Das letzte Mal haben wir über Datenkonsistenz gesprochen, den Unterschied zwischen verschiedenen Ebenen der Transaktionsisolation mit den Augen des Benutzers untersucht und herausgefunden, warum es wichtig ist, dies zu wissen. Jetzt lernen wir, wie PostgreSQL die Snapshot-basierte Isolierung und Multi-Versionierung implementiert.
In diesem Artikel wird untersucht, wie sich Daten physisch in Dateien und Seiten befinden. Dies führt uns vom Thema Isolation weg, aber ein solcher Exkurs ist notwendig, um weiteres Material zu verstehen. Wir müssen verstehen, wie die Datenspeicherung auf niedriger Ebene funktioniert.
Beziehungen
Wenn Sie sich die Tabellen und Indizes ansehen, stellt sich heraus, dass sie ähnlich angeordnet sind. Sowohl das als auch andere Basisobjekte, die einige Daten enthalten, die aus Linien bestehen.
Die Tatsache, dass die Tabelle aus Zeilen besteht, steht außer Zweifel. Für den Index ist dies weniger offensichtlich. Stellen Sie sich jedoch einen B-Baum vor: Er besteht aus Knoten, die indizierte Werte und Verknüpfungen zu anderen Knoten oder zu Tabellenzeilen enthalten. Diese Knoten können als Indexlinien betrachtet werden - tatsächlich so wie sie sind.
Tatsächlich gibt es immer noch eine Reihe von Objekten, die auf ähnliche Weise angeordnet sind: Sequenzen (im Wesentlichen einzeilige Tabellen), materialisierte Ansichten (im Wesentlichen Tabellen, die sich an die Abfrage erinnern). Und dann gibt es die üblichen Ansichten, die selbst keine Daten speichern, aber in allen anderen Sinnen Tabellen ähnlich sind.
Alle diese Objekte in PostgreSQL werden als allgemeine Wortbeziehung
bezeichnet . Das Wort ist äußerst unglücklich, weil es ein Begriff aus der relationalen Theorie ist. Sie können eine Parallele zwischen der Beziehung und der Tabelle (Ansicht) ziehen, aber sicherlich nicht zwischen der Beziehung und dem Index. Aber es ist so passiert: Die akademischen Wurzeln von PostgreSQL machen sich bemerkbar. Ich denke, dass es zuerst Tabellen und Ansichten genannt wurde und der Rest im Laufe der Zeit wuchs.
Der Einfachheit halber werden wir nur über Tabellen und Indizes sprechen, aber der Rest der
Beziehungen ist genau gleich strukturiert.
Ebenen (Gabeln) und Dateien
Normalerweise hat jede Beziehung mehrere
Schichten (Gabeln). Es gibt verschiedene Arten von Ebenen, von denen jede eine bestimmte Art von Daten enthält.
Wenn es eine Ebene gibt, wird sie zunächst durch eine einzelne
Datei dargestellt . Der Dateiname besteht aus einer numerischen Kennung, zu der die dem Namen der Ebene entsprechende Endung hinzugefügt werden kann.
Die Datei wächst allmählich und wenn ihre Größe 1 GB erreicht, wird die nächste Datei derselben Ebene erstellt (solche Dateien werden manchmal als
Segmente bezeichnet ). Die Segmentnummer wird an das Ende des Dateinamens angehängt.
Die Beschränkung der Dateigröße auf 1 GB ist in der Vergangenheit aufgetreten, um verschiedene Dateisysteme zu unterstützen, von denen einige nicht mit großen Dateien funktionieren können. Die Einschränkung kann beim
./configure --with-segsize PostgreSQL geändert werden (
./configure --with-segsize ).
Somit können mehrere Dateien einer Beziehung auf einer Festplatte entsprechen. Für einen kleinen Tisch gibt es beispielsweise 3 davon.
Alle Dateien von Objekten, die zu einem Tabellenbereich und einer Datenbank gehören, werden in einem Verzeichnis abgelegt. Dies muss berücksichtigt werden, da Dateisysteme normalerweise mit einer großen Anzahl von Dateien in einem Verzeichnis nicht sehr gut funktionieren.
