Das tidyr- Paket ist Teil des Kerns einer der beliebtesten Bibliotheken in der R-Sprache - tidyverse .
Der Hauptzweck des Pakets besteht darin, die Daten in ein ordentliches Erscheinungsbild zu bringen.
Auf Habré gibt es bereits eine Publikation zu diesem Paket, die jedoch aus dem Jahr 2015 stammt. Und ich möchte Ihnen über die wichtigsten Änderungen berichten, die der Autor Hadley Wickham vor einigen Tagen angekündigt hat.
SJK : Werden die Funktionen versammeln () und verbreiten () nicht mehr unterstützt?
Hadley Wickham : Bis zu einem gewissen Grad. Wir werden die Verwendung dieser Funktionen nicht mehr empfehlen und Fehler in ihnen korrigieren, sie werden jedoch im aktuellen Status weiterhin im Paket vorhanden sein.
Inhalt
TidyData-Konzept
Der Zweck von tidyr ist es, Ihnen zu helfen, die Daten zu einem sogenannten ordentlichen Erscheinungsbild zu bringen. Genaue Daten sind Daten, bei denen:
- Jede Variable befindet sich in einer Spalte.
- Jede Beobachtung ist eine Linie.
- Jeder Wert ist eine Zelle.
Die Daten, die für aufgeräumte Daten bereitgestellt werden, sind während der Analyse viel einfacher und bequemer zu bearbeiten.
Die Hauptfunktionen des tidyr-Pakets
tidyr enthält eine Reihe von Funktionen zum Transformieren von Tabellen:
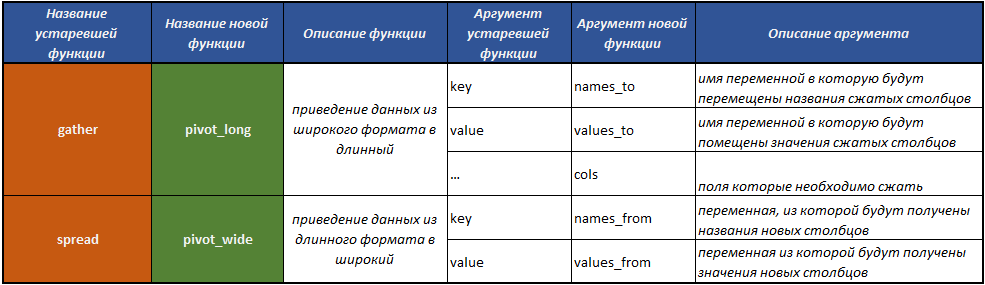
fill() - Füllen Sie die fehlenden Werte in der Spalte mit den vorherigen Werten aus.separate() - teilt ein Feld durch ein Trennzeichen in mehrere auf;unite() - führt die Operation des Kombinierens mehrerer Felder zu einem aus, der Umkehrung der Funktion separate() ;pivot_longer() - eine Funktion, die Daten von einem breiten Format in ein langes konvertiert;pivot_wider() - eine Funktion, die Daten von einem langen Format in ein breites konvertiert. Die Operation ist das Gegenteil von der pivot_longer() .gather() veraltet - eine Funktion, die Daten von einem breiten Format in ein langes konvertiert;spread() veraltet - eine Funktion, die Daten von einem langen Format in ein breites konvertiert. Die Operation ist das Gegenteil von der, die gather() Funktion gather() ausführt.
Bisher spread() für diese Art der Transformation die Funktionen gather() und spread() verwendet. Im Laufe der Jahre, in denen diese Funktionen existierten, stellte sich heraus, dass für die meisten Benutzer, einschließlich des Autors des Pakets, die Namen dieser Funktionen und ihre Argumente nicht ganz offensichtlich waren und es schwierig war, sie zu finden und zu verstehen, welche dieser Funktionen den Datumsrahmen von weit nach lang bringt Format und umgekehrt.
