
Software-Code für maschinelles Lernen ist oft komplex und ziemlich verwirrend. Das Erkennen und Beseitigen von Fehlern ist eine ressourcenintensive Aufgabe. Selbst die einfachsten
direkt verbundenen neuronalen Netze erfordern einen ernsthaften Ansatz für die Netzwerkarchitektur, die Initialisierung von Gewichten und die Netzwerkoptimierung. Ein kleiner Fehler kann zu unangenehmen Problemen führen.
Dieser Artikel befasst sich mit dem Debugging-Algorithmus Ihrer neuronalen Netze.
Skillbox empfiehlt: Ein Python-Entwickler von Grund auf .
Wir erinnern Sie daran: Für alle Leser von „Habr“ - ein Rabatt von 10.000 Rubel bei der Anmeldung für einen Skillbox-Kurs mit dem Promo-Code „Habr“.
Der Algorithmus besteht aus fünf Stufen:
- einfacher Start;
- Bestätigung von Verlusten;
- Überprüfung von Zwischenergebnissen und Verbindungen;
- Diagnose von Parametern;
- Arbeitskontrolle.
Wenn Ihnen etwas interessanter erscheint als der Rest, können Sie direkt zu diesen Abschnitten gehen.
Einfacher Start
Ein neuronales Netzwerk mit komplexer Architektur, Regularisierung und einem Lerngeschwindigkeitsplaner ist schwieriger zu debütieren als ein reguläres Netzwerk. Wir sind hier etwas knifflig, da das Element selbst einen indirekten Bezug zum Debuggen hat, aber dies ist immer noch eine wichtige Empfehlung.
Ein einfacher Anfang besteht darin, ein vereinfachtes Modell zu erstellen und es an einem Datensatz (Punkt) zu trainieren.
Zuerst erstellen wir ein vereinfachtes ModellErstellen Sie für einen schnellen Start ein kleines Netzwerk mit einer einzelnen verborgenen Ebene und überprüfen Sie, ob alles ordnungsgemäß funktioniert. Dann komplizieren wir das Modell schrittweise, überprüfen jeden neuen Aspekt seiner Struktur (zusätzliche Ebene, Parameter usw.) und fahren fort.
Wir trainieren das Modell an einem einzigen Datensatz (Punkt)Als schnellen Test für den Zustand Ihres Projekts können Sie ein oder zwei Datenpunkte für das Training verwenden, um zu überprüfen, ob das System ordnungsgemäß funktioniert. Das neuronale Netzwerk sollte eine 100% ige Genauigkeit des Trainings und der Überprüfung aufweisen. Ist dies nicht der Fall, ist entweder das Modell zu klein oder Sie haben bereits einen Fehler.
Auch wenn alles in Ordnung ist, bereiten Sie das Modell für den Durchgang einer oder mehrerer Epochen vor, bevor Sie fortfahren.
Verlustschätzung
Die Verlustschätzung ist der Hauptweg, um die Modellleistung zu verfeinern. Sie müssen sicherstellen, dass der Verlust der Aufgabe entspricht und die Verlustfunktionen auf der richtigen Skala bewertet werden. Wenn Sie mehr als eine Verlustart verwenden, stellen Sie sicher, dass alle in derselben Reihenfolge und korrekt skaliert sind.
Es ist wichtig, auf die anfänglichen Verluste zu achten. Überprüfen Sie, wie nahe das tatsächliche Ergebnis am erwarteten Ergebnis liegt, wenn das Modell mit einer zufälligen Annahme gestartet wurde. Die
Arbeit von Andrei Karpati schlägt Folgendes vor : „Stellen Sie sicher, dass Sie das erwartete Ergebnis erhalten, wenn Sie mit einer kleinen Anzahl von Parametern arbeiten. Es ist besser, den Datenverlust sofort zu überprüfen (wobei der Regularisierungsgrad auf Null gesetzt ist). Für CIFAR-10 mit dem Softmax-Klassifikator erwarten wir beispielsweise einen Anfangsverlust von 2,302, da die erwartete diffuse Wahrscheinlichkeit für jede Klasse 0,1 beträgt (da es 10 Klassen gibt) und der Verlust von Softmax die negative logarithmische Wahrscheinlichkeit der richtigen Klasse ist als - ln (0,1) = 2,302.
