
Dies ist die Fortsetzung einer langen Geschichte über unseren schwierigen Weg zur Schaffung eines leistungsstarken, hoch ausgelasteten Systems, das den Betrieb der Börse sicherstellt.
Der erste Teil ist hier .
Geheimnisvoller Fehler
Nach zahlreichen Tests wurde das aktualisierte Handels- und Clearingsystem in Betrieb genommen, und wir stießen auf einen Fehler, über den es genau richtig war, eine mystische Detektivgeschichte zu schreiben.
Kurz nach dem Start auf dem Hauptserver wurde eine der Transaktionen mit einem Fehler verarbeitet. Gleichzeitig war auf dem Backup-Server alles in Ordnung. Es stellte sich heraus, dass eine einfache mathematische Operation zur Berechnung des Exponenten auf dem Hauptserver ein negatives Ergebnis eines gültigen Arguments ergab! Die Umfragen wurden fortgesetzt, und im SSE2-Register fanden sie einen Unterschied in einem Bit, der für die Rundung bei der Arbeit mit Gleitkommazahlen verantwortlich ist.
Sie haben ein einfaches Testdienstprogramm zur Berechnung des Exponenten mit gesetztem Rundungsbit geschrieben. Es stellte sich heraus, dass in der von uns verwendeten Version von RedHat Linux ein Fehler beim Arbeiten mit einer mathematischen Funktion auftrat, als das unglückliche Bit eingefügt wurde. Wir haben dies RedHat gemeldet, nach einer Weile haben wir einen Patch von ihnen erhalten und ihn gerollt. Der Fehler trat nicht mehr auf, aber es war unklar, woher dieses Bit kam. Die
fesetround Funktion von C war dafür verantwortlich. Wir haben unseren Code sorgfältig auf der Suche nach dem angeblichen Fehler analysiert: Alle möglichen Situationen überprüft; berücksichtigte alle Funktionen, die Rundung verwendeten; hat versucht, eine fehlgeschlagene Sitzung abzuspielen; verwendete verschiedene Compiler mit verschiedenen Optionen; verwendete statische und dynamische Analyse.
Die Fehlerursache konnte nicht gefunden werden.
Dann begannen sie, die Hardware zu überprüfen: Sie führten Lasttests von Prozessoren durch; überprüfte den RAM; Es wurden sogar Tests für ein sehr unwahrscheinliches Szenario eines Mehrbitfehlers in einer Zelle durchgeführt. Ohne Erfolg.
Am Ende entschieden sie sich für Theorien aus der Welt der Hochenergiephysik: Einige hochenergetische Teilchen flogen in unser Rechenzentrum, durchbrachen die Wand des Gehäuses, trafen den Prozessor und ließen den Trigger-Latch im selben Bit stecken. Diese absurde Theorie wurde "Neutrino" genannt. Wenn Sie weit von der Elementarteilchenphysik entfernt sind: Neutrinos interagieren kaum mit der Außenwelt und können den Prozessor sicherlich nicht beeinflussen.
Da es nicht möglich war, die Fehlerursache zu finden, nur für den Fall, dass der "delinquente" Server vom Betrieb ausgeschlossen wurde.
Nach einiger Zeit haben wir begonnen, das Hot-Standby-System zu verbessern: Wir haben die sogenannten „Warm-Reserven“ (asynchrone Replikate) eingeführt. Sie erhielten eine Reihe von Transaktionen, die sich möglicherweise in verschiedenen Rechenzentren befanden, aber warm unterstützte keine aktive Interaktion mit anderen Servern.
