Allein in den Vereinigten Staaten gibt es 3 Millionen Menschen mit Behinderungen, die ihre Häuser nicht verlassen können. Hilfsroboter, die automatisch über große Entfernungen navigieren können, können diese Menschen unabhängiger machen, indem sie ihnen Lebensmittel, Medikamente und Pakete bringen. Studien zeigen, dass Deep Learning mit Verstärkung (OP) gut geeignet ist, um rohe Eingabedaten und Aktionen zu vergleichen, z. B.
um Objekte zu
erfassen oder
Roboter zu bewegen. In der Regel fehlt den OP-
Agenten jedoch das Verständnis für große physische Räume, die für eine sichere Orientierung auf Ferngespräche erforderlich sind Entfernungen ohne menschliche Hilfe und Anpassung an eine neue Umgebung.
In drei kürzlich erschienenen Arbeiten, „
Orientierungslauftraining von Grund auf mit AOP “, „
PRM-RL: Implementierung von Roboter-Orientierungslauf über große Entfernungen mithilfe einer Kombination aus Verstärkungslernen und musterbasierter Planung “ und „
Langstrecken-Orientierungslauf mit PRM-RL “, haben wir Wir untersuchen autonome Roboter, die sich leicht an eine neue Umgebung anpassen lassen und Deep OP mit langfristiger Planung kombinieren. Wir bringen lokalen Planern bei, wie sie die grundlegenden Aktionen ausführen, die zur Orientierung erforderlich sind, und wie sie kurze Strecken ohne Kollisionen mit sich bewegenden Objekten zurücklegen. Lokale Planer führen verrauschte Umgebungsbeobachtungen mit Sensoren wie eindimensionalen Lidaren durch, die den Abstand zu einem Hindernis bereitstellen und lineare und Winkelgeschwindigkeiten zur Steuerung des Roboters bereitstellen. Wir schulen den lokalen Planer in Simulationen mithilfe des automatischen Verstärkungslernens (AOP), einer Methode, die die Suche nach Belohnungen für das OP und die Architektur des neuronalen Netzwerks automatisiert. Trotz der begrenzten Reichweite von 10 bis 15 m passen sich lokale Planer sowohl für den Einsatz in echten Robotern als auch für neue, bisher unbekannte Umgebungen gut an. Auf diese Weise können Sie sie als Bausteine für die Ausrichtung auf großen Räumen verwenden. Dann erstellen wir eine Straßenkarte, ein Diagramm, in dem die Knoten separate Abschnitte sind, und die Kanten verbinden die Knoten nur dann, wenn lokale Planer, die echte Roboter mit lauten Sensoren und Steuerungen gut imitieren, zwischen ihnen wechseln können.
Automatisches Verstärkungslernen (AOP)
In
unserer ersten Arbeit schulen wir einen lokalen Planer in einer kleinen statischen Umgebung. Beim Lernen mit dem Standard-Deep-OP-Algorithmus, beispielsweise dem Deep Deterministic Gradient (
DDPG ), gibt es jedoch mehrere Hindernisse. Zum Beispiel ist das eigentliche Ziel der lokalen Planer, ein bestimmtes Ziel zu erreichen, wodurch sie seltene Belohnungen erhalten. In der Praxis müssen die Forscher viel Zeit für die schrittweise Implementierung des Algorithmus und die manuelle Anpassung der Auszeichnungen aufwenden. Die Forscher müssen auch Entscheidungen über die Architektur neuronaler Netze treffen, ohne klare, erfolgreiche Rezepte zu haben. Schließlich lernen Algorithmen wie DDPG instabil und zeigen oft
katastrophale Vergesslichkeit .
Um diese Hindernisse zu überwinden, haben wir tiefes Lernen mit Verstärkung automatisiert. AOP ist ein evolutionärer automatischer Wrapper um ein tiefes OP, der Belohnungen und neuronale Netzwerkarchitektur durch
umfassende Hyperparameteroptimierung sucht. Es funktioniert in zwei Schritten: der Suche nach Belohnungen und der Suche nach Architektur. Während der Suche nach Belohnungen trainiert AOP gleichzeitig die Population der DDPG-Agenten über mehrere Generationen hinweg, und jeder hat seine eigene leicht modifizierte Belohnungsfunktion, die für die wahre Aufgabe des lokalen Planers optimiert ist: das Erreichen des Endpunkts des Pfades. Am Ende der Belohnungssuchphase wählen wir eine aus, die die Agenten am häufigsten zum Ziel führt. In der Suchphase der neuronalen Netzwerkarchitektur wiederholen wir diesen Vorgang für dieses Rennen unter Verwendung der ausgewählten Auszeichnung und Anpassen der Netzwerkschichten, um die kumulative Auszeichnung zu optimieren.