In diesem Zusammenhang wurden tidyr zwei neue wichtige Funktionen hinzugefügt, mit denen Datumsrahmen transformiert werden sollen.
Die neuen Funktionen pivot_longer() und pivot_wider() wurden von einigen Funktionen des von John Mount und Nina Zumel erstellten cdata- Pakets inspiriert.
Installation der aktuellsten Version von tidyr 0.8.3.9000
Verwenden Sie den folgenden Code, um die neue, aktuellste Version des Pakets tidyr 0.8.3.9000 zu installieren , in der neue Funktionen verfügbar sind.
devtools::install_github("tidyverse/tidyr")
Zum Zeitpunkt des Schreibens sind diese Funktionen nur in der Entwicklungsversion des Pakets auf GitHub verfügbar.
Wechseln Sie zu neuen Funktionen
Tatsächlich ist es nicht schwierig, alte Skripte zu übertragen, um mit neuen Funktionen zu arbeiten. Zum besseren Verständnis werde ich ein Beispiel aus der Dokumentation alter Funktionen nehmen und zeigen, wie dieselben Operationen mit den neuen pivot_*() werden.
Konvertieren Sie ein breites in ein langes Format.
Beispielcode aus der Dokumentation der Erfassungsfunktion # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
Konvertieren eines langen Formats in ein breites Format.
Beispielcode aus der Dokumentation der Spread-Funktion # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
Weil In den obigen Beispielen für die Arbeit mit pivot_longer() und pivot_wider() sind in den Quellen der Quellentabelle keine Spalten in den Argumenten names_to und values_to aufgeführt. Ihre Namen müssen in Anführungszeichen angegeben werden.
Die Tabelle, mit deren Hilfe Sie am einfachsten herausfinden, wie Sie mit dem neuen Tidyr- Konzept arbeiten können.
Anmerkung des Autors
Der gesamte folgende Text ist anpassungsfähig, ich würde sogar eine kostenlose Übersetzung der Vignette von der offiziellen Website der Tidyverse-Bibliothek sagen.
pivot_longer () - verlängert Datensätze, indem die Anzahl der Spalten verringert und die Anzahl der Zeilen erhöht wird.

Um die im Artikel vorgestellten Beispiele auszuführen, müssen Sie zuerst die erforderlichen Pakete verbinden:
library(tidyr) library(dplyr) library(readr)
Angenommen, wir haben eine Tabelle mit den Ergebnissen einer Umfrage, in der (unter anderem) Personen nach ihrer Religion und ihrem Jahreseinkommen befragt wurden:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
Diese Tabelle enthält die Religionsdaten der Befragten in Zeilen, und die Einkommensniveaus sind auf die Spaltennamen verteilt. Die Anzahl der Befragten aus jeder Kategorie wird in den Zellwerten an der Schnittstelle von Religion und Einkommensniveau gespeichert. Verwenden pivot_longer() einfach pivot_longer() um die Tabelle in ein ordentliches, korrektes Format zu bringen:
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
Argumente für pivot_longer()
- Das erste Argument, cols , beschreibt, welche Spalten zusammengeführt werden sollen. In diesem Fall alle Spalten außer Zeit .
- Das Argument names_to gibt den Namen der Variablen an, die aus den von uns kombinierten Spaltennamen erstellt wird.
- values_to gibt den Namen der Variablen an, die aus den in den Zellenwerten der verknüpften Spalten gespeicherten Daten erstellt wird.
Technische Daten
Dies ist die neue Funktionalität des tidyr- Pakets, die zuvor bei der Arbeit mit veralteten Funktionen nicht verfügbar war.
Eine Spezifikation ist ein Datenrahmen, dessen jede Zeile einer Spalte in einem neuen Ausgabedatum entspricht, und zwei spezielle Spalten, die beginnen mit:
- .name enthält den ursprünglichen Namen der Spalte.
- .value enthält den Namen der Spalte, in die die Zellenwerte eingefügt werden.
