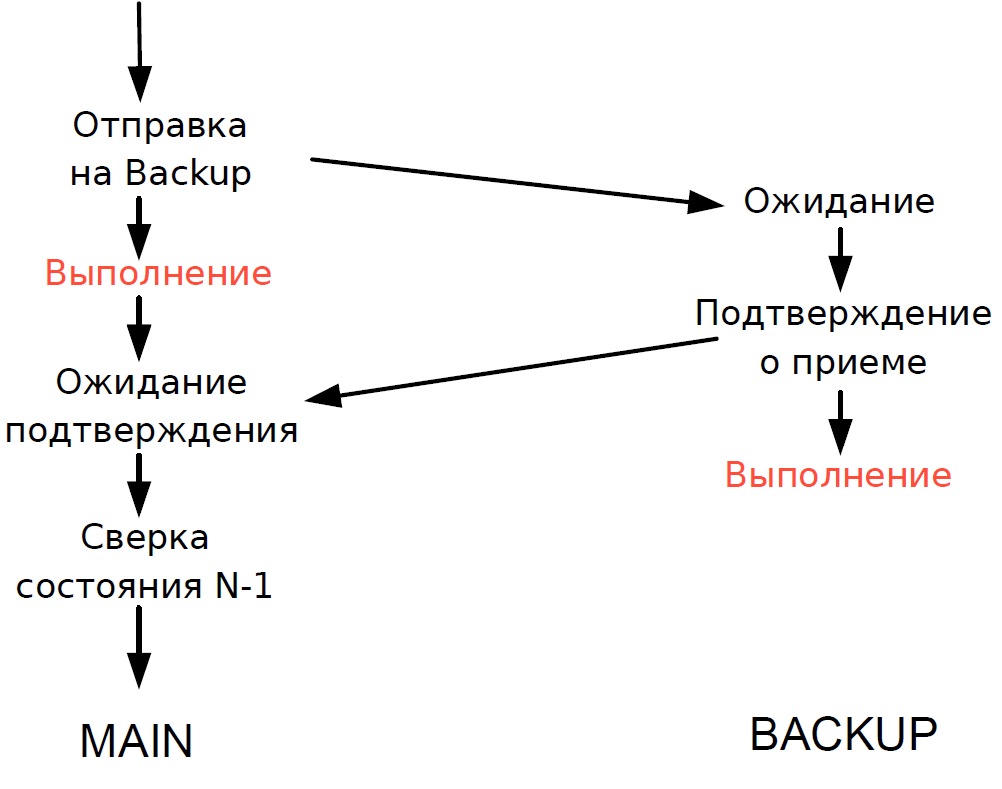
- Der Hauptserver verarbeitete jede Transaktion und wartete auf die Bestätigung vom Sicherungsserver. Um die Verzögerung zu minimieren, haben wir uns geweigert, auf den Abschluss der Transaktion auf dem Sicherungsserver zu warten. Da die Dauer der Transaktion über das Netzwerk mit der Dauer der Transaktion vergleichbar war, wurde keine zusätzliche Verzögerung hinzugefügt.
- Wir konnten den Verarbeitungsstatus des Haupt- und Sicherungsservers nur für die vorherige Transaktion überprüfen, und der Verarbeitungsstatus der aktuellen Transaktion war unbekannt. Da hier immer noch Single-Thread-Prozesse verwendet wurden, würde das Warten auf eine Antwort von Backup den gesamten Verarbeitungsablauf verlangsamen. Daher haben wir einen vernünftigen Kompromiss eingegangen: Wir haben das Ergebnis der vorherigen Transaktion überprüft.

Das Schema funktionierte wie folgt.
Angenommen, der Hauptserver reagiert nicht mehr, aber das Gateway kommuniziert weiter. Auf dem Sicherungsserver wird ein Timeout ausgelöst, es wird an Governor weitergeleitet, und er weist ihm die Rolle des Hauptservers zu, und alle Gateways wechseln zum neuen Hauptserver.
Wenn der Hauptserver wieder in Betrieb ist, wird auch ein internes Timeout ausgelöst, da seit einiger Zeit keine Anrufe mehr vom Gateway an den Server eingegangen sind. Dann wendet er sich auch an den Gouverneur und schließt ihn vom Plan aus. Infolgedessen arbeitet die Börse bis zum Ende des Handelszeitraums mit einem Server. Da die Wahrscheinlichkeit eines Serverabsturzes eher gering ist, wurde ein solches Schema als durchaus akzeptabel angesehen, enthielt keine komplexe Logik und war leicht zu testen.
Fortsetzung folgt.