Hallo allerseits! Mein Name ist Denis Girko, ich bin der Systemarchitekt der E-Commerce-Plattform in Lamoda. Letztes Jahr habe ich auf der DevConf-Konferenz mit einem Bericht gesprochen , den ich mit Ihnen teilen möchte.
Dies ist ein Überprüfungsbericht über die Schwierigkeiten, auf die ein großer Online-Shop bei der Lieferung von Bestellungen stößt, und darüber, welche technischen Lösungen dazu beitragen können, diese zu überwinden (am Beispiel der von Lamoda getesteten Lösungen).

Worum geht es? Ich sage dir:
- Über den Lieferprozess und identifizieren Sie Probleme;
- wie Liefergebiete effektiv in der Datenbank gespeichert werden können;
- wie man die Qualität der Daten verbessert, die wir vom Kunden erhalten;
- So suchen Sie den Adressaten in der Adressdatenbank, um genauere Ergebnisse zu erhalten.
Allgemeines Lamoda Order Delivery Scheme
Lamoda ist ein Online-Shop mit vier Lieferländern: Russland, Ukraine, Kasachstan, Weißrussland. Wir liefern Waren bereits am nächsten Tag, da wir einen eigenen Lieferservice und ein Dutzend Partner haben, deren Dienstleistungen wir nutzen. Die Lieferung ist ein großer Teil unseres Geschäfts.
Lamoda nimmt die Bestellung an, fragt den Kunden zum Zeitpunkt der Registrierung nach der Adresse und leitet sie an den Kurierdienst weiter.
Was ist, wenn wir nicht einen Kurierdienst haben, sondern mehrere? Dann wird der nächste Schritt hinzugefügt - um zu bestimmen, welcher Lieferservice die Bestellung entgegennimmt.
Möglicherweise gibt es einige Kriterien für die Unternehmensauswahl. Als Erstes muss jedoch darüber nachgedacht werden, ob dieser Kurierdienst in die vom Kunden ausgewählte Stadt geliefert wird oder nicht. Daher besteht der erste Schritt bei der Integration eines Kurierunternehmens in unser System darin, den Versorgungsbereich zu ermitteln.
Als Nächstes müssen Sie lernen, wie Sie überprüfen können, ob die Adresse des Kunden in dieses Gebiet fällt oder nicht.
Das allgemeine Schema wird verbessert und sieht folgendermaßen aus:
- nach einer Adresse fragen;
- Finden Sie heraus, welche Kurierdienste es liefern können.
- Wählen Sie aus den verfügbaren die gewünschte aus.
Nun etwas mehr zu diesen Schritten.
Wir fragen den Kunden nach der Adresse
Wie kann ich ihn fragen?
- Bitten Sie darum, ein großes Feld auszufüllen. Der Kunde hämmert seine Adresse ein, was keine kniffligen Manipulationen erfordert. Die Adresse kann auf ein Blatt Papier gedruckt werden, das dem Kurier zu Fuß gegeben wird, der es dann selbst herausfindet.
- Die zweite Option ist komplizierter. Wir bitten den Kunden, jede Komponente der Adresse in seinem Feld auszufüllen. Hier kann man schon was machen. Vergleichen Sie beispielsweise die Stadt Moskau mit einer bestimmten Liste von Städten. Aber es wird schlecht funktionieren, weil die Stadt Moskau auf viele Arten geschrieben werden kann: „g. Moskau “,„ Moskauer Stadt “,„ Moskauer Stadt “ohne Leerzeichen und so weiter.
- Daher gibt es eine noch erweiterte Option. Da die Liste der Städte, die wir haben, endlich ist, können Sie eine Liste der Städte vorab zusammenstellen und dem Kunden vorschlagen, die gewünschte Stadt auszuwählen. Der Bonus ist, dass wir jedem Element einer solchen Liste hier bereits eine Kennung zuordnen können. Wir Entwickler lieben es, nicht mit Zeichenfolgen zu arbeiten, sondern mit Bezeichnern, die in allen unseren Systemen als Äquivalent zur ausgewählten Stadt verwendet werden können. Ich habe einen zentralen Postindex auf der Folie als Kennung.

Welchen Lieferservice transportieren wir?
Da wir einen Bezeichner (Index) haben, lassen Sie das in unserer Datenbank gespeicherte Gebiet durch eine Liste von Indizes dargestellt werden. In diesem Fall ist der Algorithmus zur Überprüfung des Eintritts der Stadt in das Gebiet sehr einfach. Also lasst es uns tun: Wir werden die von Kurierdiensten erhaltenen Liefergebiete in Form von Indizes in die Datenbank aufnehmen.
Indizes haben ihre Vor- und Nachteile. Ich werde im Voraus sagen, dass Lamoda zu Beginn genau das getan hat: Das Ergebnis der Auswahl eines Stadtkunden war ein Index, und unsere Indizes wurden in der Datenbank gespeichert. Warum ein Plus? Wie gesagt, ein Index ist eine Sache, die jeder versteht. Jeder Manager, der gerade zur Arbeit gekommen ist, weiß, was ein Index ist. Er kann von der Kurierfirma der Stadt empfangen, sie irgendwie in Indizes umwandeln und verwenden. Der Nachteil ist, dass der Index die Kennung der Post der russischen Post ist. Und nahe gelegene Siedlungen können denselben Index haben.
Warum fehlen die Indizes?