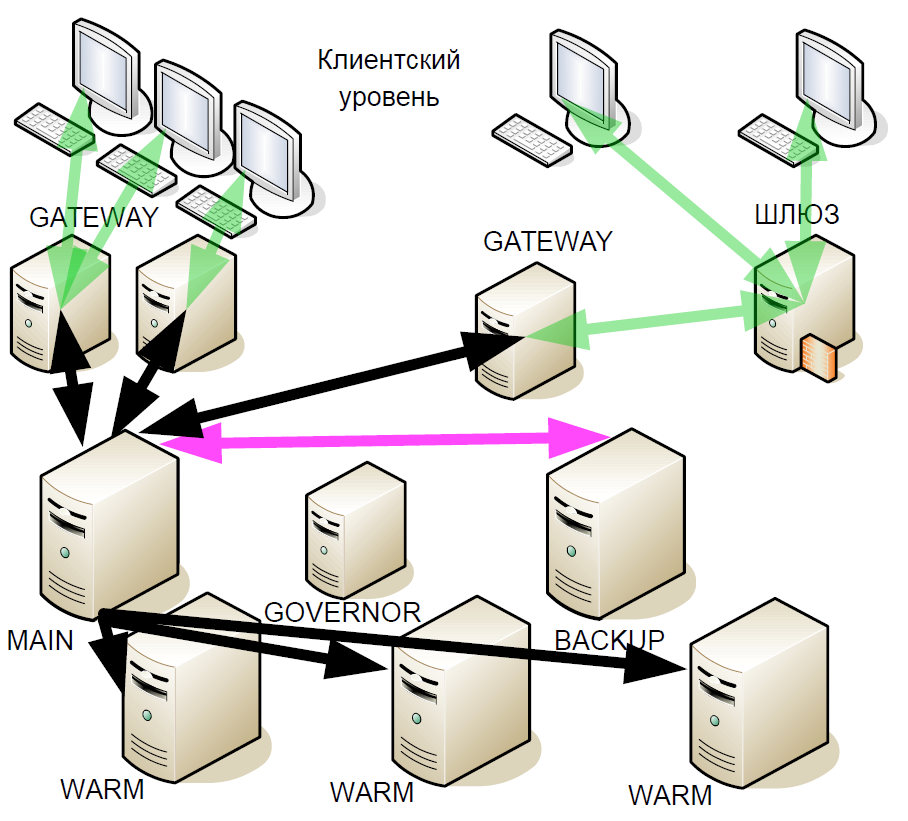
Warum wurde das gemacht? Wenn der Sicherungsserver ausfällt, wird die Warmbindung an den Hauptserver zur neuen Sicherung. Das heißt, nach einem Ausfall bleibt das System erst am Ende der Handelssitzung mit einem Hauptserver.
Und als die neue Version des Systems getestet und in Betrieb genommen wurde, trat erneut ein Fehler mit einem Rundungsbit auf. Darüber hinaus trat der Fehler mit zunehmender Anzahl von Warm-Servern häufiger auf. In diesem Fall hatte der Verkäufer nichts zu präsentieren, da es keine konkreten Beweise gibt.
Bei der nächsten Analyse der Situation stellte sich die Theorie auf, dass das Problem mit dem Betriebssystem zusammenhängen könnte. Wir haben ein einfaches Programm geschrieben, das die
fesetround Funktion in einer Endlosschleife
fesetround , sich den aktuellen Status merkt und ihn im Ruhezustand überprüft. Dies geschieht in vielen konkurrierenden Threads. Nachdem wir die Schlafparameter und die Anzahl der Threads ausgewählt hatten, begannen wir, den Bitfehler nach etwa 5 Minuten des Dienstprogramms stabil zu reproduzieren. Die Red Hat-Unterstützung konnte es jedoch nicht reproduzieren. Tests unserer anderen Server haben gezeigt, dass nur diejenigen mit bestimmten installierten Prozessoren von dem Fehler betroffen sind. Gleichzeitig löste der Übergang zu einem neuen Kern das Problem. Am Ende haben wir nur das Betriebssystem ersetzt, und die wahre Ursache des Fehlers blieb unklar.
Und letztes Jahr erschien plötzlich ein Artikel über Habré „
Wie ich einen Fehler in Intel Skylake-Prozessoren gefunden habe “. Die darin beschriebene Situation war unserer sehr ähnlich, aber der Autor hat die Untersuchung weiter vorangetrieben und die Theorie vertreten, dass der Fehler im Mikrocode lag. Bei der Aktualisierung von Linux-Kerneln aktualisieren die Hersteller auch den Mikrocode.
