Um ein Problem zu lösen, müssen Sie es manchmal nur aus einem anderen Blickwinkel betrachten. Auch wenn solche Probleme in den letzten 10 Jahren auf dieselbe Weise mit unterschiedlichen Effekten gelöst wurden, ist es keine Tatsache, dass diese Methode die einzige ist.
Es gibt ein Thema wie Kundenabwanderung. Die Sache ist unvermeidlich, weil Kunden eines Unternehmens ihre Produkte oder Dienstleistungen aus vielen Gründen nicht mehr nutzen können. Für das Unternehmen ist der Abfluss natürlich eine natürliche, aber nicht die wünschenswerteste Maßnahme. Daher versucht jeder, diesen Abfluss zu minimieren. Und noch besser - um die Wahrscheinlichkeit eines Abflusses einer bestimmten Benutzerkategorie oder eines bestimmten Benutzers vorherzusagen und einige Aufbewahrungsschritte anzubieten.
Analysieren Sie und versuchen Sie, den Kunden möglichst aus folgenden Gründen zu halten:
- Die Gewinnung neuer Kunden ist teurer als Kundenbindungsverfahren . Um neue Kunden zu gewinnen, müssen Sie in der Regel etwas Geld ausgeben (Werbung), während bestehende Kunden mit einem Sonderangebot mit Sonderkonditionen aktiviert werden können;
- Das Verständnis, warum Kunden abreisen, ist der Schlüssel zur Verbesserung von Produkten und Dienstleistungen .
Es gibt Standardansätze zur Vorhersage von Abflüssen. Bei einer der KI-Meisterschaften haben wir uns jedoch entschlossen, die Weibull-Verteilung zu testen. Am häufigsten wird es für Überlebensanalysen, Wettervorhersagen, Naturkatastrophenanalysen, Wirtschaftsingenieurwesen und dergleichen verwendet. Die Weibull-Verteilung ist eine spezielle Verteilungsfunktion, die durch zwei Parameter parametrisiert wird
und
.
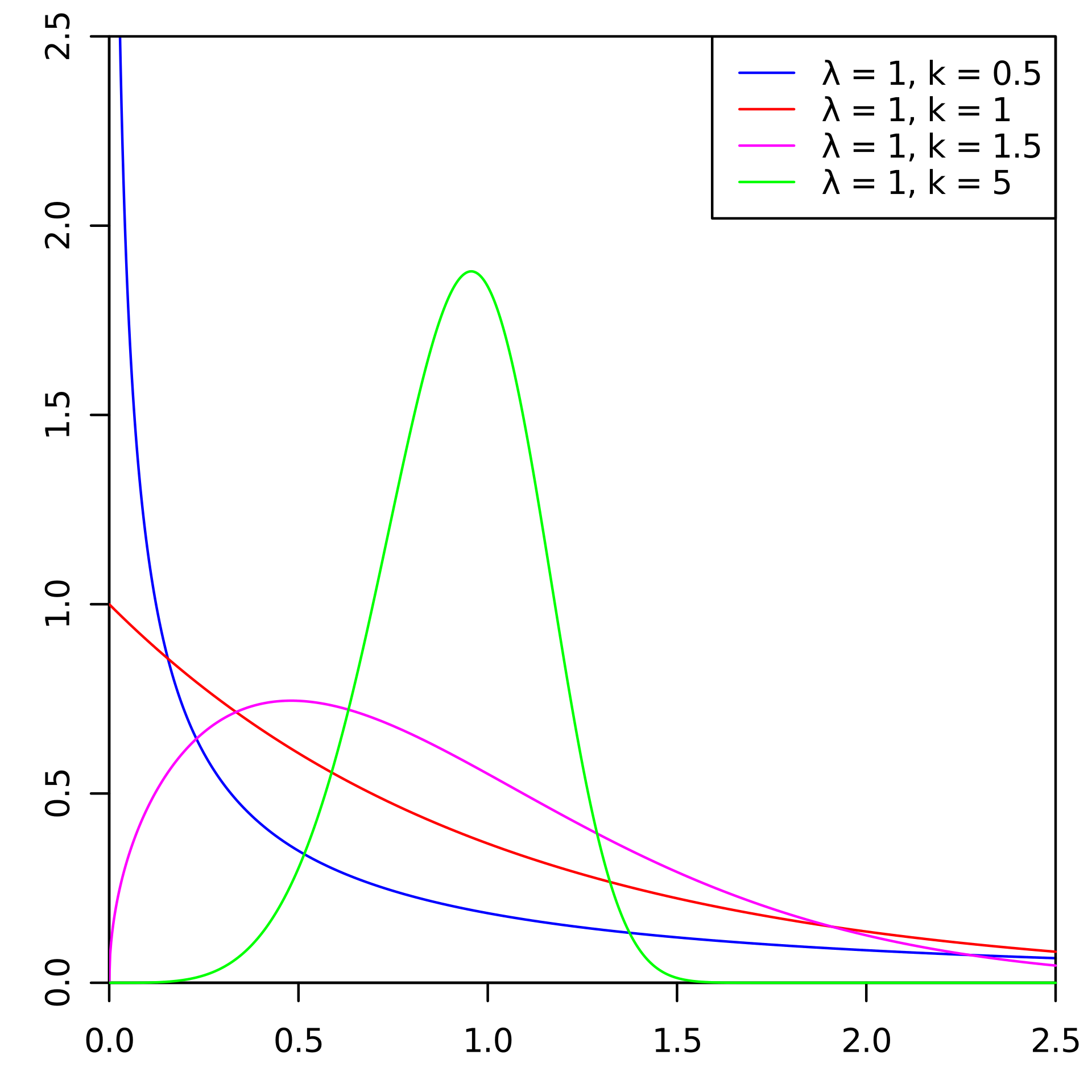 Wikipedia
WikipediaIm Allgemeinen ist die Sache unterhaltsam, aber um den Abfluss vorherzusagen, und tatsächlich wird sie in der Fintech nicht so oft verwendet. Unter dem Strich werden wir Ihnen sagen, wie wir (das Labor für Data Mining) dies getan haben, indem wir Gold bei der AI-Meisterschaft in der Nominierung "AI in Banks" gewonnen haben.
Über den Abfluss im Allgemeinen