Ein einfaches Beispiel: Lyubertsie. In der Nähe liegt das Dorf Marusino. Marusino hat kein Postamt, ihre Korrespondenz kommt zu einem der Postämter von Lyubertsy. Wenn wir die Lieferung zu Lyubertsy hinzufügen wollten, aber nicht zu Marusino, weil dies für uns möglicherweise nicht finanziell rentabel ist, könnten wir dies nicht nur nach Index tun.
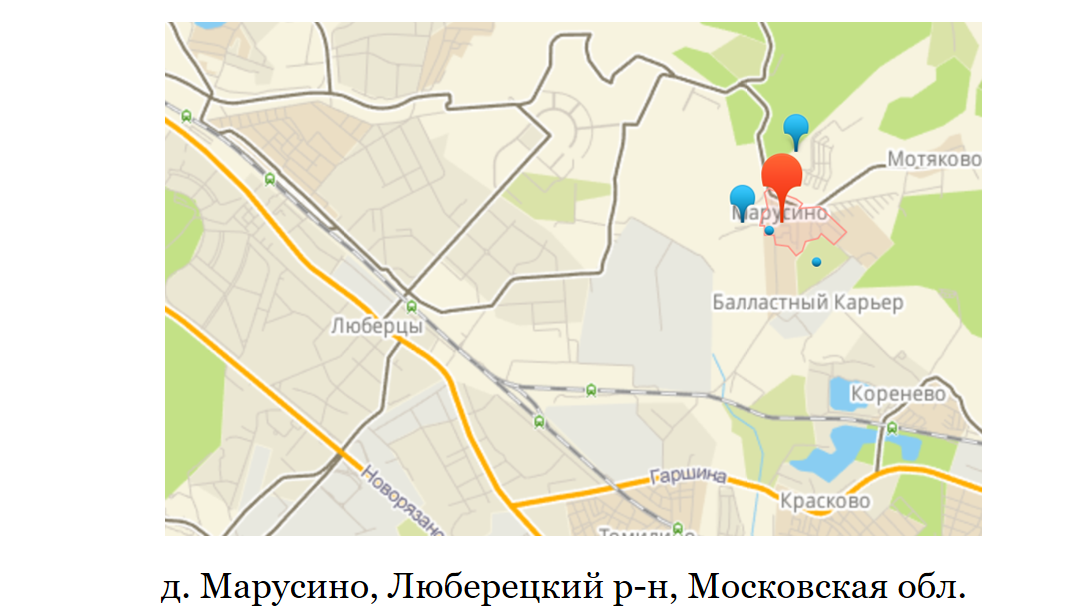
Ein weiteres Beispiel ist die Erweiterung und Eröffnung eines zweiten Transitlagers in Moskau durch Lamoda. Es war notwendig, Moskau in die nördliche und südliche Hälfte zu teilen. Und bereits zum Zeitpunkt der Bestellung wissen Sie, von welchem Transitlager die Lieferung ausgeführt wird. In diesem Fall würde ein Index pro Stadt nicht ausreichen.
Wir haben uns entschieden, Geokoordinaten zusammen mit Indizes zu verwenden. Wir nehmen die Adresse des Kunden und führen sie durch den Yandex-Geocoder . Am Ausgang erhalten wir nicht nur den Index, sondern auch die Koordinaten. Wir verwenden Indizes in Fällen, in denen Details nicht wichtig sind. Und die Koordinaten geben die Fälle an, in denen Sie eine dünne Aufteilung des Gebiets vornehmen müssen.
Sie haben in ihrem Setup-Programm eine Schnittstelle für Logistiker bereitgestellt, über die Sie ein Polygon über der Karte zeichnen können. Es ist ganz einfach: Der Punkt fällt auf die Mülldeponie - es gibt Lieferung, fällt nicht - nein.
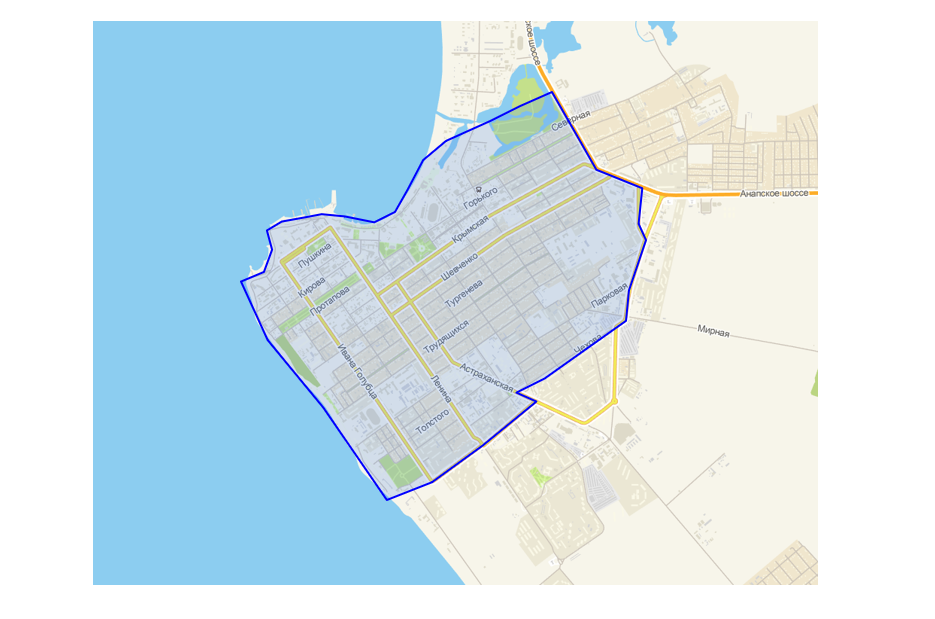
Schnittstelle zur Erstellung von Polygonzonen
Der Bonus, den wir für jede Bestellung mit Geokoordinaten haben, war die Möglichkeit, die Schnittstelle zu verbessern, über die Logistiker Routen für Vertriebsmitarbeiter erstellen. Die Benutzeroberfläche zeigt eine Karte an, auf der Kundenaufträge markiert sind. Der Logistiker verwendet das Lasso-Tool, das die benachbarten Aufträge zu einer Route zusammenfasst. Außerdem führt diese Route zu einem Vertriebsmitarbeiter, dh eine Person muss tagsüber nicht von einem Ende der Stadt zum anderen Ende gehen, um alle ihre Bestellungen entgegenzunehmen - sie sind alle geografisch nahe beieinander.