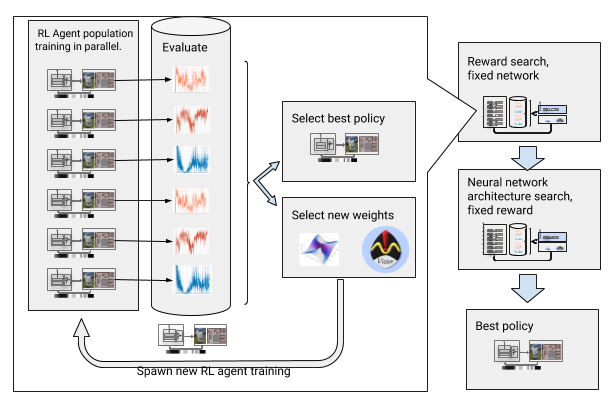 AOP mit der Suche nach Auszeichnung und Architektur des neuronalen Netzes
AOP mit der Suche nach Auszeichnung und Architektur des neuronalen NetzesDieser schrittweise Prozess macht AOP jedoch hinsichtlich der Anzahl der Proben unwirksam. Für ein AOP-Training mit 10 Generationen von 100 Wirkstoffen sind 5 Milliarden Proben erforderlich, was 32 Studienjahren entspricht! Der Vorteil ist, dass nach AOP der manuelle Lernprozess automatisiert wird und DDPG kein katastrophales Vergessen hat. Am wichtigsten ist, dass die Qualität der endgültigen Richtlinien höher ist - sie sind beständig gegen Störungen durch Sensor, Laufwerk und Lokalisierung und lassen sich gut auf neue Umgebungen übertragen. Unsere beste Strategie ist 26% erfolgreicher als andere Orientierungsmethoden an unseren Teststandorten.
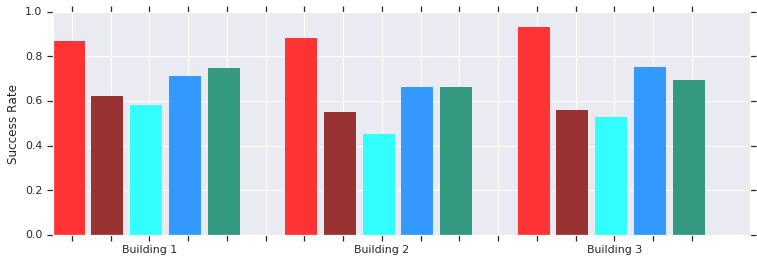 Rot - AOP-Erfolge auf kurzen Strecken (bis zu 10 m) in mehreren bisher unbekannten Gebäuden. Vergleich mit manuell trainiertem DDPG (dunkelrot), künstlichen Potentialfeldern (blau), dynamischem Fenster (blau) und Verhaltensklonen (grün).Die lokale AOP-Scheduler-Richtlinie funktioniert gut mit Robotern in realen unstrukturierten Umgebungen
Rot - AOP-Erfolge auf kurzen Strecken (bis zu 10 m) in mehreren bisher unbekannten Gebäuden. Vergleich mit manuell trainiertem DDPG (dunkelrot), künstlichen Potentialfeldern (blau), dynamischem Fenster (blau) und Verhaltensklonen (grün).Die lokale AOP-Scheduler-Richtlinie funktioniert gut mit Robotern in realen unstrukturierten UmgebungenUnd obwohl diese Politiker nur lokal orientiert sind, sind sie widerstandsfähig gegen sich bewegende Hindernisse und werden von echten Robotern in unstrukturierten Umgebungen gut vertragen. Und obwohl sie in Simulationen mit statischen Objekten geschult wurden, bewältigen sie effektiv bewegte Objekte. Der nächste Schritt besteht darin, AOP-Richtlinien mit einer stichprobenbasierten Planung zu kombinieren, um ihren Arbeitsbereich zu erweitern und ihnen das Navigieren über große Entfernungen beizubringen.