Weiterentwicklung des Systems
Obwohl wir den Fehler beseitigt haben, hat uns diese Geschichte dazu gebracht, die Architektur des Systems erneut zu überdenken. Schließlich waren wir nicht vor der Wiederholung solcher Fehler geschützt.
Die folgenden Prinzipien bildeten die Grundlage für weitere Verbesserungen des Backup-Systems:
- Sie können niemandem vertrauen. Server funktionieren möglicherweise nicht richtig.
- Mehrheitsredundanz.
- Konsensbildung. Als logische Ergänzung zur Mehrheitsredundanz.
- Doppelte Ausfälle sind möglich.
- Vitalität. Das neue Hot-Spare-System sollte nicht schlechter sein als das vorherige. Der Handel sollte reibungslos bis zum letzten Server verlaufen.
- Eine leichte Zunahme der Verzögerung. Jede Ausfallzeit bringt enorme finanzielle Verluste mit sich.
- Minimale Netzwerkinteraktion, damit die Verzögerung so gering wie möglich ist.
- Wählen Sie in Sekunden einen neuen Master-Server aus.
Keine der auf dem Markt verfügbaren Lösungen passte zu uns, und das Raft-Protokoll steckte noch in den Kinderschuhen. Deshalb haben wir unsere eigene Lösung entwickelt.

Netzwerkkonnektivität
Zusätzlich zum Backup-System haben wir begonnen, die Netzwerkkonnektivität zu modernisieren. Das E / A-Subsystem bestand aus einer Vielzahl von Prozessen, die Jitter und Verzögerung am schlimmsten beeinflussten. Mit Hunderten von Prozessen, die TCP-Verbindungen verarbeiten, mussten wir ständig zwischen ihnen wechseln, und im Mikrosekundenbereich ist dies ein ziemlich langwieriger Vorgang. Das Schlimmste ist jedoch, dass ein Prozess, der ein Paket zur Verarbeitung empfangen hat, es an eine SystemV-Warteschlange gesendet und dann auf Ereignisse aus einer anderen SystemV-Warteschlange gewartet hat. Bei einer großen Anzahl von Knoten stellen das Eintreffen eines neuen TCP-Pakets in einem Prozess und der Empfang von Daten in einer Warteschlange in einem anderen Prozess zwei konkurrierende Ereignisse für das Betriebssystem dar. In diesem Fall wird einer verarbeitet, wenn für beide Aufgaben keine physischen Prozessoren verfügbar sind, und der zweite steht in der Warteschlange. Es ist unmöglich, die Konsequenzen vorherzusagen.
In solchen Situationen können Sie die dynamische Prozessprioritätssteuerung anwenden, dies erfordert jedoch die Verwendung ressourcenintensiver Systemaufrufe. Infolgedessen haben wir mit dem klassischen Epoll zu einem Thread gewechselt. Dies hat die Geschwindigkeit erheblich erhöht und die Verarbeitungszeit der Transaktion verkürzt. Wir haben auch bestimmte Prozesse der Netzwerkinteraktion und -interaktion durch SystemV beseitigt, die Anzahl der Systemaufrufe erheblich reduziert und begonnen, die Prioritäten des Betriebs zu steuern. Mit nur einem E / A-Subsystem konnten je nach Szenario ca. 8-17 Mikrosekunden eingespart werden. Dieses Single-Threaded-Schema wurde seitdem unverändert angewendet. Ein Epoll-Stream mit einem Rand reicht aus, um alle Verbindungen zu bedienen.