Beachten Sie nur, dass die Dateien wiederum in
Seiten (oder
Blöcke ) unterteilt sind, normalerweise 8 KB. Wir werden über die interne Struktur der folgenden Seiten sprechen.
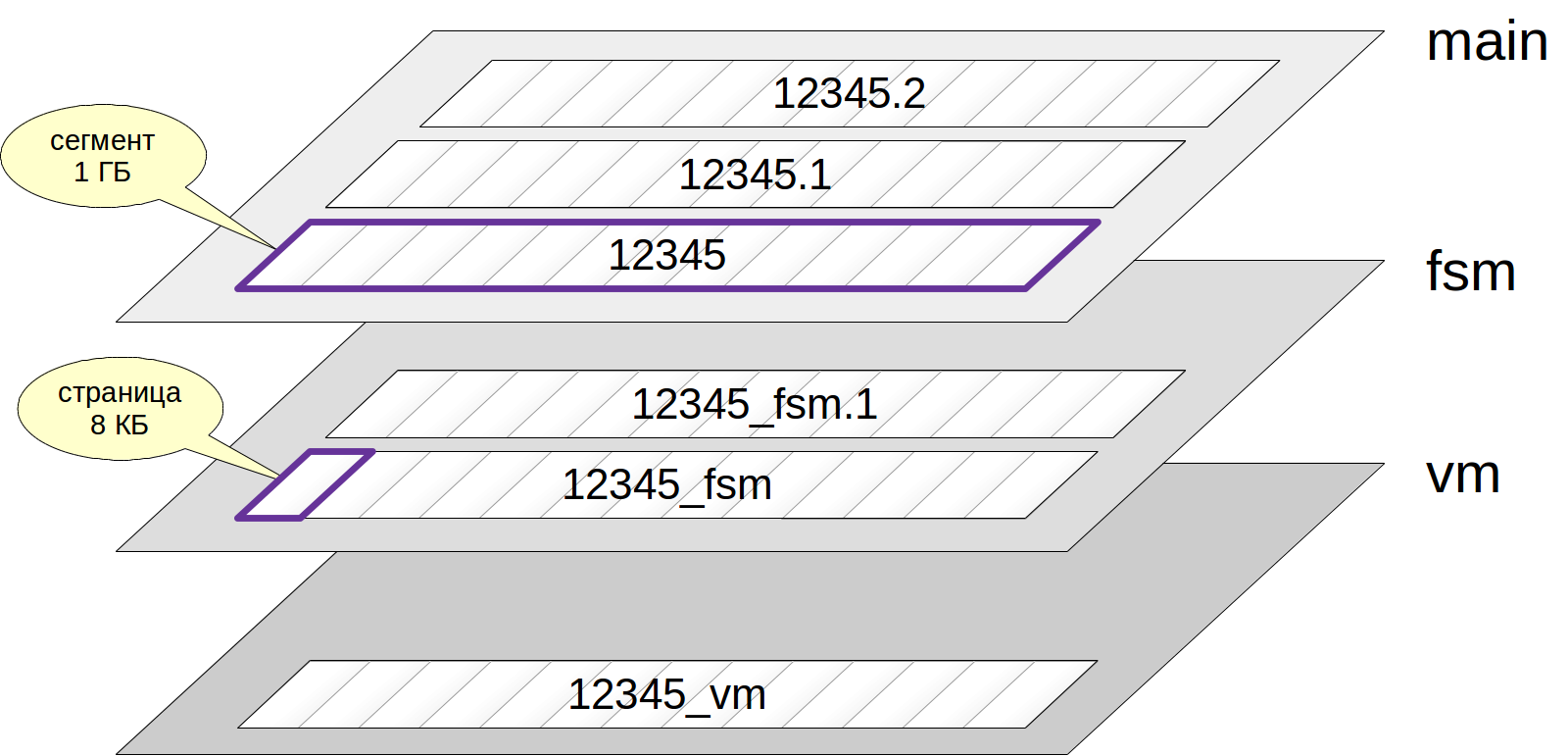
Schauen wir uns nun die Arten von Ebenen an.