Für ein binäres Beispiel wird eine ähnliche Berechnung einfach für jede der Klassen durchgeführt. Hier sind zum Beispiel die Daten: 20% Nullen und 80% Einsen. Der erwartete Anfangsverlust beträgt bis zu –0,2 ln (0,5) –0,8 ln (0,5) = 0,693147. Wenn das Ergebnis größer als 1 ist, kann dies darauf hinweisen, dass die Gewichte des neuronalen Netzwerks nicht richtig ausgeglichen sind oder die Daten nicht normalisiert sind.
Zwischenergebnisse und Verbindungen prüfen
Um ein neuronales Netzwerk zu debuggen, ist es notwendig, die Dynamik von Prozessen innerhalb des Netzwerks und die Rolle einzelner Zwischenschichten zu verstehen, da diese miteinander verbunden sind. Hier sind einige häufige Fehler, auf die Sie stoßen könnten:
- Falsche Ausdrücke für Verlaufsaktualisierungen
- Gewichtsaktualisierungen gelten nicht;
- verschwindende oder explodierende Farbverläufe.
Wenn die Gradientenwerte Null sind, bedeutet dies, dass die Lerngeschwindigkeit im Optimierer zu langsam ist oder dass Sie auf einen falschen Ausdruck gestoßen sind, um den Gradienten zu aktualisieren.
Darüber hinaus müssen die Werte der Aktivierungsfunktionen, Gewichte und Aktualisierungen der einzelnen Ebenen überwacht werden. Beispielsweise sollte der Wert von Parameteraktualisierungen (Gewichte und Offsets)
1-e3 sein .
Es gibt ein Phänomen namens "Sterbendes ReLU" oder
"Verschwindendes Gradientenproblem", wenn ReLU-Neuronen nach dem Untersuchen des großen negativen Vorspannungswerts für ihre Gewichte Null ausgeben. Diese Neuronen werden an keiner Datenstelle wieder aktiviert.
Sie können Gradiententests verwenden, um diese Fehler zu erkennen, indem Sie den Gradienten mithilfe eines numerischen Ansatzes approximieren. Wenn es nahe an den berechneten Gradienten liegt, wurde die Rückausbreitung korrekt implementiert. Um eine Verlaufsprüfung zu erstellen, lesen Sie
hier und
hier diese großartigen CS231-Ressourcen sowie das Tutorial von Andrew Nga zu diesem Thema.
Fayzan Sheikh weist auf drei Hauptmethoden zur Visualisierung eines neuronalen Netzwerks hin:
- Vorläufig - einfache Methoden, die uns die allgemeine Struktur des trainierten Modells zeigen. Sie umfassen die Ausgabe von Formularen oder Filtern einzelner Schichten des neuronalen Netzwerks und von Parametern in jeder Schicht.
- Basierend auf der Aktivierung. In ihnen entschlüsseln wir die Aktivierung einzelner Neuronen oder Gruppen von Neuronen, um ihre Funktionen zu verstehen.
- Gradientenbasiert. Diese Methoden neigen dazu, die Gradienten zu manipulieren, die sich beim Training des Modells aus der Passage hin und her bilden (einschließlich Signifikanzkarten und Klassenaktivierungskarten).
Es gibt verschiedene nützliche Tools zur Visualisierung der Aktivierungen und Verbindungen einzelner Ebenen, z. B.
ConX und
Tensorboard .
Parameterdiagnose
Neuronale Netze haben viele Parameter, die miteinander interagieren, was die Optimierung erschwert. Tatsächlich ist dieser Abschnitt Gegenstand aktiver Forschung durch Spezialisten, daher sollten die folgenden Vorschläge nur als Ratschläge betrachtet werden, auf denen Sie aufbauen können.