Transaktionsverarbeitung
Die wachsende Belastung unseres Systems erforderte die Modernisierung fast aller seiner Komponenten. Leider erlaubte uns die Stagnation der Erhöhung der Prozessortaktrate in den letzten Jahren nicht mehr, die Prozesse „frontal“ zu skalieren. Aus diesem Grund haben wir uns entschlossen, den Engine-Prozess in drei Ebenen zu unterteilen. Die am stärksten belastete ist das Risikoüberprüfungssystem, das die Verfügbarkeit von Geldern auf den Konten bewertet und die Transaktionen selbst erstellt. Das Geld kann jedoch in verschiedenen Währungen vorliegen, und es musste herausgefunden werden, nach welchem Prinzip die Anforderungsverarbeitung aufgeteilt werden sollte.
Die logische Lösung besteht darin, nach Währungen zu teilen: Ein Server handelt in Dollar, ein anderer in Pfund und ein dritter Euro. Wenn bei einem solchen Schema jedoch zwei Transaktionen gesendet werden, um unterschiedliche Währungen zu kaufen, besteht das Problem, dass Brieftaschen nicht synchron sind. Und das Synchronisieren ist schwierig und teuer. Daher ist es richtig, auf Brieftaschen und auf Werkzeugen getrennt zu scherben. Übrigens ist in den meisten westlichen Börsen die Aufgabe, Risiken zu überprüfen, nicht so akut wie bei uns, daher erfolgt dies meistens offline. Wir mussten einen Online-Check durchführen.
Lassen Sie uns anhand eines Beispiels veranschaulichen. Der Händler möchte 30 USD kaufen, und die Anfrage geht zur Validierung der Transaktion: Wir prüfen, ob dieser Händler in diesen Handelsmodus zugelassen ist und ob er über die erforderlichen Rechte verfügt. Wenn alles in Ordnung ist, geht die Anfrage an das Risikoüberprüfungssystem, d. H. um zu überprüfen, ob die Mittel ausreichen, um eine Transaktion abzuschließen. Es gibt einen Hinweis, dass der erforderliche Betrag derzeit gesperrt ist. Ferner wird die Anfrage an das Handelssystem umgeleitet, das diese Transaktion genehmigt oder nicht genehmigt. Angenommen, die Transaktion wird genehmigt. Dann stellt das Risikoüberprüfungssystem fest, dass das Geld freigeschaltet und die Rubel in Dollar umgerechnet werden.
Im Allgemeinen enthält das Risikoüberprüfungssystem komplexe Algorithmen, führt eine Vielzahl sehr ressourcenintensiver Berechnungen durch und überprüft nicht nur den „Kontostand“, wie es auf den ersten Blick erscheinen mag.
Als wir anfingen, den Engine-Prozess in Ebenen zu unterteilen, stießen wir auf ein Problem: Der Code, der zu diesem Zeitpunkt in den Phasen der Validierung und Verifizierung verfügbar war, verwendete aktiv dasselbe Datenarray, wodurch die gesamte Codebasis neu geschrieben werden musste. Aus diesem Grund haben wir uns eine Methode zur Verarbeitung von Anweisungen von modernen Prozessoren ausgeliehen: Jede von ihnen ist in kleine Stufen unterteilt, und mehrere Aktionen werden parallel in einem Zyklus ausgeführt.
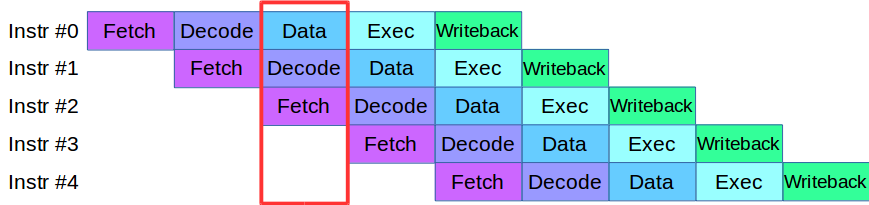
Nach einer kleinen Anpassung des Codes haben wir eine Pipeline für die parallele Verarbeitung von Transaktionen erstellt, in der die Transaktion in vier Phasen der Pipeline unterteilt wurde: Netzwerkinteraktion, Validierung, Ausführung und Veröffentlichung des Ergebnisses

Betrachten Sie ein Beispiel. Wir haben zwei Verarbeitungssysteme, seriell und parallel. Die erste Transaktion kommt an und wird in beiden Systemen validiert. Dann kommt die zweite Transaktion an: In einem parallelen System wird sie sofort zur Arbeit gebracht, und in einem sequentiellen System wird sie in die Warteschlange gestellt, bis die erste Transaktion die aktuelle Verarbeitungsstufe durchläuft. Das heißt, der Hauptvorteil von Pipelining besteht darin, dass wir die Transaktionswarteschlange schneller verarbeiten.