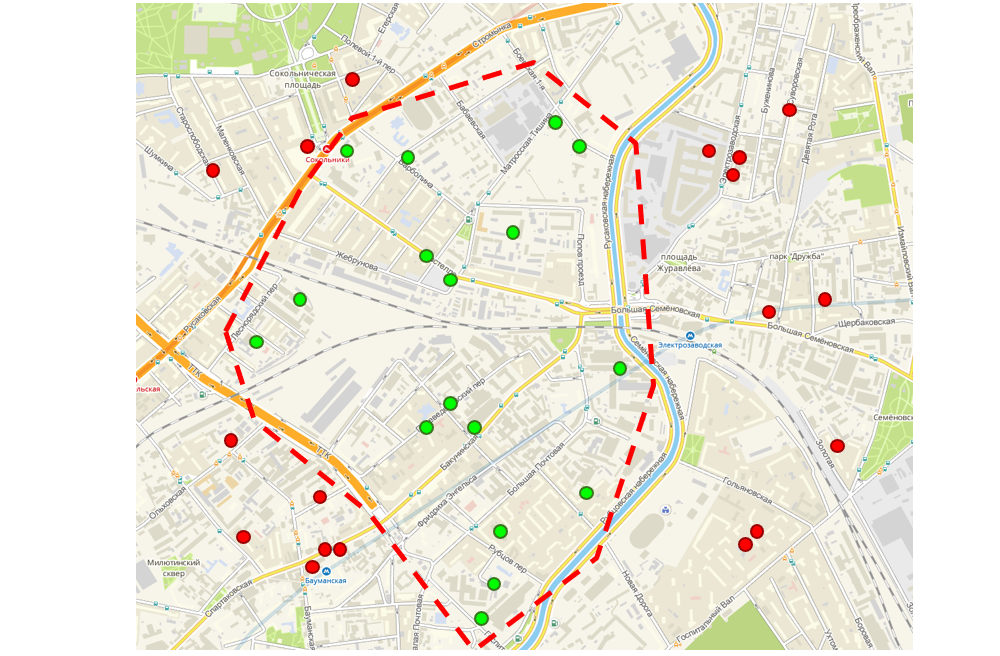
Routing-Schnittstelle
Die vom Kunden eingegebene Adresse wird in Koordinaten umgewandelt. Die Wahrscheinlichkeit, dass wir die Koordinaten für eine bestimmte Adresse direkt erhalten, hängt von der Qualität der vom Kunden eingegebenen Adresse ab. Daher haben wir uns als erstes Gedanken darüber gemacht, wie wir die Anzahl der bekannten Adressen erhöhen können. Daher müssen Sie dem Kunden helfen, die richtige Adresse einzugeben.
Tatsache ist, dass Kunden häufig nicht den von uns für sie bereitgestellten Szenarien folgen. Daher haben wir Adressdatenbanken für jedes der vier Länder erworben, in die wir Bestellungen liefern. Und sie machten nicht nur für die Stadt, sondern auch für die Straße und sogar für die Hausnummer ein Sajest. Um eine Liste der Häuser zu erstellen, haben wir die offenen Daten von openstreetmap.org analysiert.
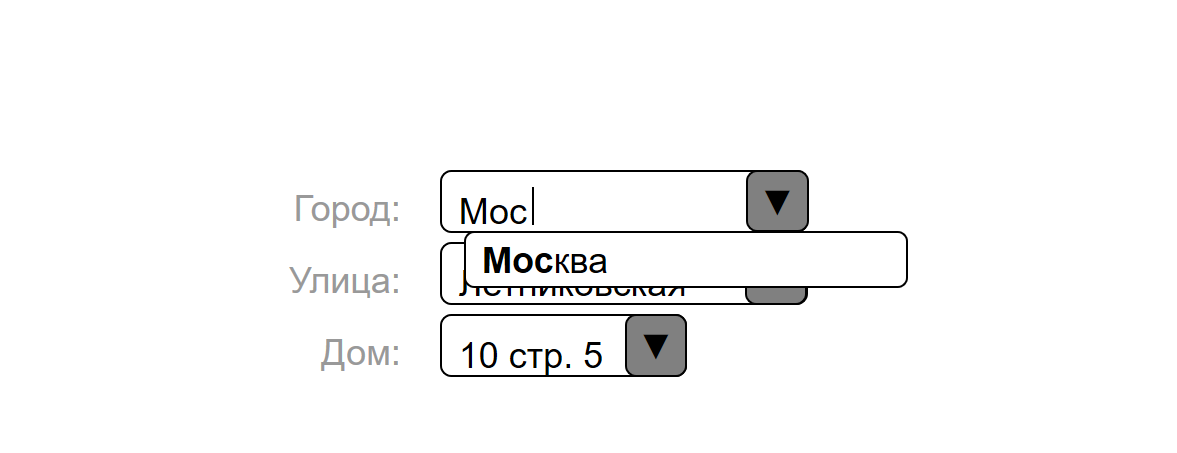
Das Checkout-Formular bietet Tipps zur Formalisierung von Adressdaten
Adressbasis
Um ein Sujest an der Adressbasis zu machen, müssen Sie es zu Hause behalten. Woher haben wir alle Adressbasen für unsere vier Länder? In Russland ist es FIAS , die Adressbasis , die von unserem Steuerdienst erstellt und verwaltet wird. Es ist ziemlich vollständig, wenn auch nicht ohne Mängel. Unsere Lieferpartner haben uns in anderen Ländern geholfen.

