Hallo. Mein Name ist Andrey, ich bin ein Doktorand an einer der technischen Universitäten von Moskau und Teilzeit sehr bescheiden Anfänger Unternehmer und Entwickler. In diesem Artikel habe ich beschlossen, meine Erfahrungen mit dem Wechsel von PHP (das mir einst wegen seiner Einfachheit gefallen hat, aber schließlich von mir gehasst wurde - ich erkläre, warum unter dem Schnitt) zu NodeJS zu teilen. Hier können sehr triviale und scheinbar elementare Aufgaben gestellt werden, die ich persönlich während meiner Bekanntschaft mit NodeJS und den Funktionen der serverseitigen Entwicklung in JavaScript persönlich lösen wollte. Ich werde versuchen, klar zu erklären und zu demonstrieren, dass PHP endlich in den Sonnenuntergang gegangen ist und NodeJS Platz gemacht hat. Vielleicht ist es sogar nützlich, wenn jemand einige Funktionen zum Rendern von HTML-Seiten in Node lernt, die ursprünglich aus dem Wort überhaupt nicht angepasst wurden.
Einführung
Beim Schreiben der Engine habe ich die einfachsten Techniken verwendet. Keine Paketmanager, kein Routing. Nur Hardcore-Ordner, deren Name mit der angeforderten Route übereinstimmt, und index.php in jedem von ihnen, die von PHP-FPM zur Unterstützung des Prozesspools konfiguriert wurden. Später wurde es notwendig, Composer und Laravel zu verwenden, was für mich der letzte Strohhalm war. Bevor ich zu der Geschichte übergehe, warum ich mich überhaupt dazu entschlossen habe, alles von PHP auf NodeJS umzuschreiben, möchte ich Ihnen ein wenig über den Hintergrund erzählen.
Paketmanager
Ende 2018 arbeitete ich zufällig mit einem in Laravel geschriebenen Projekt. Es war notwendig, mehrere Fehler zu beheben, Änderungen an der vorhandenen Funktionalität vorzunehmen und einige neue Schaltflächen in der Benutzeroberfläche hinzuzufügen. Der Prozess begann mit der Installation des Paket- und Abhängigkeitsmanagers. In PHP wird hierfür Composer verwendet. Dann stellte der Kunde einen Server mit 1 Kern und 512 Megabyte RAM zur Verfügung, und dies war meine erste Erfahrung mit Composer. Bei der Installation von Abhängigkeiten auf einem virtuellen privaten Server mit 512 Megabyte Speicher stürzte der Prozess aufgrund von Speichermangel ab.

Für mich als Person, die mit Linux vertraut ist und Erfahrung in der Arbeit mit Debian und Ubuntu hat, war die Lösung dieses Problems offensichtlich - die Installation einer SWAP-Datei (Swap-Datei - für diejenigen, die mit der Linux-Administration nicht vertraut sind). Ein unerfahrener unerfahrener Entwickler, der beispielsweise seine erste Laravel-Distribution auf Digital Ocean installiert hat, geht einfach zum Control Panel und erhöht den Tarif, bis die Installation von Abhängigkeiten mit einem Speichersegmentierungsfehler beendet wird. Was ist mit NodeJS?
Und NodeJS hat einen eigenen Paketmanager - npm. Es ist viel einfacher zu bedienen, kompakter und kann auch in einer Umgebung mit minimalem RAM-Speicher verwendet werden. Im Allgemeinen gibt es nichts, was Composer vor dem Hintergrund von NPM verantwortlich machen könnte. Im Falle von Fehlern bei der Installation von Paketen stürzt Composer jedoch wie eine normale PHP-Anwendung ab und Sie werden nie wissen, welcher Teil des Pakets installiert wurde und ob es am Ende installiert wurde endet. Im Allgemeinen ist für den Linux-Administrator die abgestürzte Installation = Rückblenden im Rettungsmodus und dpkg --configure -a . Als mich solche „Überraschungen“ überholten, mochte ich PHP nicht, aber dies waren die letzten Nägel im Sarg meiner einst großen Liebe zu PHP.