Also haben wir das ASTS + System.
Auch bei Förderbändern ist nicht alles so glatt. Angenommen, wir haben eine Transaktion, die sich auf die Datenfelder in einer benachbarten Transaktion auswirkt. Dies ist eine typische Situation für den Austausch. Eine solche Transaktion kann nicht in der Pipeline ausgeführt werden, da sie andere betreffen kann. Diese Situation wird als Datengefahr bezeichnet, und solche Transaktionen werden einfach separat verarbeitet: Wenn die "schnellen" Transaktionen in der Warteschlange enden, stoppt die Pipeline, das System verarbeitet die "langsame" Transaktion und startet die Pipeline erneut. Glücklicherweise ist der Anteil solcher Transaktionen am Gesamtfluss sehr gering, sodass die Pipeline so selten stoppt, dass die Gesamtleistung nicht beeinträchtigt wird.

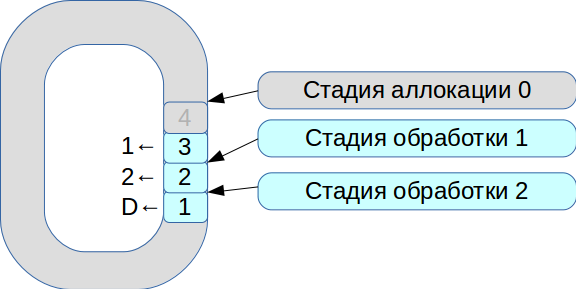
Dann begannen wir, das Problem der Synchronisation von drei Ausführungsthreads zu lösen. Als Ergebnis wurde ein System geboren, das auf einem kreisförmigen Puffer mit Zellen fester Größe basiert. In diesem System unterliegt alles der Verarbeitungsgeschwindigkeit, Daten werden nicht kopiert.
- Alle eingehenden Netzwerkpakete fallen in die Zuordnungsphase.
- Wir platzieren sie in einem Array und markieren, dass sie für Stufe Nr. 1 verfügbar sind.
- Die zweite Transaktion kam, sie ist wieder für Stufe Nr. 1 verfügbar.
- Der erste Verarbeitungsablauf sieht die verfügbaren Transaktionen, verarbeitet sie und überträgt sie an die nächste Stufe des zweiten Verarbeitungsablaufs.
- Dann verarbeitet es die erste Transaktion und markiert die entsprechende Zelle mit dem
deleted Flag - jetzt steht sie zur neuen Verwendung zur Verfügung.
Somit wird die gesamte Warteschlange verarbeitet.
Die Verarbeitung jeder Stufe dauert Einheiten oder zehn Mikrosekunden. Wenn Sie Standard-Betriebssystemsynchronisationsschemata verwenden, verlieren wir mehr Zeit für die Synchronisation. Deshalb haben wir angefangen, Spinlock zu verwenden. Dies ist jedoch ein sehr schlechter Ton in einem Echtzeitsystem, und RedHat empfiehlt dies strikt nicht. Daher verwenden wir Spinlock für 100 ms und wechseln dann in den Semaphor-Modus, um die Möglichkeit eines Deadlocks auszuschließen.
Infolgedessen haben wir eine Leistung von rund 8 Millionen Transaktionen pro Sekunde erzielt. Und nur zwei Monate später sahen sie in einem
Artikel über LMAX Disruptor eine Beschreibung einer Schaltung mit derselben Funktionalität.