Wir haben auch eine Reihe von PHP-Skripten, die das Format annehmen, mit dem die Adressbasis zu uns kommt, und sie auf ungefähr die gleiche Weise zu PostgreSQL hinzufügen. Warum in der gleichen Form? Denn eine der Aufgaben besteht darin, diese Datenbanken regelmäßig aus denselben Quellen zu aktualisieren. Dies bedeutet, dass die Konvertierung bei jeder Aktualisierung wiederholt werden müsste. Daher werden die Daten an PostgreSQL gesendet und von dort in Apache Solr konvertiert und gespeichert. Mit Solr können Sie schnell nach ihnen suchen und sajest machen. Ein kleiner PHP-Webserver kann Anforderungen in Solr erstellen. Entsprechend ihren Ergebnissen wird eine Liste für den Client auf der Site für einen Vorschlag erstellt.
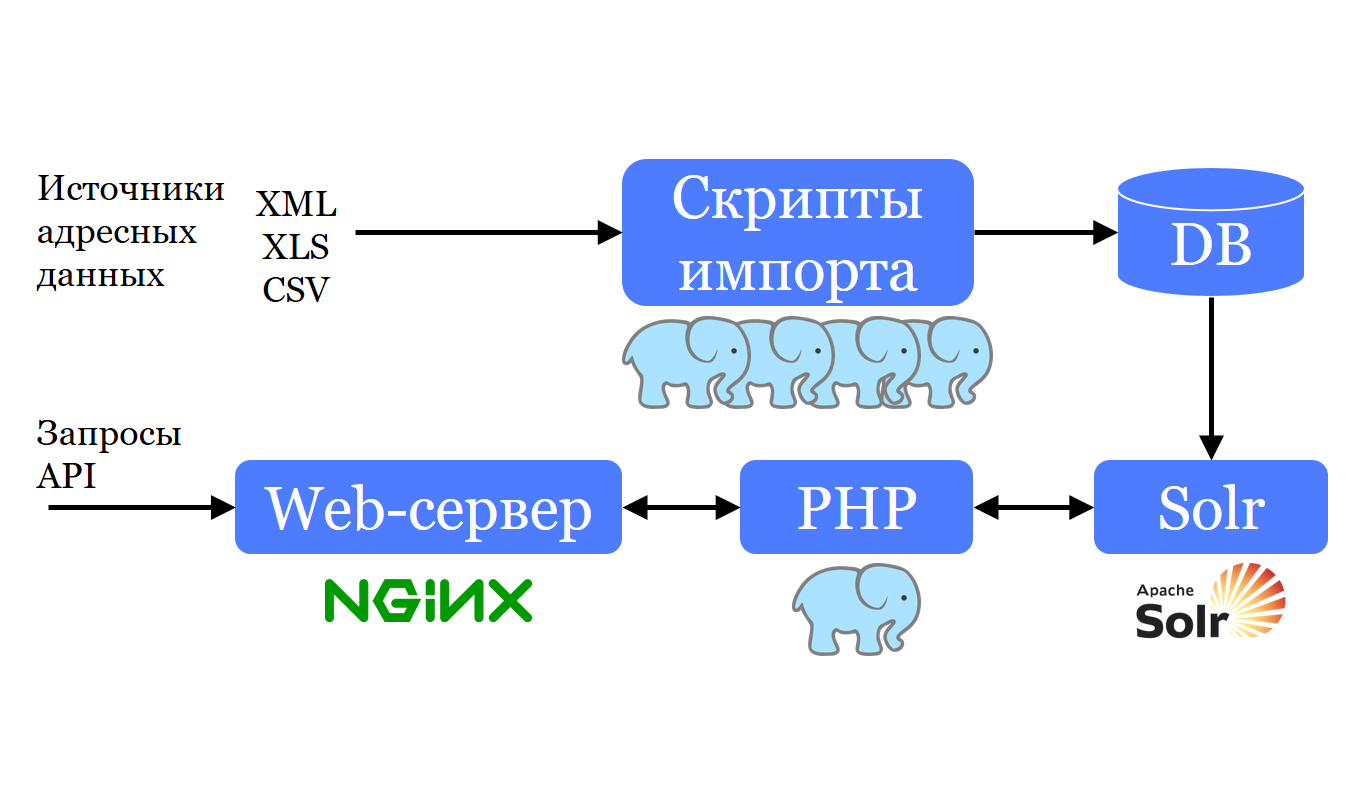
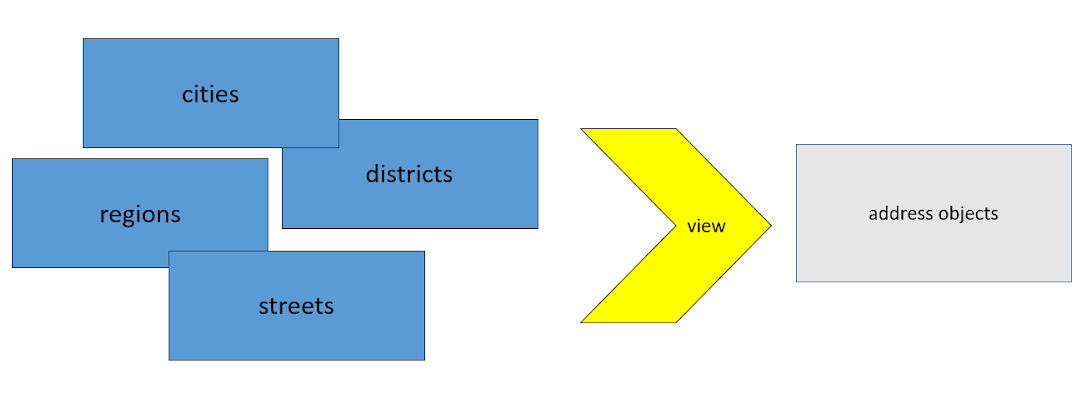
Wir laden Daten aus der Quelle in ungefähr derselben Form herunter, in der sie zu uns gekommen sind. Das heißt, mit demselben Satz von Feldern, mit denselben Spaltentypen und so weiter. Fügen Sie sie so hinzu, wie sie sind. Wir haben von Anfang an versucht, die Daten in dieser Form zu verwenden, und um sie in die Strukturen umzuwandeln, mit denen wir arbeiten können, haben wir mehrere Ansichten geschrieben. Da wir 4 Länder haben, wurde dies alles mit 4 multipliziert, und die Unterstützung war sehr schwierig und teuer. Daher war es notwendig, etwas dagegen zu unternehmen.