Fernorientierung mit PRM-RL
Musterbasierte Planer arbeiten mit großer Ausrichtung und nähern sich den Roboterbewegungen an. Beispielsweise erstellt ein Roboter
probabilistische Roadmaps (PRMs), indem er Übergangspfade zwischen Abschnitten zeichnet. In unserer
zweiten Arbeit , die auf der
ICRA 2018- Konferenz ausgezeichnet wurde, kombinieren wir PRM mit manuell abgestimmten lokalen OP-Schedulern (ohne AOP), um Roboter lokal zu trainieren und sie dann an andere Umgebungen anzupassen.
Zunächst trainieren wir für jeden Roboter die lokale Scheduler-Richtlinie in einer verallgemeinerten Simulation. Anschließend erstellen wir unter Berücksichtigung dieser Richtlinie ein PRM, das sogenannte PRM-RL, basierend auf einer Karte der Umgebung, in der es verwendet wird. Dieselbe Karte kann für jeden Roboter verwendet werden, den wir im Gebäude verwenden möchten.
Um ein PRM-RL zu erstellen, kombinieren wir Knoten aus Samples nur, wenn der lokale OP-Scheduler zuverlässig und wiederholt zwischen ihnen wechseln kann. Dies erfolgt in einer Monte-Carlo-Simulation. Die resultierende Karte passt sich den Fähigkeiten und der Geometrie eines bestimmten Roboters an. Karten für Roboter mit derselben Geometrie, aber unterschiedlichen Sensoren und Antrieben haben unterschiedliche Konnektivität. Da sich der Agent um die Ecke drehen kann, können auch Knoten aktiviert werden, die sich nicht in direkter Sichtlinie befinden. Es ist jedoch weniger wahrscheinlich, dass Knoten, die an Wände und Hindernisse angrenzen, aufgrund von Sensorrauschen in die Karte aufgenommen werden. Zur Laufzeit bewegt sich der OP-Agent über die Karte von einem Abschnitt zum anderen.
 Für jedes zufällig ausgewählte Knotenpaar wird eine Karte mit drei Monte-Carlo-Simulationen erstellt
Für jedes zufällig ausgewählte Knotenpaar wird eine Karte mit drei Monte-Carlo-Simulationen erstellt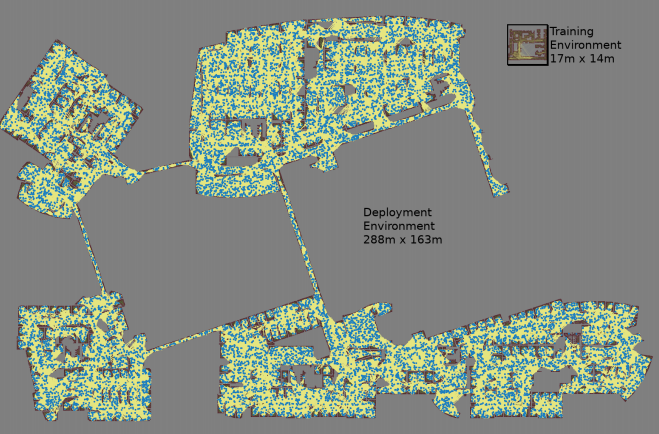 Die größte Karte war 288 x 163 m groß und enthielt fast 700.000 Kanten. 300 Arbeiter sammelten es für 4 Tage, nachdem sie 1,1 Milliarden Kollisionskontrollen durchgeführt hatten.Die dritte Arbeit
Die größte Karte war 288 x 163 m groß und enthielt fast 700.000 Kanten. 300 Arbeiter sammelten es für 4 Tage, nachdem sie 1,1 Milliarden Kollisionskontrollen durchgeführt hatten.Die dritte Arbeit bietet mehrere Verbesserungen gegenüber dem ursprünglichen PRM-RL. Erstens ersetzen wir das manuell abgestimmte DDPG durch lokale AOP-Scheduler, wodurch sich die Ausrichtung über große Entfernungen verbessert. Zweitens werden
Karten zur gleichzeitigen Lokalisierung und Markierung (
SLAM ) hinzugefügt, die Roboter zur Laufzeit als Quelle für die Erstellung von Roadmaps verwenden. SLAM-Karten sind Rauschen ausgesetzt, und dies schließt die „Lücke zwischen Simulator und Realität“, ein bekanntes Problem in der Robotik, aufgrund dessen sich in Simulationen geschulte Agenten in der realen Welt viel schlechter verhalten. Unser Erfolgsniveau in der Simulation stimmt mit dem Erfolgsniveau realer Roboter überein. Und schließlich haben wir verteilte Gebäudekarten hinzugefügt, damit wir sehr große Karten mit bis zu 700.000 Knoten erstellen können.