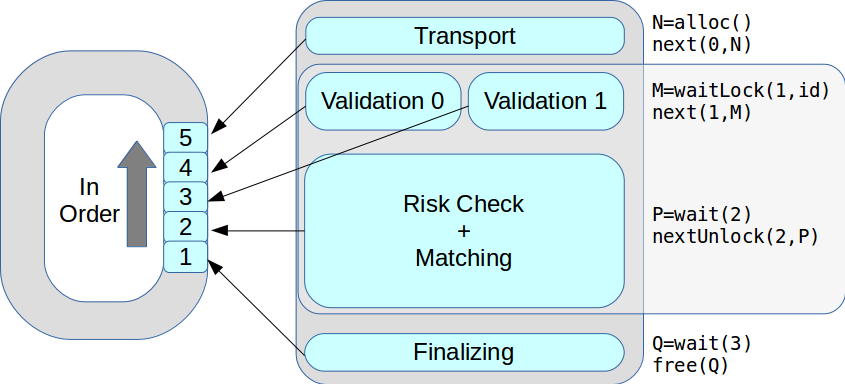
Jetzt könnte es zu einem bestimmten Zeitpunkt mehrere Ausführungsthreads geben. Alle Transaktionen wurden der Reihe nach in der Reihenfolge ihres Eingangs bearbeitet. Infolgedessen stieg die Spitzenleistung von 18.000 auf 50.000 Transaktionen pro Sekunde.
Exchange Risk Management System
Der Perfektion sind keine Grenzen gesetzt, und bald begannen wir wieder mit der Modernisierung: Im Rahmen von ASTS + begannen wir, Risikomanagementsysteme und Abwicklungsvorgänge in autonome Komponenten zu übertragen. Wir haben eine flexible moderne Architektur und ein neues hierarchisches Risikomodell entwickelt und versucht, wo immer möglich, die Klasse
fixed_point anstelle von
double .
Aber sofort trat das Problem auf: Wie kann man die gesamte Geschäftslogik, die seit vielen Jahren funktioniert, synchronisieren und auf das neue System übertragen? Infolgedessen musste die erste Version des Prototyps des neuen Systems aufgegeben werden. Die zweite Version, die derzeit in der Produktion arbeitet, basiert auf demselben Code, der sowohl im Handelsteil als auch im Risikoteil funktioniert. Während der Entwicklung war es am schwierigsten, Git zwischen den beiden Versionen zusammenzuführen. Unser Kollege Evgeny Mazurenok führte diese Operation jede Woche durch und fluchte jedes Mal sehr lange.
Bei der Auswahl eines neuen Systems mussten wir das Interaktionsproblem sofort lösen. Bei der Auswahl eines Datenbusses war auf stabilen Jitter und minimale Verzögerung zu achten. Hierfür ist das InfiniBand RDMA-Netzwerk am besten geeignet: Die durchschnittliche Verarbeitungszeit ist viermal kürzer als in 10-G-Ethernet-Netzwerken. Der wirkliche Unterschied lag jedoch in den Perzentilen - 99 und 99,9.
Natürlich hat InfiniBand seine eigenen Schwierigkeiten. Erstens ist eine andere API ibverbs anstelle von Sockets. Zweitens gibt es fast keine allgemein verfügbaren Open-Source-Messaging-Lösungen. Wir haben versucht, unseren Prototyp herzustellen, aber es stellte sich als sehr schwierig heraus. Deshalb haben wir uns für eine kommerzielle Lösung entschieden - Confinity Messaging mit geringer Latenz (ehemals IBM MQ LLM).
Dann trat das Problem der korrekten Trennung des Risikosystems auf. Wenn Sie nur die Risk Engine herausnehmen und keinen Zwischenknoten erstellen, können Transaktionen aus zwei Quellen verwechselt werden.