Das erste, was wir losgeworden sind, ist die unstrukturierte oder vielmehr spezifische Strukturiertheit in einem frühen Stadium. Das heißt, sobald die Rohdaten hochgeladen wurden, transformieren wir sie mithilfe von Ansichten in ein einheitliches Format, mit dem alle anderen Transformationen weiter konfiguriert werden. Dies hat uns davor bewahrt, mit 4 zu multiplizieren. In diesem Moment vergessen wir die Struktur, in der die Daten zu uns kamen, und arbeiten nur mit dem, was wir für uns selbst erfunden haben.
Wenn Sie zwei Quellen benötigen - bitte herunterladen. Die Hauptsache ist, dass das Format dieser Datenausgabe nach der Konvertierung in Ansichten dasselbe ist.
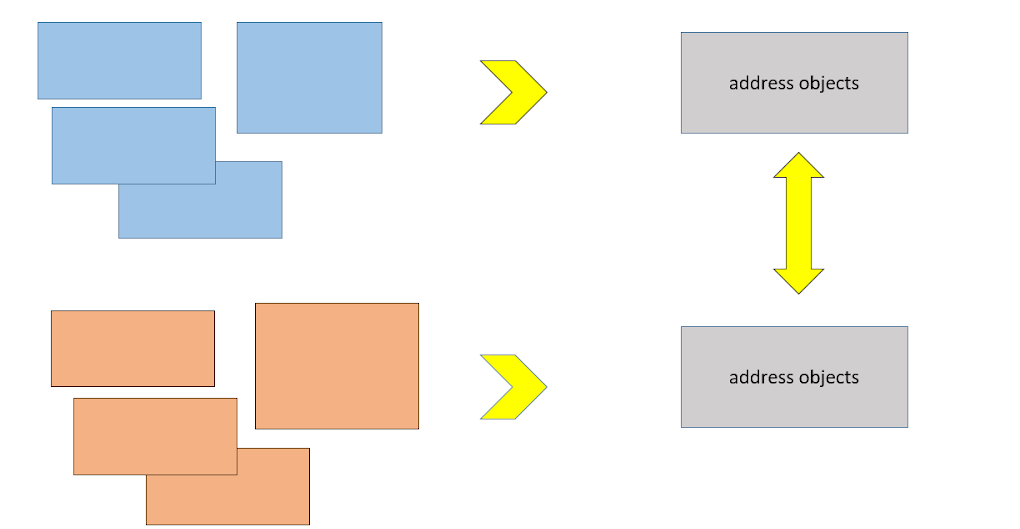
Eine weitere Anforderung für geladene Adressdatenbanken war, dass Punktkorrekturen daran vorgenommen werden mussten. Ein einfaches Beispiel: In FIAS heißt die Tschuwaschische Republik "Tschuwaschische Republik". "Tschuwaschien." Nun, wir wollen nur die Tschuwaschische Republik. Warum brauchen wir diesen Strich? Gleichzeitig können wir regelmäßige Aktualisierungen aus Quellen immer noch nicht vermeiden.
Hier sind die folgenden Ebenen, die wir in PostgreSQL haben.

Die Tabellen links sind Rohdaten, die von der Quelle heruntergeladen wurden.
Dahinter befinden sich Ansichten, die Daten in ein Standardformat konvertieren.