Problem mit langfristiger Unterstützung und Versionierung
Erinnern Sie sich, welche Art von Hype und Erstaunen PHP7 verursachte, als die Entwickler es zum ersten Mal präsentierten? Steigerung der Produktivität um mehr als das Zweifache und bei einigen Komponenten um das Fünffache! Erinnerst du dich, als die siebte PHP-Version geboren wurde? Und wie schnell hat WordPress verdient! Es war Dezember 2015. Wussten Sie, dass PHP 7.0 jetzt als veraltete Version von PHP gilt und es dringend empfohlen wird, es zu aktualisieren ... Nein, nicht auf Version 7.1, sondern auf Version 7.2. Laut den Entwicklern ist Version 7.1 bereits der aktiven Unterstützung beraubt und erhält nur Sicherheitsupdates. Und nach 8 Monaten wird dies aufhören. Es wird zusammen mit der aktiven Unterstützung und Version 7.2 eingestellt. Es stellt sich heraus, dass PHP bis Ende dieses Jahres nur eine aktuelle Version haben wird - 7.3.

Eigentlich wäre dies kein Nit-Picking und ich würde dies nicht den Gründen für meine Abkehr von PHP zuschreiben, wenn die Projekte, die ich in PHP 7.0 geschrieben habe. * Bereits beim Öffnen keine Warnung vor Verfall verursacht. Kehren wir zu dem Projekt zurück, bei dem die Installation von Abhängigkeiten abgestürzt ist. Dies war ein Projekt, das 2015 auf Laravel 4 mit PHP 5.6 geschrieben wurde. Es schien, dass nur 4 Jahre vergangen waren, aber nein - eine Reihe von Verfallswarnungen, veraltete Module, die Unfähigkeit, normalerweise aufgrund einer Reihe von Root-Engine-Updates auf Laravel 5 zu aktualisieren.
Und das gilt nicht nur für Laravel. Versuchen Sie, während der aktiven Unterstützung der ersten Versionen von PHP 7.0 eine PHP-Anwendung zu schreiben, und verbringen Sie Ihren Abend damit, nach Lösungen für Probleme zu suchen, die in veralteten PHP-Modulen aufgetreten sind. Schließlich eine interessante Tatsache: Die Unterstützung für PHP 7.0 wurde früher eingestellt als die Unterstützung für PHP 5.6. Für eine Sekunde.
Was ist mit NodeJS? Ich würde nicht sagen, dass hier alles viel besser ist und dass sich die Support-Zeiten für NodeJS grundlegend von denen für PHP unterscheiden. Nein, hier ist es ungefähr gleich - jede LTS-Version wird 3 Jahre lang unterstützt. Aber NodeJS hat ein bisschen mehr von diesen aktuellsten Versionen.
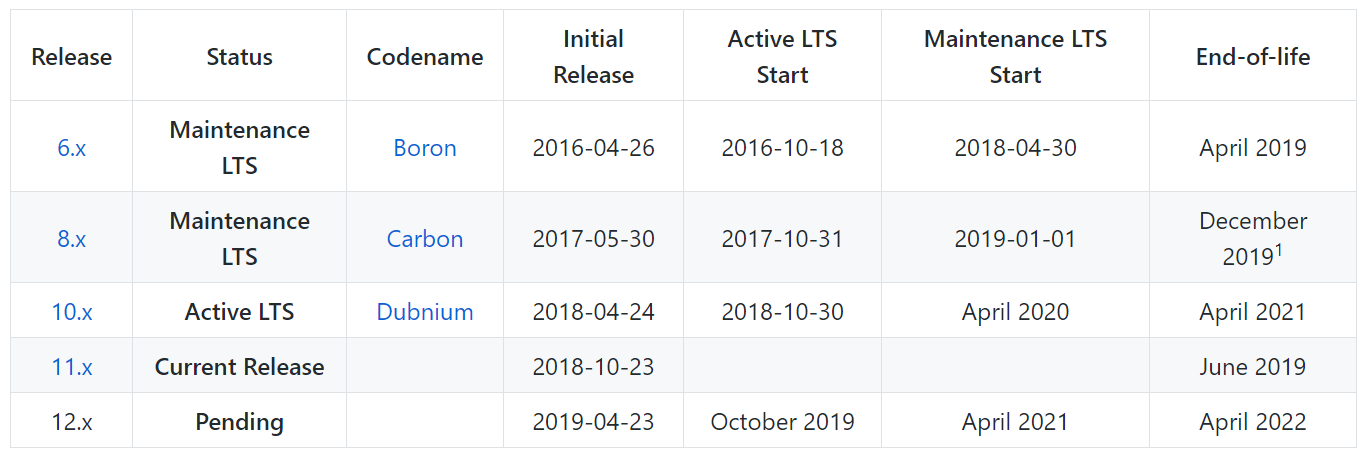
Wenn Sie eine 2016 geschriebene Anwendung bereitstellen müssen, stellen Sie sicher, dass Sie damit absolut keine Probleme haben. Version 6. * wird übrigens erst im April dieses Jahres nicht mehr unterstützt. Und vorne sind 8, 10, 11 und die kommenden 12.
Schwierigkeiten und Überraschungen beim Wechsel zu NodeJS
Ich beginne vielleicht mit der für mich aufregendsten Frage, wie HTML-Seiten in NodeJS gerendert werden. Aber denken wir zuerst daran, wie dies in PHP gemacht wird:
- Betten Sie HTML direkt in PHP-Code ein. Dies gilt auch für alle Neulinge, die MVC noch nicht erreicht haben. Und so wird es in WordPress gemacht, was absolut schrecklich ist.
- Verwenden Sie MVC, um die Interaktion des Entwicklers zu vereinfachen und das Projekt in Teile zu unterteilen. In Wirklichkeit erschwert dieser Ansatz jedoch nur zeitweise alles.
- Verwenden Sie eine Template-Engine. Die bequemste Option, aber nicht in PHP. Schauen Sie sich einfach die in Twig oder Blade vorgeschlagene Syntax mit geschweiften Klammern und Prozentsätzen an.
Ich bin ein leidenschaftlicher Gegner der Kombination oder Zusammenführung mehrerer Technologien. HTML muss separat existieren, Stile dafür separat, JavaScript separat (in React sieht dies im Allgemeinen monströs aus - HTML und JavaScript werden gemischt). Aus diesem Grund ist eine Vorlagen-Engine die ideale Option für Entwickler mit Vorlieben wie meinen. Ich musste lange nicht mehr nach einer Webanwendung auf NodeJS suchen und entschied mich für Jade (PugJS). Schätzen Sie einfach die Einfachheit der Syntax:
div.row.links div.col-lg-3.col-md-3.col-sm-4 h4.footer-heading . div.copyright div.copy-text 2017 - #{current_year} . div.contact-link span : a(href='mailto:hello@flaut.ru') hello@flaut.ru
Hier ist alles ganz einfach: Ich habe eine Vorlage geschrieben, sie in die Anwendung heruntergeladen, einmal kompiliert und dann zu jeder beliebigen Zeit an einem beliebigen Ort verwendet. Meiner Meinung nach ist die PugJS-Leistung etwa zweimal besser als das Rendern durch Einbetten von HTML in PHP-Code. Wenn früher in PHP eine statische Seite vom Server in etwa 200 bis 250 Millisekunden generiert wurde, beträgt diese Zeit jetzt etwa 90 bis 120 Millisekunden (wir sprechen nicht über das Rendern in PugJS, sondern über die Zeit, die von der Seitenanforderung bis zur Antwort des Servers an den Client mit bereitem HTML benötigt wird ) So sieht das Laden und Kompilieren von Vorlagen und ihren Komponenten beim Start der Anwendung aus:
const pugs = {} fs.readdirSync(__dirname + '/templates/').forEach(file => { if(file.endsWith('.pug')) { try { var filepath = __dirname + '/templates/' + file pugs[file.split('.pug')[0]] = pug.compile(fs.readFileSync(filepath, 'utf-8'), { filename: filepath }) } catch(e) { console.error(e) } } })
Es sieht unglaublich einfach aus, aber mit Jade war die Arbeit mit bereits kompiliertem HTML etwas komplex. Tatsache ist, dass zum Implementieren von Skripten auf der Seite eine asynchrone Funktion verwendet wird, die alle .js Dateien aus dem Verzeichnis .js und jedem von ihnen das Datum ihrer letzten Änderung hinzufügt. Die Funktion hat folgende Form:
for(let i = 0; i < files.length; i++) { let period = files[i].lastIndexOf('.')