Die verbleibenden Spalten der Spezifikation geben an, wie der Name der komprimierbaren Spalten aus .name in der neuen Spalte angezeigt wird.
Die Spezifikation beschreibt die im Spaltennamen gespeicherten Metadaten mit einer Zeile für jede Spalte und einer Spalte für jede Variable in Kombination mit dem Spaltennamen. Diese Definition erscheint jetzt wahrscheinlich verwirrend, aber nach einigen Beispielen wird alles viel klarer.
Die Bedeutung der Spezifikation besteht darin, dass Sie neue Metadaten für den konvertierten Datenrahmen abrufen, ändern und festlegen können.
Die Funktion pivot_longer_spec() wird pivot_longer_spec() , um mit Spezifikationen zu arbeiten, wenn eine Tabelle von einem breiten Format in ein langes konvertiert wird.
Wie diese Funktion funktioniert, nimmt sie einen beliebigen Datumsrahmen und generiert ihre Metadaten wie oben beschrieben.
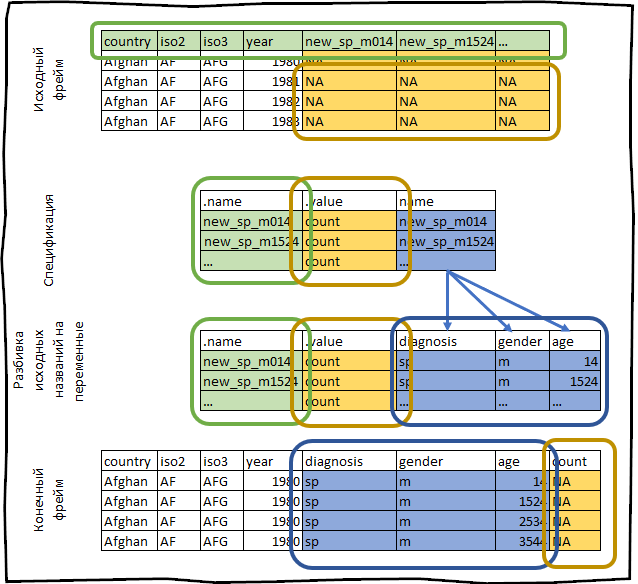
Nehmen wir zum Beispiel das who-Dataset, das mit dem tidyr- Paket geliefert wird . Dieser Datensatz enthält Informationen der internationalen Gesundheitsorganisation zum Auftreten von Tuberkulose.
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
Wir konstruieren seine Spezifikation.
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
Die Felder Land , iso2 , iso3 sind bereits Variablen. Unsere Aufgabe ist es, die Spalten von new_sp_m014 nach newrel_f65 zu wechseln .
Die Namen dieser Spalten enthalten die folgenden Informationen:
- Das Präfix
new_ gibt an, dass die Spalte Daten zu neuen Fällen von Tuberkulose enthält. Der aktuelle new_ enthält nur Informationen zu neuen Krankheiten. Daher hat dieses Präfix im aktuellen Kontext keine Bedeutung. sp / rel / sp / ep beschreibt eine Methode zur Diagnose einer Krankheit.m / f Geschlecht des Patienten.014 Altersspanne des Patienten.
Wir können diese Spalten mithilfe der Funktion extract() mithilfe eines regulären Ausdrucks trennen.
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
Beachten Sie, dass die Spalte .name unverändert bleiben muss, da dies unser Index in den Spaltennamen des Quelldatensatzes ist.
Geschlecht und Alter (Spalten Geschlecht und Alter ) haben feste und bekannte Werte. Daher wird empfohlen, diese Spalten in Faktoren umzuwandeln:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
Um die von uns erstellte Spezifikation auf das ursprüngliche Datum des who- Frames anzuwenden, müssen wir das spec- Argument in der Funktion pivot_longer() verwenden.
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
Alles, was wir gerade getan haben, kann wie folgt schematisch dargestellt werden:
Angabe mit mehreren Werten (.value)
Im obigen Beispiel enthielt die Spalte .value- Spezifikation nur einen Wert. In den meisten Fällen geschieht dies.