Lokale Überschreibungen sind unsere Tabellen, die einige Attribute der geladenen Adressdaten punktuell neu definieren. Wir haben hier zum Beispiel aufgenommen, dass ein Datensatz mit einer solchen Kennung anstelle von „Chuvash rep. - Tschuwaschien “ist unser gewählter Name.
Die Zuordnungstabelle ist unser Repository für Bezeichner, die wir selbst den heruntergeladenen Adressobjekten zugewiesen haben. Dadurch konnten wir unsere Systeme von der Quelle, von den in der Quelle verwendeten Bezeichnern abstrahieren und nicht nur eine Quelle, sondern sogar mehrere - unter einer ID verbergen Ich werde es etwas später erzählen. All dies zusammen wird kombiniert und in einer materialisierten Ansicht fixiert. Somit erhalten wir fast das Äquivalent der endgültigen Tabelle, die durch Ausführen eines SQL-Befehls REFRESH MATERIALIZED VIEW aktualisiert werden kann.
Adressobjekte - gebildete Adressbasis mit allen Korrekturen und Ergänzungen.
Am Ausgang haben wir also bereits Adressobjekte korrigiert, bereits mit neuen Namen und unseren Bezeichnern. All dies wird transformiert und denormalisiert, wie es für die Suche bequem ist, und in Solr addiert.
Da wir jetzt Adressdatenbanken haben, wäre es cool, diese nicht nur zu verwenden, um ein Sujest für das Bestellformular zu erstellen, sondern auch um eine Suche durchzuführen. Wo kann eine Suche nützlich sein? Es stellt sich viel heraus, wo. Dieselben Zustellgebiete, die wir von Kurierdiensten erhalten, werden sehr oft einfach durch eine Liste von Städten dargestellt. Und die Liste der Städte ist mit den gleichen Problemen behaftet wie bei Benutzereingaben: Städte können unterschiedliche Interpretationen, unterschiedliche Namen und mehr haben.
Ich habe hier eine spezielle Folie, eine solche Horrorgeschichte - was müssten wir tun, wenn wir alles manuell nehmen würden, um es in PHP umzuwandeln: Tschetschenien, die Tschetschenische Republik und so für jede Datenquelle - Hölle ist Hölle.

Ergänzung: Auf dem Bildschirm - ein Stück echten Codes aus dem Dienst, der nur aufgrund der beschriebenen Lösungen unnötig wurde.
Wir haben diese Probleme klassifiziert.
1) Äquivalente Namen derselben Objekte. Zum Beispiel solche gebräuchlichen Synonyme wie Tschuwaschien und die Tschuwaschische Republik.
2) Umbenannte Städte. Die Ukraine befindet sich derzeit in der aktiven Phase, um die kommunistische Vergangenheit loszuwerden, weshalb sie buchstäblich jeden Tag Änderungen an den Namen ihrer Siedlungen vornimmt. Aus diesem Grund kann sich herausstellen, dass wir in einer Datenbank alte und in einer anderen Datenbank neue Namen haben.
3) Viele Fehler. Oft falsch im Status von Siedlungen. Es gibt ein Dorf, hier ist ein Dorf oder hier ist ein Dorf, es gibt einen Bauernhof.
4) Transliterierte Fremdwörter ins Russische, oft wird der gleiche Name auf unterschiedliche Weise transliteriert.
5) Es gibt viele Fehler in der Hierarchie: Zelenograd gehört aus Gewohnheit zur Region Moskau, obwohl es formal auch in Moskau als FIAS aufgeführt ist. Schreiben Sie richtig "Stadt Moskau, Zelenograd".
Wie sind wir darauf gekommen?
Als erstes trennen wir alle unbedeutenden Komponenten der Adresse von den Namen. Wir werfen sie nicht weg, sie nehmen an der Suche teil, sondern getrennt von den wesentlichen Teilen.
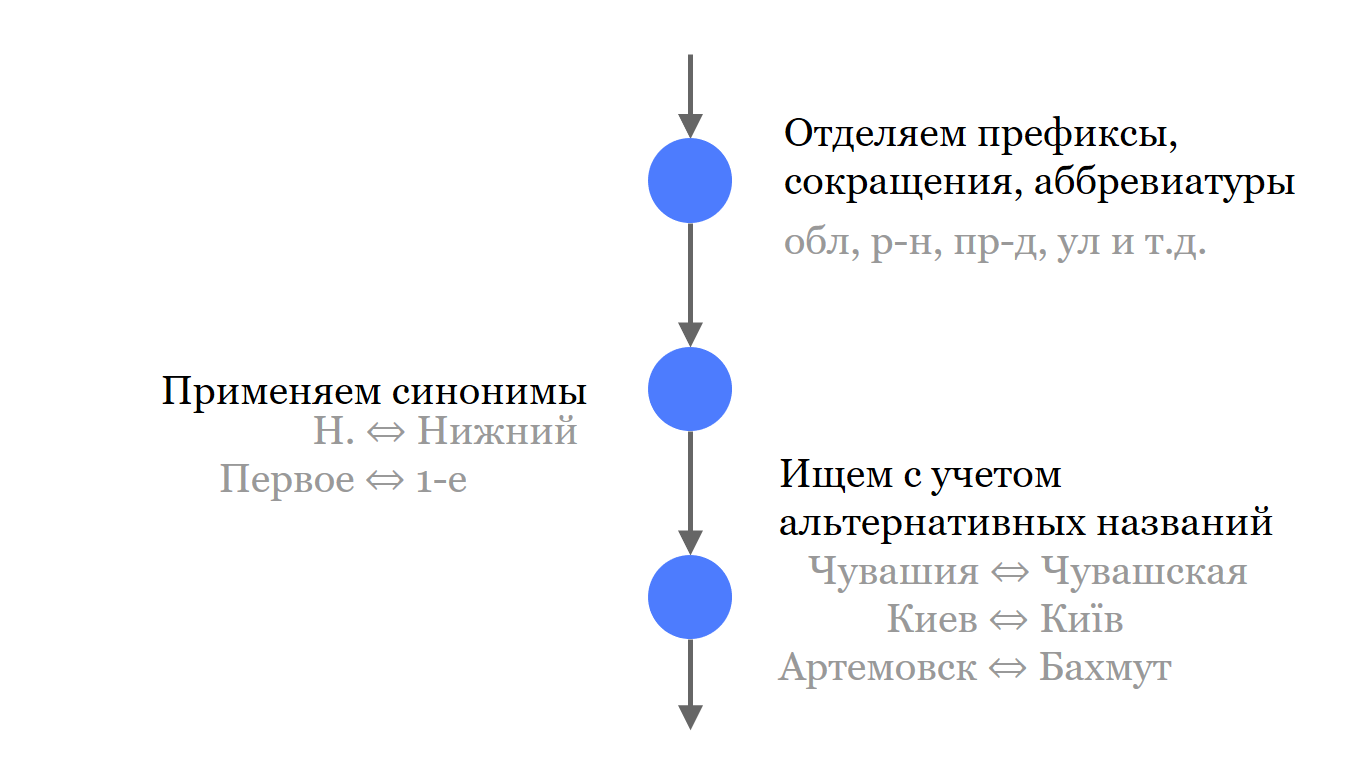
Als nächstes haben wir eine kurze Liste gängiger Synonyme und Abkürzungen erstellt, die in den Namen verwendet werden. Wo es die Quelle erlaubte, haben wir alle Namen in Solr geladen und eingefügt. Nicht nur die relevantesten, sondern auch mögliche Synonyme und historische Namen.
Zur besseren Suche werfen wir alle Buchstaben aus, die zu Unstimmigkeiten führen können. Dies gilt für die russische Sprache und die Sprachen, mit denen wir uns noch befassen müssen.
Wir korrigieren Tippfehler und korrigieren das Layout.
Schließlich haben wir uns Phantomeltern ausgedacht - dies sind Eltern, die Objekten zugeordnet sind. Sie sind für die Suche relevant, nehmen jedoch nicht am Suchergebnis teil. Für Zelenograd haben wir beispielsweise die Region Moskau hinzugefügt. Jetzt können Sie nach „Moskau, Zelenograd“ suchen und das gewünschte Objekt finden, aber in den Suchergebnissen ist es immer noch das richtige „Moskau, Zelenograd“.
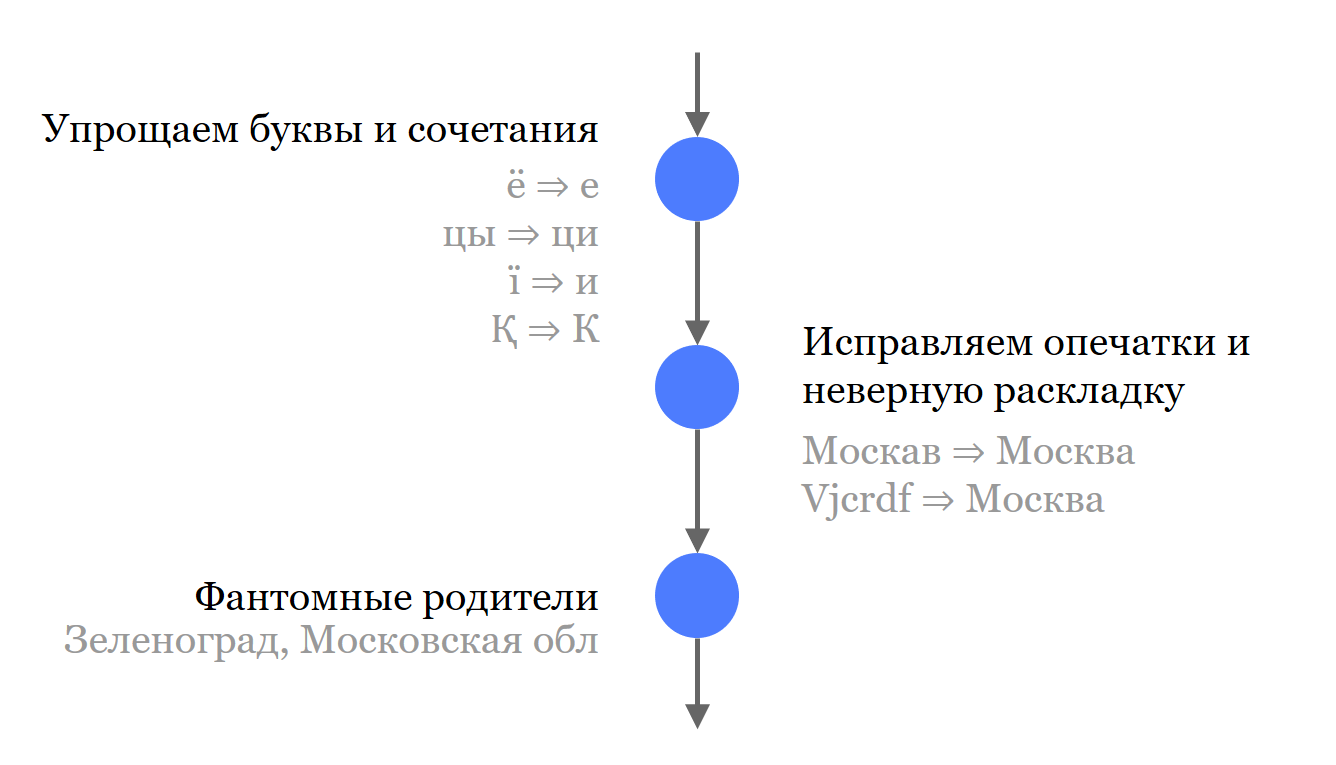
Abhängig von den Geschäftsanforderungen ist eine unterschiedliche Abstufung der Suchgenauigkeit erforderlich. Daher haben wir 4 Grad, von denen jeder ein Ergebnis mit einer höheren Wahrscheinlichkeit liefert, aber mit einer niedrigeren Wahrscheinlichkeit ist es genau das Ergebnis, das gesucht wird.

Und wo haben wir eine solche Suchanwendung gefunden?
- Wir führen erneut die vom Kunden eingegebene Adresse durch eine solche Suche aus. Wenn er unsere Tipps auf der Checkout-Seite nicht verwendet hat, haben wir noch eine Chance, die von ihm eingegebenen Zeilen in Bezeichner umzuwandeln. Wir bekommen eine formalisierte Adresse.
- Wir durchlaufen diese Suche alles, was uns Kurierdienste senden - wir erkennen die Städte, die sie uns übermitteln. Auf diese Weise konnten wir nur 10 Stück pro Tag auf den Markt bringen. Dies ist für B2B relevant. Lamoda liefert an Drittunternehmen, sodass pro Zeiteinheit viele neue Kurierdienste verbunden sind.
- Dies ermöglichte es uns, verschiedene nützliche Informationen in unsere Bezeichner in Adressdatenbanken einzutragen. Zum Beispiel haben wir Zeitzonen und IP-Adressen heruntergeladen, um nach Städten anhand der IP-Adressen von Kunden zu suchen.
- Wir haben jetzt die Möglichkeit, die Adressbasis aus zwei Quellen mit einer unserer Kennungen zu verbergen. Das heißt, es wurde ermöglicht, Duplikate zu vermeiden und dieselben Adressobjekte in beiden Basen abzugleichen.
Wir hören nicht auf. Dies ist ein Prozess, den wir noch verbessern können.
Erstens arbeitet Lamoda an Indizes. Das heißt, unsere Bezeichner sind Indizes, deren Minuspunkte wir kennen. Fast alle unsere Systeme haben auf die neue API umgestellt, sie arbeiten nicht mit Indizes, sondern mit genau den Kennungen, die wir selbst unseren Adressobjekten zugewiesen haben. Das Plus ist, dass die Suche nach einer Stadt im Gebiet so einfach ist wie bei Indizes. Es gibt jedoch kein Minus in der Tatsache, dass sich mehrere Siedlungen hinter einer ID verstecken können.
Ergänzung: Die Zeit ist seit dem Moment meiner Rede vergangen, und jetzt bin ich froh, mich zu korrigieren: Unsere Verzeichnisse bleiben nur für den Fall erhalten, dass der Kurier uns ihr Territorium in Form einer Liste von ihnen, zum Beispiel der Russischen Post, gibt. In anderen Fällen wurden die Indizes durch unsere internen Adresskennungen ersetzt.
Auf der Folie befindet sich ein Teil der Benutzeroberfläche, mit der Sie das Gebiet manuell konfigurieren können. Tatsächlich wird jedoch alles aus stapelweise geladenen Listen von Adressobjekten in Form von Zeichenfolgen konfiguriert.

Wir haben Geokoordinaten von openstreetmap.org für Privathaushalte heruntergeladen. In einem großen Prozentsatz der Fälle müssen wir jetzt nicht mehr zu einem externen Dienst gehen, um den Standort herauszufinden. Dies reduzierte uns zehnmal irgendwo nach Yandex, was natürlich Geld sparte.
Wir werden PHP in der Suchkette für Adressdaten los. Wir haben den Code, der auf Solr auf Lua zugegriffen hat, neu geschrieben. Ersetzt Nginx durch Openresty , jetzt ist alles sehr schnell und hält schweren Belastungen stand. 95% der Antworten unseres Suchdienstes passen in 10 Millisekunden, was für uns mehr als ausreichend ist.

Ergänzung: Die Verwendung von Openresty und Lua, die durch ihre Leistung angezogen wurden, war eine Art Experiment, das sich ausgezahlt hat: Der Service funktioniert schnell, ist unter Last stabil und leicht zu warten. Aber seitdem hat Lamoda Golang, das die gleichen Eigenschaften hat, als eine der Programmiersprachen für das geladene Backend übernommen. Wenn die Entscheidung zur Entwicklung des Dienstes jetzt getroffen würde, würden wir es vorziehen.
Fazit
Meine persönliche Moral bei all der geleisteten Arbeit ist, dass Adressdaten ein Bereich sind, in dem Sie keine ideale Datenqualität erwarten können. Das wird niemals passieren. Wir werden niemals perfekte Daten von einem Kunden oder von externen Quellen erhalten. Daher müssen Sie das Maximum aus dem herausdrücken, was ist.