Paketgröße (Stapelgröße) - Wenn die Paketgröße groß genug sein soll, um genaue Schätzungen des Fehlergradienten zu erhalten, aber klein genug, damit der stochastische Gradientenabstieg (SGD) Ihr Netzwerk rationalisieren kann. Die geringe Größe der Pakete wird zu einer schnellen Konvergenz aufgrund von Rauschen im Lernprozess und in Zukunft zu Optimierungsschwierigkeiten führen. Dies wird
hier ausführlicher beschrieben.
Lerngeschwindigkeit - Zu langsam führt zu einer langsamen Konvergenz oder dem Risiko, in lokalen Tiefs zu stecken. Gleichzeitig führt eine hohe Lerngeschwindigkeit zu einer Diskrepanz bei der Optimierung, da Sie das Risiko eingehen, durch die Tiefe zu "springen", aber gleichzeitig einen engen Teil der Verlustfunktion. Versuchen Sie, die Geschwindigkeitsplanung zu verwenden, um sie während des Trainings des neuronalen Netzwerks zu reduzieren. CS231n
hat einen großen Abschnitt zu diesem Thema .
Gradienten-Clipping - Trimmen der Gradienten von Parametern während der Rückausbreitung auf den Maximalwert oder die Grenznorm. Nützlich zum Lösen von Problemen mit explodierenden Verläufen, die im dritten Absatz auftreten können.
Batch-Normalisierung - wird verwendet, um die Eingabedaten jeder Schicht zu normalisieren, wodurch das Problem der internen kovarianten Verschiebung gelöst werden kann. Wenn Sie Dropout und Batch Norma zusammen verwenden,
lesen Sie diesen Artikel .
Stochastic Gradient Descent (SGD) - Es gibt verschiedene Arten von SGD, die Impuls, adaptive Lerngeschwindigkeiten und die Nesterov-Methode verwenden. Gleichzeitig hat keiner von ihnen einen klaren Vorteil sowohl in Bezug auf die Trainingseffizienz als auch in Bezug auf die Verallgemeinerung (
Details hier ).
Regularisierung - ist für die Erstellung eines verallgemeinerten Modells von entscheidender Bedeutung, da dadurch die Komplexität des Modells oder extreme Parameterwerte beeinträchtigt werden. Dies ist eine Möglichkeit, die Varianz des Modells zu verringern, ohne seine Verschiebung signifikant zu erhöhen. Weitere
Informationen hier .
Um alles selbst zu bewerten, müssen Sie die Regularisierung deaktivieren und den Gradienten des Datenverlusts selbst überprüfen.
Dropout ist eine weitere Möglichkeit, Ihr Netzwerk zu optimieren, um eine Überlastung zu vermeiden. Während des Trainings tritt ein Verlust nur auf, indem die Aktivität des Neurons mit einer bestimmten Wahrscheinlichkeit p (Hyperparameter) aufrechterhalten oder im umgekehrten Fall auf Null gesetzt wird. Infolgedessen muss das Netzwerk für jede Trainingspartei eine andere Teilmenge von Parametern verwenden, wodurch die Änderungen bestimmter Parameter, die dominant werden, verringert werden.
Wichtig: Wenn Sie sowohl die Ausfall- als auch die Chargennormalisierung verwenden, achten Sie auf die Reihenfolge dieser Vorgänge oder sogar auf deren gemeinsame Verwendung. All dies wird noch aktiv diskutiert und ergänzt. Hier sind zwei wichtige Diskussionen zu diesem Thema
zu Stackoverflow und
Arxiv .
Arbeitskontrolle
Es geht darum, Workflows und Experimente zu dokumentieren. Wenn Sie nichts dokumentieren, können Sie beispielsweise vergessen, welche Trainingsgeschwindigkeit oder welches Klassengewicht verwendet wird. Dank der Steuerung können Sie frühere Experimente einfach anzeigen und reproduzieren. Dies reduziert die Anzahl der doppelten Experimente.
Richtig, manuelle Dokumentation kann bei viel Arbeit eine Herausforderung sein. Hier helfen Tools wie Comet.ml dabei, Datensätze, Codeänderungen, Versuchsverlauf und Produktionsmodelle automatisch zu protokollieren, einschließlich wichtiger Informationen zu Ihrem Modell (Hyperparameter, Modellleistungsindikatoren und Umgebungsinformationen).