Gelegentlich kann es jedoch vorkommen, dass Sie Daten aus Spalten mit unterschiedlichen Datentypen in den Werten erfassen müssen. Mit der Funktion "Veraltete spread() wäre dies ziemlich schwierig.
Das folgende Beispiel stammt aus der Vignette für das Paket data.table .
Lassen Sie uns einen Trainingsdatenrahmen erstellen.
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
Der erstellte Datumsrahmen in jeder Zeile enthält Daten zu den Kindern einer Familie. Familien können ein oder zwei Kinder haben. Für jedes Kind werden Daten zum Geburtsdatum und Geschlecht bereitgestellt, und die Daten für jedes Kind befinden sich in separaten Spalten. Unsere Aufgabe besteht darin, diese Daten in das für die Analyse korrekte Format zu bringen.
Bitte beachten Sie, dass wir zwei Variablen mit Informationen zu jedem Kind haben: sein Geschlecht und sein Geburtsdatum (Spalten mit dem Präfix dop enthalten das Geburtsdatum, Spalten mit dem Präfix gender enthalten das Geschlecht des Kindes). Im erwarteten Ergebnis sollten sie in separaten Spalten stehen. Wir können dies tun, indem wir eine Spezifikation generieren, in der die Spalte .value zwei verschiedene Werte hat.
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
Lassen Sie uns also die Schritte durchgehen, die vom obigen Code ausgeführt werden.
pivot_longer_spec(-family) - pivot_longer_spec(-family) eine Spezifikation, die alle verfügbaren Spalten mit Ausnahme der Familienspalte komprimiert.separate(col = name, into = c(".value", "child")) - trennt die .name- Spalte, die die Namen der Quellfelder enthält, unterstrichen und fügt die Werte in die .value- und child- Spalten ein.mutate(child = parse_number(child)) - Konvertiert die Werte des mutate(child = parse_number(child)) Felds vom Text in den numerischen Datentyp.
Jetzt können wir die empfangene Spezifikation auf den anfänglichen Datenrahmen anwenden und die Tabelle in die gewünschte Form bringen.
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
Wir verwenden das Argument na.rm = TRUE , da das aktuelle Datenformular uns zwingt, zusätzliche Zeilen für nicht vorhandene Beobachtungen zu erstellen. Weil Familie 2 hat nur ein Kind, na.rm = TRUE stellt sicher, dass Familie 2 eine Zeile in der Ausgabe hat.
pivot_wider() - ist die inverse Transformation, und umgekehrt wird die Anzahl der Spalten im pivot_wider() erhöht, indem die Anzahl der Zeilen verringert wird.
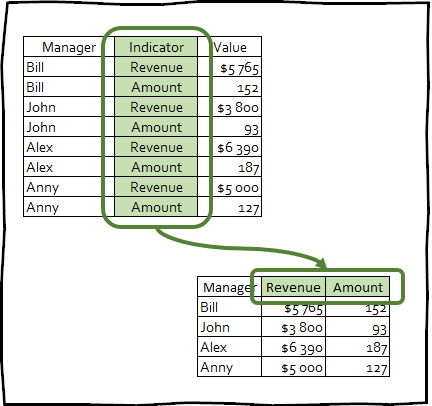
Diese Art der Transformation wird selten verwendet, um Daten in ein ordentliches Erscheinungsbild zu bringen. Diese Technik kann jedoch nützlich sein, um Pivot-Tabellen zu erstellen, die in Präsentationen verwendet werden, oder um sie in andere Tools zu integrieren.
Tatsächlich sind die Funktionen pivot_longer() und pivot_wider() symmetrisch und führen entgegengesetzte Aktionen aus, d. H.: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) und df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) gibt den ursprünglichen df zurück.