Schauen wir uns ein wenig an, was Client-Abfluss ist und warum er so wichtig ist. Für das Geschäft ist der Kundenstamm wichtig. Neue Kunden kommen in diese Datenbank, nachdem sie beispielsweise durch Werbung von einem Produkt oder einer Dienstleistung erfahren haben, leben sie einige Zeit (nutzen die Produkte aktiv) und stellen sie nach einiger Zeit nicht mehr ein. Dieser Zeitraum wird als „Customer Lifecycle“ (engl. Customer Lifecycle) bezeichnet. Dieser Begriff beschreibt die Schritte, die der Kunde durchläuft, wenn er sich über ein Produkt informiert, eine Kaufentscheidung trifft, bezahlt, nutzt und ein treuer Kunde wird und letztendlich die Nutzung einstellt aus dem einen oder anderen Grund Produkte. Dementsprechend ist der Abfluss die letzte Phase des Lebenszyklus des Kunden, in der der Kunde die Dienste nicht mehr nutzt. Für Unternehmen bedeutet dies, dass der Kunde nicht mehr rentabel ist und im Allgemeinen keinen Nutzen mehr hat.
Jeder Kunde der Bank ist eine bestimmte Person, die eine bestimmte Bankkarte speziell für ihre Bedürfnisse auswählt. Oft reisen - eine Karte mit Meilen ist nützlich. Er kauft viel - hallo, Karte mit Cashback. Er kauft viel in bestimmten Läden - und dafür gibt es bereits einen speziellen Affiliate-Kunststoff. Natürlich wird manchmal auch eine Karte nach dem Kriterium „Günstigster Service“ ausgewählt. Im Allgemeinen gibt es hier genügend Variablen.
Und eine andere Person wählt die Bank selbst - lohnt es sich, eine Bankkarte zu wählen, deren Filialen nur in Moskau und der Region liegen, wenn Sie aus Chabarowsk kommen? Wenn die Karte einer solchen Bank mindestens zweimal rentabler ist, ist das Vorhandensein von Bankfilialen in der Nähe immer noch ein wichtiges Kriterium. Ja, 2019 ist bereits da und digital ist unser Alles, aber eine Reihe von Problemen für einige Banken können nur in der Filiale gelöst werden. Auch hier vertraut ein Teil der Bevölkerung einer physischen Bank viel mehr als einer Anwendung auf einem Smartphone. Dies muss ebenfalls berücksichtigt werden.
Infolgedessen kann eine Person viele Gründe haben, die Produkte der Bank (oder der Bank selbst) abzulehnen. Er wechselte seinen Job und der Kartensatz änderte sich von einem Gehalt zu "Für bloße Sterbliche", was weniger rentabel ist. Er zog in eine andere Stadt, in der es keine Bankfilialen gibt. Ich habe es nicht gemocht, mit einem ungelernten Mitarbeiter in der Abteilung zu sprechen. Das heißt, es kann noch mehr Gründe für die Schließung eines Kontos geben als für die Verwendung eines Produkts.
Und der Kunde kann nicht nur ausdrücklich seine Absicht zum Ausdruck bringen - zur Bank kommen und eine Erklärung schreiben, sondern einfach die Verwendung der Produkte einstellen, ohne den Vertrag zu brechen. Um solche Probleme zu verstehen, wurde beschlossen, maschinelles Lernen und KI zu verwenden.
Darüber hinaus kann der Abfluss von Kunden in jeder Branche auftreten (Telekommunikation, Internetprovider, Versicherungsunternehmen im Allgemeinen, wo immer es einen Kundenstamm gibt und regelmäßige Transaktionen).
Was haben wir getan?
Zunächst musste eine klare Grenze beschrieben werden - seit wann betrachten wir den Kunden als verschwunden. Aus Sicht der Bank, die uns die Daten für die Arbeit zur Verfügung gestellt hat, war der Aktivitätsstatus des Kunden binär - er ist entweder aktiv oder nicht. In der Tabelle "Aktivität" befand sich ein ACTIVE_FLAG-Flag, dessen Wert entweder "0" oder "1" ("Inaktiv" bzw. "Aktiv") sein konnte. Und alles wäre in Ordnung, aber die Person ist so, dass sie es für eine Weile aktiv nutzen und dann für einen Monat aus dem Aktiv herausfallen kann - sie wird krank, geht in ein anderes Land, um sich auszuruhen, oder geht sogar, um die Karte einer anderen Bank zu testen. Oder nutzen Sie nach einer langen Zeit der Inaktivität wieder die Dienste der Bank
Aus diesem Grund haben wir beschlossen, den Zeitraum der Inaktivität als einen bestimmten kontinuierlichen Zeitraum zu bezeichnen, in dem das Flag für "0" gesetzt wurde.
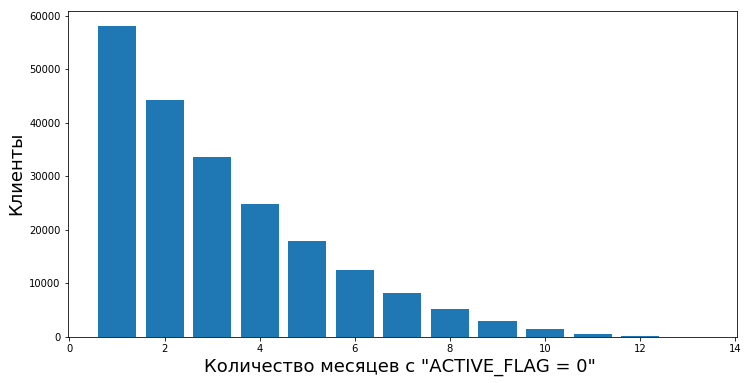
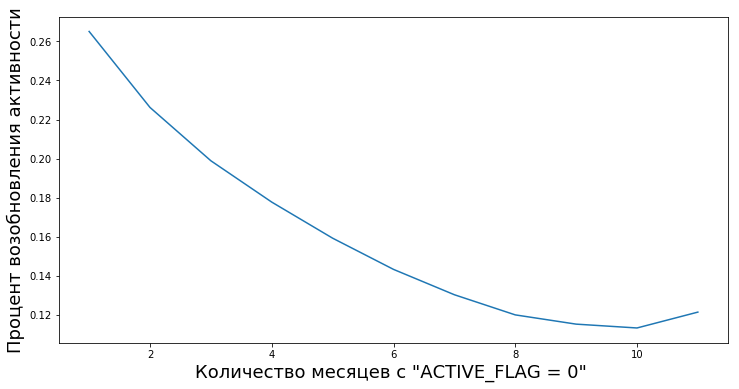
Kunden wechseln nach Inaktivitätsperioden unterschiedlicher Länge von inaktiv zu aktiv. Wir haben die Möglichkeit, den Grad des empirischen Werts „Zuverlässigkeit von Inaktivitätsperioden“ zu berechnen, dh die Wahrscheinlichkeit, dass eine Person nach vorübergehender Inaktivität wieder anfängt, die Produkte der Bank zu verwenden.
Dieses Diagramm zeigt beispielsweise die Wiederaufnahme der Aktivität (ACTIVE_FLAG = 1) von Kunden nach mehreren Monaten Inaktivität (ACTIVE_FLAG = 0).
Hier werden wir den Datensatz, mit dem wir zu arbeiten begonnen haben, ein wenig erläutern. Daher hat die Bank in den folgenden Tabellen 19 Monate lang aggregierte Informationen bereitgestellt:
- "Aktivität" - monatliche Kundentransaktionen (per Karte, im Internetbanking und im Mobile Banking), einschließlich Gehalts- und Umsatzinformationen.
- "Karten" - Daten auf allen Karten, die ein Kunde hat, mit einem detaillierten Tarifplan.
- „Verträge“ - Informationen zu Kundenverträgen (offen und geschlossen): Kredite, Einlagen usw., unter Angabe der jeweiligen Parameter.
- "Kunden" - eine Reihe demografischer Daten (Geschlecht und Alter) und die Verfügbarkeit von Kontaktdaten.
Für die Arbeit brauchten wir alle Tabellen außer der "Karte".
Die Schwierigkeit hier war etwas anderes - in diesen Daten gab die Bank nicht an, welche Art von Aktivität auf den Karten stattfand. Das heißt, wir konnten verstehen, ob es Transaktionen gab oder nicht, aber wir konnten ihren Typ nicht mehr bestimmen. Daher war unklar, ob der Kunde Bargeld abhebt, ob er ein Gehalt erhält oder ob er Geld für Einkäufe ausgibt. Und wir hatten keine Daten zu Kontensalden, was nützlich wäre.
Die Stichprobe selbst war unvoreingenommen - für diesen Abschnitt unternahm die Bank 19 Monate lang keine Versuche, Kunden zu binden und den Abfluss zu minimieren.
Also über Perioden der Inaktivität.
Um die Definition des Abflusses zu formulieren, müssen Sie einen Zeitraum der Inaktivität auswählen. So erstellen Sie jeweils eine Abflussprognose
Sie müssen in dem Intervall eine Kundenhistorie von mindestens 3 Monaten haben
. Unsere Vorgeschichte war auf 19 Monate begrenzt, daher entschieden wir uns für eine Inaktivitätsperiode von 6 Monaten, falls vorhanden. Und für den Mindestzeitraum für eine qualitative Prognose dauerten sie 3 Monate. Die Zahlen nach 3 und 6 Monaten wurden empirisch anhand einer Analyse des Verhaltens von Kundendaten ermittelt.
Die Definition des Abflusses haben wir wie folgt formuliert: Monatsabfluss des Kunden
Dies ist der erste Monat mit ACTIVE_FLAG = 0, in dem seit diesem Monat mindestens sechs Nullen hintereinander im Feld ACTIVE_FLAG ausgeführt wurden, dh der Monat, seit dem der Client 6 Monate lang inaktiv war.
 Anzahl der verstorbenen Kunden
Anzahl der verstorbenen Kunden Anzahl der verbleibenden Kunden
Anzahl der verbleibenden KundenDa wird es als Abfluss betrachtet
In solchen Wettbewerben und in der Praxis werden Abflüsse häufig auf diese Weise vorhergesagt. Der Kunde nutzt Produkte und Dienstleistungen in unterschiedlichen Zeitintervallen, Daten zur Interaktion mit ihm werden in Form eines Merkmalsvektors fester Länge n dargestellt. Am häufigsten umfassen diese Informationen:
- Benutzerspezifische Daten (demografische Daten, Marketing-Segment).
- Die Geschichte der Nutzung von Bankprodukten und -dienstleistungen (dies sind Kundenaktionen, die immer an einen bestimmten Zeitraum oder Zeitraum des von uns benötigten Intervalls gebunden sind).
- Externe Daten, sofern verfügbar - beispielsweise Bewertungen aus sozialen Netzwerken.
Danach leiten sie die Definition des Abflusses ab, die für jede Aufgabe eine eigene ist. Dann verwenden sie den Algorithmus für maschinelles Lernen, der die Wahrscheinlichkeit des Austritts des Kunden vorhersagt
basierend auf dem Vektor der Faktoren
. Um den Algorithmus zu erlernen, wird eines der bekannten Frameworks zum
Erstellen von Ensembles aus Entscheidungsbäumen,
XGBoost ,
LightGBM ,
CatBoost oder deren Modifikationen verwendet.
Der Algorithmus selbst ist nicht schlecht, hat jedoch in Bezug auf die Vorhersage des Abflusses mehrere schwerwiegende Nachteile.
- Er hat nicht das sogenannte "Gedächtnis". Die Eingabe des Modells erhält eine bestimmte Anzahl von Merkmalen, die dem aktuellen Zeitpunkt entsprechen. Um Informationen über den Verlauf von Parameteränderungen zu erhalten, müssen spezielle Merkmale berechnet werden, die Änderungen von Parametern im Zeitverlauf charakterisieren, z. B. die Anzahl oder Menge der Bankgeschäfte in den letzten 1.2.3 Monaten. Ein solcher Ansatz kann die Art vorübergehender Änderungen nur teilweise widerspiegeln.
- Fester Prognosehorizont. Das Modell kann den Abfluss von Kunden nur für einen vorgegebenen Zeitraum vorhersagen, z. B. eine Prognose einen Monat im Voraus. Wenn Sie eine Prognose für einen anderen Zeitraum benötigen, z. B. für drei Monate, müssen Sie den Trainingssatz neu erstellen und das neue Modell neu trainieren.
Unser Ansatz
Wir haben sofort beschlossen, keine Standardansätze zu verwenden. Zusätzlich zu uns haben sich 497 Personen für die Meisterschaft angemeldet, von denen jeder eine gute Erfahrung gemacht hat. Daher ist es keine gute Idee, unter solchen Bedingungen zu versuchen, etwas auf normale Weise zu tun.
Und wir begannen, die Probleme des binären Klassifizierungsmodells zu lösen, indem wir die probabilistische Verteilung der Kundenabflusszeiten vorhersagten. Ein ähnlicher Ansatz ist hier zu sehen: Er ermöglicht eine flexiblere Vorhersage des Abflusses und das Testen komplexerer Hypothesen als beim klassischen Ansatz. Als Verteilungsfamilie, die die
Abflusszeit simuliert, haben wir die
Weibull-Verteilung aufgrund ihrer weit verbreiteten Verwendung in der Überlebensanalyse ausgewählt. Kundenverhalten kann als eine Art Überleben angesehen werden.
Hier sind Beispiele für Weibull-Wahrscheinlichkeitsdichteverteilungen in Abhängigkeit von Parametern
und
::
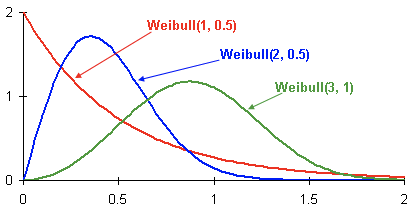
Dies ist die Wahrscheinlichkeitsdichteverteilung der Kundenabwanderung von drei verschiedenen Kunden über die Zeit. Die Zeit wird in Monaten angegeben. Mit anderen Worten, diese Grafik zeigt, wann es am wahrscheinlichsten ist, dass der Client in den nächsten zwei Monaten abfließt. Wie Sie sehen, hat ein Client mit einer Verteilung ein großes Potenzial, früher als Kunden mit einer Weibull- (2, 0,5) und Weibull- (3,1) -Distribution zu gehen.
Das Ergebnis ist ein Modell, das für jeden Kunden für jeden geeignet ist
des Monats prognostiziert die Weibull-Verteilungsparameter, die den Beginn der Wahrscheinlichkeit eines Abflusses über die Zeit am besten widerspiegeln. Wenn mehr Details:
- Zielmerkmale in der Trainingsstichprobe - die verbleibende Zeit vor dem Abfluss in einem bestimmten Monat für einen bestimmten Kunden.
- Wenn für den Kunden kein Abflussindikator vorhanden ist, gehen wir davon aus, dass die Abflusszeit länger als die Anzahl der Monate ist, beginnend mit dem aktuellen und dem Ende unserer Historie.
- Das verwendete Modell: ein wiederkehrendes neuronales Netzwerk mit einer LSTM-Schicht.
- Als Verlustfunktion verwenden wir die negative logarithmische Wahrscheinlichkeitsfunktion für die Weibull-Verteilung.
Hier sind die Vorteile dieser Methode:
- Die Wahrscheinlichkeitsverteilung ermöglicht es Ihnen neben der offensichtlichen Möglichkeit der binären Klassifizierung, verschiedene Ereignisse flexibel vorherzusagen, z. B. ob der Kunde die Dienste der Bank innerhalb von 3 Monaten nicht mehr nutzt. Bei Bedarf können auch verschiedene Metriken über diese Verteilung gemittelt werden.
- Das wiederkehrende neuronale LSTM-Netzwerk verfügt über Speicher und nutzt den gesamten Verlauf effizient. Mit der Erweiterung oder Verfeinerung der Geschichte wächst die Genauigkeit.
- Der Ansatz kann problemlos skaliert werden, wenn Zeitintervalle in kleinere unterteilt werden (z. B. wenn Monate in Wochen unterteilt werden).
Es reicht jedoch nicht aus, ein gutes Modell zu erstellen, sondern Sie müssen auch dessen Qualität richtig bewerten.
Wie bewertet man die Qualität?
Als Metrik haben wir die Auftriebskurve gewählt. Es wird in solchen Fällen aufgrund einer verständlichen Interpretation im Geschäftsleben verwendet und
hier und
hier gut beschrieben. Wenn Sie die Bedeutung dieser Metrik in einem Satz beschreiben, erhalten Sie: „Wie oft macht der Algorithmus im ersten Satz die beste Vorhersage
% als zufällig. "
Wir trainieren Modelle
Die Wettbewerbsbedingungen haben keine spezifische Qualitätsmetrik festgelegt, anhand derer verschiedene Modelle und Ansätze verglichen werden können. Darüber hinaus kann die Definition des Abflusskonzepts unterschiedlich sein und von der Erklärung des Problems abhängen, die wiederum von den Geschäftszielen bestimmt wird. Um zu verstehen, welche Methode besser ist, haben wir zwei Modelle trainiert:
- Ein häufig verwendeter binärer Klassifizierungsansatz unter Verwendung des maschinellen Lernalgorithmus eines Entscheidungsbaumensembles ( LightGBM );
- Modell Weibull-LSTM
Die Testprobe bestand aus 500 vorgewählten Kunden, die nicht in der Trainingsprobe waren. Für das Modell wurden Hyperparameter unter Verwendung einer Kreuzvalidierung durch den Client ausgewählt. Um jedes Modell zu trainieren, wurden dieselben Attributgruppen verwendet.
Aufgrund der Tatsache, dass das Modell kein Gedächtnis hat, wurden spezielle Zeichen dafür genommen, die das Verhältnis der Änderungen der Parameter eines Monats zum Durchschnittswert der Parameter in den letzten drei Monaten zeigen. Was kennzeichnete die Änderungsrate der Werte in den letzten drei Monaten? Ohne dies wäre ein auf Random Forest basierendes Modell in einer zuvor verlorenen Position gegenüber Weibull-LSTM.
Warum LSTM mit Weibull-Verteilung besser ist als der Ansatz, der auf dem Ensemble von Entscheidungsbäumen basiert
Hier ist alles klar buchstäblich ein paar Bilder.
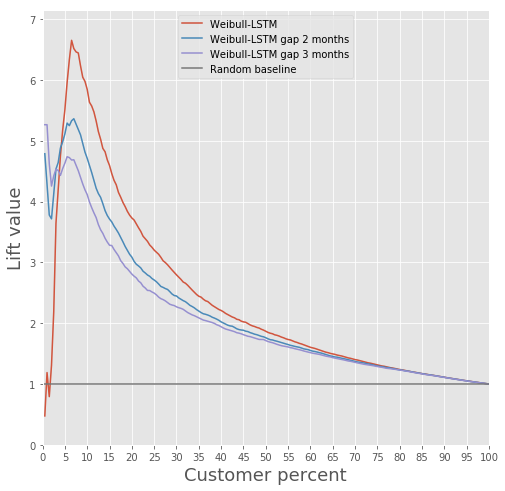 Vergleich der Auftriebskurve für den klassischen Algorithmus und Weibull-LSTM
Vergleich der Auftriebskurve für den klassischen Algorithmus und Weibull-LSTM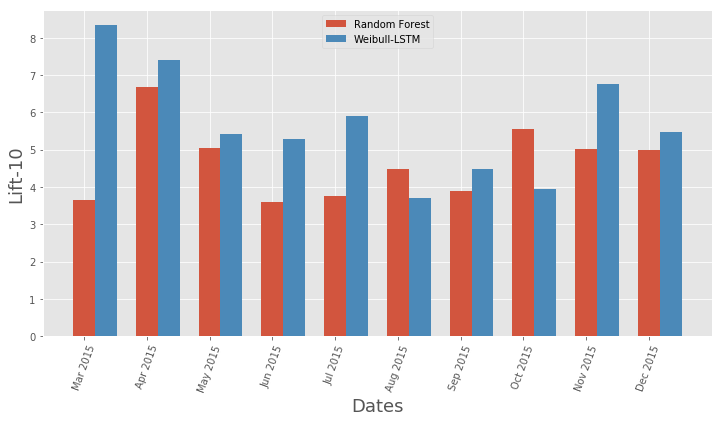 Monatlicher Vergleich der Auftriebskurvenmetrik für klassischen Algorithmus und Weibull-LSTM
Monatlicher Vergleich der Auftriebskurvenmetrik für klassischen Algorithmus und Weibull-LSTMIm Allgemeinen führt LSTM in fast allen Fällen den klassischen Algorithmus aus.
Abflussvorhersage
Ein Modell, das auf einem wiederkehrenden neuronalen Netzwerk mit LSTM-Zellen mit einer Weibull-Verteilung basiert, kann den Abfluss im Voraus vorhersagen, beispielsweise die Abreise eines Kunden in den nächsten n Monaten vorhersagen. Betrachten Sie den Fall für n = 3. In diesem Fall muss das neuronale Netzwerk für jeden Monat korrekt bestimmen, ob der Client vom nächsten Monat bis zum n-ten Monat abreist. Mit anderen Worten, sie muss korrekt bestimmen, ob der Kunde nach n Monaten bleibt. Dies kann als Voraussage angesehen werden: Vorhersage des Augenblicks, in dem der Kunde gerade darüber nachgedacht hat, wie er gehen soll.
Vergleichen Sie die Auftriebskurve für Weibull-LSTM 1, 2 und 3 Monate vor dem Abfluss:
Wir haben bereits oben geschrieben, dass die Prognosen, die für Kunden erstellt werden, die einige Zeit nicht aktiv sind, ebenfalls wichtig sind. Daher werden wir hier solche Fälle in die Stichprobe aufnehmen, wenn der verstorbene Client bereits ein oder zwei Monate inaktiv war, und prüfen, ob Weibull-LSTM solche Fälle korrekt als Abfluss klassifiziert. Da solche Fälle in der Stichprobe vorhanden waren, erwarten wir, dass das Netzwerk sie gut bewältigt:
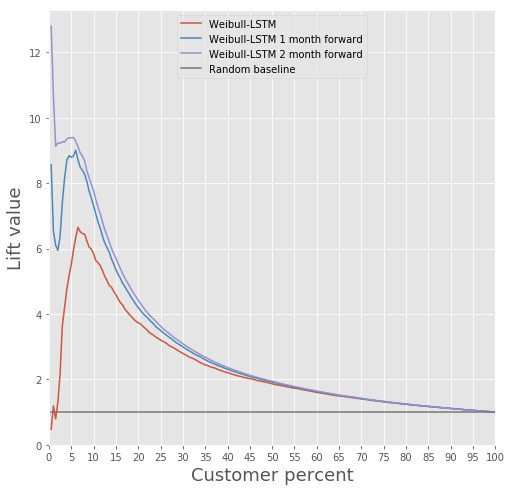
Kundenbindung
Tatsächlich ist dies die Hauptsache, die mit den vorliegenden Informationen erreicht werden kann, dass sich diese und jene Kunden darauf vorbereiten, das Produkt nicht mehr zu verwenden. Wenn Sie über das Erstellen eines Modells sprechen, das Kunden etwas Nützliches bieten könnte, um sie zu halten, funktioniert dies nicht, wenn Sie keine Vorgeschichte solcher Versuche haben, die gut enden würden.
Wir hatten keine solche Geschichte, also haben wir es so entschieden.
- Wir bauen ein Modell, das für jeden Kunden interessante Produkte definiert.
- In jedem Monat führen wir einen Klassifikator durch und identifizieren potenzielle ausgehende Kunden.
- Einige Kunden bieten ein Produkt an, nach dem Modell von Absatz 1, erinnern sich an ihre Handlungen.
- Nach einigen Monaten prüfen wir, welcher dieser potenziell ausgehenden Kunden noch übrig ist und welcher noch übrig ist. Somit bilden wir ein Trainingsmuster.
- Wir trainieren das Modell anhand der in Absatz 4 erhaltenen Geschichte.
- Wiederholen Sie optional den Vorgang, indem Sie das Modell aus Absatz 1 durch das in Absatz 5 erhaltene Modell ersetzen.
Die üblichen A / B-Tests können als Überprüfung der Qualität einer solchen Aufbewahrung dienen. Wir teilen Kunden, die möglicherweise abreisen, in zwei Gruppen ein. Wir bieten einem Produkte an, die auf unserem Retentionsmodell basieren, und wir bieten dem zweiten nichts an. Wir haben uns entschlossen, ein Modell zu trainieren, von dem bereits Punkt 1 unseres Beispiels profitieren könnte.
Wir wollten die Segmentierung so interpretierbar wie möglich machen. Zu diesem Zweck haben wir verschiedene Zeichen ausgewählt, die leicht zu interpretieren sind: Gesamtzahl der Transaktionen, Gehalt, Gesamtumsatz des Kontos, Alter, Geschlecht. Die Zeichen aus der Tabelle „Karten“ wurden aufgrund der Komplexität der Verarbeitung nicht als nicht aussagekräftig angesehen, und die Zeichen aus Tabelle 3 „Verträge“ - um Datenlecks zwischen dem Validierungssatz und dem Trainingssatz zu vermeiden.