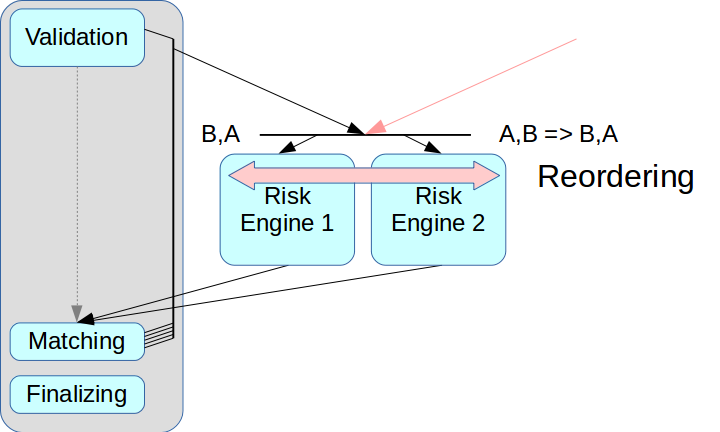
Die sogenannten Ultra Low Latency-Lösungen verfügen über einen Neuordnungsmodus: Transaktionen aus zwei Quellen können nach Erhalt in der richtigen Reihenfolge angeordnet werden. Dies erfolgt über einen separaten Kanal zum Austausch von Informationen über die Sequenz. Wir wenden diesen Modus jedoch noch nicht an: Er verkompliziert den gesamten Prozess und wird in einigen Lösungen überhaupt nicht unterstützt. Außerdem müssten jeder Transaktion die entsprechenden Zeitstempel zugewiesen werden, und in unserem Schema ist es sehr schwierig, diesen Mechanismus korrekt zu implementieren. Daher haben wir das klassische Schema mit Message Broker verwendet, dh mit einem Dispatcher, der Nachrichten zwischen Risk Engine verteilt.
Das zweite Problem betraf den Clientzugriff: Wenn mehrere Risiko-Gateways vorhanden sind, muss der Client eine Verbindung zu jedem dieser Gateways herstellen. Dazu müssen Sie Änderungen an der Client-Schicht vornehmen. Wir wollten zu diesem Zeitpunkt davon Abstand nehmen, daher verarbeiten sie im aktuellen Risk Gateway-Schema den gesamten Datenstrom. Dies schränkt den maximalen Durchsatz erheblich ein, vereinfacht jedoch die Systemintegration erheblich.
Vervielfältigung
Unser System sollte keinen einzigen Fehlerpunkt haben, dh alle Komponenten müssen dupliziert werden, einschließlich eines Nachrichtenbrokers. Wir haben dieses Problem mit dem CLLM-System gelöst: Es enthält einen RCMS-Cluster, in dem zwei Disponenten im Master-Slave-Modus arbeiten können. Wenn einer ausfällt, wechselt das System automatisch zum anderen.
Arbeiten Sie mit einem Backup-Rechenzentrum
InfiniBand ist für die Verwendung als lokales Netzwerk optimiert, dh für den Anschluss von Rack-Geräten, und es gibt keine Möglichkeit, ein InfiniBand-Netzwerk zwischen zwei geografisch verteilten Rechenzentren einzurichten. Aus diesem Grund haben wir einen Bridge / Dispatcher implementiert, der über reguläre Ethernet-Netzwerke eine Verbindung zum Nachrichtenspeicher herstellt und alle Transaktionen an das zweite IB-Netzwerk weiterleitet. Wenn Sie eine Migration aus dem Rechenzentrum benötigen, können wir auswählen, mit welchem Rechenzentrum wir jetzt arbeiten möchten.
Zusammenfassung
All dies wurde nicht auf einmal durchgeführt, es dauerte mehrere Iterationen der Entwicklung einer neuen Architektur. Wir haben den Prototyp in einem Monat erstellt, aber es dauerte mehr als zwei Jahre, bis die Arbeitsbedingungen abgeschlossen waren. Wir haben versucht, den besten Kompromiss zwischen der Verlängerung der Transaktionsverarbeitung und der Zuverlässigkeit des Systems zu erzielen.