Bei der Ausgabe erhalten wir ein Array von Objekten mit zwei Eigenschaften - dem Pfad zur Datei und der Zeit, zu der sie zuletzt im Zeitstempel bearbeitet wurde (zum Aktualisieren des Client-Cache). Das Problem ist, dass selbst beim Sammeln von Skriptdateien aus einem Verzeichnis alle streng alphabetisch in den Speicher geladen werden (da sie sich im Verzeichnis selbst befinden und die Dateien darin von oben nach unten gesammelt werden - vom ersten bis zum letzten). Dies führte dazu, dass die Datei app.js zuerst geladen wurde und bereits danach die Datei core.min.js mit Polyfills und Vendor.min.js ganz am Ende. Dieses Problem wurde ganz einfach gelöst - sehr banale Sortierung:
scripts.sort((a, b) => { if(a.path.includes('core.min.js')) { return -1 } else if(a.path.includes('vendor.min.js')) { return 0 } return 1 })
In PHP hatte alles ein monströses Aussehen in Form von Pfaden zu JS-Dateien, die in einer Zeichenfolge vorab geschrieben wurden. Einfach aber unpraktisch.
NodeJS behält seine Anwendung im RAM
Das ist ein großes Plus. Alles ist für mich so angeordnet, dass auf dem Server parallel und unabhängig voneinander zwei separate Sites vorhanden sind - die Version für den Entwickler und die Produktionsversion. Stellen Sie sich vor, ich habe einige Änderungen an den PHP-Dateien auf der Entwicklungssite vorgenommen und muss diese Änderungen in der Produktion einführen. Dazu müssen Sie den Server stoppen oder einen "sorry, tech. Work" -Stub einfügen und zu diesem Zeitpunkt Dateien einzeln aus dem Entwicklerordner in den Produktionsordner kopieren. Dies führt zu Ausfallzeiten und kann zum Verlust von Conversions führen. Der Vorteil der In-Memory-Anwendung in NodeJS besteht für mich darin, dass alle Änderungen an den Engine-Dateien erst nach dem Neustart vorgenommen werden. Dies ist sehr praktisch, da Sie alle erforderlichen Dateien mit den Änderungen kopieren und erst dann den Server neu starten können. Der Vorgang dauert nicht länger als 1-2 Sekunden und verursacht keine Ausfallzeiten.
Der gleiche Ansatz wird beispielsweise in Nginx verwendet. Sie bearbeiten zuerst die Konfiguration, überprüfen sie mit nginx -t und nehmen erst dann Änderungen mit dem service nginx reload
Clustering einer NodeJS-Anwendung
NodeJS hat ein sehr praktisches Tool - pm2 process manager . Wie führen wir normalerweise Anwendungen in Node aus? Wir gehen in die Konsole und schreiben den node index.js . Sobald wir die Konsole schließen, wird die Anwendung geschlossen. Zumindest passiert dies auf einem Server mit Ubuntu. Um dies zu vermeiden und die Anwendung immer am Laufen zu halten, fügen Sie sie einfach mit dem einfachen pm2 start index.js --name production . Das ist aber noch nicht alles. Das Tool ermöglicht die Überwachung ( pm2 monit ) und das Clustering von Anwendungen.
Erinnern wir uns, wie Prozesse in PHP organisiert sind. Angenommen, wir haben Nginx, das http-Anfragen bedient, und wir müssen die Anfrage an PHP weiterleiten. Sie können dies entweder direkt tun und dann wird bei jeder Anforderung ein neuer PHP-Prozess erzeugt, und wenn er abgeschlossen ist, wird er beendet. Oder Sie können einen Fastcgi-Server verwenden. Ich denke, jeder weiß, was es ist und es besteht keine Notwendigkeit, auf Details einzugehen, aber nur für den Fall, ich werde klarstellen, dass PHP-FPM am häufigsten als Fastcgi verwendet wird und seine Aufgabe darin besteht, viele PHP-Prozesse zu erzeugen, die jederzeit bereit sind, eine neue Anfrage anzunehmen und zu verarbeiten. Was ist der Nachteil dieses Ansatzes?
Das erste ist, dass Sie nie wissen, wie viel Speicher Ihre Anwendung verbraucht. Zweitens ist die maximale Anzahl von Prozessen immer begrenzt, und dementsprechend verwendet Ihre PHP-Anwendung bei einem starken Anstieg des Datenverkehrs entweder den gesamten verfügbaren Speicher und stürzt ab oder ruht sich an der zulässigen Prozessgrenze aus und beginnt, alte Prozesse zu beenden. Dies kann verhindert werden, indem ich nicht weiß, welcher Parameter in der PHP-FPM-Konfigurationsdatei dynamisch ist und dann zu diesem Zeitpunkt so viele Prozesse wie nötig erzeugt werden. Aber auch hier verbraucht ein elementarer DDoS-Angriff den gesamten Arbeitsspeicher und stellt Ihren Server auf. Oder ein Fehlerskript verbraucht beispielsweise den gesamten Arbeitsspeicher und der Server friert für einige Zeit ein (es gab Präzedenzfälle im Entwicklungsprozess).
Der grundlegende Unterschied bei NodeJS besteht darin, dass die Anwendung nicht mehr als 1,5 Gigabyte RAM verbrauchen kann. Es gibt keine Prozessbeschränkungen, es gibt nur ein Speicherlimit. Dies ermutigt Sie, so leichte Programme wie möglich zu schreiben. Darüber hinaus ist es sehr einfach, die Anzahl der Cluster zu berechnen, die wir uns leisten können, abhängig von der verfügbaren CPU-Ressource. Es wird empfohlen, nicht mehr als einen Cluster an jeden Kern zu hängen (genau wie in Nginx, nicht mehr als einen Worker pro CPU-Kern).

Ein Vorteil dieses Ansatzes besteht darin, dass PM2 nacheinander alle Cluster neu lädt. Zurück zum vorherigen Absatz, in dem es um Ausfallzeiten von 1-2 Sekunden während des Neustarts ging. Wenn Sie den Server im Cluster-Modus neu starten, tritt in Ihrer Anwendung keine Ausfallzeit von Millisekunden auf.
NodeJS ist ein gutes Schweizer Messer
Jetzt gibt es eine solche Situation, in der PHP als Sprache zum Schreiben von Websites fungiert und Python als Tool zum Crawlen dieser Websites fungiert. NodeJS ist 2 in 1, einerseits eine Gabel, andererseits ein Löffel. Sie können schnelle und leistungsstarke Anwendungen und Webcrawler auf demselben Server in derselben Anwendung schreiben. Klingt verlockend. Aber wie kann das realisiert werden, fragen Sie? Google selbst hat die offizielle Chromium API - Puppeteer eingeführt. Sie können Headless Chrome (einen Browser ohne Benutzeroberfläche - "Headless" Chrome) starten und den größtmöglichen Zugriff auf die Browser-API erhalten, um Seiten zu crawlen. Die einfachste und zugänglichste Art, mit Puppenspieler zu arbeiten .
In unserer VKontakte-Gruppe werden beispielsweise regelmäßig Rabatte und Sonderangebote für verschiedene Ziele aus den Städten der GUS veröffentlicht. Wir generieren Bilder für Beiträge im automatischen Modus, und um sie schön zu machen, brauchen wir schöne Bilder. Ich möchte mich nicht an verschiedene APIs binden und Konten auf Dutzenden von Websites erstellen. Deshalb habe ich eine einfache Anwendung geschrieben, die einen normalen Nutzer mit dem Google Chrome-Browser nachahmt, der mit Stock-Bildern auf der Website herumläuft und das durch das Keyword gefundene Bild zufällig aufnimmt. Früher habe ich dafür Python und BeautifulSoup verwendet, jetzt ist dies nicht mehr erforderlich. Das Hauptmerkmal und der Vorteil von Puppeteer ist, dass Sie sogar SPA-Websites problemlos betrügen können, da Ihnen ein vollwertiger Browser zur Verfügung steht, der JavaScript-Code auf Websites versteht und ausführt. Es ist schmerzlich einfach:
const browser = await puppeteer.launch({headless: true, args:['--no-sandbox']}) const page = (await browser.pages())[0] await page.goto(`https://pixabay.com/photos/search/${imageKeyword}/?cat=buildings&orientation=horizontal`, { waitUntil: 'networkidle0' })
Also haben wir in 3 Codezeilen den Browser gestartet und die Site-Seite mit Archivbildern geöffnet. Jetzt können wir einen zufälligen Block mit dem Bild auf der Seite auswählen und ihm eine Klasse hinzufügen, in der wir später auf die gleiche Weise umblättern und direkt mit dem Bild selbst zur Seite gehen können, um sie weiter zu laden:
var imagesLength = await page.evaluate(() => { var photos = document.querySelectorAll('.search_results > .item') if(photos.length > 0) { photos[Math.floor(Math.random() * photos.length)].className += ' --anomaly_selected' } return photos.length })
Erinnern Sie sich daran, wie viel Code erforderlich wäre, um dies in PhantomJS zu schreiben (das übrigens geschlossen wurde und eng mit dem Puppeteer-Entwicklungsteam zusammenarbeitete). Kann solch ein wunderbares Tool jemanden davon abhalten, zu NodeJS zu wechseln?
NodeJS bietet grundlegende Asynchronität
Dies kann als großer Vorteil von NodeJS und JavaScript angesehen werden, insbesondere mit dem Aufkommen von async / await in ES2017. Im Gegensatz zu PHP, wo jeder Anruf synchron getätigt wird. Ich werde ein einfaches Beispiel geben. Früher wurden in der Suchmaschine Seiten auf dem Server generiert, aber auf der Seite, die bereits im Client vorhanden war, musste etwas mit JavaScript angezeigt werden. Zu diesem Zeitpunkt war Yandex jedoch noch nicht in der Lage, JavaScript auf Websites zu verwenden, und musste einen Snapshot-Mechanismus (Seiten-Snapshots) speziell dafür implementieren. mit Prerender. Schnappschüsse wurden auf unserem Server gespeichert und auf Anfrage an den Roboter gesendet. Das Dilemma bestand darin, dass diese Bilder innerhalb von 3 bis 5 Sekunden erstellt wurden. Dies ist völlig inakzeptabel und kann das Ranking der Website in den Suchergebnissen beeinflussen. Um dieses Problem zu lösen, wurde ein einfacher Algorithmus erfunden: Wenn der Roboter eine Seite anfordert, von der wir bereits einen Schnappschuss haben, geben wir ihm einfach den vorhandenen Schnappschuss. Anschließend führen wir den Vorgang aus, um im Hintergrund einen neuen Schnappschuss zu erstellen und ihn zu ersetzen bereits verfügbar. Wie es in PHP gemacht wurde:
exec('/usr/bin/php ' . __DIR__ . '/snapshot.php -a ' . $affiliation_type . ' -l ' . urlencode($full_uri) . ' > /dev/null 2>/dev/null &');
Mach das niemals.
In NodeJS kann dies durch Aufrufen der asynchronen Funktion erreicht werden:
async function saveSnapshot() { getSnapshot().then((res) => { db.saveSnapshot().then((status) => { if(status.err) console.error(err) }) }) } saveSnapshot()
Kurz gesagt, Sie versuchen nicht, die Synchronität zu umgehen, sondern entscheiden, wann die synchrone Codeausführung und wann die asynchrone Codeausführung verwendet werden soll. Und es ist wirklich praktisch. Besonders wenn Sie die Möglichkeiten von Promise.all () kennenlernen
Die Flugsuchmaschine selbst ist so konzipiert, dass sie eine Anfrage an einen zweiten Server sendet, der Daten sammelt und aggregiert, und sich dann an sie wendet, um bereitgestellte Daten zu erhalten. Richtungsseiten werden verwendet, um organischen Verkehr anzuziehen.
Für die Abfrage "Flüge Moskau St. Petersburg" wird beispielsweise eine Seite mit der Adresse / tickets / moscow / saint-petersburg / ausgegeben , die Daten benötigt:
- Flugpreise in diese Richtung für den laufenden Monat
- Flugpreise in diese Richtung für das kommende Jahr (Durchschnittspreis für jeden Monat für die nächsten 12 Monate)
- Planen Sie Flüge in diese Richtung
- Beliebte Ziele aus der Versandstadt - aus Moskau (zum Verknüpfen)
- Beliebte Ziele aus der Ankunftsstadt sind St. Petersburg (zum Verknüpfen)
In PHP wurden alle diese Anforderungen synchron ausgeführt - nacheinander. Die durchschnittliche API-Antwortzeit pro Anforderung beträgt 150-200 Millisekunden. Wir multiplizieren 200 mit 5 und erhalten im Durchschnitt eine Sekunde, um Anforderungen an den Server mit Daten zu erfüllen. NodeJS hat eine großartige Funktion namens Promise.all , die alle Anforderungen parallel ausführt, das Ergebnis jedoch einzeln schreibt. Der Ausführungscode für alle fünf der oben genannten Anforderungen würde beispielsweise folgendermaßen aussehen:
var [montlyPrices, yearlyPrices, flightsSchedule, originPopulars, destPopulars] = await Promise.all([ getMontlyPrices(), getYearlyPrices(), getFlightSchedule(), getOriginPopulars(), getDestPopulars() ])
Und wir erhalten alle Daten in 200-300 Millisekunden, wodurch sich die Datengenerierungszeit für die Seite von 1-1,5 Sekunden auf ~ 500 Millisekunden verringert.
Fazit
Der Wechsel von PHP zu NodeJS hat mir geholfen, mich mit asynchronem JavaScript vertraut zu machen, zu lernen, wie man mit Versprechungen arbeitet und asynchron / wartet. Nach dem Umschreiben der Engine wurde die Seitenladegeschwindigkeit optimiert und unterschied sich erheblich von den Ergebnissen, die die Engine in PHP zeigte. In diesem Artikel könnten wir auch darüber sprechen, wie einfache Module verwendet werden, um mit dem Cache (Redis) und dem pg-Versprechen (PostgreSQL) in NodeJS zu arbeiten und sie mit Memcached und php-pgsql zu vergleichen, aber dieser Artikel erwies sich als ziemlich umfangreich. Und da sie mein "Talent" zum Schreiben kannte, stellte sich heraus, dass sie schlecht strukturiert war. Der Zweck dieses Artikels ist es, die Aufmerksamkeit von Entwicklern auf sich zu ziehen, die noch mit PHP arbeiten und sich der Vorteile von NodeJS und der Entwicklung webbasierter Anwendungen nicht bewusst sind, indem ein Beispiel eines realen Projekts verwendet wird, das einmal in PHP geschrieben wurde, jedoch aufgrund von Präferenzen sein Besitzer ging zu einer anderen Plattform.
Ich hoffe, dass ich meine Gedanken vermitteln konnte und mehr oder weniger strukturiert war, um sie in diesem Material auszudrücken. Zumindest habe ich es versucht :)
Schreiben Sie Kommentare - freundlich oder wütend. Ich werde jede konstruktive beantworten.