Wir haben diese Methode mit Hilfe unseres AOP-Agenten evaluiert, der Karten basierend auf Zeichnungen von Gebäuden erstellt hat, die die Trainingsumgebung um das 200-fache überschritten haben, einschließlich nur Rippen, die in 90% der Fälle in 20 Versuchen erfolgreich abgeschlossen wurden. Wir haben PRM-RL mit verschiedenen Methoden in Entfernungen von bis zu 100 m verglichen, was die Reichweite des lokalen Planers deutlich überstieg. PRM-RL erzielte aufgrund der korrekten Verbindung der Knoten, die für die Fähigkeiten des Roboters geeignet ist, 2-3-mal häufiger Erfolge als herkömmliche Methoden.
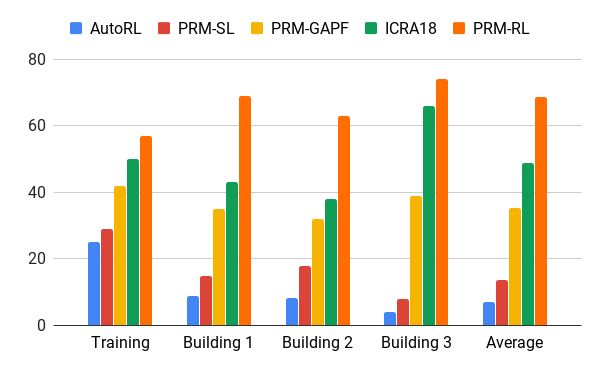 Erfolgsquote beim Umzug von 100 m in verschiedenen Gebäuden. Blau - lokaler AOP-Scheduler, erster Job; rot - original PRM; gelb - künstliche Potentialfelder; Grün ist der zweite Job; rot - der dritte Job, PRM mit AOP.
Erfolgsquote beim Umzug von 100 m in verschiedenen Gebäuden. Blau - lokaler AOP-Scheduler, erster Job; rot - original PRM; gelb - künstliche Potentialfelder; Grün ist der zweite Job; rot - der dritte Job, PRM mit AOP.Wir haben PRM-RL an vielen echten Robotern in vielen Gebäuden getestet. Unten finden Sie eine der Testsuiten. Der Roboter bewegt sich fast überall zuverlässig, mit Ausnahme der unordentlichsten Stellen und Bereiche, die über die SLAM-Karte hinausgehen.

Fazit
Maschinenorientierung kann die Unabhängigkeit von Menschen mit eingeschränkter Mobilität ernsthaft erhöhen. Dies kann erreicht werden, indem autonome Roboter entwickelt werden, die sich leicht an die Umgebung anpassen lassen, und die Methoden, die für die Implementierung in der neuen Umgebung verfügbar sind, basierend auf vorhandenen Informationen. Dies kann erreicht werden, indem das grundlegende Orientierungstraining für kurze Strecken mit AOP automatisiert und die erworbenen Fähigkeiten zusammen mit SLAM-Karten verwendet werden, um Roadmaps zu erstellen. Roadmaps bestehen aus Knoten, die durch Rippen verbunden sind, auf denen sich Roboter zuverlässig bewegen können. Als Ergebnis wird eine Roboterverhaltensrichtlinie entwickelt, die nach einem Training in verschiedenen Umgebungen verwendet werden kann und Roadmaps erstellt, die speziell für einen bestimmten Roboter angepasst wurden.