Das Clustering wurde unter Verwendung von Gaußschen Mischungsmodellen durchgeführt.
Das Akaike-Informationskriterium ermöglichte die Bestimmung von 2 Optima. Das erste Optimum entspricht 1 Cluster. Das zweite, weniger ausgeprägte Optimum entspricht 80 Clustern. Aus diesem Ergebnis kann die folgende Schlussfolgerung gezogen werden: Es ist äußerst schwierig, Daten ohne vorherige Informationen in Cluster zu unterteilen. Für ein besseres Clustering benötigen Sie Daten, die jeden Client detailliert beschreiben.Daher wurde die Aufgabe der Ausbildung bei einem Lehrer in Betracht gezogen, um jedem einzelnen Kunden ein Produkt anzubieten. Die folgenden Produkte wurden berücksichtigt: "Festgeld", "Kreditkarte", "Überziehungskredit", "Verbraucherkredit", "Autokredit", "Hypothek".In den Daten war ein anderer Produkttyp vorhanden: „Girokonto“. Aufgrund des geringen Informationsgehalts haben wir dies jedoch nicht berücksichtigt. Von Benutzern, die Kunden der Bank sind, d.h. Sie haben nicht aufgehört, ihre Produkte zu verwenden. Es wurde ein Modell erstellt, das vorhersagte, welches Produkt für sie von Interesse sein könnte. Als Modell wurde die logistische Regression gewählt, und der Lift-Wert für die ersten 10 Perzentile wurde als Qualitätsbewertungsmetrik verwendet.Die Qualität des Modells kann in der Abbildung geschätzt werden.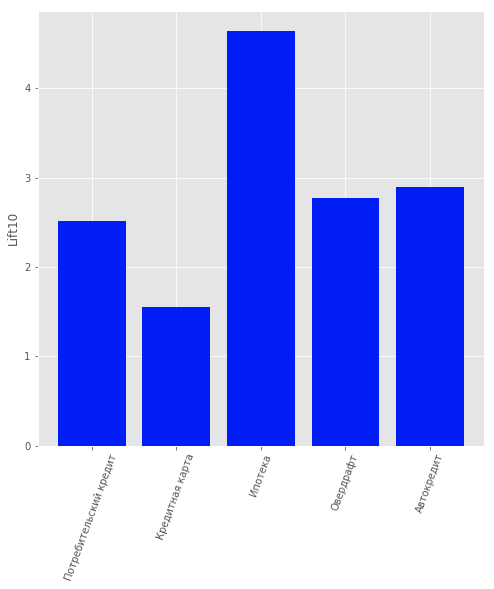 Ergebnisse des Kundenempfehlungsmodells
Ergebnisse des KundenempfehlungsmodellsZusammenfassung
Dieser Ansatz brachte uns den ersten Platz in der Nominierung für „AI in Banks“ bei der RAIF-Challenge 2017 AI Championship. Anscheinend bestand die Hauptsache darin, das Problem von einer ungewöhnlichen Seite aus anzugehen und eine Methode zu verwenden, die üblicherweise für andere Situationen verwendet wird.Obwohl der massive Abfluss von Benutzern durchaus eine Naturkatastrophe für Dienste sein kann.Diese Methode kann für jeden anderen Bereich angewendet werden, in dem es wichtig ist, den Abfluss zu berücksichtigen, nicht für die Banken insgesamt. Zum Beispiel haben wir damit unseren eigenen Abfluss berechnet - in den sibirischen und St. Petersburger Niederlassungen von Rostelecom.Firma "Laboratory of Data Mining" "Suchportal" Sputnik "
Anscheinend bestand die Hauptsache darin, das Problem von einer ungewöhnlichen Seite aus anzugehen und eine Methode zu verwenden, die üblicherweise für andere Situationen verwendet wird.Obwohl der massive Abfluss von Benutzern durchaus eine Naturkatastrophe für Dienste sein kann.Diese Methode kann für jeden anderen Bereich angewendet werden, in dem es wichtig ist, den Abfluss zu berücksichtigen, nicht für die Banken insgesamt. Zum Beispiel haben wir damit unseren eigenen Abfluss berechnet - in den sibirischen und St. Petersburger Niederlassungen von Rostelecom.Firma "Laboratory of Data Mining" "Suchportal" Sputnik "