Der Denkprozess einer Person ist schwer zu mathematisieren. Jede Geschäftsaufgabe generiert eine Reihe formeller und informeller Dokumente, deren Informationen sich im Unternehmens-Repository widerspiegeln. Jede Aufgabe, die einen Informationsprozess generiert, erstellt um sich herum eine Reihe von Dokumenten und die Logik ihrer Verarbeitung, die in der Unternehmensspeicherumgebung wenig formalisiert ist. Im Data Warehouse sollten Strukturen vorhanden sein, um den Informationsfluss zu löschen. Das Oracle Enterprise Data Quality-Produkt, mit dem die Aufgaben der Bereinigung "schmutziger" Daten gelöst werden sollen, kann Abhilfe schaffen. Dies ist jedoch nicht auf seine Verwendung beschränkt.
1. Das Konzept einer zufälligen Datenbank.Die allerersten Geschäftsbeziehungen einer Person werden durch formelle und informelle Dokumente wie eine Erklärung, eine Erklärung, einen Arbeitsvertrag, einen Antrag auf Vermittlung und einen Antrag auf eine Ressource beschrieben. Diese Dokumente stellen logische Verbindungen zwischen Geschäftsprozessen her, sind jedoch in der Regel ein Produkt des Denkens von Büroleitern und schlecht formalisiert.
Die Aufgabe einer zumindest komplizierten Optimierung besteht nicht nur darin, die formellen und informellen Regeln zu verstehen, sondern häufig ungleiches Wissen in eine gemeinsame Informationsbasis zu bringen.
Definition Eine zufällige Datenbank besteht aus einer Reihe von Fakten, Dokumenten, manuellen Notizen und formalen Dokumenten, die von einer Person für einen bestimmten Geschäftsprozess verarbeitet werden, jedoch aufgrund des starken Einflusses des menschlichen Faktors nicht vollständig automatisch verarbeitet werden können.Ein Beispiel. Die Sekretärin erhält den Anruf offiziell. Der Anrufer interessiert sich für ein Produkt oder eine Dienstleistung. Der Anrufer ist für CRM nicht bekannt. Frage: Was soll der Anrufer sagen, um von einem Spezialisten gehört zu werden?
Genauer gesagt: Inwieweit ermöglichen die Geschäftsanweisungen der Sekretärin einen formellen Dialog über das Geschäft, wenn der zuständige Spezialist für diese Art von Tätigkeit nicht bereit ist?
Es stellt sich heraus, dass wir wieder zur Definition einer zufälligen Datenbank kommen.
Vielleicht enthält es mehr Fakten, als die Sekretärin wissen kann. Die darin erhaltenen Informationen können jedoch nicht überflüssig sein. Wenn zufällige Fakten einer zufälligen Datenbank bei der Eingabe eines formalisierten Systems eintreffen, entsteht im Allgemeinen eine Informationsüberflutung - und jede Informationsüberflutung kann die Leistung nicht nur des Sekretärs, sondern des gesamten Unternehmens beeinträchtigen.
Wenn es zu Verarbeitungszwecken verwendet wird, kommt eine Maschine, die die Zustände dieser Informationen liest, auf der Grundlage logischer Schlussfolgerungen zu dem Zustand, der der Überlastung von Menscheninformationen entgegengesetzt ist. Die menschliche Logik ist flexibler.
2. Anwendung der Definition auf reale Aufgaben.Stellen Sie sich ein Geschäft vor, in dem die Preise für zufällige Waren spürbar hoch oder niedrig sind. Wenn Sie dieses Geschäft verlassen, wird im Kopf eines unerfahrenen Kunden mit einer Einkaufsliste der Preis von 5-7 (oder sogar 3) der beliebtesten Waren angegeben, dessen Preis die Größe des Gesamtschecks beeinflussen kann. Es stellt sich heraus, dass, wenn es möglich wäre, die Liste der Waren zu kennen, an deren Preis sich die Käufer am häufigsten erinnern, der Rest der Preise in einem relativ großen Bereich variieren könnte.
Haben Sie sich jemals gefragt, warum das Fleisch vor der Fastenzeit zunächst stark billiger wird und dann stark im Preis steigen und dann verschwinden kann? Der Preis eines Produkts, dessen Nachfrage auf Null fallen kann, wird zuerst künstlich erwärmt, dann, wenn er eine bestimmte Nachfrage überschreitet, beginnt er festgesetzt zu werden, und nach einer Weile steigt er kräftig an, da die Gier es nicht erlaubt, illiquide Waren zu einem fairen Preis zu verschenken.
Eine fast ähnliche Situation besteht auf dem Datenmarkt. Die nützlichsten Informationen werden fast immer von sekundären Hypothesen über ihre Anwendbarkeit und Extrahierbarkeit verborgen.
Es reicht aus, alle Informationen, die für 5000-7000 Personen interessant sind, auf einer relativ ungeschützten Ressource bereitzustellen. Es gibt sicherlich Websites zum Kopieren und Einfügen.
Oder das berühmte Spiel mit den Telefoncodes „Wer hat mich angerufen?“. Ungefähr tausend Websites in Runet bestehen nur aus den Telefonnummern verschiedener Betreiber, um in den Suchergebnissen etwas höher zu sein, um den Domainnamen irgendwie zu verkaufen und Werbung teurer zu machen.
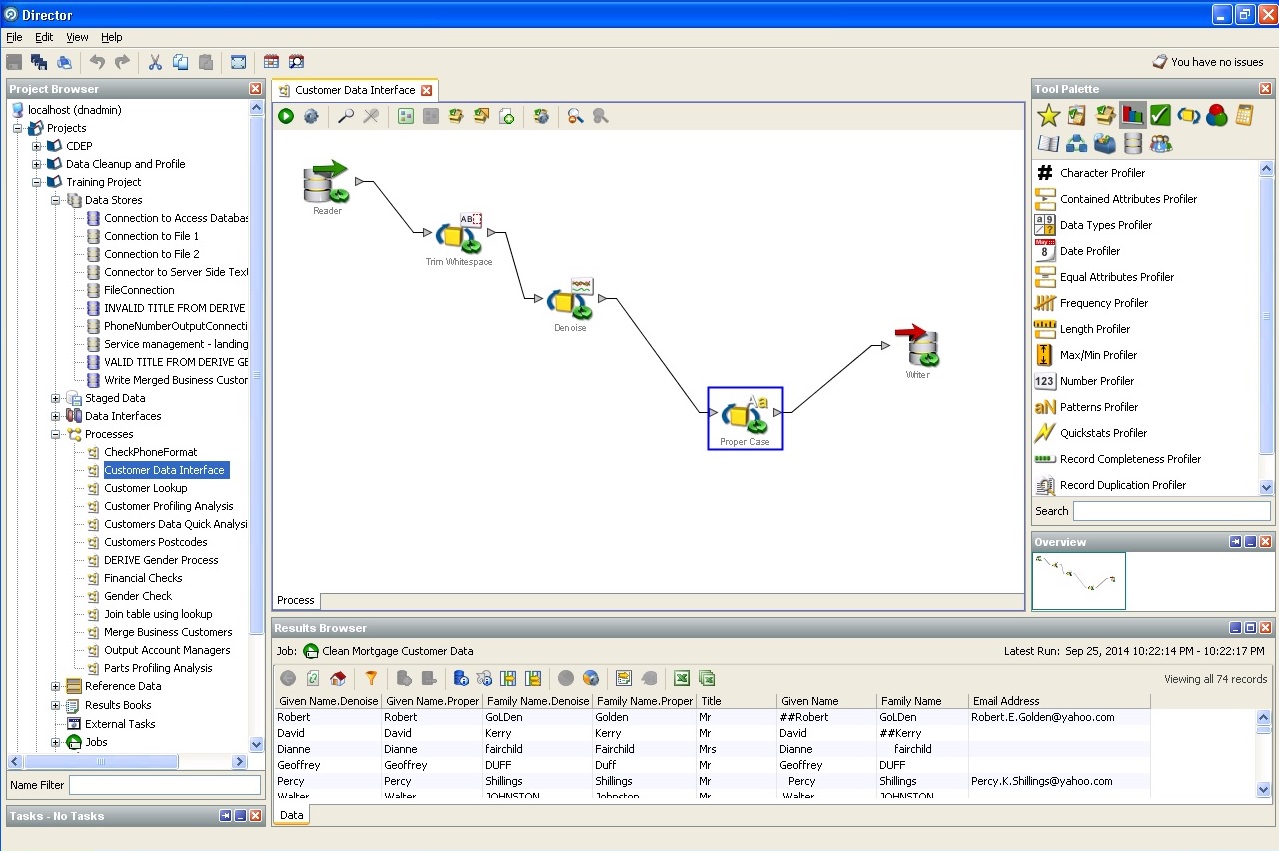
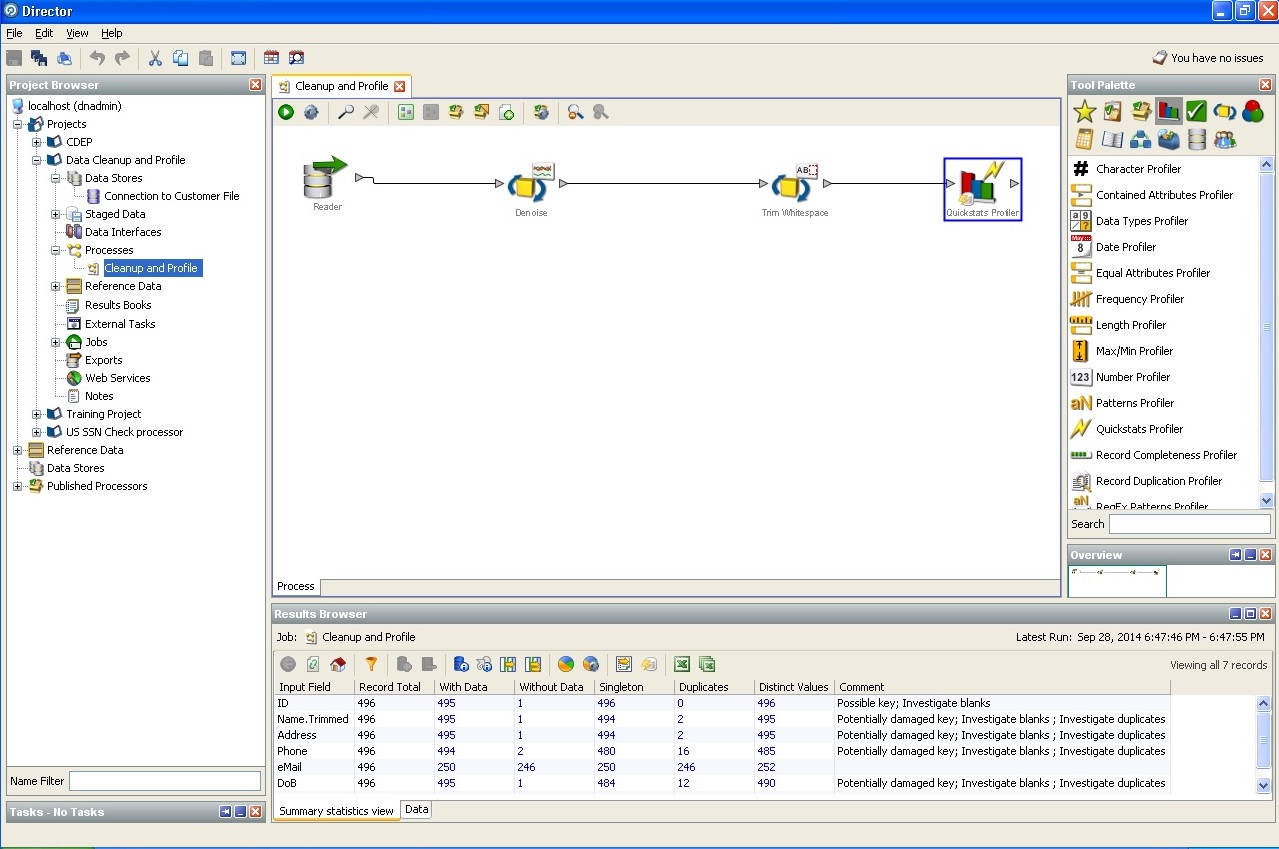
3. Der Preis des Problems bei der Arbeit mit "schmutzigen" Daten.Nach den Recherchen des Autors des Artikels werden bis zu 10% der Arbeitsressourcen jedes Projekts für das Schreiben bestimmter Datenbereinigungsverfahren verwendet. Wenn Sie sich nicht mit einem völlig banalen Typ und einer völlig banalen Länge befassen, dh mit eindeutigen Kennungen, Datenbankintegritätsregeln und Geschäftsintegritätsregeln, quantitativen und qualitativen Einheitenskalen, Arbeitseinheitensystemen und anderen Zuständen, Einflüssen, Übergängen, deren Erstellung wie üblich statistische Daten erfordert logische und seriöse Geschäftsanalyse. Bei der Formalisierung von Anforderungen muss die Beziehung zwischen Fakten und Dimensionen sowohl für den Aufbau von Repositorys als auch für die Lösung von Problemen im Front-End formalisiert werden.
Stimmen Sie zu, wenn ETL-Prozesse 70% der Arbeitszeit eines Speichers beanspruchen, ist es bereits ein guter Bonus, 5-7% der Ressourcen für die korrekte Bereinigung von Daten bei einem bedingten Speicher von 200.000 Kunden einzusparen?
Wir werden uns ein wenig mit den Problemen "schmutziger" Daten in vorgefertigten Systemen befassen. Angenommen, Sie gratulieren 10.000 Kunden per Post zu einem Nationalfeiertag per Post. Wie viele Personen werfen Ihren Brief mit der besten Postkarte in die Mailbox, wenn Sie einen Fehler im Vor- oder Nachnamen machen oder das Formular im Formular falsch ausfüllen? Der Preis Ihrer Bemühungen kann die Stimmung eines jeden Benutzers auf Null reduzieren!
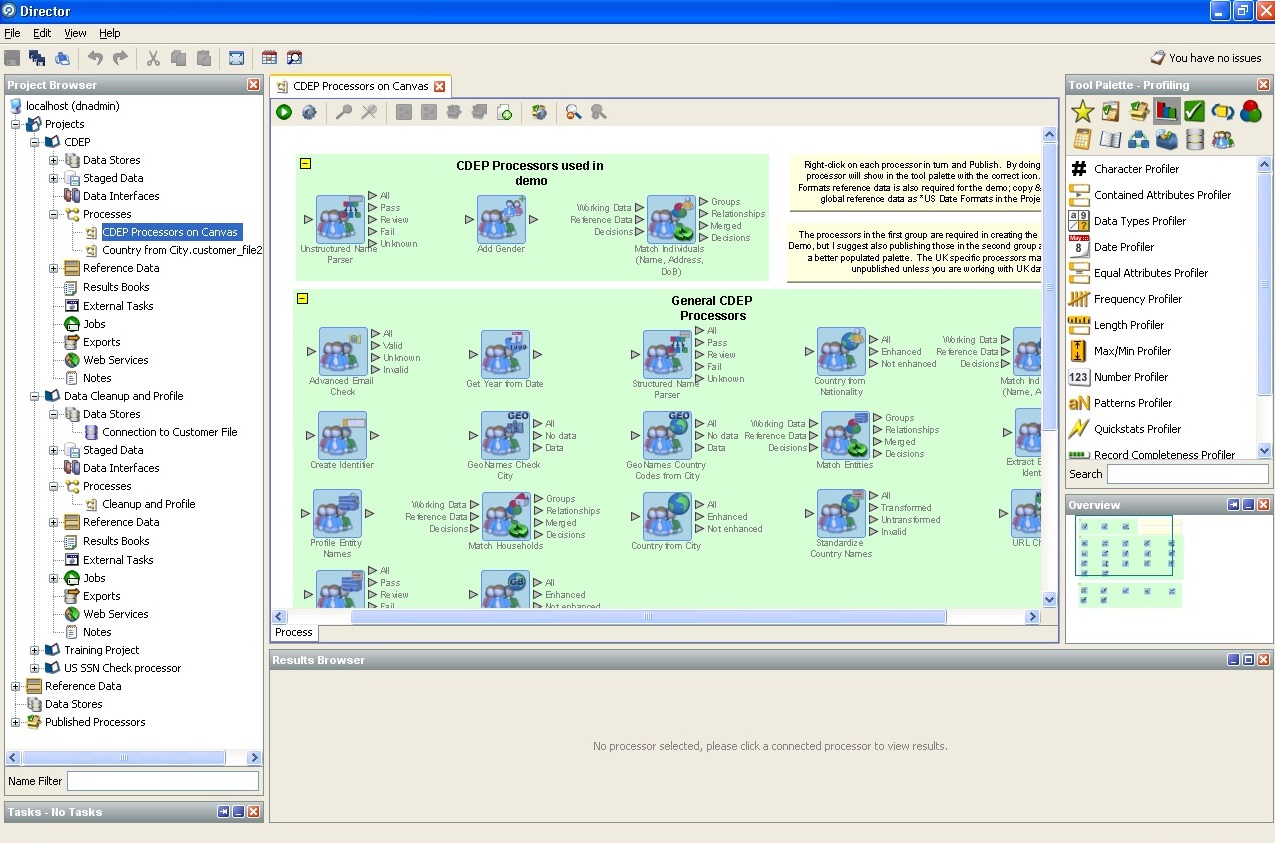
4. Oracle Enterprise Data Quality - Schutzschild und Schwert des Unternehmensspeichers.Die von uns bereitgestellten Screenshots beschreiben die Funktionen von Oracle Enterprise Data Quality.
Lassen Sie also jemanden Wasser auf Ihre Datenbank oder Ihr Textdokument verschütten.
Hier ist eine Liste von Standardprozessoren (logische Einheiten, die Sie verwenden können
zu den Daten der einen oder anderen Hypothese oder zur Suche nach der erforderlichen):
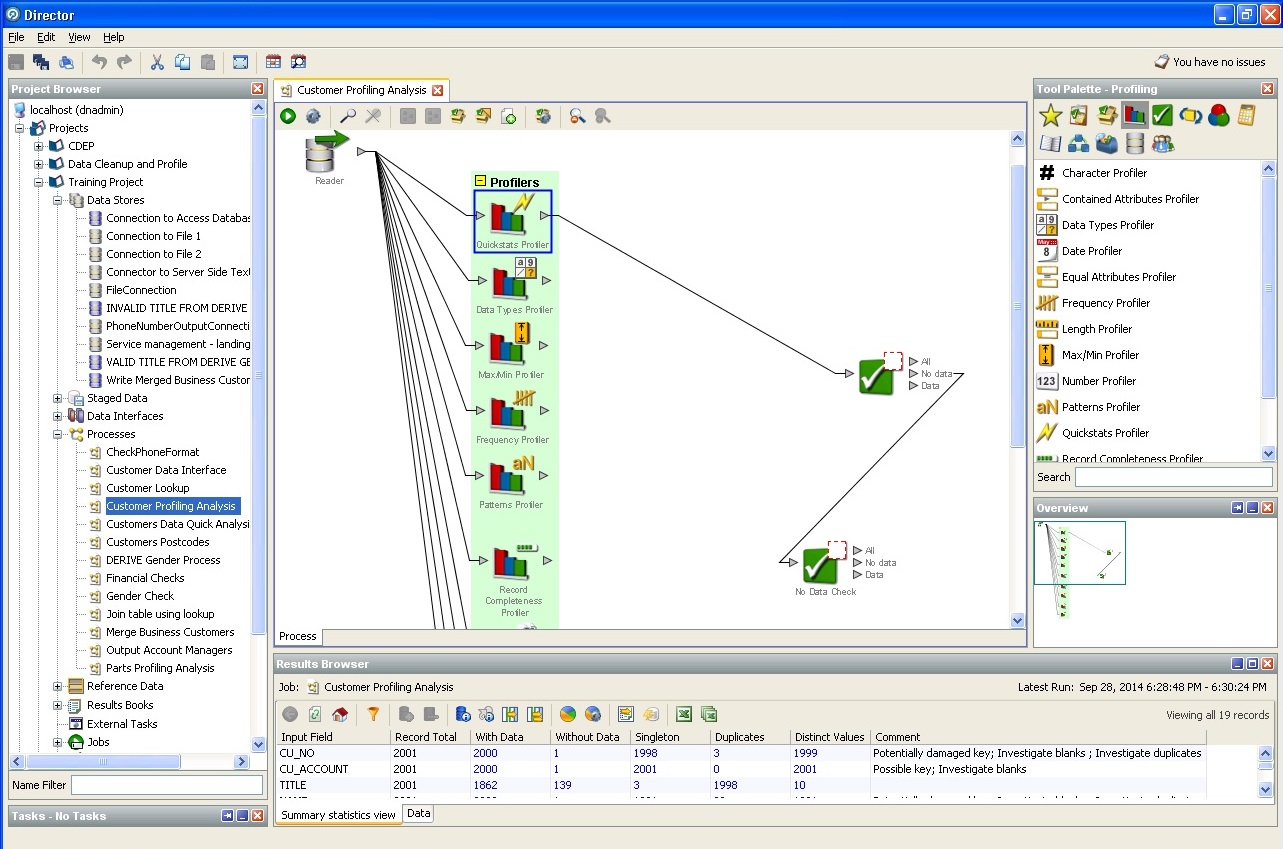
Zufällige Datenbank-Profiler-Aktion:
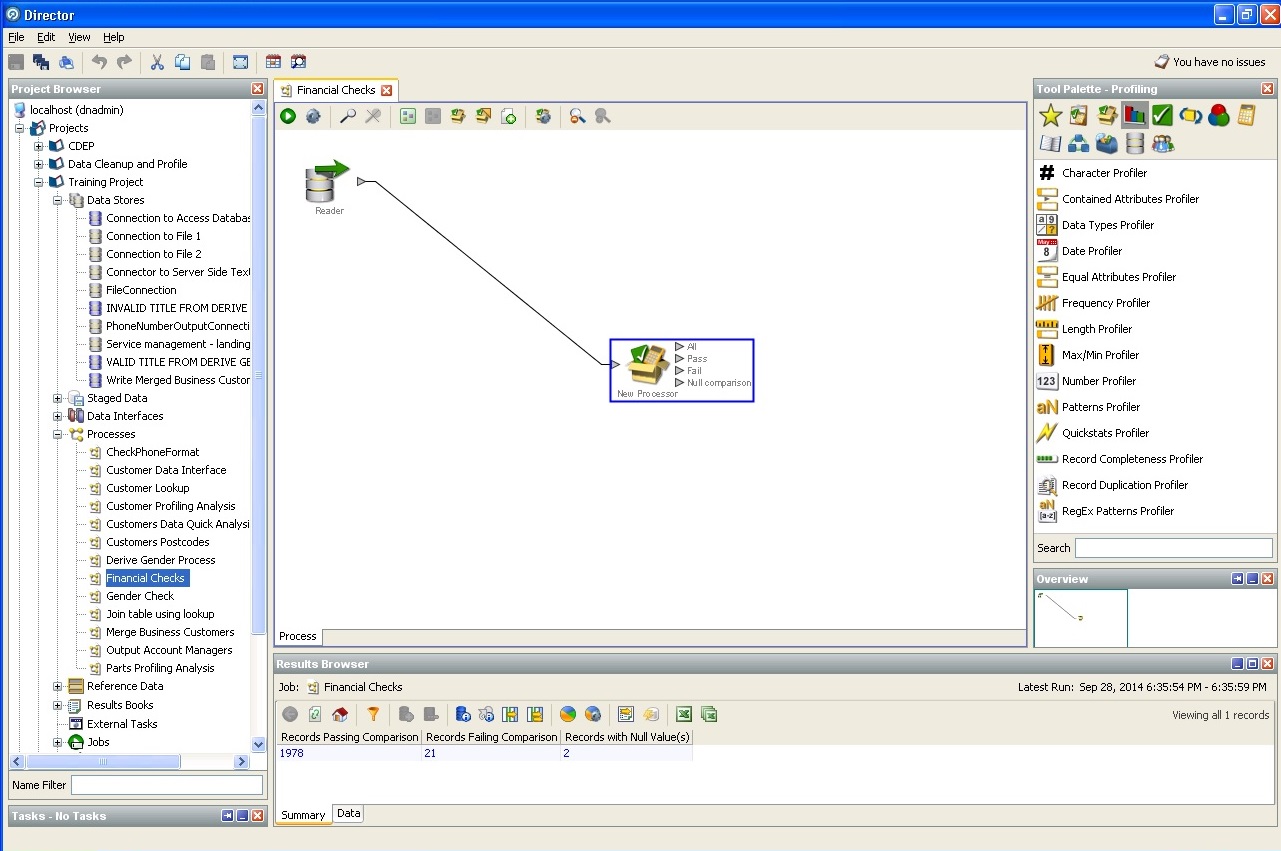
Grundprüfung der Zahlungsfähigkeit:
Arbeiten Sie mit einer Postleitzahl:
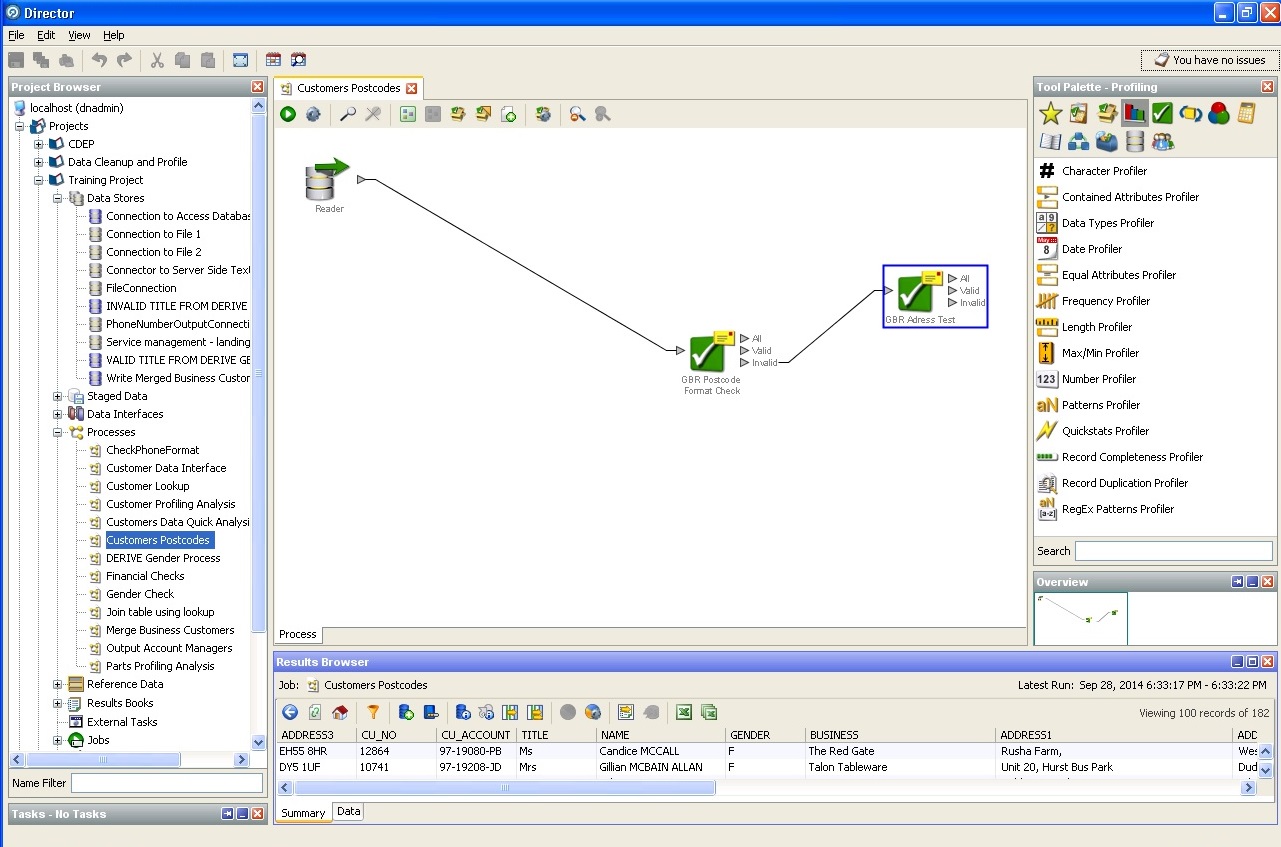
Postanschrift reinigen:
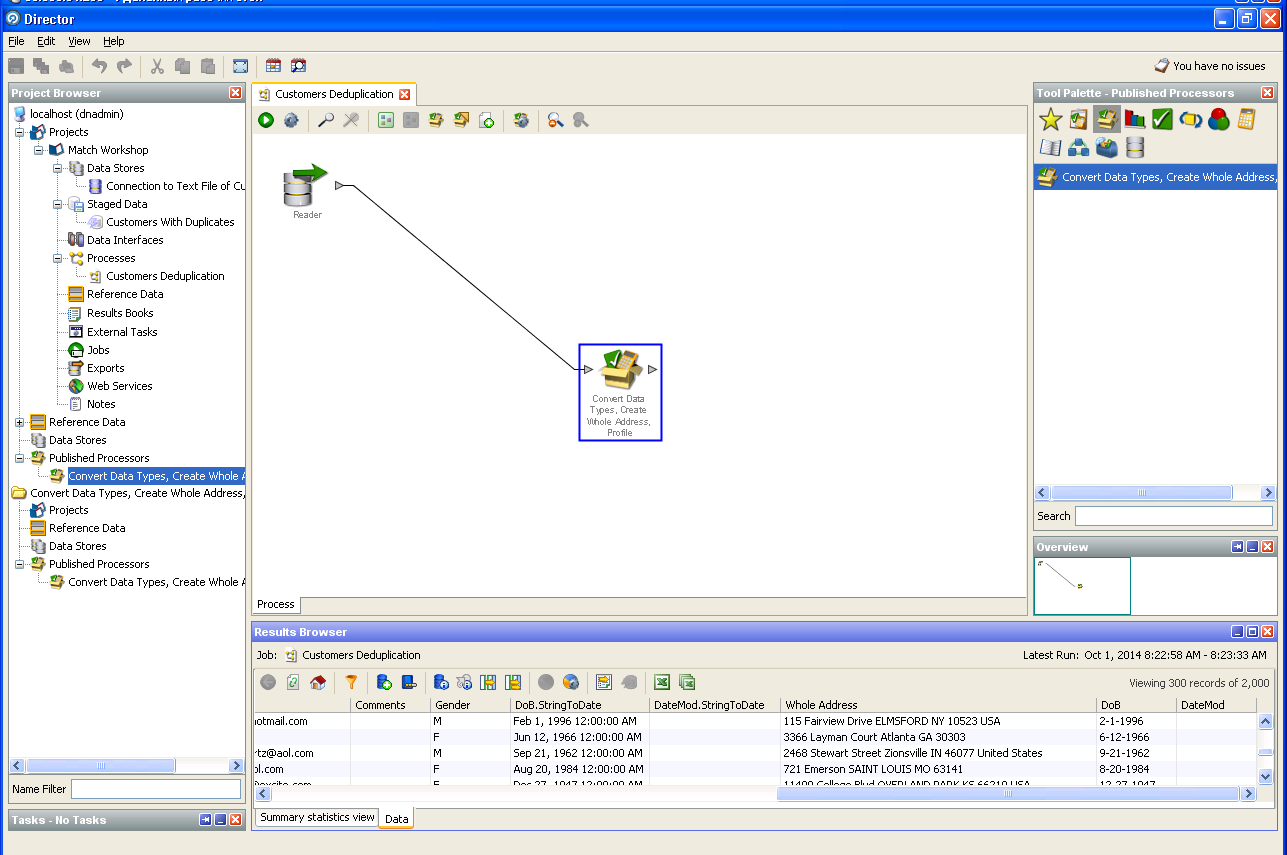
Benutzerdaten löschen:
Zuordnung eines Datensatzes zu dem einen oder anderen Konfidenzintervall:
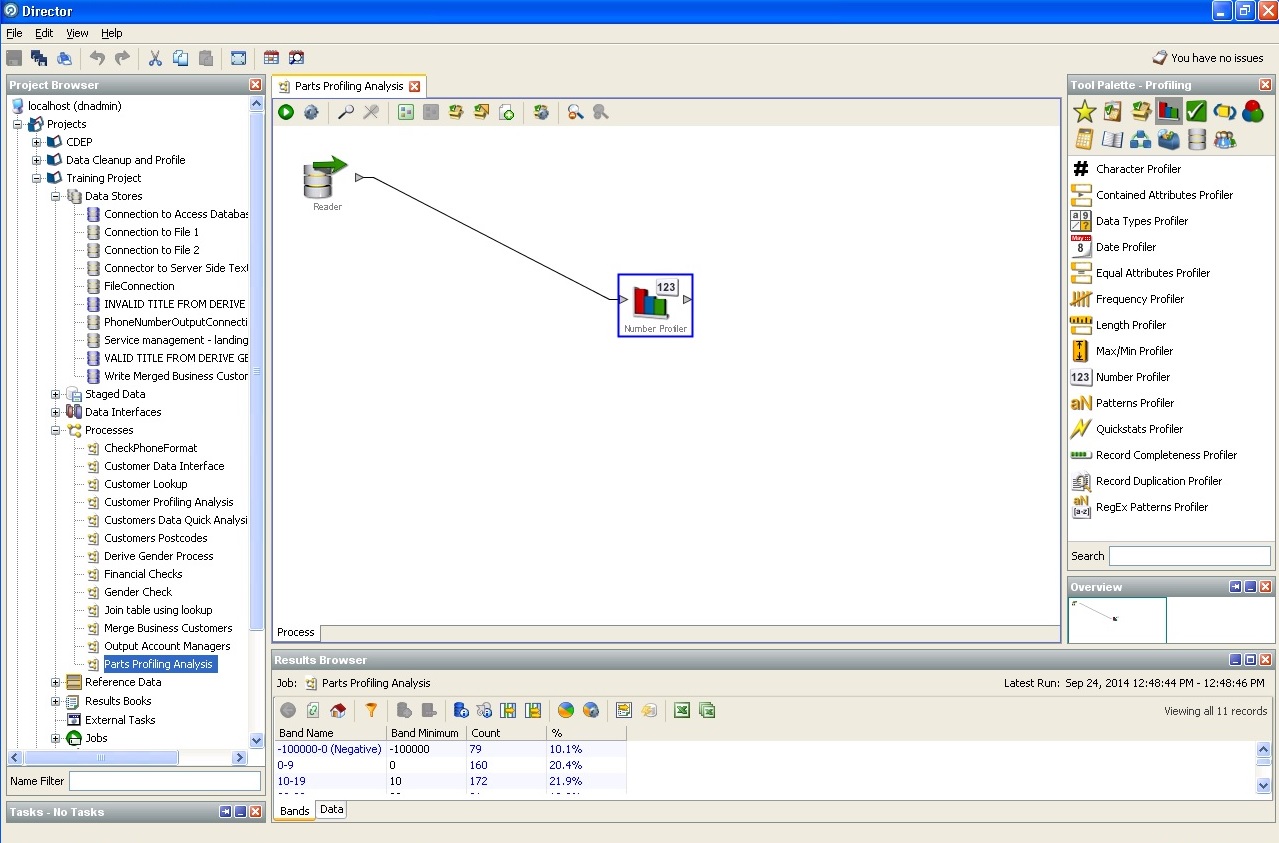
Ermittlung des Geschlechts des Benutzers anhand indirekter Daten:
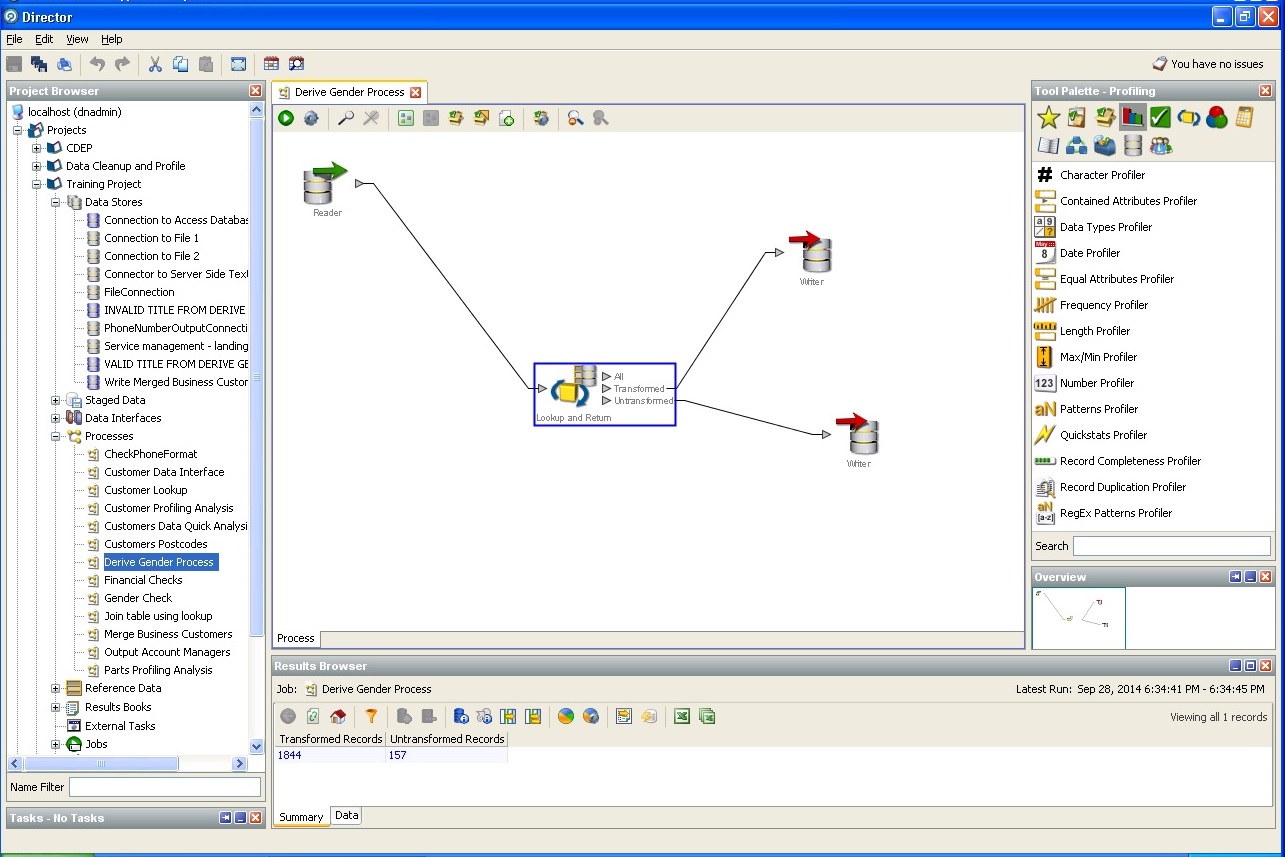
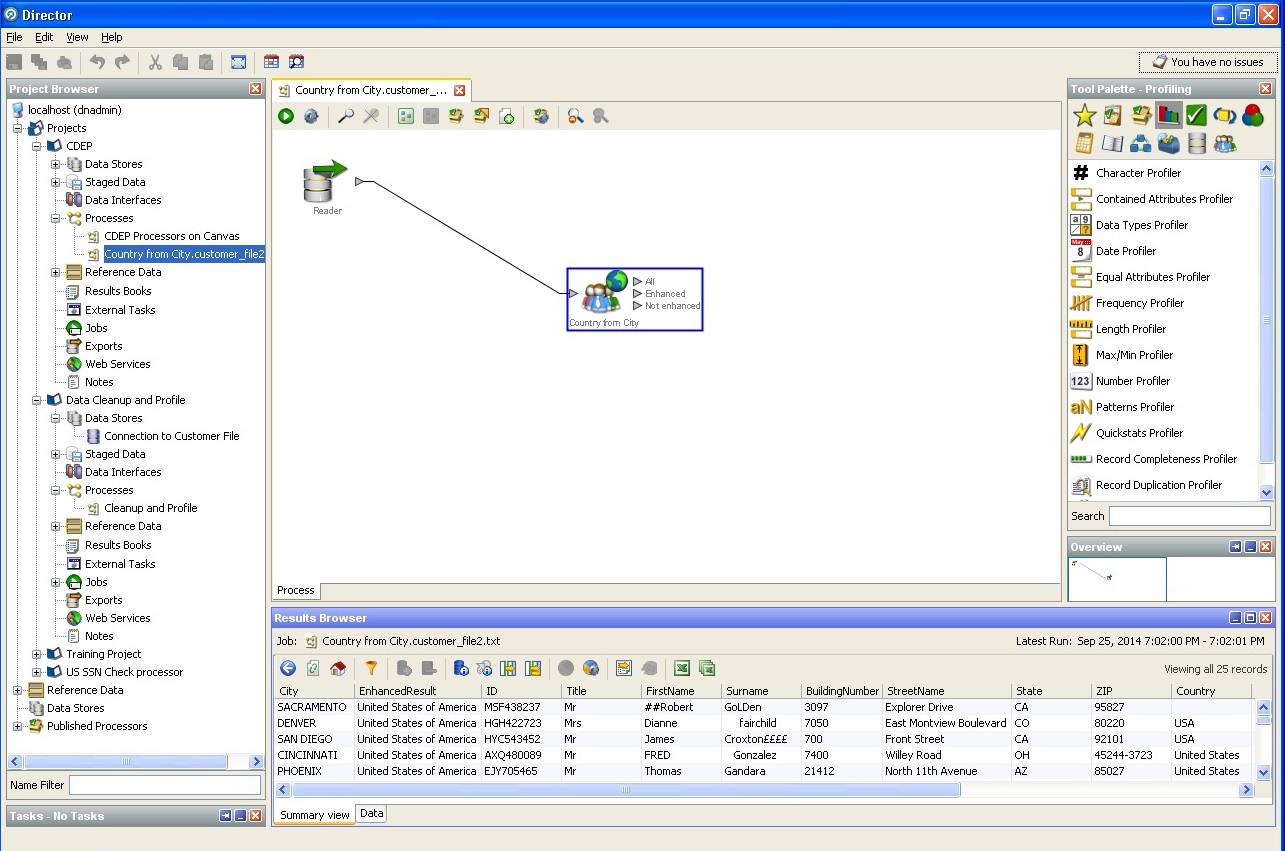
Definition einer Stadt und eines Landes, Bundesland:
Die einfachste Schlüsselsuche in einer zufälligen Datenbank:
Deduplizierung von Benutzerdaten:
 5. Lustige Beobachtungen zu den Ergebnissen der Arbeit an Oracle EDQ.
5. Lustige Beobachtungen zu den Ergebnissen der Arbeit an Oracle EDQ.Eines der Prinzipien für den Vergleich der Beiträge von Schriftstellern und Dichtern zur Literatur ist der Vergleich ihrer poetischen und literarischen Wörterbücher. Wir bieten eine Reihe von Wörterbüchern, die in der Freizeit zusammengestellt wurden, um vorgefertigte Lösungen für Oracle EDQ, Python und Java zu testen. Wir werden dankbar sein, wenn die Philologen in den Kommentaren ihre Ergebnisse veröffentlichen.
Nummer p.p.
| Wort
| Häufigkeit des Auftretens
|
Löwe
Tolstoi, Krieg und Frieden. Fragment der Häufigkeitstabelle
Copyright-Wörterbuch.
| I.
Brodsky, Urania.
| I.
Brodsky Complete Works, ein Fragment des Frequenzwörterbuchs
der Autor.
| N.
Nekrasov, ein Fragment des Frequenzwörterbuchs für die gesamte Sammlung
Essays.
|
1.
| und
| 10351
| in
1037
| in
5745
| und
3420
|
3.
| in
| 5185
| und
647
| und
4500
| in
2108
|
4.
| nicht
| 4292
| nicht
391
| nicht
3022
| nicht
1726
|
5.
| was
| 3845
| auf
341
| auf
2239
| ich
1040
|
6.
| er ist
| 3730
| wie
329
| wie
1758
| mit
883
|
7.
| auf
| 3305
| mit
237
| mit
1674
| auf
854
|
8.
| mit
| 3030
| was
168
| was
1531
| wie
763
|
9.
| wie
| 2097
| zu
148
| Und
1200
| was
693
|
10.
| ich
| 1896
| von
147
| ich
1040
| er ist
644
|
11.
| sein
| 1882
| von
104
| zu
922
| du
475
|
12.
| zu
| 1771
| ich
90
| von
810
| aber
472
|
13.
| dann
| 1600
| wo
88
| alle
748
| aber
449
|
14.
| sie ist
| 1564
| als
88
| von
744
| so
383
|
15.
| aber
| 1234
| für
76
| du
721
| zu
367
|
16.
| Das
| 1208
| von
74
| In
713
| alle
344
|
17.
| sagte
| 1135
| Aber
72
| für
687
| für
313
|
18.
| war
| 1125
| auch nicht
70
| von
635
| mir
309
|
19.
| so
| 1032
| würde
69
| aber
617
| ja
294
|
20.
| der Prinz
| 1012
| dann
67
| er ist
592
| sein
275
|
21.
| für
| 985
| du
67
| Aber
584
| dann
232
|
22.
| aber
| 962
| über
66
| dann
540
| war
229
|
23.
| zu ihm
| 918
| aber
63
| über
538
| von
224
|
24.
| alle
| 908
| ist da
61
| Das
524
| Nein
223
|
25.
| von
| 895
| Ich bin
61
| Ich bin
489
| auch nicht
222
|
26.
| sie
| 885
|
| aber
463
| über
213
|
27.
| von
| 845
|
| wo
449
| ihre
212
|
28.
|
|
|
| als
443
| von
209
|
29.
|
|
|
| A.
428
| von
207
|
30.
|
|
|
| das gleiche
422
| wir sind
206
|
Fazit: Die Statistik der russischen Sprache in den letzten hundert Jahren in Bezug auf die Häufigkeit einzelner Wörter hat sich bei Dichtern nicht wesentlich geändert - Wörter sind „melodiöser“. Übrigens stimmen die Statistiken von Daria Dontsova in vielerlei Hinsicht mit denen von Leo Tolstoi im Bereich des Frequenzwörterbuchs der gesamten Werke überein.
6. Mehrere formale Berechnungen als Schlussfolgerung.Ungefähr 60 Tausend Iwanow Iwanow Iwanowitsch leben in unserem Land. Unter der Annahme, dass irgendwo hypothetisch 100 Tabellen in der durchschnittlichen Datenbank gespeichert sind, 10 Schlüsselfelder in jeder Tabelle und jeder Schlüssel 60.000 Werte annehmen kann, ergibt sich eine Gesamtzahl von 60 Millionen eindeutigen Schlüsselzuständen in der Datenbank. Selbst wenn zwei Schlüssel in einer Tabelle verwechselt werden, können sie bis zu 20 eindeutige Zustände in einer Tabelle generieren. Insgesamt können bis zu mehreren Tausend auf die Basis eindeutiger Zustände stoßen. Stimmen Sie zu, dass es ein unzulässiger Luxus ist, 10% der Entwicklungszeit und 5-7% der ETL-Ausführungszeit für das Fangen solcher Kleinigkeiten aufzuwenden?
UPD1 Wenn Sie es satt haben, das Steuerungssystem für jedes mehr oder weniger wichtige Verzeichnis in Ihrer Arbeit zu ziehen,
helfen Ihnen MDM-Systeme (Master Data Management). Natürlich liefern wir solche Systeme auf den Markt, einschließlich einer Version mit freier Software.
UPD2 Sehr oft wird auf Konferenzen die Frage gestellt: „Wie schafft man ein billigeres Datenqualitätsmanagementsystem
? “. Ich bitte Sie, diesen Artikel als kleine Einführung in dieses Problem mit einer gewissen Vereinfachung der EDQ-Funktionalität zu betrachten. Ja, und dennoch können Sie eine Menge ODI + EDQ nehmen und es sehr gut machen, aber dies ist das Thema weiterer Erzählungen.