Die Hauptschicht sind die Daten selbst: dieselbe Tabelle oder dieselben Indexzeilen. Die Hauptebene ist für jede Beziehung vorhanden (mit Ausnahme von Darstellungen, die keine Daten enthalten).
Die Namen der Dateien in der Hauptebene bestehen nur aus einer numerischen Kennung. Hier ist ein Beispielpfad zu der Tabellendatei, die wir zuletzt erstellt haben:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
Woher kommen diese Kennungen? Das Basisverzeichnis entspricht dem Tabellenbereich pg_default, das nächste Unterverzeichnis entspricht der Datenbank und die Datei, an der wir interessiert sind, befindet sich bereits darin:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
Der Pfad ist relativ und wird aus dem Datenverzeichnis (PGDATA) gezählt. Darüber hinaus werden fast alle Pfade in PostgreSQL von PGDATA aus gezählt. Dank dessen können Sie PGDATA sicher an einen anderen Ort übertragen - es enthält nichts (es sei denn, Sie müssen möglicherweise den Pfad zu den Bibliotheken in LD_LIBRARY_PATH konfigurieren).
Wir schauen weiter im Dateisystem:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
Eine Initialisierungsebene ist nur für nicht journalisierte Tabellen (erstellt mit UNLOGGED) und deren Indizes vorhanden. Solche Objekte unterscheiden sich nicht von normalen Objekten, außer dass Aktionen mit ihnen nicht im Voraufzeichnungsprotokoll aufgezeichnet werden. Aus diesem Grund ist die Arbeit mit ihnen schneller, aber im Falle eines Fehlers ist es unmöglich, Daten in einem konsistenten Zustand wiederherzustellen. Daher löscht PostgreSQL bei der Wiederherstellung einfach alle Ebenen solcher Objekte und schreibt die Initialisierungsebene an die Stelle der Hauptebene. Das Ergebnis ist ein "Dummy". Wir werden ausführlich über Journaling sprechen, aber in einem anderen Zyklus.
Die Kontentabelle wird protokolliert, daher gibt es keine Initialisierungsebene dafür. Für das Experiment können Sie die Protokollierung deaktivieren:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
Die Möglichkeit, das Journaling im laufenden Betrieb zu aktivieren und zu deaktivieren, wie aus dem Beispiel ersichtlich, umfasst das Überschreiben von Daten in Dateien mit unterschiedlichen Namen.
Die Initialisierungsebene hat denselben Namen wie die Hauptebene, jedoch mit dem Suffix "_init":
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
Karte des freien Speicherplatzes (
Karte des freien Speicherplatzes ) - eine Ebene, in der sich innerhalb der Seiten ein leerer Speicherplatz befindet. Dieser Ort ändert sich ständig: Wenn neue Versionen von Zeichenfolgen hinzugefügt werden, nimmt sie während der Reinigung ab - sie nimmt zu. Die Freiraumkarte wird beim Einfügen neuer Zeilenversionen verwendet, um schnell eine geeignete Seite zu finden, auf die die hinzuzufügenden Daten passen.
Die Freiraumkarte hat das Suffix "_fsm". Die Datei wird jedoch nicht sofort angezeigt, sondern nur bei Bedarf. Der einfachste Weg, dies zu erreichen, besteht darin, den Tisch zu reinigen (warum - lassen Sie uns rechtzeitig sprechen):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
Eine Sichtbarkeitskarte ist eine Ebene, in der Seiten, die nur aktuelle Versionen von Zeichenfolgen enthalten, mit einem Bit markiert sind. Grob gesagt bedeutet dies, dass beim Versuch einer Transaktion, eine Zeile von einer solchen Seite zu lesen, die Zeile angezeigt werden kann, ohne ihre Sichtbarkeit zu überprüfen. Wie dies geschieht, werden wir in den folgenden Artikeln im Detail untersuchen.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Seiten
Wie bereits erwähnt, werden Dateien logisch in Seiten unterteilt.
Normalerweise ist eine Seite 8 KB groß. Die Größe kann innerhalb einiger Grenzen geändert werden (16 KB oder 32 KB), jedoch nur während der Montage (
./configure --with-blocksize ). Die zusammengestellte und laufende Instanz kann mit Seiten nur einer Größe arbeiten.
Unabhängig davon, zu welcher Ebene die Dateien gehören, werden sie vom Server ungefähr auf die gleiche Weise verwendet. Seiten werden zuerst in den Puffercache eingelesen, wo Prozesse sie lesen und ändern können. Bei Bedarf werden die Seiten dann auf die Festplatte zurückgeschoben.
Jede Seite hat ein internes Markup und enthält im Allgemeinen die folgenden Abschnitte:
0 + ----------------------------------- +
| Überschrift |
24 + ----------------------------------- +
| Array von Zeigern auf Versionszeichenfolgen |
niedriger + ----------------------------------- +
| freier Speicherplatz |
obere + ----------------------------------- +
| Zeilenversionen |
spezielle + ----------------------------------- +
| Sonderbereich |
Seitengröße + ----------------------------------- +
Die Größe dieser Abschnitte lässt sich mit der pageinspect-Erweiterung „Forschung“ leicht herausfinden:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Hier sehen wir uns den
Titel der allerersten (Null-) Seite der Tabelle an. Neben der Größe der verbleibenden Bereiche enthält die Kopfzeile weitere Informationen zur Seite, die uns jedoch noch nicht interessieren.
Am Ende der Seite befindet sich ein
spezieller Bereich , in unserem Fall leer. Es wird nur für Indizes und dann nicht für alle verwendet. Der "Boden" hier entspricht dem Bild; Vielleicht wäre es richtiger, „an hohen Adressen“ zu sagen.
Dem speziellen Bereich folgen
die Zeilenversionen - genau die Daten, die wir in der Tabelle speichern, sowie einige Overhead-Informationen.
Am oberen Rand der Seite, unmittelbar nach der Überschrift, befindet sich das Inhaltsverzeichnis: ein
Array von Zeigern auf die Version der auf der Seite verfügbaren Zeilen.
Zwischen Versionen von Linien und Zeigern kann
freier Speicherplatz vorhanden sein (der in der Freiraumkarte markiert ist). Beachten Sie, dass es innerhalb der Seite keine Fragmentierung gibt. Der gesamte freie Speicherplatz wird immer durch ein Fragment dargestellt.
Zeiger
Warum sind Zeiger auf String-Versionen notwendig? Tatsache ist, dass sich Indexzeilen irgendwie auf die Version der Zeilen in der Tabelle beziehen müssen. Es ist klar, dass der Link die Dateinummer, die Seitenzahl in der Datei und einige Angaben zur Version der Zeile enthalten sollte. Ein Versatz vom Anfang der Seite könnte als solche Anzeige verwendet werden, dies ist jedoch unpraktisch. Wir könnten die Version der Zeile nicht innerhalb der Seite verschieben, da dadurch vorhandene Links beschädigt würden. Dies würde zu einer Fragmentierung des Raums innerhalb der Seiten und anderen unangenehmen Folgen führen. Daher bezieht sich der Index auf die Indexnummer und der Zeiger auf die aktuelle Position der Zeilenversion auf der Seite. Es stellt sich heraus, indirekte Adressierung.
Jeder Zeiger belegt genau 4 Bytes und enthält:
- Link zur Version des Strings;
- die Länge dieser Version der Zeichenfolge;
- mehrere Bits, die den Versionsstatus einer Zeichenfolge bestimmen.
Datenformat
Das Datenformat auf der Festplatte stimmt vollständig mit der Darstellung der Daten im RAM überein. Die Seite wird "wie sie ist" ohne Transformationen in den Puffercache eingelesen. Daher sind Datendateien von einer Plattform nicht mit anderen Plattformen kompatibel.
In der x86-Architektur wird beispielsweise die Bytereihenfolge von der niedrigstwertigen zur höchsten (Little-Endian) übernommen, z / Architecture verwendet die umgekehrte Reihenfolge (Big-Endian) und in ARM die Switch-Reihenfolge.