Um die Funktionsweise der Funktion pivot_wider() zu demonstrieren, verwenden wir den Datensatz fish_encounters , in dem Informationen darüber gespeichert sind , wie verschiedene Stationen die Bewegung von Fischen entlang des Flusses aufzeichnen.
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
In den meisten Fällen ist diese Tabelle informativer und bequemer zu verwenden, wenn Sie Informationen für jede Station in einer separaten Spalte angeben.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
Dieser Datensatz zeichnet Informationen nur auf, wenn der Fisch von der Station erkannt wurde, d. H. Wenn ein Fisch nicht von einer Station repariert wurde, sind diese Daten nicht in der Tabelle enthalten. Dies bedeutet, dass die Ausgabe von NA gefüllt wird.
In diesem Fall wissen wir jedoch, dass das Fehlen eines Datensatzes bedeutet, dass der Fisch nicht bemerkt wurde. Daher können wir das Argument values_fill in der Funktion pivot_wider() verwenden und diese fehlenden Werte mit Nullen füllen:
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
Generieren eines Spaltennamens aus mehreren Quellvariablen
Stellen Sie sich vor, wir haben eine Tabelle mit einer Kombination aus Produkt, Land und Jahr. Um ein Testframe-Datum zu generieren, können Sie den folgenden Code ausführen:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
Unsere Aufgabe ist es, den Datumsrahmen so zu erweitern, dass eine Spalte Daten für jede Kombination aus Produkt und Land enthält. Übergeben Sie dazu einfach den Vektor mit den Namen der zu verbindenden Felder in das Argument names_from .
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
Sie können auch Spezifikationen auf die Funktion pivot_wider() anwenden. Bei pivot_wider() an pivot_wider() Spezifikation jedoch das Gegenteil von pivot_longer() : Die in .name angegebenen Spalten werden mit Werten aus .value und anderen Spalten erstellt.
Für diesen Datensatz können Sie eine Benutzerspezifikation generieren, wenn jede mögliche Kombination aus Land und Produkt eine eigene Spalte haben soll und nicht nur diejenigen, die in den Daten vorhanden sind:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
Einige fortgeschrittene Beispiele für die Arbeit mit dem neuen Tidyr-Konzept
Bringen Sie Daten anhand des US-amerikanischen Datensatzes für Einnahmen und Mietzählungen zu einem ordentlichen Erscheinungsbild
Der Datensatz us_rent_income enthält Informationen zum durchschnittlichen Einkommen und zur durchschnittlichen Miete für jeden Staat in den USA für 2017 (der Datensatz ist im Tidycensus- Paket verfügbar).
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
Es ist äußerst unpraktisch, mit ihnen in der Form zu arbeiten, in der die Daten im Datensatz us_rent_income gespeichert sind. Daher möchten wir einen Datensatz mit den folgenden Spalten erstellen: rent , rent_moe , come , einkommen_moe . Es gibt viele Möglichkeiten, diese Spezifikation zu erstellen, aber die Hauptsache ist, dass wir jede Kombination aus Variablenwerten und Schätzung / Moe generieren und dann den Spaltennamen generieren müssen.
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
Wenn Sie diese Spezifikation für pivot_wider() , erhalten Sie das pivot_wider() Ergebnis:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
Weltbank
Manchmal sind mehrere Schritte erforderlich, um den Datensatz in die richtige Form zu bringen.
Der Datensatz world_bank_pop enthält Daten der Weltbank zur Bevölkerung jedes Landes von 2000 bis 2018.
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
Unser Ziel ist es, einen übersichtlichen Datensatz zu erstellen, in dem sich jede Variable in einer separaten Spalte befindet. Es ist noch nicht klar, welche Schritte notwendig sind, aber wir beginnen mit dem offensichtlichsten Problem: Das Jahr ist auf mehrere Spalten verteilt.
Um dies zu beheben, müssen Sie die Funktion pivot_longer() verwenden.
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
Fazit
, tidyr , spread() gather() . pivot_longer() pivot_wider() .