Da das System stark aktualisiert wurde, haben wir die Datenwiederherstellung aus zwei unabhängigen Quellen implementiert. Wenn der Nachrichtenspeicher aus irgendeinem Grund nicht ordnungsgemäß funktioniert, können Sie das Transaktionsprotokoll aus einer zweiten Quelle beziehen - aus der Risk Engine. Dieses Prinzip wird im gesamten System eingehalten.
Unter anderem ist es uns gelungen, die Client-API so zu halten, dass weder Broker noch andere Personen eine wesentliche Änderung für die neue Architektur benötigen. Ich musste einige Schnittstellen ändern, aber ich musste keine wesentlichen Änderungen am Arbeitsmodell vornehmen.
Wir haben die aktuelle Version unserer Plattform Rebus genannt - als Abkürzung für die beiden bemerkenswertesten Innovationen in der Architektur, Risk Engine und BUS.
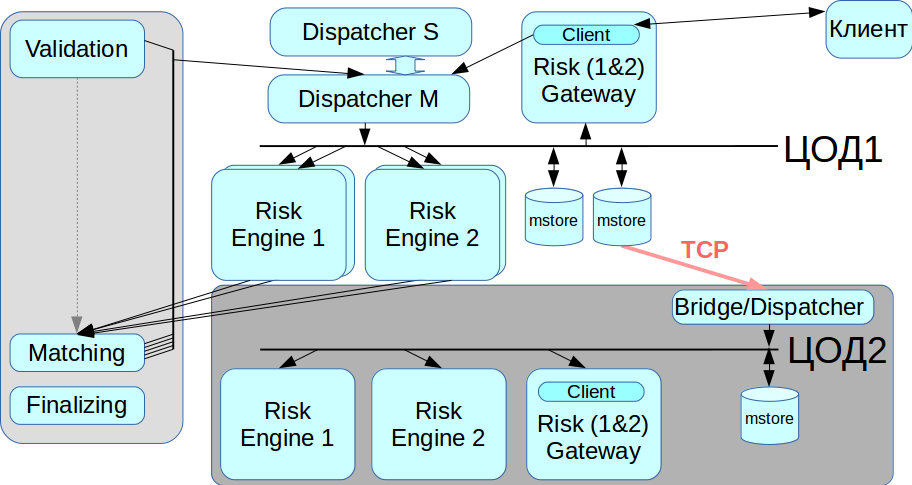
Anfangs wollten wir nur den Clearing-Teil hervorheben, aber das Ergebnis war ein riesiges verteiltes System. Jetzt können Kunden entweder mit dem Trading Gateway oder mit dem Clearing oder mit beiden gleichzeitig interagieren.
Was wir letztendlich erreicht haben:

Die Verzögerung wurde reduziert. Bei einem geringen Transaktionsvolumen funktioniert das System genauso wie die Vorgängerversion, hält jedoch gleichzeitig einer viel höheren Belastung stand.
Die Spitzenproduktivität stieg von 50.000 auf 180.000 Transaktionen pro Sekunde. Ein weiterer Informationsstrom behindert das weitere Wachstum.
Es gibt zwei Möglichkeiten zur weiteren Verbesserung: Parallelisierungsabgleich und Änderung des Arbeitsschemas mit Gateway. Jetzt arbeiten alle Gateways nach dem Replikationsschema, das bei dieser Last nicht mehr normal funktioniert.Am Ende kann ich denjenigen, die Unternehmenssysteme entwickeln, einige Ratschläge geben:- Seien Sie immer auf das Schlimmste vorbereitet. Probleme treten immer unerwartet auf.
- Es ist normalerweise unmöglich, die Architektur schnell zu wiederholen. Vor allem, wenn Sie bei einer Vielzahl von Indikatoren maximale Zuverlässigkeit erreichen möchten. Je mehr Knoten vorhanden sind, desto mehr Ressourcen werden für die Unterstützung benötigt.
- Alle speziellen und proprietären Lösungen erfordern zusätzlich Ressourcen für Forschung, Support und Support.
- , .