Viele Architekturen bieten Datenausrichtung über Maschinenwortgrenzen hinweg. Auf einem x86-32-Bit-System werden beispielsweise Ganzzahlen (Ganzzahltyp, belegt 4 Byte) am Rand von 4-Byte-Wörtern sowie Gleitkommazahlen mit doppelter Genauigkeit (Typ mit doppelter Genauigkeit, 8 Byte) ausgerichtet. Bei einem 64-Bit-System werden Doppelwerte am Rand von 8-Byte-Wörtern ausgerichtet. Dies ist ein weiterer Grund für die Inkompatibilität.
Aufgrund der Ausrichtung hängt die Größe der Tabellenzeile von der Reihenfolge der Felder ab. Normalerweise ist dieser Effekt nicht sehr auffällig, kann aber in einigen Fällen zu einer signifikanten Vergrößerung führen. Wenn Sie beispielsweise die Felder char (1) und integer vertauscht platzieren, werden normalerweise 3 Bytes zwischen ihnen verschwendet. Mehr dazu erfahren
Sie in Nikolai Shaplovs Präsentation "
What's Inside It ".
String- und TOAST-Versionen
Wir werden beim nächsten Mal ausführlich darauf eingehen, wie Versionen von Zeichenfolgen von innen angeordnet sind. Bisher ist für uns nur wichtig, dass jede Version vollständig auf eine Seite passt: PostgreSQL bietet keine Möglichkeit, die Zeile auf der nächsten Seite "fortzusetzen". Stattdessen wird eine Technologie namens TOAST (The Oversized Attributes Storage Technique) verwendet. Der Name selbst legt nahe, dass die Schnur in Toast geschnitten werden kann.
Im Ernst, TOAST beinhaltet mehrere Strategien. "Lange" Attributwerte können an eine separate Servicetabelle gesendet werden, die zuvor in kleine Toaststücke geschnitten wurde. Eine andere Möglichkeit besteht darin, den Wert so zu komprimieren, dass die Version der Zeile weiterhin auf eine normale Tabellenseite passt. Und es ist sowohl das als auch das andere möglich: zuerst zu komprimieren und erst dann zu schneiden und zu senden.
Falls erforderlich, wird für jede Haupttabelle eine separate TOAST-Tabelle (und ein spezieller Index dafür) für alle Attribute erstellt. Die Notwendigkeit wird durch das Vorhandensein potenziell langer Attribute in der Tabelle bestimmt. Wenn eine Tabelle beispielsweise eine Spalte vom Typ "numerisch" oder "Text" enthält, wird sofort eine TOAST-Tabelle erstellt, auch wenn keine langen Werte verwendet werden.
Da es sich bei der TOAST-Tabelle im Wesentlichen um eine reguläre Tabelle handelt, weist sie immer noch die gleichen Ebenen auf. Dies verdoppelt die Anzahl der Dateien, die die Tabelle "bedienen".
Strategien werden zunächst durch Spaltendatentypen bestimmt. Sie können sie mit dem Befehl
\d+ in psql anzeigen. Da jedoch auch viele andere Informationen angezeigt werden, verwenden wir die Anforderung an das Systemverzeichnis:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
Die Namen der Strategien haben folgende Bedeutung:
- plain - TOAST wird nicht verwendet (wird für offensichtlich „kurze“ Datentypen wie Integer verwendet);
- erweitert - Komprimierung und Speicherung in einer separaten TOAST-Tabelle sind zulässig.
- extern - lange Werte werden unkomprimiert in der TOAST-Tabelle gespeichert;
- main - long - Werte werden zuerst und nur in der TOAST - Tabelle komprimiert, wenn die Komprimierung nicht geholfen hat.
Im Allgemeinen ist der Algorithmus wie folgt. PostgreSQL möchte, dass mindestens 4 Zeilen auf eine Seite passen. Wenn die Größe der Zeile den vierten Teil der Seite unter Berücksichtigung der Überschrift überschreitet (bei einer normalen 8-KB-Seite sind dies 2040 Byte), sollte TOAST auf einen Teil der Werte angewendet werden. Wir handeln in der unten beschriebenen Reihenfolge und halten an, sobald die Leitung den Schwellenwert nicht mehr überschreitet:
- Zunächst sortieren wir Attribute mit externen und erweiterten Strategien und wechseln von der längsten zur kürzeren. Erweiterte Attribute werden komprimiert (sofern dies Auswirkungen hat). Wenn der Wert selbst ein Viertel der Seite überschreitet, wird er sofort an die TOAST-Tabelle gesendet. Externe Attribute werden auf die gleiche Weise behandelt, jedoch nicht komprimiert.
- Wenn nach dem ersten Durchgang die Version der Zeile immer noch nicht passt, senden wir die verbleibenden Attribute mit den externen und erweiterten Strategien an die TOAST-Tabelle.
- Wenn dies auch nicht hilft, versuchen Sie, die Attribute mit der Hauptstrategie zu komprimieren, während Sie sie auf der Tabellenseite belassen.
- Und nur wenn die Zeile danach noch nicht kurz genug ist, werden die Hauptattribute an die TOAST-Tabelle gesendet.
Manchmal kann es nützlich sein, die Strategie für einige Spalten zu ändern. Wenn beispielsweise im Voraus bekannt ist, dass die Daten in der Spalte nicht komprimiert sind, können Sie eine externe Strategie dafür festlegen. Dies erspart unnötige Komprimierungsversuche. Dies geschieht wie folgt:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
Wenn wir die Anfrage wiederholen, erhalten wir:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
TOAST-Tabellen und -Indizes befinden sich in einem separaten pg_toast-Schema und sind daher normalerweise nicht sichtbar. Für temporäre Tabellen wird das Schema pg_toast_temp_N verwendet, ähnlich dem üblichen Schema pg_temp_N
.Wenn gewünscht, macht sich natürlich niemand die Mühe, einen Blick auf die internen Mechanismen des Prozesses zu werfen. Angenommen, die Kontentabelle enthält drei potenziell lange Attribute, daher muss eine TOAST-Tabelle vorhanden sein. Da ist sie:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
Es ist logisch, dass für die „Toasts“, in die die Linie geschnitten wird, die einfache Strategie angewendet wird: TOAST der zweiten Ebene existiert nicht.
Der PostgreSQL-Index wird sorgfältiger ausgeblendet, ist aber auch leicht zu finden:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
Die Client-Spalte verwendet die erweiterte Strategie: Die darin enthaltenen Werte werden komprimiert. Überprüfen Sie:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
Die TOAST-Tabelle enthält nichts: Wiederholte Zeichen werden perfekt komprimiert, und danach passt der Wert in eine reguläre Tabellenseite.
Lassen Sie den Client-Namen nun aus zufälligen Zeichen bestehen:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Diese Sequenz kann nicht komprimiert werden und fällt in die TOAST-Tabelle:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
Wie Sie sehen können, werden die Daten in Fragmente von 2000 Bytes geschnitten.
Beim Zugriff auf einen "langen" Wert stellt PostgreSQL automatisch, für die Anwendung transparent, den ursprünglichen Wert wieder her und gibt ihn an den Client zurück.
Natürlich werden ziemlich viele Ressourcen für die Komprimierung in Scheiben und die anschließende Wiederherstellung aufgewendet. Daher ist das Speichern umfangreicher Daten in PostgreSQL keine gute Idee, insbesondere wenn sie aktiv verwendet werden und für sie keine Transaktionslogik erforderlich ist (Beispiel: gescannte Originale von Buchhaltungsdokumenten). Eine rentablere Alternative könnte darin bestehen, solche Daten im Dateisystem und im DBMS die Namen der entsprechenden Dateien zu speichern.
Eine TOAST-Tabelle wird nur verwendet, wenn auf einen „langen“ Wert verwiesen wird. Darüber hinaus verfügt die Toasttabelle über eine eigene Versionierung: Wenn sich die Datenaktualisierung nicht auf den Wert "long" auswirkt, verweist die neue Version der Zeile auf denselben Wert in der TOAST-Tabelle - dies spart Platz.
Beachten Sie, dass TOAST nur für Tabellen funktioniert, nicht jedoch für Indizes. Dadurch wird die Größe der indizierten Schlüssel begrenzt.
Weitere Informationen zur internen Datenorganisation finden Sie in der Dokumentation .
Fortsetzung folgt .