Ein neuronales Netzwerk kann sehr empfindlich auf kleine Änderungen reagieren, was zu einer Verringerung der Modellleistung führt. Das Verfolgen und Dokumentieren von Arbeiten ist der erste Schritt zur Standardisierung Ihrer Umgebung und Modellierung.
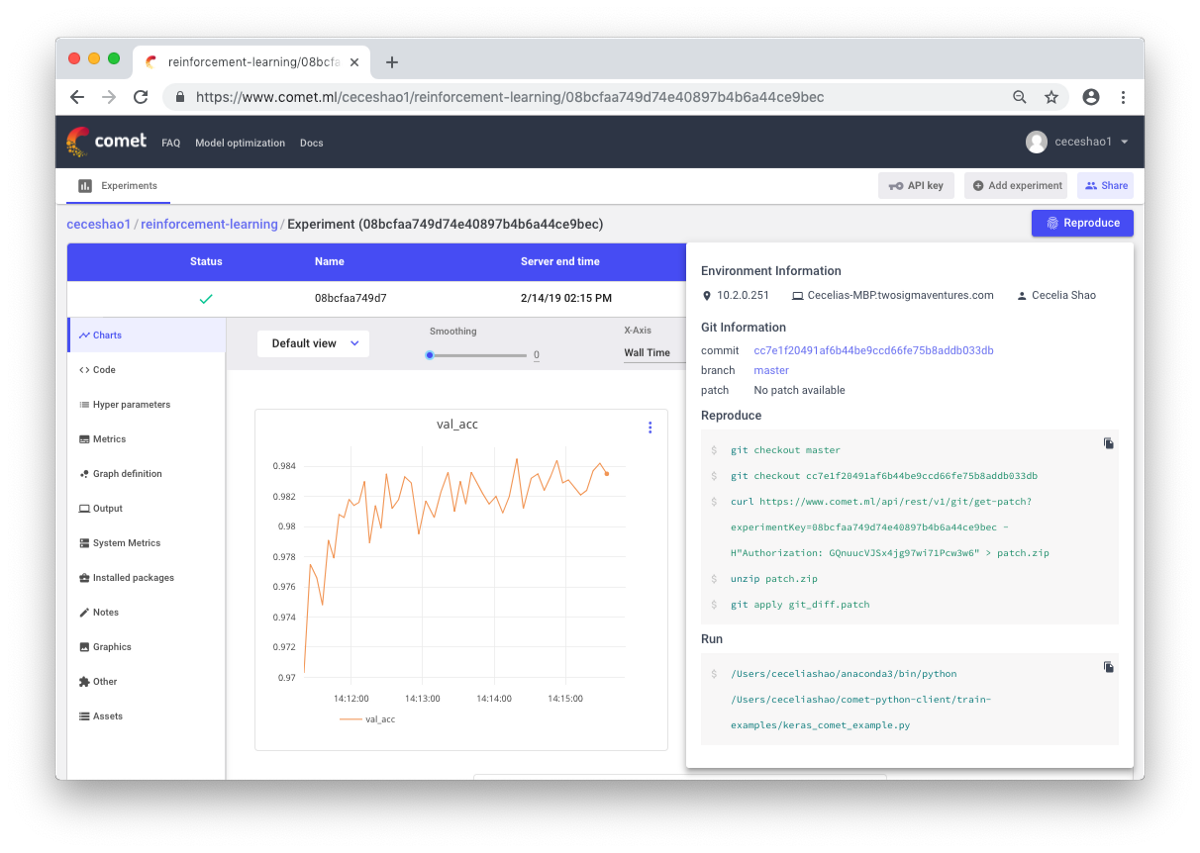
Ich hoffe, dass dieser Beitrag der Ausgangspunkt sein kann, von dem aus Sie mit dem Debuggen Ihres neuronalen Netzwerks beginnen.
Skillbox empfiehlt: